Structure over Pixels: Learning Variable-Length Visual Programs
Pith reviewed 2026-06-29 18:03 UTC · model grok-4.3
The pith
STROP learns both a structural codebook and the right number of tokens per image in one forward pass by supervising on rate-distortion quality of DINO features instead of pixels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
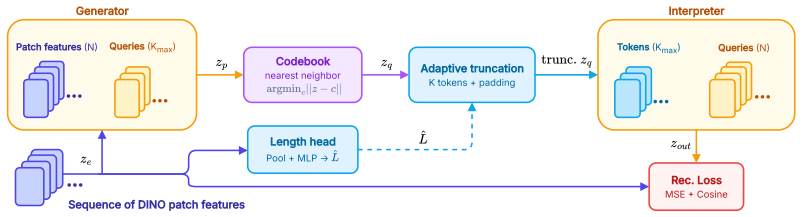
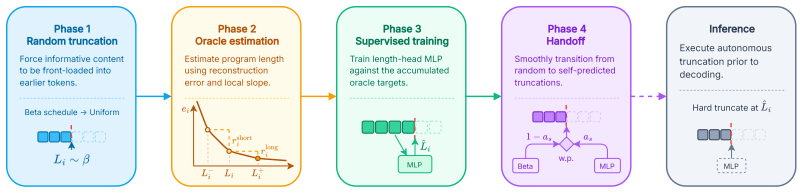
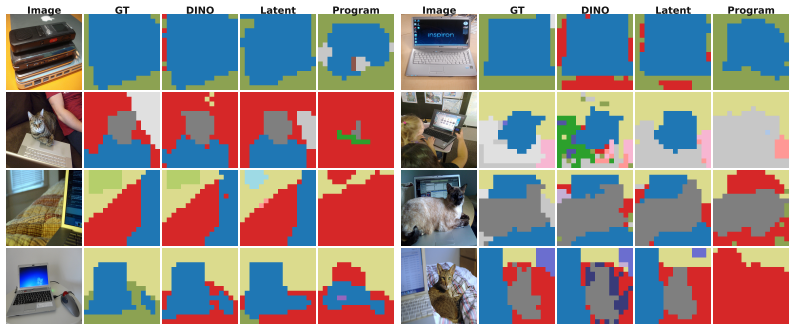
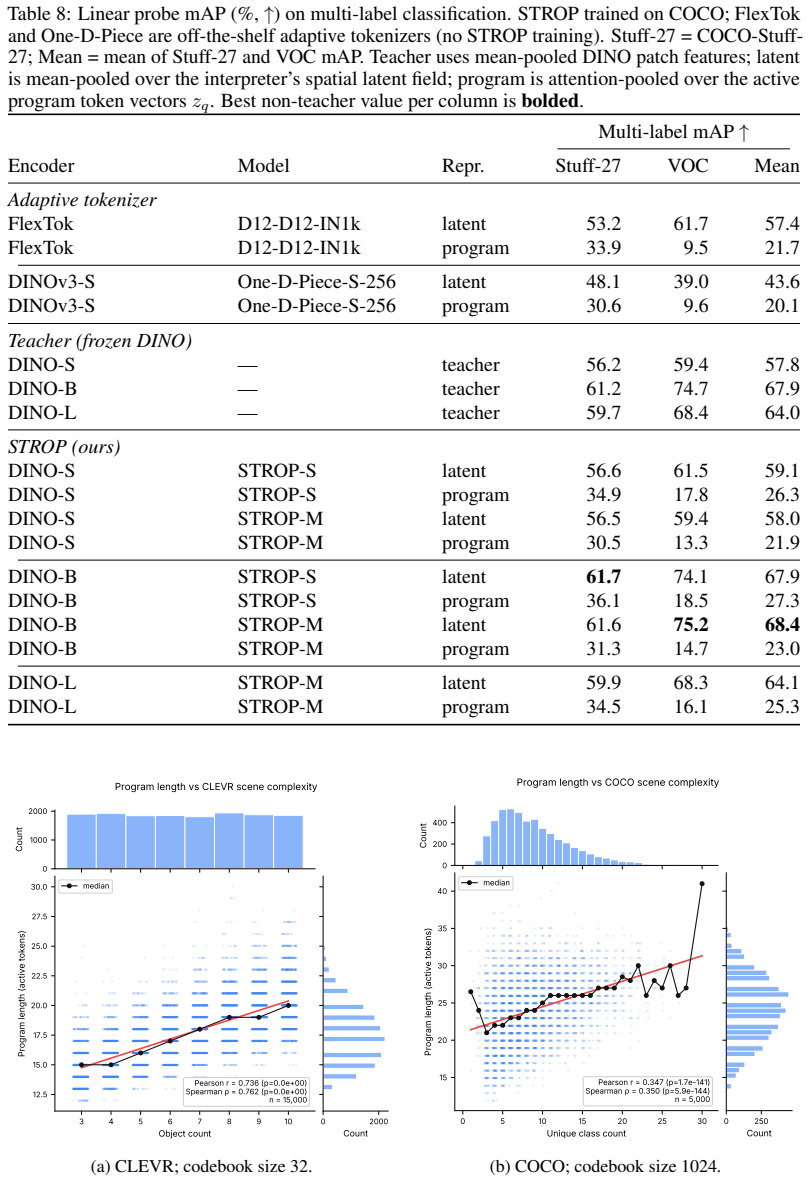
STROP forms structural scene representations and simultaneously learns how long an image's visual program should be. Using a four-phase curriculum supervised by local rate-distortion probes against frozen DINOv3 features, STROP optimizes a dedicated length head that estimates the active prefix length in a single forward pass. By bypassing pixel-level reconstruction gradients, the codebook is shaped entirely by the quality of higher-level latent representations. Program length grows with scene complexity, and signs of compositional structure emerge both in downstream dense-prediction transfer and in direct inspection of the learned code vocabulary.
What carries the argument
STROP length head, a module that estimates the active prefix length of the visual program from rate-distortion quality measured on frozen DINOv3 features.
If this is right
- Program length increases with scene complexity.
- Compositional structure becomes visible upon inspection of the learned code vocabulary.
- Downstream dense-prediction tasks benefit from the learned structural codes.
- A single forward pass suffices to determine the appropriate program length for any image.
Where Pith is reading between the lines
- The same length-adaptation mechanism could be tested on video sequences to see whether it selects longer programs only for frames with changing structure.
- Because length is predicted from structural quality alone, the codes might serve as a more compact input for relational reasoning models than fixed-length tokenizers.
- Removing the curriculum phases one at a time would reveal which stage most strongly enforces the observed growth of program length with complexity.
Load-bearing premise
That local rate-distortion probes against frozen DINOv3 features provide a sufficient and unbiased supervision signal for shaping the codebook toward structure without any pixel-level reconstruction term.
What would settle it
Measuring whether estimated program lengths fail to increase when independent measures of scene complexity are increased, or whether downstream dense-prediction performance remains unchanged when the length head is removed.
Figures



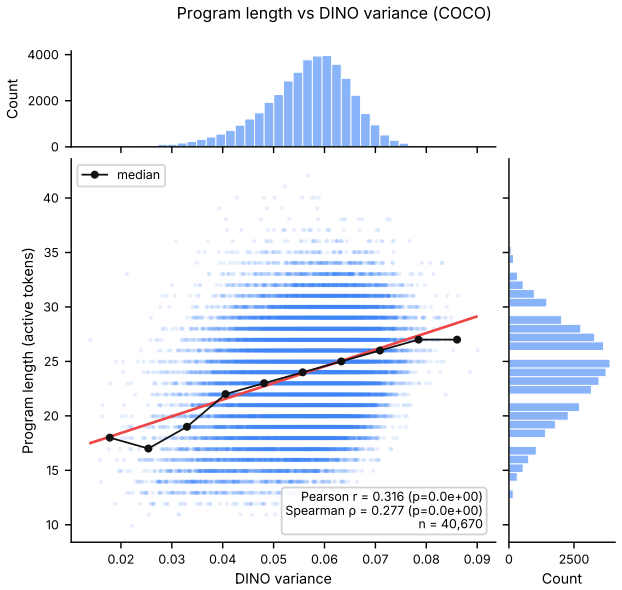
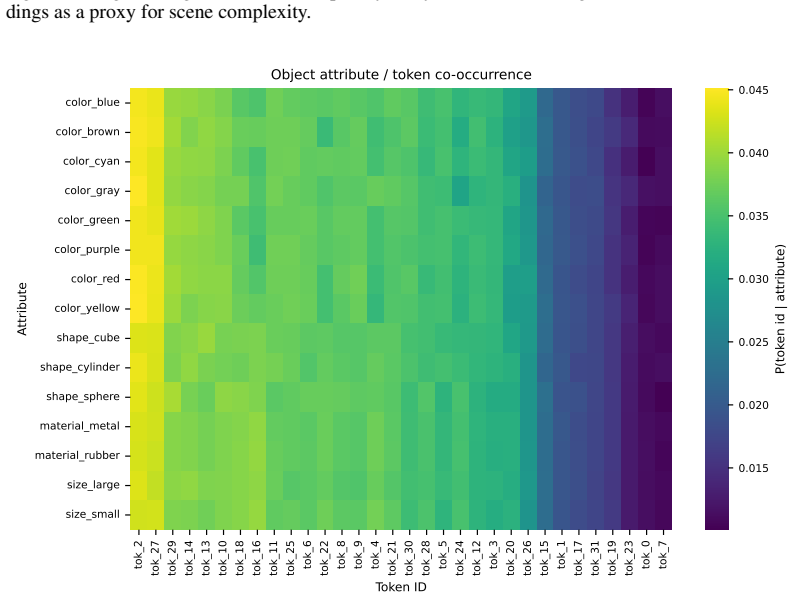
read the original abstract
Discrete visual tokenizers translate images into ordered sequences of codes, providing a natural representation for structural description of scenes. Yet existing adaptive tokenizers either require post-hoc search or select among a discrete set of pre-trained rates, rather than learning a continuous per-image sequence length coupled to the model and scene, and they typically train against pixel reconstruction, emphasizing texture rather than structure. We propose STROP, a discrete visual tokenizer architecture that forms structural scene representations and simultaneously learns how long an image's visual program should be. Using a four-phase curriculum supervised by local rate--distortion probes against frozen DINOv3 features, STROP optimizes a dedicated length head that estimates the active prefix length in a single forward pass. By bypassing pixel-level reconstruction gradients, the codebook is shaped entirely by the quality of higher-level latent representations. Program length grows with scene complexity, and signs of compositional structure emerge both in downstream dense-prediction transfer and in direct inspection of the learned code vocabulary.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes STROP, a discrete visual tokenizer that learns structural scene representations from images while simultaneously estimating a variable per-image program length via a dedicated length head. It uses a four-phase curriculum driven solely by local rate-distortion probes against frozen DINOv3 features, with no pixel-level reconstruction term, claiming that resulting program lengths grow with scene complexity and that compositional structure appears in downstream dense-prediction transfer and code-vocabulary inspection.
Significance. If the central claims hold after addressing robustness concerns, the work would offer a technically interesting route to adaptive-length structural tokenization that decouples length prediction from pixel texture. The single-forward-pass length head and curriculum design are concrete strengths that could be reusable; however, the absence of any reported invariance checks or alternative-extractor ablations limits the strength of the structural-compositionality claim.
major comments (2)
- [Abstract] Abstract: the claim that bypassing pixel reconstruction allows the codebook to be 'shaped entirely by the quality of higher-level latent representations' is load-bearing for the variable-length result, yet the manuscript provides no derivation or experiment showing that the local rate-distortion objective remains stable when the frozen extractor is replaced by a different model family.
- [Curriculum description (four-phase procedure)] Curriculum description (four-phase procedure): because both the rate-distortion supervision and the downstream evaluation probes are defined with respect to the same DINOv3 feature space, any DINO-specific bias in latent geometry would directly affect both the learned lengths and the reported transfer gains; a cross-extractor stability test is required to support the claim that lengths reflect scene complexity rather than extractor artifacts.
minor comments (2)
- The abstract states that 'signs of compositional structure emerge in direct inspection of the learned code vocabulary' without providing quantitative metrics, example programs, or inter-rater agreement on the inspected codes.
- Notation for the length head and the active-prefix selection mechanism is introduced without an accompanying equation or pseudocode block, making it difficult to verify that length estimation occurs in a single forward pass as claimed.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and for recognizing the strengths of the single-forward-pass length head and curriculum design. We address the two major comments below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that bypassing pixel reconstruction allows the codebook to be 'shaped entirely by the quality of higher-level latent representations' is load-bearing for the variable-length result, yet the manuscript provides no derivation or experiment showing that the local rate-distortion objective remains stable when the frozen extractor is replaced by a different model family.
Authors: The rate-distortion objective is formulated generally with respect to any provided frozen feature extractor and contains no pixel reconstruction term, so the codebook is optimized solely against the quality of the supplied latents. The four-phase curriculum applies the same local probes without reference to DINOv3-specific geometry beyond the features themselves. While we did not run replacement experiments with other families, the variable-length head is trained to predict active prefix length from the same rate signal, and the design is extractor-agnostic in principle. We will revise the abstract to state that the codebook is shaped by the chosen higher-level representations rather than claiming universality. revision: partial
-
Referee: [Curriculum description (four-phase procedure)] Curriculum description (four-phase procedure): because both the rate-distortion supervision and the downstream evaluation probes are defined with respect to the same DINOv3 feature space, any DINO-specific bias in latent geometry would directly affect both the learned lengths and the reported transfer gains; a cross-extractor stability test is required to support the claim that lengths reflect scene complexity rather than extractor artifacts.
Authors: We agree that shared use of DINOv3 for both supervision and evaluation creates a risk that reported lengths and transfer gains partly reflect DINOv3 biases. The downstream tasks themselves are standard benchmarks whose labels are independent of DINOv3, and length growth is observed qualitatively across diverse scenes. However, a full cross-extractor ablation would require repeating the entire four-phase curriculum with alternative frozen models, which was outside the scope of the submitted work. We will add an explicit limitations paragraph discussing extractor dependence and the scope of the current claims. revision: partial
- Empirical demonstration that the local rate-distortion objective and resulting program lengths remain stable when the frozen DINOv3 extractor is replaced by a different model family, as this requires new training runs not performed in the manuscript.
Circularity Check
No significant circularity detected
full rationale
The paper's derivation relies on an external frozen DINOv3 model to supply the rate-distortion supervision signal for the four-phase curriculum and length head; this external benchmark is independent of the STROP parameters being optimized. No self-citations, self-definitional equations, fitted inputs renamed as predictions, or ansatzes smuggled via prior author work appear in the abstract or described mechanism. The variable-length estimation and codebook shaping are therefore driven by an outside latent geometry rather than reducing to the model's own outputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption DINOv3 features provide a suitable structural supervision signal for rate-distortion probes
Reference graph
Works this paper leans on
-
[1]
Object-Centric Learning with Slot Attention
Francesco Locatello, Dirk Weissenborn, Thomas Unterthiner, Aravindh Mahendran, Georg Heigold, Jakob Uszkoreit, Alexey Dosovitskiy, and Thomas Kipf. Object-Centric Learning with Slot Attention. In: Advances in Neural Information Processing Systems (NeurIPS). 2020
2020
-
[2]
Illiterate DALL-E Learns to Compose
Gautam Singh, Fei Deng, and Sungjin Ahn. Illiterate DALL-E Learns to Compose. In:International Conference on Learning Representations (ICLR). 2022. arXiv:2110.11405
-
[3]
Bridging the Gap to Real-World Object-Centric Learning
Maximilian Seitzer, Max Horn, Andrii Zadaianchuk, Dominik Zietlow, Tianjun Xiao, Carl-Johann Simon-Gabriel, Tong He, Zheng Zhang, Bernhard Schölkopf, Thomas Brox, and Francesco Locatello. Bridging the Gap to Real-World Object-Centric Learning. In:International Conference on Learning Representations (ICLR). 2023. arXiv:2209.14860
-
[4]
Neural Programmer-Interpreters
Scott Reed and Nando de Freitas. Neural Programmer-Interpreters. In:International Conference on Learning Representations (ICLR). 2016. arXiv:1511.06279
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[5]
Jian Jia, Jingtong Gao, Ben Xue, Junhao Wang, Qingpeng Cai, Quan Chen, Xiangyu Zhao, Peng Jiang, and Kun Gai.From Principles to Applications: A Comprehensive Survey of Discrete Tokenizers in Generation, Comprehension, Recommendation, and Information Retrieval. 2025. arXiv:2502.12448 [cs.IR]. 10
-
[6]
Neural Discrete Representation Learning
Aäron van den Oord, Oriol Vinyals, and Koray Kavukcuoglu. Neural Discrete Representation Learning. In:Advances in Neural Information Processing Systems (NeurIPS). 2017
2017
-
[7]
Taming Transformers for High-Resolution Image Synthesis
Patrick Esser, Robin Rombach, and Björn Ommer. Taming Transformers for High-Resolution Image Synthesis. In:IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2021
2021
-
[8]
An Image is Worth 32 Tokens for Reconstruction and Generation
Qihang Yu, Mark Weber, Xueqing Deng, Xiaohui Shen, Daniel Cremers, and Liang-Chieh Chen. An Image is Worth 32 Tokens for Reconstruction and Generation. In:Advances in Neural Information Processing Systems (NeurIPS). 2024. arXiv:2406.07550
-
[9]
FlexTok: Resampling Images into 1D Token Sequences of Flexible Length
Roman Bachmann, Jesse Allardice, David Mizrahi, Enrico Fini, O ˘guzhan Fatih Kar, Elmira Amirloo, Alaaeldin El-Nouby, Amir Zamir, and Afshin Dehghan. FlexTok: Resampling Images into 1D Token Sequences of Flexible Length. In:International Conference on Machine Learning (ICML). 2025. arXiv: 2502.13967
-
[10]
One-D-Piece: Image Tokenizer Meets Quality-Controllable Compression
Keita Miwa, Kento Sasaki, Hidehisa Arai, Tsubasa Takahashi, and Yu Yamaguchi. One-D-Piece: Image Tokenizer Meets Quality-Controllable Compression. In:arXiv preprint arXiv:2501.10064(2025)
-
[11]
ElasticTok: Adaptive Tokenization for Image and Video
Wilson Yan, Matei Zaharia, V olodymyr Mnih, Pieter Abbeel, Aleksandra Faust, and Hao Liu. ElasticTok: Adaptive Tokenization for Image and Video. In:International Conference on Learning Representations (ICLR). 2025. arXiv:2410.08368
-
[12]
Shivam Duggal, Phillip Isola, Antonio Torralba, and William T. Freeman. Adaptive Length Image Tokenization via Recurrent Allocation. In:International Conference on Learning Representations (ICLR)
-
[13]
CAT: Content-Adaptive Image Tokenization
Junhong Shen, Kushal Tirumala, Michihiro Yasunaga, Ishan Misra, Luke Zettlemoyer, Lili Yu, and Chunting Zhou. CAT: Content-Adaptive Image Tokenization. In:arXiv preprint arXiv:2501.03120 (2025)
-
[14]
InfoTok: Adaptive Discrete Video Tokenizer via Information-Theoretic Compression
Haotian Ye, Qiyuan He, Jiaqi Han, Puheng Li, Jiaojiao Fan, Zekun Hao, Fitsum Reda, Yogesh Balaji, Huayu Chen, Sheng Liu, Angela Yao, James Zou, Stefano Ermon, Haoxiang Wang, and Ming-Yu Liu. InfoTok: Adaptive Discrete Video Tokenizer via Information-Theoretic Compression. In:arXiv preprint arXiv:2512.16975(2025)
-
[15]
BEiT v2: Masked Image Modeling with Vector-Quantized Visual Tokenizers
Zhiliang Peng, Li Dong, Hangbo Bao, Qixiang Ye, and Furu Wei. BEiT v2: Masked Image Modeling with Vector-Quantized Visual Tokenizers. In:arXiv preprint arXiv:2208.06366(2022)
-
[16]
Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think
Sihyun Yu, Sangkyung Kwak, Huiwon Jang, Jongheon Jeong, Jonathan Huang, Jinwoo Shin, and Saining Xie. Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think. In:International Conference on Learning Representations (ICLR). 2025. arXiv:2410.06940
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Masked Autoencoders Are Effective Tokenizers for Diffusion Models
Hao Chen, Yujin Han, Fangyi Chen, Xiang Li, Yidong Wang, Jindong Wang, Ze Wang, Zicheng Liu, Difan Zou, and Bhiksha Raj. Masked Autoencoders Are Effective Tokenizers for Diffusion Models. In: International Conference on Machine Learning (ICML). 2025. arXiv:2502.03444
-
[18]
Oriane Siméoni, Huy V . V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, Francisco Massa, Daniel Haziza, Luca Wehrstedt, Jianyuan Wang, Timothée Darcet, Théo Moutakanni, Leonel Sentana, Claire Roberts, Andrea Vedaldi, Jamie Tolan, John Brandt, Camille Couprie, Julie...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Generating Diverse High-Fidelity Images with VQ-V AE-2
Ali Razavi, Aäron van den Oord, and Oriol Vinyals. Generating Diverse High-Fidelity Images with VQ-V AE-2. In:Advances in Neural Information Processing Systems (NeurIPS). 2019
2019
-
[20]
Huiwen Chang, Han Zhang, Lu Jiang, Ce Liu, and William T. Freeman. MaskGIT: Masked Generative Image Transformer. In:IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2022
2022
-
[21]
Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction
Keyu Tian, Yi Jiang, Zehuan Yuan, Bingyue Peng, and Liwei Wang. Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction. In:Advances in Neural Information Processing Systems (NeurIPS). 2024. arXiv:2404.02905
-
[22]
Finite Scalar Quantization: VQ-VAE Made Simple
Fabian Mentzer, David Minnen, Eirikur Agustsson, and Michael Tschannen. Finite Scalar Quantization: VQ-V AE Made Simple. In:International Conference on Learning Representations (ICLR). 2024. arXiv: 2309.15505
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Autoregressive Image Generation Using Residual Quantization
Doyup Lee, Chiheon Kim, Saehoon Kim, Minsu Cho, and Wook-Shin Han. Autoregressive Image Generation Using Residual Quantization. In:IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2022
2022
-
[24]
Junkins, Dennis Duan, Aniketh Iger, Jerry W
Christopher Fifty, Ronald G. Junkins, Dennis Duan, Aniketh Iger, Jerry W. Liu, Ehsan Amid, Sebastian Thrun, and Christopher Ré. Restructuring Vector Quantization with the Rotation Trick. In:International Conference on Learning Representations (ICLR). 2025. arXiv:2410.06424. 11
-
[25]
Language Model Beats Diffusion - Tokenizer is key to visual generation
Lijun Yu, Jose Lezama, Nitesh Bharadwaj Gundavarapu, Luca Versari, Kihyuk Sohn, David Minnen, Yong Cheng, Agrim Gupta, Xiuye Gu, Alexander G Hauptmann, Boqing Gong, Ming-Hsuan Yang, Irfan Essa, David A Ross, and Lu Jiang. Language Model Beats Diffusion - Tokenizer is key to visual generation. In:The Twelfth International Conference on Learning Representat...
2024
- [26]
-
[27]
SoftVQ-V AE: Efficient 1-Dimensional Continuous Tokenizer
Hao Chen, Ze Wang, Xiang Li, Ximeng Sun, Fangyi Chen, Jiang Liu, Jindong Wang, Bhiksha Raj, Zicheng Liu, and Emad Barsoum. SoftVQ-V AE: Efficient 1-Dimensional Continuous Tokenizer. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2025. arXiv: 2412.10958
-
[28]
ImageFolder: Autoregressive Image Generation with Folded Tokens
Xiang Li, Kai Qiu, Hao Chen, Jason Kuen, Jiuxiang Gu, Bhiksha Raj, and Zhe Lin. ImageFolder: Autoregressive Image Generation with Folded Tokens. In: 2024. arXiv:2410.01756
-
[29]
Adaptive Computation Time for Recurrent Neural Networks
Alex Graves. Adaptive Computation Time for Recurrent Neural Networks. In:arXiv preprint arXiv:1603.08983(2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[30]
Pondernet: Learning to ponder.arXiv preprint arXiv:2107.05407,
Andrea Banino, Jan Balaguer, and Charles Blundell. PonderNet: Learning to Ponder. In:arXiv preprint arXiv:2107.05407(2021)
-
[31]
Sangmin Bae, Yujin Kim, Reza Bayat, Sungnyun Kim, Jiyoun Ha, Tal Schuster, Adam Fisch, Hrayr Harutyunyan, Ziwei Ji, Aaron Courville, and Se-Young Yun. Mixture-of-Recursions: Learning Dynamic Recursive Depths for Adaptive Token-Level Computation. In:Advances in Neural Information Processing Systems (NeurIPS). 2025. arXiv:2507.10524
-
[32]
Return of Unconditional Generation: A Self-Supervised Representation Generation Method
Tianhong Li, Dina Katabi, and Kaiming He. Return of Unconditional Generation: A Self-Supervised Representation Generation Method. In:Advances in Neural Information Processing Systems (NeurIPS)
-
[33]
arXiv preprint arXiv:2504.10483 (2025)
Xingjian Leng, Jaskirat Singh, Yunzhong Hou, Zhenchang Xing, Saining Xie, and Liang Zheng. REPA-E: Unlocking V AE for End-to-End Tuning with Latent Diffusion Transformers. In:IEEE/CVF International Conference on Computer Vision (ICCV). 2025. arXiv:2504.10483
-
[34]
Reconstruction vs
Jingfeng Yao and Xinggang Wang. Reconstruction vs. Generation: Taming Optimization Dilemma in Latent Diffusion Models. In:IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
-
[35]
Latent Denoising Makes Good Visual Tokenizers
Jiawei Yang, Tianhong Li, Lijie Fan, Yonglong Tian, and Yue Wang. Latent Denoising Makes Good Visual Tokenizers. In:arXiv preprint arXiv:2507.15856(2025)
-
[36]
SlotDiffusion: Object-Centric Generative Modeling with Diffusion Models
Ziyi Wu, Jingyu Hu, Wuyue Lu, Igor Gilitschenski, and Animesh Garg. SlotDiffusion: Object-Centric Generative Modeling with Diffusion Models. In:Advances in Neural Information Processing Systems (NeurIPS). 2023. arXiv:2305.11281
-
[37]
Xin Wen, Bingchen Zhao, Ismail Elezi, Jiankang Deng, and Xiaojuan Qi. “Principal Components” Enable a New Language of Images. In:IEEE/CVF International Conference on Computer Vision (ICCV). 2025. arXiv:2503.08685
-
[38]
How Diffusion Models Learn to Factorize and Compose
Qiyao Liang, Ziming Liu, Mitchell Ostrow, and Ila Fiete. How Diffusion Models Learn to Factorize and Compose. In:Advances in Neural Information Processing Systems (NeurIPS). 2024. arXiv: 2408.13256
-
[39]
Maya Okawa, Ekdeep Singh Lubana, Robert P. Dick, and Hidenori Tanaka. Compositional Abili- ties Emerge Multiplicatively: Exploring Diffusion Models on a Synthetic Task. In:arXiv preprint arXiv:2310.09336(2023)
-
[40]
Disentangled Latent Representations of Images with Atomic Autoencoders
Alasdair Newson and Yann Traonmilin. Disentangled Latent Representations of Images with Atomic Autoencoders. In:Sampling Theory and Applications Conference (SampTA). 2023
2023
-
[41]
End-to-End Object Detection with Transformers
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-End Object Detection with Transformers. In:European Conference on Computer Vision (ECCV). 2020
2020
-
[42]
Perceiver: General Perception with Iterative Attention
Andrew Jaegle, Felix Gimeno, Andrew Brock, Andrew Zisserman, Oriol Vinyals, and João Carreira. Perceiver: General Perception with Iterative Attention. In:International Conference on Machine Learning (ICML). 2021
2021
-
[43]
Botvinick, Andrew Zisserman, Oriol Vinyals, and João Carreira
Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, and João Carreira. Perceiver IO: A General Architecture for Structured Inputs & Outputs. In:International Conference on Learn...
2022
-
[44]
Everingham, S
M. Everingham, S. M. A. Eslami, L. Van Gool, C. K. I. Williams, J. Winn, and A. Zisserman. The Pascal Visual Object Classes Challenge: A Retrospective. In:International Journal of Computer Vision111.1 (Jan. 2015), pp. 98–136. 12
2015
-
[45]
Holger Caesar, Jasper Uijlings, and Vittorio Ferrari.COCO-Stuff: Thing and Stuff Classes in Context
-
[46]
arXiv:1612.03716 [cs.CV]
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
Semantic understanding of scenes through the ade20k dataset
Bolei Zhou, Hang Zhao, Xavier Puig, Tete Xiao, Sanja Fidler, Adela Barriuso, and Antonio Torralba. Semantic understanding of scenes through the ade20k dataset. In:International Journal of Computer Vision127.3 (2019), pp. 302–321
2019
-
[48]
The Cityscapes Dataset for Semantic Urban Scene Understanding
Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Rodrigo Benen- son, Uwe Franke, Stefan Roth, and Bernt Schiele. The Cityscapes Dataset for Semantic Urban Scene Understanding. In:Proc. of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2016
2016
-
[49]
Indoor Segmentation and Support Inference from RGBD Images
Pushmeet Kohli Nathan Silberman Derek Hoiem and Rob Fergus. Indoor Segmentation and Support Inference from RGBD Images. In:ECCV. 2012
2012
-
[50]
ImageNet: A large- scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. ImageNet: A large-scale hierar- chical image database. In:2009 IEEE Conference on Computer Vision and Pattern Recognition. 2009, pp. 248–255.DOI:10.1109/CVPR.2009.5206848
-
[51]
Microsoft COCO: Common Objects in Context
Tsung-Yi Lin, Michael Maire, Serge J. Belongie, Lubomir D. Bourdev, Ross B. Girshick, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C. Lawrence Zitnick. Microsoft COCO: Common Objects in Context. In:CoRRabs/1405.0312 (2014). arXiv:1405.0312
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[52]
CLEVR: A Diagnostic Dataset for Compositional Language and Elementary Visual Reasoning
Justin Johnson, Bharath Hariharan, Laurens van der Maaten, Li Fei-Fei, C. Lawrence Zitnick, and Ross B. Girshick. CLEVR: A Diagnostic Dataset for Compositional Language and Elementary Visual Reasoning. In:CoRRabs/1612.06890 (2016). arXiv:1612.06890. 13 A Adaptive program-length curriculum details This appendix gives the full parameterization of the adapti...
work page internal anchor Pith review Pith/arXiv arXiv 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.