CAREF: Calibration-Aware Regularization for Explanation Faithfulness Without Rationale Supervision
Pith reviewed 2026-06-29 14:39 UTC · model grok-4.3
The pith
CAREF introduces a single unified loss that combines entropy calibration and token sparsity to jointly optimize LLM accuracy and explanation faithfulness without rationale supervision.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
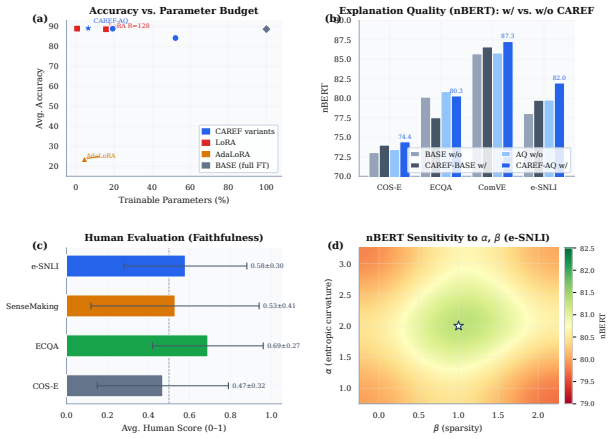
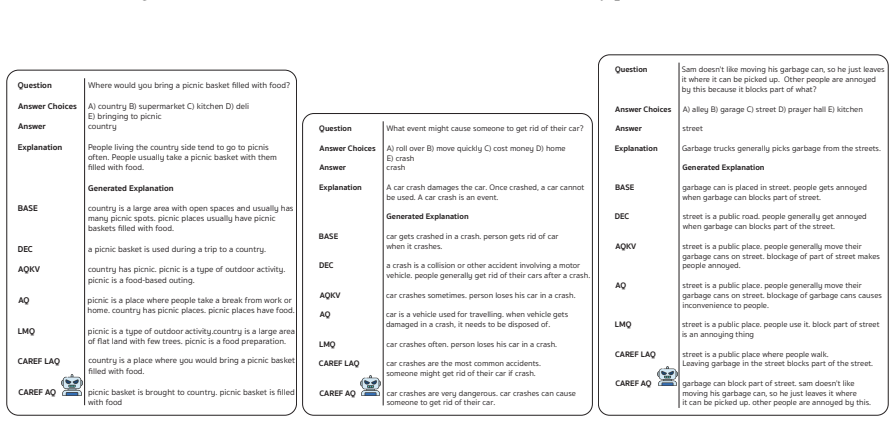
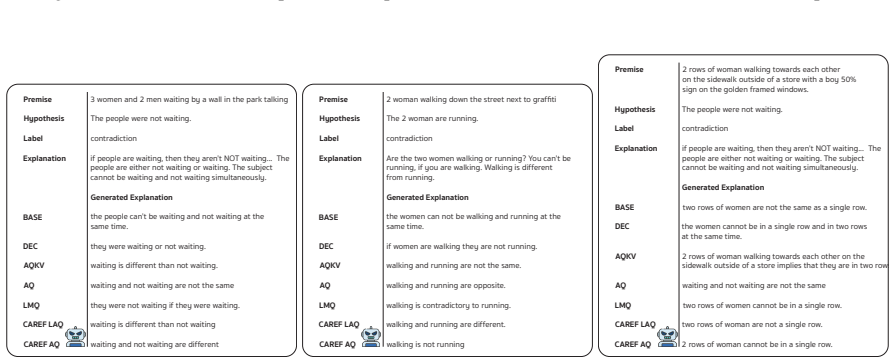
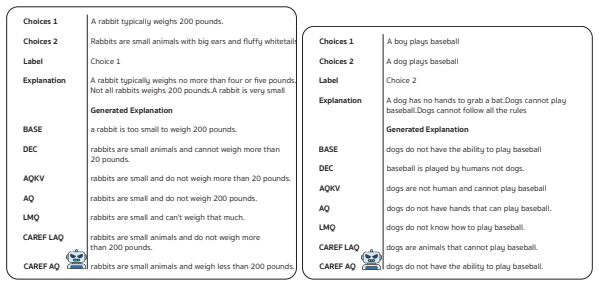
CAREF couples entropy-based calibration with token-level sparsity control through a single unified loss, the Calibration-Aware Regularization for Explanation Faithfulness (LSCED), without requiring rationale supervision. This enables joint optimization of predictive accuracy and explanation faithfulness for interpretable LLM fine-tuning, and the CAREF-AQ variant attains the best average accuracy (89.04) and explanation alignment (81.00 nBERT) using only 6.43 percent of trainable parameters while outperforming LoRA and AdaLoRA on four NLE benchmarks.
What carries the argument
The LSCED loss, which unifies entropy-based calibration and token-level sparsity regularization into one training objective to control explanation quality.
If this is right
- Achieves state-of-the-art average accuracy of 89.04 and explanation alignment of 81.00 nBERT across COS-E, ECQA, ComVE, and e-SNLI.
- Requires training only 6.43 percent of model parameters while exceeding LoRA and AdaLoRA performance.
- Eliminates the need for rationale supervision during fine-tuning.
- Unifies entropy and sparsity regularization inside a single objective for the first time in this setting.
Where Pith is reading between the lines
- The same loss structure could be tested on decoder-only models to check whether the gains transfer beyond encoder-decoder architectures like Flan-T5.
- Removing the need for rationale labels may allow scaling explanation training to larger unlabeled corpora.
- The calibration-sparsity coupling might generalize to other generation tasks where output conciseness and confidence calibration matter.
Load-bearing premise
The LSCED loss can be optimized jointly for predictive accuracy and explanation faithfulness without any rationale supervision.
What would settle it
Training the same model on the same benchmarks with the calibration and sparsity terms removed from the loss and measuring whether explanation alignment scores drop below the reported 81.00 nBERT.
Figures

read the original abstract
We introduce CAREF, a parameter-efficient fine-tuning framework that jointly optimizes predictive accuracy and explanation faithfulness via calibration-aware regularization. At its core, CAREF couples entropy-based calibration with token-level sparsity control through a single unified loss, the Calibration-Aware Regularization for Explanation Faithfulness (LSCED), without requiring rationale supervision. Evaluated on four NLE benchmarks (COS-E, ECQA, ComVE, e-SNLI) with Flan-T5, our lightweight CAREF-AQ variant attains the best average accuracy (89.04) and explanation alignment (81.00 nBERT) using only 6.43% of trainable parameters, outperforming LoRA and AdaLoRA. To our knowledge, CAREF is the first method to unify entropy and sparsity regularization in a single training objective for interpretable LLM fine-tuning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CAREF, a parameter-efficient fine-tuning framework for LLMs that jointly optimizes predictive accuracy and explanation faithfulness without rationale supervision. Its core is the LSCED loss, which couples entropy-based calibration with token-level sparsity control in a single unified objective. On four NLE benchmarks (COS-E, ECQA, ComVE, e-SNLI) using Flan-T5, the lightweight CAREF-AQ variant reports the best average accuracy (89.04) and explanation alignment (81.00 nBERT) while using only 6.43% of trainable parameters, outperforming LoRA and AdaLoRA. The work claims to be the first to unify entropy and sparsity regularization for interpretable LLM fine-tuning.
Significance. If the central claims hold after verification, the result would be significant for parameter-efficient interpretable fine-tuning: it offers a supervision-free route to improved explanation alignment via a lightweight unified loss, with strong reported efficiency gains over standard PEFT baselines. The unification of calibration and sparsity terms in one objective, if shown to causally improve faithfulness metrics rather than just post-hoc alignment, would address a practical gap in NLE methods.
major comments (2)
- [Abstract] Abstract: The central claim that LSCED delivers explanation faithfulness (rather than artifacts that score well on post-hoc nBERT) rests on the untested assumption that entropy calibration plus token sparsity suffice as proxies; no derivation, ablation against sufficiency/comprehensiveness, or perturbation-based faithfulness tests are referenced to establish the causal link.
- [Abstract] Abstract: The reported performance numbers (89.04 avg accuracy, 81.00 nBERT at 6.43% params) are given without error bars, statistical tests, or details on how the four-benchmark average was computed, so it is impossible to assess whether the gains over LoRA/AdaLoRA are robust or load-bearing for the superiority claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract claims and result reporting. We address each major comment below and outline planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that LSCED delivers explanation faithfulness (rather than artifacts that score well on post-hoc nBERT) rests on the untested assumption that entropy calibration plus token sparsity suffice as proxies; no derivation, ablation against sufficiency/comprehensiveness, or perturbation-based faithfulness tests are referenced to establish the causal link.
Authors: LSCED is derived from the joint objective of minimizing predictive entropy (for calibration) while enforcing token-level sparsity, with the explicit goal of improving explanation faithfulness in a no-rationale-supervision setting. nBERT is used as the evaluation metric because it directly measures alignment with human rationales on the NLE benchmarks without requiring additional supervision during training. We acknowledge that the manuscript does not include explicit ablations using sufficiency/comprehensiveness or perturbation-based tests. These metrics are typically defined with respect to ground-truth rationales and are therefore outside the core no-supervision scope, but we agree a clarifying discussion would strengthen the presentation. In revision we will expand the methods section with a short derivation of the LSCED terms and add a limitations paragraph noting the reliance on nBERT while referencing related faithfulness literature. revision: partial
-
Referee: [Abstract] Abstract: The reported performance numbers (89.04 avg accuracy, 81.00 nBERT at 6.43% params) are given without error bars, statistical tests, or details on how the four-benchmark average was computed, so it is impossible to assess whether the gains over LoRA/AdaLoRA are robust or load-bearing for the superiority claim.
Authors: We agree that the abstract numbers should be accompanied by measures of variability and transparency on aggregation. The reported figures are means across the four benchmarks (COS-E, ECQA, ComVE, e-SNLI), with each benchmark result itself averaged over three random seeds. In the revised manuscript we will (i) report standard deviations, (ii) explicitly state the averaging procedure, and (iii) include paired statistical significance tests against LoRA and AdaLoRA in the main results table; the abstract will either retain the point estimates with a reference to the table or be updated with the additional statistics. revision: yes
Circularity Check
No circularity: empirical method with defined loss and benchmark results
full rationale
The paper defines a new unified loss LSCED combining entropy calibration and token sparsity, applies it in parameter-efficient fine-tuning without rationale supervision during training, and reports empirical accuracy/alignment numbers on four benchmarks. No equations reduce a claimed prediction to a fitted parameter by construction, no self-citation chain justifies a uniqueness theorem, and no ansatz is smuggled in; the central claims rest on experimental outcomes rather than definitional equivalence to inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
InAd- vances in Neural Information Processing Systems, volume 33, pages 1877–1901
Language models are few-shot learners. InAd- vances in Neural Information Processing Systems, volume 33, pages 1877–1901. Curran Associates, Inc. Oana-Maria Camburu, Eleonora Giunchiglia, Jakob Fo- erster, Thomas Lukasiewicz, and Phil Blunsom
1901
-
[2]
minimal sufficient subsets
The struggles of feature-based explanations: Shap- ley values vs. minimal sufficient subsets. InAAAI 2021 Workshop on Explainable Agency in Artificial Intelligence. Oana-Maria Camburu, Tim Rocktäschel, Thomas Lukasiewicz, and Phil Blunsom
2021
-
[3]
PaLM: Scaling Language Modeling with Pathways
Palm: Scaling language mod- eling with pathways.CoRR, abs/2204.02311. Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Sourab Mangrulkar, Sylvain Gugger, Lysandre Debut, Younes Belkada, and Sayak Paul
Few-shot parameter-efficient fine-tuning is better and cheaper than in-context learning.Ad- vances in Neural Information Processing Systems, 35:1950–1965. Sourab Mangrulkar, Sylvain Gugger, Lysandre Debut, Younes Belkada, and Sayak Paul
1950
-
[5]
InFindings of the Associa- tion for Computational Linguistics: NAACL 2022, pages 410–424, Seattle, United States
Few-shot self-rationalization with nat- ural language prompts. InFindings of the Associa- tion for Computational Linguistics: NAACL 2022, pages 410–424, Seattle, United States. Association for Computational Linguistics. Colin Raffel, Noam Shazeer, Adam Roberts, Kather- ine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu
2022
-
[6]
AdaLoRA: Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning
Adaptive budget allocation for parameter-efficient fine-tuning.arXiv preprint arXiv:2303.10512. 5 A Theoretical Justification ofL SCED A.1 Relationship to Classical Divergence Measures The design of LSCED is grounded in a principled generalization of classical information-theoretic regularizers. To see this, recall the standard KL divergence from a unifor...
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.