VibeSearchBench: Benchmarking Long-horizon Proactive Search in the Wild
Pith reviewed 2026-06-29 13:11 UTC · model grok-4.3
The pith
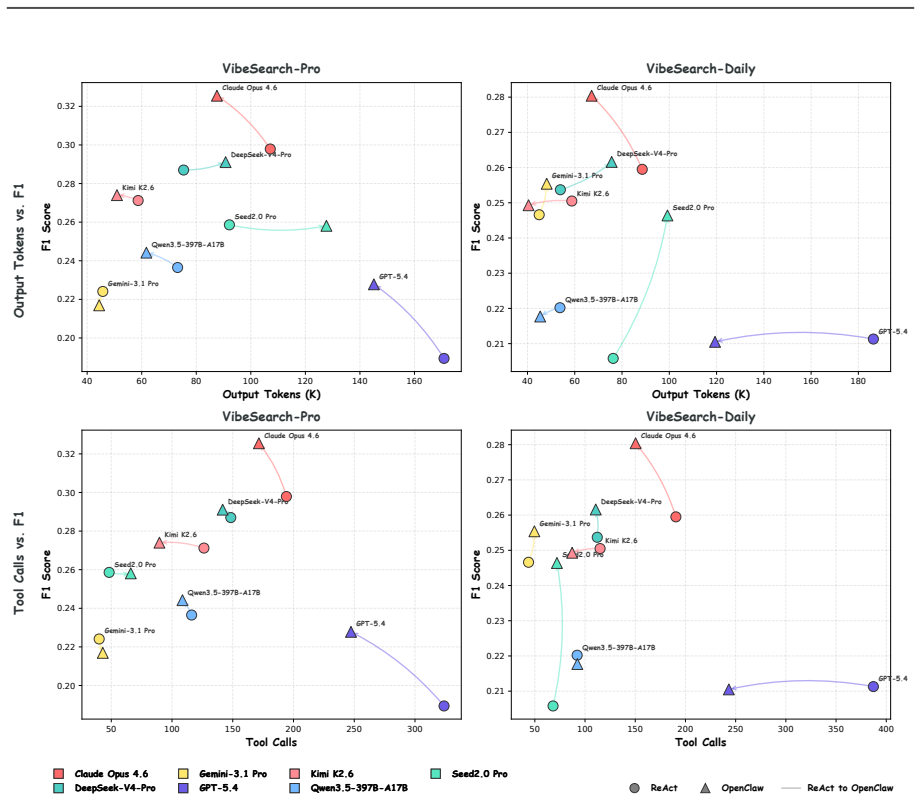
LLM agents remain inadequate for real-world vague multi-turn search, scoring at most 30.3 F1.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
VibeSearchBench shows that no tested model supports VibeSearch at usable levels. In VibeSearch users begin with underspecified goals and agents must elicit details over extended turns while assembling accurate structured knowledge; the benchmark measures this process directly and finds a maximum F1 of 30.30.
What carries the argument
VibeSearchBench, evaluated through a progressive-disclosure simulator and graph-matching against schema-free ground-truth knowledge graphs.
If this is right
- Agents must improve long-context reasoning to sustain coherent multi-turn refinement.
- Proactive intent elicitation needs to become a primary design target rather than an optional behavior.
- Structured knowledge construction from conversational input must advance before practical deployment.
- Single-turn and over-specified benchmarks systematically overestimate readiness for actual search use.
Where Pith is reading between the lines
- User satisfaction in deployed search may hinge more on handling ambiguity than on answering explicit queries.
- The simulator-plus-graph approach could transfer to other long-horizon interactive tasks such as planning or tutoring.
- Closing the benchmark-to-experience gap would require new training signals that reward progressive disclosure and knowledge assembly.
Load-bearing premise
The 200 manually curated tasks and the progressive-disclosure simulator plus graph-matching evaluation accurately reflect real-world user search behavior and satisfaction gaps.
What would settle it
A study in which models scoring below 35 F1 on the benchmark nevertheless produce high real-user satisfaction in uncontrolled multi-turn searches would indicate the tasks or simulator do not capture the intended gap.
Figures


read the original abstract
LLM-based agents score well on search benchmarks, yet real users consistently find results unsatisfying, revealing a persistent evaluation-experience gap. We attribute this gap to existing benchmarks' reliance on over-specified queries, single-turn interactions, and fixed-schema evaluation, none of which reflect real search behavior where users and agents collaboratively refine vague intent through multi-turn dialogue. We term this paradigm VibeSearch and introduce VibeSearchBench, a benchmark comprising 200 manually curated bilingual (Chinese and English) tasks across 20 domains, split into VibeSearch-Pro (professional) and VibeSearch-Daily (daily-life) subsets. Each task pairs a user persona with a schema-free ground-truth knowledge graph, and is evaluated through a progressive-disclosure user simulator and a graph-matching evaluation framework. We benchmark seven frontier models under both the ReAct framework and the OpenClaw agent harness. Results show that all models remain substantially inadequate for VibeSearch (best F1: 30.30), highlighting the need for fundamental advances in long-context reasoning, proactive intent elicitation, and structured knowledge construction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces VibeSearchBench to address an evaluation-experience gap in LLM agent search benchmarks. It defines the VibeSearch paradigm as multi-turn collaborative refinement of vague intents and presents a benchmark of 200 manually curated bilingual tasks across 20 domains (split into professional and daily-life subsets). Each task pairs a persona with a schema-free ground-truth knowledge graph and is evaluated via a progressive-disclosure user simulator plus graph-matching F1. Seven frontier models are tested under ReAct and OpenClaw, with the best reported F1 of 30.30, from which the authors conclude that current models are substantially inadequate and that fundamental advances in long-context reasoning, proactive intent elicitation, and structured knowledge construction are required.
Significance. If the simulator and graph-matching metric are shown to track real user satisfaction, the benchmark could usefully redirect research away from over-specified single-turn tasks toward realistic long-horizon proactive search. The work supplies a concrete testbed and reproducible harness that could support follow-on model development.
major comments (2)
- [Abstract / Evaluation] Abstract and Evaluation section: The headline claim that all models remain substantially inadequate (best F1 30.30) is load-bearing on the assertion that the progressive-disclosure simulator plus graph-matching F1 accurately reflects real-world user satisfaction gaps. No human correlation data, inter-rater reliability statistics for the 200 KG constructions, or ablation showing that simulator trajectories produce satisfaction distributions matching real multi-turn search logs are supplied; without such evidence the inadequacy conclusion does not follow from the reported numbers.
- [Benchmark Construction] Benchmark Construction section: The 200 tasks are described as manually curated with persona+schema-free KG pairs, yet no details on curation protocol, domain coverage criteria, or validation that the tasks instantiate the claimed vague-intent multi-turn behavior are given. This directly affects whether the performance gap generalizes beyond the specific 200 instances.
minor comments (2)
- [Abstract] The abstract states results for both ReAct and OpenClaw but does not indicate whether the reported best F1 aggregates across frameworks or reports the stronger of the two; clarify in the results table.
- [Evaluation Framework] Notation for the graph-matching F1 (precision/recall over KG nodes/edges) should be defined explicitly with an equation or pseudocode in the evaluation framework section.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting important aspects of validation and reproducibility in VibeSearchBench. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and Evaluation section: The headline claim that all models remain substantially inadequate (best F1 30.30) is load-bearing on the assertion that the progressive-disclosure simulator plus graph-matching F1 accurately reflects real-world user satisfaction gaps. No human correlation data, inter-rater reliability statistics for the 200 KG constructions, or ablation showing that simulator trajectories produce satisfaction distributions matching real multi-turn search logs are supplied; without such evidence the inadequacy conclusion does not follow from the reported numbers.
Authors: We agree that the manuscript does not include human correlation data or ablations against real user logs, so the claim of real-world inadequacy rests on the design rationale of the simulator and metric rather than direct empirical validation. The progressive-disclosure approach and graph-matching F1 were chosen to measure collaborative refinement of vague intents in a schema-free setting, which we view as a necessary step beyond existing single-turn benchmarks. We will revise the Evaluation and Limitations sections to explicitly discuss this gap, qualify the conclusions as applying to performance on the proposed benchmark, and outline directions for future human studies. We will not add new empirical correlation results, as none were collected. revision: partial
-
Referee: [Benchmark Construction] Benchmark Construction section: The 200 tasks are described as manually curated with persona+schema-free KG pairs, yet no details on curation protocol, domain coverage criteria, or validation that the tasks instantiate the claimed vague-intent multi-turn behavior are given. This directly affects whether the performance gap generalizes beyond the specific 200 instances.
Authors: We acknowledge that the current description of task curation is high-level. The 200 tasks were created manually by the authors with explicit attention to ensuring initial user intents are vague and require multi-turn elicitation. We will expand the Benchmark Construction section to include the curation protocol (domain selection for balance across professional and daily-life categories, persona-KG pairing guidelines, and internal checks for multi-turn potential). This addition will improve reproducibility without altering the reported results. revision: yes
- Human correlation data, inter-rater reliability statistics for the 200 KG constructions, or ablations matching simulator trajectories to real multi-turn search logs, as these were not part of the original study and cannot be supplied in revision.
Circularity Check
No circularity in benchmark construction or evaluation
full rationale
The paper presents an empirical benchmark (VibeSearchBench) with 200 manually curated tasks, a progressive-disclosure simulator, and graph-matching F1 evaluation. No derivation chain, first-principles prediction, or fitted parameter is claimed; results are direct model runs on the benchmark. No self-citations are load-bearing, and the central claim (model inadequacy at F1 30.30) does not reduce to any input by construction. The work is self-contained as a standard benchmark study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 200 tasks and progressive-disclosure simulator reflect real search behavior where users refine vague intent through multi-turn dialogue.
invented entities (1)
-
VibeSearch paradigm
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Deep research system card,
OpenAI. Deep research system card, . URL https://cdn.openai.com/deep-research-system-card. pdf
-
[2]
Tongyi DeepResearch Technical Report
Tongyi DeepResearch Team, Baixuan Li, Bo Zhang, Dingchu Zhang, Fei Huang, Guangyu Li, Guoxin Chen, Huifeng Yin, Jialong Wu, Jingren Zhou, Kuan Li, Liangcai Su, Litu Ou, Liwen Zhang, Pengjun Xie, Rui Ye, Wenbiao Yin, Xinmiao Yu, Xinyu Wang, Xixi Wu, Xuanzhong Chen, Yida Zhao, Zhen Zhang, Zhengwei Tao, Zhongwang Zhang, Zile Qiao, Chenxi Wang, Donglei Yu, Ga...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
BrowseComp: A Simple Yet Challenging Benchmark for Browsing Agents
Jason Wei, Zhiqing Sun, Spencer Papay, Scott McKinney, Jeffrey Han, Isa Fulford, Hyung Won Chung, Alex Tachard Passos, William Fedus, and Amelia Glaese. Browsecomp: A simple yet challenging benchmark for browsing agents, 2025. URLhttps://arxiv.org/abs/2504.12516
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Widesearch: Benchmarking agentic broad info-seeking, 2025
Ryan Wong, Jiawei Wang, Junjie Zhao, Li Chen, Yan Gao, Long Zhang, Xuan Zhou, Zuo Wang, Kai Xiang, Ge Zhang, Wenhao Huang, Yang Wang, and Ke Wang. Widesearch: Benchmarking agentic broad info-seeking, 2025. URLhttps://arxiv.org/abs/2508.07999
-
[5]
Llm-wikirace benchmark: How far can llms plan over real-world knowledge graphs?,
Juliusz Ziomek, William Bankes, Lorenz Wolf, Shyam Sundhar Ramesh, Xiaohang Tang, and Ilija Bogunovic. Llm-wikirace benchmark: How far can llms plan over real-world knowledge graphs?,
-
[6]
URLhttps://arxiv.org/abs/2602.16902
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Hendryx, Brad Kenstler, and Bing Liu
Manasi Sharma, Chen Bo Calvin Zhang, Chaithanya Bandi, Clinton Wang, Ankit Aich, Huy Nghiem, Tahseen Rabbani, Ye Htet, Brian Jang, Sumana Basu, Aishwarya Balwani, Denis Peskoff, Marcos Ayestaran, Sean M. Hendryx, Brad Kenstler, and Bing Liu. Researchrubrics: A benchmark of prompts and rubrics for evaluating deep research agents, 2025. URLhttps://arxiv.org...
-
[8]
Qianyu Yang, Yang Liu, Jiaqi Li, Jun Bai, Hao Chen, Kaiyuan Chen, Tiliang Duan, Jiayun Dong, Xiaobo Hu, Zixia Jia, Yang Liu, Tao Peng, Yixin Ren, Ran Tian, Zaiyuan Wang, Yanglihong Xiao, Gang Yao, Lingyue Yin, Ge Zhang, Chun Zhang, Jianpeng Jiao, Zilong Zheng, and Yuan Gong. $onemillion-bench: How far are language agents from human experts?, 2026. URL htt...
-
[9]
Miroeval: Benchmarking multimodal deep research agents in process and outcome, 2026
Fangda Ye, Yuxin Hu, Pengxiang Zhu, Yibo Li, Ziqi Jin, Yao Xiao, Yibo Wang, Lei Wang, Zhen Zhang, Lu Wang, Yue Deng, Bin Wang, Yifan Zhang, Liangcai Su, Xinyu Wang, He Zhao, Chen Wei, Qiang Ren, Bryan Hooi, An Bo, Shuicheng Yan, and Lidong Bing. Miroeval: Benchmarking multimodal deep research agents in process and outcome, 2026. URLhttps://arxiv.org/abs/2...
-
[10]
URLhttps://openclaw.ai/
Openclaw — personal ai assistant. URLhttps://openclaw.ai/
-
[11]
URLhttps://hermes-agent.nousresearch.com/
Hermes agent. URLhttps://hermes-agent.nousresearch.com/
-
[12]
URLhttps://www.anthropic.com/product/claude-code
Claude code. URLhttps://www.anthropic.com/product/claude-code
-
[13]
Deepresearch bench: A comprehensive benchmark for deep research agents
Mingxuan Du, Benfeng Xu, Chiwei Zhu, Licheng Zhang, Xiaorui Wang, and Zhendong Mao. Deepresearch bench: A comprehensive benchmark for deep research agents. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id= hQ0K2Hhq7H
2026
-
[14]
Deepsearchqa: Bridging the comprehensiveness gap for deep research agents, 2026
Nikita Gupta, Riju Chatterjee, Lukas Haas, Connie Tao, Andrew Wang, Chang Liu, Hidekazu Oiwa, Elena Gribovskaya, Jan Ackermann, John Blitzer, Sasha Goldshtein, and Dipanjan Das. Deepsearchqa: Bridging the comprehensiveness gap for deep research agents, 2026. URL https: //arxiv.org/abs/2601.20975
-
[15]
Gisa: A benchmark for general information-seeking assistant, 2026
Yutao Zhu, Xingshuo Zhang, Maosen Zhang, Jiajie Jin, Liancheng Zhang, Xiaoshuai Song, Kangzhi Zhao, Wencong Zeng, Ruiming Tang, Han Li, Ji-Rong Wen, and Zhicheng Dou. Gisa: A benchmark for general information-seeking assistant, 2026. URLhttps://arxiv.org/abs/2602.08543
-
[16]
Interactcomp: Evaluating search agents with ambiguous queries, 2025
Mingyi Deng, Lijun Huang, Yani Fan, Jiayi Zhang, Fashen Ren, Jinyi Bai, Fuzhen Yang, Dayi Miao, Zhaoyang Yu, Yifan Wu, Yanfei Zhang, Fengwei Teng, Yingjia Wan, Song Hu, Yude Li, Xin Jin, Conghao Hu, Haoyu Li, Qirui Fu, Tai Zhong, Xinyu Wang, Xiangru Tang, Nan Tang, Chenglin Wu, and Yuyu Luo. Interactcomp: Evaluating search agents with ambiguous queries, 2...
-
[17]
Claw-Eval: Towards Trustworthy Evaluation of Autonomous Agents
Bowen Ye, Rang Li, Qibin Yang, Yuanxin Liu, Linli Yao, Hanglong Lv, Zhihui Xie, Chenxin An, Lei Li, Lingpeng Kong, Qi Liu, Zhifang Sui, and Tong Yang. Claw-eval: Towards trustworthy evaluation of autonomous agents, 2026. URLhttps://arxiv.org/abs/2604.06132
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
Yuxuan Zhang, Yubo Wang, Yipeng Zhu, Penghui Du, Junwen Miao, Xuan Lu, Wendong Xu, Yunzhuo Hao, Songcheng Cai, Xiaochen Wang, Huaisong Zhang, Xian Wu, Yi Lu, Minyi Lei, Kai Zou, Huifeng Yin, Ping Nie, Liang Chen, Dongfu Jiang, Wenhu Chen, and Kelsey R. Allen. Clawbench: Can ai agents complete everyday online tasks?, 2026. URLhttps://arxiv.org/abs/2604.08523
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
Wildclawbench, 2026
Shuangrui Ding, Xuanlang Dai, Long Xing, Shengyuan Ding, Ziyu Liu, Jingyi Yang, Penghui Yang, Zhixiong Zhang, Xilin Wei, Yubo Ma, Haodong Duan, Jing Shao, Jiaqi Wang, Dahua Lin, Kai Chen, and Yuhang Zang. Wildclawbench, 2026. URLhttps://github.com/InternLM/WildClawBench
2026
-
[20]
QwenClawBench: Real-user-distribution benchmark for openclaw agents, April 2026
Qwen Team and Alibaba Data. QwenClawBench: Real-user-distribution benchmark for openclaw agents, April 2026. URLgithub.com/SKYLENAGE-AI/QwenClawBench
2026
-
[21]
Pinchbench: Real-world benchmarks for ai coding agents, 2026
PinchBench Team. Pinchbench: Real-world benchmarks for ai coding agents, 2026. URL https: //github.com/pinchbench/skill
2026
-
[22]
ClawMark: A Living-World Benchmark for Multi-Turn, Multi-Day, Multimodal Coworker Agents
Fanqing Meng, Lingxiao Du, Zijian Wu, Guanzheng Chen, Xiangyan Liu, Jiaqi Liao, Chonghe Jiang, Zhenglin Wan, Jiawei Gu, Pengfei Zhou, Rui Huang, Ziqi Zhao, Shengyuan Ding, Ailing Yu, Bo Peng, Bowei Xia, Hao Sun, Haotian Liang, Ji Xie, Jiajun Chen, Jiajun Song, Liu Yang, Ming Xu, Qionglin Qiu, Runhao Fu, Shengfang Zhai, Shijian Wang, Tengfei Ma, Tianyi Wu,...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
Introducing claude opus 4.6
Anthropic. Introducing claude opus 4.6. URL https://www.anthropic.com/news/claude-opus-4-6
-
[24]
Gpt-5.4 thinking system card,
OpenAI. Gpt-5.4 thinking system card, . URL https://deploymentsafety.openai.com/ gpt-5-4-thinking/gpt-5-4-thinking.pdf
-
[25]
Gemini 3.1 promodel card
Google. Gemini 3.1 promodel card. URL https://storage.googleapis.com/deepmind-media/ Model-Cards/Gemini-3-1-Pro-Model-Card.pdf
-
[26]
Seed2.0 model card: Towards intelligence frontier for real-world complex- ity
Bytedance Seed. Seed2.0 model card: Towards intelligence frontier for real-world complex- ity. URL https://lf3-static.bytednsdoc.com/obj/eden-cn/lapzild-tss/ljhwZthlaukjlkulzlp/ seed2/0214/Seed2.0%20Model%20Card.pdf
-
[27]
Kimi k2.6: Advancing open-source coding
Moonshot AI. Kimi k2.6: Advancing open-source coding. URL https://www.kimi.com/blog/ kimi-k2-6
-
[28]
Deepseek-v4: Towards highly efficient million-token context intelligence
DeepSeek-AI. Deepseek-v4: Towards highly efficient million-token context intelligence. URL https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf
-
[29]
Qwen3.5: Towards native multimodal agents
Alibaba Qwen Team. Qwen3.5: Towards native multimodal agents. URL https://qwen.ai/blog? id=qwen3.5. 11 A Evaluation Details This appendix provides the formal definitions and implementation details of the graph-based evaluation framework described in Section 3.4. A.1 Triplet Recall For each triple e∗ ∈ E ∗ in the ground-truth graph G ∗, we use an LLM-as-ju...
-
[30]
A predicted triple directly expresses the same information
-
[31]
A predicted triple carries more information and subsumes the ground-truth triple
-
[32]
Multiple predicted triples collectively cover the ground-truth triple’s information
-
[33]
name": "search
Multiple predicted triples can be composed through explicit relations already present in the predicted graph to derive the ground-truth triple. Triplet recall is defined as the fraction of covered ground-truth triples: Triplet Recall= |{e∗ ∈ E ∗ |covered(e ∗, ˆG)}| |E ∗| (1) A.2 Triplet Precision During recall evaluation, the LLM judge simultaneously reco...
2025
-
[34]
Models mechani- cally extract citation information that falls entirely outside the user’s information needs
Bibliographic metadata( pages, volume, DOI, volume/page): invalidity ≥98%. Models mechani- cally extract citation information that falls entirely outside the user’s information needs. This is the primary driver of Claude Opus 4.6’s anomalously low Precision (0.137 on Pro)
-
[35]
Subjective assessments( significance, structural innovation , core_contribution): invalidity ≥95%. Models inject evaluative judgments about concept importance rather than extracting factual information, producing self-generated assessments with no grounding in the user’s search intent
-
[36]
assistant proactively asks about X
Extraneous knowledge( appellate_body_judge, suited merger structure ): invalidity 100%. Gemini-3.1 Pro generates triples from parametric knowledge that were never retrieved through search (potentially accurate but not requested by the user). Finally, output format failures cause catastrophic zero-F1 results. Seed2.0 Pro accounts for 28 zero-F1 20 Table 18...
-
[37]
Discovered Entities: All specific entities such as products, brands, goods, institutions, and people found during the research -- including entities explored in intermediate turns
-
[38]
Yes" or
Attributes relevant to user needs in any turn: For each entity, extract every attribute dimension related to any of the user's questions throughout the entire conversation. # Rules - Be exhaustive: Extract all relevant triples from every turn of the conversation. - Extract only what the user asked for: Only extract triples related to the information needs...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.