Same Question, Different Source, Different Answer: Auditing Source-Dependence in Medical Multi-Source RAG
Pith reviewed 2026-06-29 12:19 UTC · model grok-4.3
The pith
Multi-source RAG systems produce different answers to the same medical question depending on the institutional source retrieved, so evaluation must shift from single-answer correctness to inter-source relationships.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In transplant patient education, where institutional handbooks demonstrably disagree, grounding generation in different sources produces conflicting answers to identical questions. Auditing therefore requires measuring the relationship between those answers rather than checking against a single correct response; a structured-output judge assigns each pair one of five validated labels. At scale, stronger retrieval exposes substantially more disagreement than prior estimates had indicated, understating prevalence rather than intensity.
What carries the argument
A structured-output judge that assigns one of five validated labels to the relationship between answers generated from different sources.
If this is right
- Evaluation of multi-source RAG must include inter-source relationship labels in addition to correctness checks.
- The TransplantQA benchmark and HERO-QA strategy enable systematic auditing of source-dependence in medical QA.
- The five-label taxonomy provides a reusable tool for quantifying disagreement between grounded answers.
- The auditing framework transfers directly to legal and educational RAG systems that draw from multiple institutional sources.
Where Pith is reading between the lines
- RAG interfaces could surface multiple source-grounded answers and flag conflicts rather than synthesize a single response.
- Persistent source-dependence may indicate underlying inconsistencies in the source documents themselves.
- The taxonomy could be extended to measure whether disagreement correlates with downstream user confusion or harm.
Load-bearing premise
The structured-output judge reliably assigns the five validated labels to inter-source answer relationships without systematic bias or need for human verification on the TransplantQA data.
What would settle it
A human re-labeling of a random sample of TransplantQA answer pairs that shows low agreement with the judge, or an experiment in which improved retrieval does not increase the observed disagreement rate.
Figures
read the original abstract
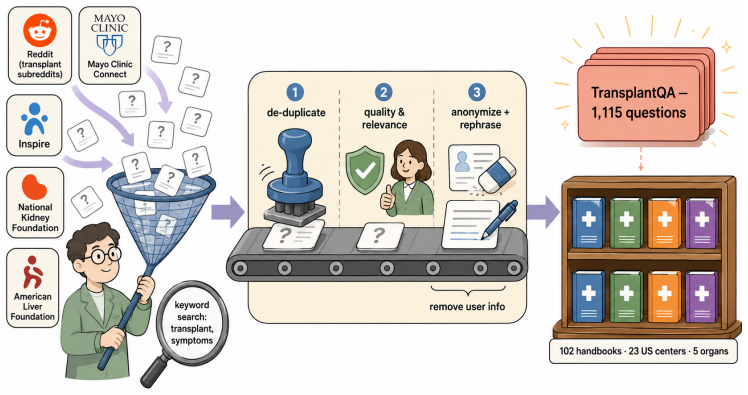
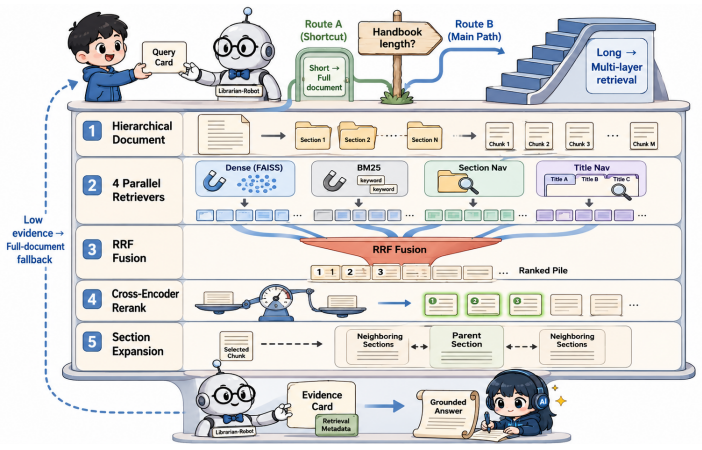
A retrieval-augmented generation (RAG) system deployed over a multi-author institutional corpus can give a different answer to the same question depending on which source it retrieves -- a failure mode the dominant single-gold-answer paradigm cannot diagnose. We argue that source-dependence is a missing axis of NLP evaluation, and that auditing it means shifting the unit of evaluation from answer correctness to the inter-source relationship. We make this concrete in transplant patient education, where institutional sources demonstrably disagree, releasing three artefacts: TransplantQA, a benchmark of real patient questions, each answered by grounding generation in multiple institutional handbooks as candidate sources; HERO-QA, a hierarchical retrieval strategy that grounds and audits each answer; and a structured-output judge that scores inter-source relationships on a validated 5-label taxonomy. At scale, better retrieval reveals far more disagreement than prior estimates suggested -- understating its prevalence, not its intensity. The framework is domain-agnostic and transfers to legal and educational RAG: measuring source-dependence is a responsibility for deployed multi-source NLP generally.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript argues that source-dependence is an overlooked failure mode in multi-source RAG systems, where the same question can yield different answers depending on the retrieved source. To address this, the authors release TransplantQA, a benchmark of patient questions grounded in multiple institutional handbooks; HERO-QA, a hierarchical retrieval strategy; and a structured-output judge using a 5-label taxonomy for inter-source relationships. They claim that at scale, better retrieval exposes substantially more disagreement than prior single-gold-answer evaluations suggested, understating prevalence rather than intensity. The approach is presented as domain-agnostic.
Significance. If the empirical findings hold, the work makes a valuable contribution by identifying a missing evaluation axis for RAG systems and providing concrete auditing tools. The emphasis on inter-source relationships over correctness to a single answer is a useful reframing for domains with inherent source disagreement, such as medicine. Releasing the benchmark, retrieval method, and judge supports reproducibility and extension to other fields like law and education.
major comments (1)
- [Abstract and Methods (structured-output judge)] Abstract and Methods (structured-output judge): The claim that the 5-label taxonomy is 'validated' and that better retrieval reveals more disagreement rests on the judge's assignments, yet no human verification, inter-annotator agreement rates, or bias/error analysis is reported on TransplantQA instances. Without these, it is unclear whether the increase in detected disagreement is a property of the sources or an artifact of prompt sensitivity or label assignment on medical phrasing.
minor comments (2)
- [Abstract] The abstract states the framework 'transfers to legal and educational RAG' but provides no concrete transfer experiment or adaptation details.
- [Methods] Notation for the five labels in the taxonomy could be introduced with an explicit table or figure early in the paper to aid readability.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for stronger validation of the structured-output judge. We address this concern directly below.
read point-by-point responses
-
Referee: [Abstract and Methods (structured-output judge)] Abstract and Methods (structured-output judge): The claim that the 5-label taxonomy is 'validated' and that better retrieval reveals more disagreement rests on the judge's assignments, yet no human verification, inter-annotator agreement rates, or bias/error analysis is reported on TransplantQA instances. Without these, it is unclear whether the increase in detected disagreement is a property of the sources or an artifact of prompt sensitivity or label assignment on medical phrasing.
Authors: We agree that the initial manuscript does not report human verification, inter-annotator agreement, or a dedicated bias/error analysis of the judge on TransplantQA instances. The 5-label taxonomy was constructed iteratively with input from transplant clinicians to reflect observable inter-source relationships (full agreement, partial agreement, contradiction on key facts, etc.), but this design process and any associated checks were not documented with quantitative human evaluation in the submitted version. In the revision we will add a new subsection under Methods that reports: (1) a human annotation study on a random sample of 200 TransplantQA instances (two annotators with medical background), (2) inter-annotator agreement (Cohen's kappa) both on the 5-label taxonomy and on a collapsed 3-label version, and (3) an error analysis that compares judge outputs against human labels, including cases of prompt sensitivity tested across two prompt variants. This addition will allow readers to assess whether the reported increase in disagreement is driven by source content rather than judge artifacts. revision: yes
Circularity Check
Empirical auditing framework with no derivation chain or self-referential reductions
full rationale
The paper introduces TransplantQA, HERO-QA, and a structured-output judge as new empirical artifacts for auditing source-dependence in multi-source RAG. No equations, fitted parameters, predictions, or derivation steps appear in the abstract or described framework. Claims about disagreement prevalence rest on direct measurement from the released benchmark rather than any quantity defined in terms of itself or reduced by construction. No self-citation load-bearing steps, uniqueness theorems, or ansatzes are referenced in a way that would create circularity. This is a standard non-finding for an empirical auditing paper.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Institutional medical handbooks demonstrably disagree on answers to the same patient questions
- domain assumption A 5-label taxonomy can be validated for scoring inter-source answer relationships
invented entities (3)
-
TransplantQA benchmark
no independent evidence
-
HERO-QA hierarchical retrieval strategy
no independent evidence
-
Structured-output judge with 5-label taxonomy
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Early access
The Faiss library.IEEE Transactions on Big Data. Early access. Timnit Gebru, Jamie Morgenstern, Briana Vecchione, Jennifer Wortman Vaughan, Hanna Wallach, Hal Daumé III, and Kate Crawford. 2021. Datasheets for datasets.Communications of the ACM, 64(12):86– 92. Di Jin, Eileen Pan, Nassim Oufattole, Wei-Hung Weng, Hanyi Fang, and Peter Szolovits. 2021. What...
2021
-
[2]
InThe Thirteenth International Conference on Learning Representations
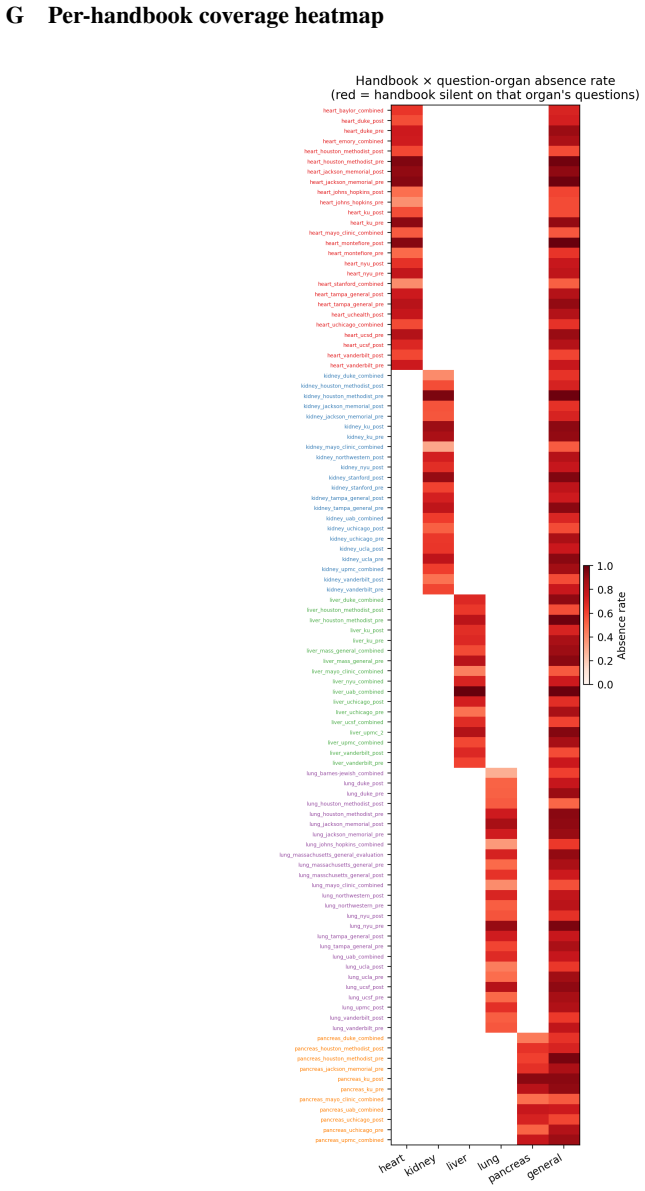
JudgeLM: Fine-tuned large language models are scalable judges. InThe Thirteenth International Conference on Learning Representations. 10 A Question sources and inclusion criteria The 1,115 released questions were drawn from an initial pool of 3,000+ candidates collected from four families of public, patient-facing sources. Table 4 reports the top-10 sourc...
2021
-
[3]
If the evidence answers the question, give the answer using only that evidence
-
[4]
If pages are unknown, cite the section heading only
Cite the supporting section heading, and page if provided. If pages are unknown, cite the section heading only
-
[5]
NOT ADDRESSED: This handbook does not contain information on this topic
If the evidence does not answer the question, respond exactly: "NOT ADDRESSED: This handbook does not contain information on this topic."
-
[6]
classification
Do not use outside medical knowledge. Do not fill gaps with general transplant advice. User: ## Handbook Context {context} ## Patient Question {question} Generation runs with greedy decoding (temperature 0), max_new_tokens=512, and <think>...</think>reasoning blocks stripped before the answer is persisted. E Judge prompt and output schema Our judge uses t...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.