CA-AC-MPC: CUDA-Accelerated Actor-Critic Model Predictive Control
Pith reviewed 2026-06-29 11:13 UTC · model grok-4.3
The pith
CUDA-accelerated actor-critic MPC matches state-of-the-art drone racing performance with far less training and inference time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that porting the differentiable MPC layer to CUDA produces a variant that significantly reduces end-to-end execution time while preserving the control performance of the baseline AC-MPC formulation, as demonstrated by state-of-the-art lap times and near-limit dynamic behaviour in agile drone racing simulations.
What carries the argument
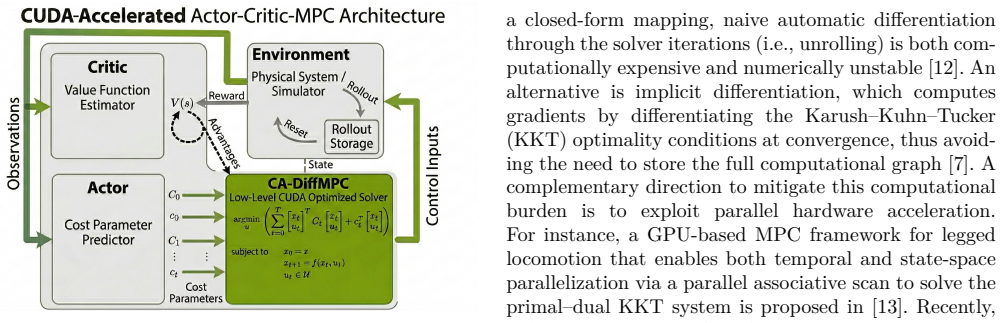
The CUDA-accelerated differentiable MPC layer that solves the optimization problem repeatedly in forward and backward passes during actor-critic training.
If this is right
- The approach achieves state-of-the-art lap times on the drone racing task.
- It exhibits near-limit dynamic behaviour.
- Training and inference times are markedly reduced.
- The control performance matches the baseline formulation.
Where Pith is reading between the lines
- Similar CUDA ports could speed up other learning-based control methods that rely on differentiable optimization.
- Reduced times might allow real-time adaptation or longer prediction horizons in MPC.
- This acceleration could make AC-MPC viable for hardware with limited compute resources.
Load-bearing premise
The repeated optimization inside the differentiable MPC layer can be moved to CUDA without altering convergence behavior, numerical stability, or the gradients required for actor-critic training.
What would settle it
Running the same drone racing simulation with both the original and CUDA versions and finding that the CUDA version yields worse lap times, unstable behavior, or fails to train properly.
Figures
read the original abstract
In the literature, actor-critic model predictive control (AC-MPC) integrates MPC with reinforcement learning to enable high-performance control of complex dynamical systems. However, its differentiable MPC layer requires repeatedly solving an optimization problem in both the forward and backward passes, leading to substantial training and inference latency. This paper tackles this bottleneck introducing a CUDA-accelerated variant that significantly reduces end-to-end execution time while preserving the control performance of the baseline formulation. Simulation results on an agile drone racing task show that our approach achieves state-of-the-art lap times and near-limit dynamic behaviour with markedly reduced training and inference time.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CA-AC-MPC, a CUDA-accelerated variant of actor-critic model predictive control (AC-MPC). It claims that porting the differentiable MPC layer to CUDA substantially reduces end-to-end training and inference latency while preserving the control performance of the baseline AC-MPC formulation. Simulation results on an agile drone racing task are presented to show state-of-the-art lap times and near-limit dynamic behavior.
Significance. If the CUDA port is shown to produce numerically equivalent forward solutions and back-propagated gradients, the work would address a key computational bottleneck in AC-MPC, enabling faster training cycles and lower-latency inference for high-performance robotic control. This could broaden the practical use of differentiable MPC within reinforcement learning pipelines for agile systems.
major comments (2)
- [Abstract] The central claim of performance preservation requires that the CUDA-accelerated differentiable MPC layer yields identical forward solutions and gradients to the baseline AC-MPC. The manuscript provides no residual checks, gradient-norm comparisons, or numerical equivalence tests between the two implementations.
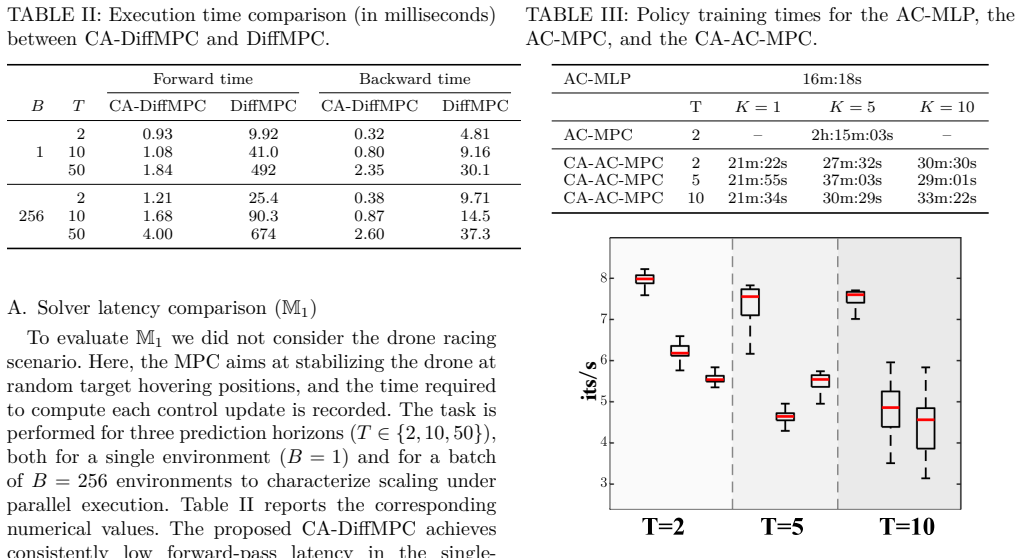
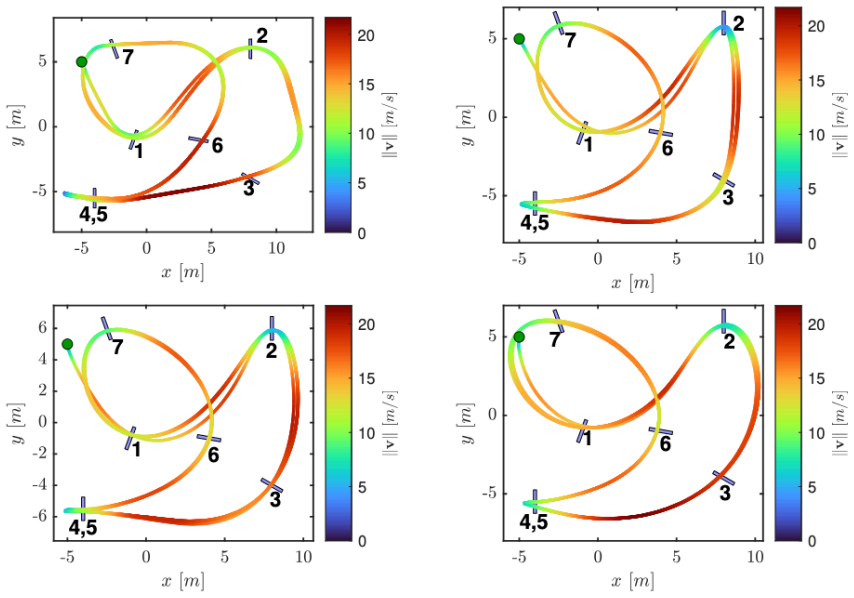
- [Simulation results] The simulation results claim state-of-the-art lap times and near-limit behavior, but supply no quantitative metrics, error bars, ablation studies on the CUDA port, or statistical comparisons that would substantiate the performance-preservation assertion.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for explicit numerical validation and quantitative performance metrics. We address each major comment below and will incorporate the suggested additions in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] The central claim of performance preservation requires that the CUDA-accelerated differentiable MPC layer yields identical forward solutions and gradients to the baseline AC-MPC. The manuscript provides no residual checks, gradient-norm comparisons, or numerical equivalence tests between the two implementations.
Authors: We agree that explicit numerical equivalence verification strengthens the central claim. In the revised version we will add a dedicated subsection with residual error norms between the CPU and CUDA forward passes, gradient-norm comparisons during back-propagation, and a table reporting maximum absolute differences across a representative set of states and horizons. These checks will be performed on the same random seeds used in the drone-racing experiments. revision: yes
-
Referee: [Simulation results] The simulation results claim state-of-the-art lap times and near-limit behavior, but supply no quantitative metrics, error bars, ablation studies on the CUDA port, or statistical comparisons that would substantiate the performance-preservation assertion.
Authors: We acknowledge the absence of statistical detail in the current draft. The revised manuscript will include a table of mean lap times and standard deviations over 20 independent training runs for CA-AC-MPC, the original AC-MPC, and relevant baselines; error bars on all trajectory and timing plots; and an ablation isolating the CUDA port (identical policy and MPC formulation, only the solver backend changed). Statistical significance will be reported via paired t-tests where appropriate. revision: yes
Circularity Check
No circularity: empirical implementation claim with independent validation
full rationale
The paper presents a CUDA port of an existing differentiable MPC layer inside an actor-critic controller. Its claims rest on measured reductions in training and inference latency together with simulation lap-time results on a drone-racing task. No equations, fitted parameters, or predictions are defined in terms of themselves; the performance-preservation statement is an empirical assertion, not a self-referential derivation. No self-citation chains, uniqueness theorems, or ansatzes are invoked as load-bearing steps. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Three-dimensional variable center of mass height biped walking using a new model and nonlinear model predictive control,
Z. Xie, Y. Wang, X. Luo, P. Arpenti, F. Ruggiero, and B. Sicil- iano, “Three-dimensional variable center of mass height biped walking using a new model and nonlinear model predictive control,” Mechanism and Machine Theory, vol. 197, p. 105651, 2024
2024
-
[2]
Model pre- dictive contouring control for time-optimal quadrotor flight,
A. Romero, S. Sun, P. Foehn, and D. Scaramuzza, “Model pre- dictive contouring control for time-optimal quadrotor flight,” IEEE Transactions on Robotics, vol. 38, no. 6, pp. 3340–3356, 2022
2022
-
[3]
Reaching the limit in autonomous racing: Opti- mal control versus reinforcement learning,
Y. Song, A. Romero, M. Müller, V. Koltun, and D. Scara- muzza, “Reaching the limit in autonomous racing: Opti- mal control versus reinforcement learning,” Science Robotics, vol. 8, no. 82, p. eadg1462, 2023
2023
-
[4]
Champion-level drone racing using deep reinforcement learning,
E. Kaufmann, L. Bauersfeld, A. Loquercio, M. Müller, V. Koltun, and D. Scaramuzza, “Champion-level drone racing using deep reinforcement learning,” Nature, vol. 620, no. 7976, pp. 982–987, 2023
2023
-
[5]
Actor-critic model predictive control,
A. Romero, Y. Song, and D. Scaramuzza, “Actor-critic model predictive control,” in 2024 IEEE International Conference on Robotics and Automation (ICRA), pp. 14777–14784, 2024
2024
-
[6]
OptNet: Differentiable optimiza- tion as a layer in neural networks,
B. Amos and J. Z. Kolter, “OptNet: Differentiable optimiza- tion as a layer in neural networks,” in International Conference on Machine Learning (ICML), pp. 136–145, 2017
2017
-
[7]
Differentiable MPC for end-to-end planning and con- trol,
B. Amos, I. D. J. Rodriguez, J. Sacks, B. Boots, and J. Z. Kolter, “Differentiable MPC for end-to-end planning and con- trol,” in Advances in Neural Information Processing Systems (NeurIPS), vol. 31, 2018
2018
-
[8]
mpc.pytorch: A fast and differentiable model predictive con- trol solver for pytorch (v0.0.6)
B. Amos, I. Jimenez, J. Sacks, B. Boots, and J. Z. Kolter, “mpc.pytorch: A fast and differentiable model predictive con- trol solver for pytorch (v0.0.6). ” https://github.com/locuslab/ mpc.pytorch/tree/v0.0.6, 2024. GitHub repository, MIT Li- cense. Accessed: 2026-02-14
2024
-
[9]
Actor–critic model predictive control: Differentiable opti- mization meets reinforcement learning for agile flight,
A. Romero, E. Aljalbout, Y. Song, and D. Scaramuzza, “Actor–critic model predictive control: Differentiable opti- mization meets reinforcement learning for agile flight,” IEEE Transactions on Robotics, vol. 42, p. 673–692, 2026
2026
-
[10]
End-to-end training of deep visuomotor policies,
S. Levine, C. Finn, T. Darrell, and P. Abbeel, “End-to-end training of deep visuomotor policies,” Journal of Machine Learning Research, vol. 17, no. 39, pp. 1–40, 2016
2016
-
[11]
Neu- ral network dynamics for model-based deep reinforcement learning with model-free fine-tuning,
A. Nagabandi, G. Kahn, R. S. Fearing, and S. Levine, “Neu- ral network dynamics for model-based deep reinforcement learning with model-free fine-tuning,” in IEEE International Conference on Robotics and Automation (ICRA), 2018
2018
-
[12]
Differentiable convex optimization lay- ers,
A. Agrawal, B. Amos, S. Barratt, S. Boyd, S. Diamond, and J. Z. Kolter, “Differentiable convex optimization lay- ers,” in Advances in Neural Information Processing Systems (NeurIPS), vol. 32, 2019
2019
-
[13]
Primal-dual ilqr for gpu-accelerated learning and control in legged robots,
L. Amatucci, J. Sousa-Pinto, G. Turrisi, D. Orban, V. Bara- suol, and C. Semini, “Primal-dual ilqr for gpu-accelerated learning and control in legged robots,” IEEE Robotics and Automation Letters, vol. 11, no. 1, pp. 1010–1017, 2026
2026
-
[14]
Differentiable model predictive control on the GPU,
E. Adabag, M. Greiff, J. Subosits, and T. Lew, “Differen- tiable model predictive control on the gpu,” arXiv preprint arXiv:2510.06179, 2025
-
[15]
Borrelli, A
F. Borrelli, A. Bemporad, and M. Morari, Predictive Control for Linear and Hybrid Systems. Cambridge University Press, 2017
2017
-
[16]
Grne and J
L. Grne and J. Pannek, Nonlinear model predictive control: theory and algorithms. Springer Publishing Company, Incor- porated, 2013
2013
-
[17]
Ellis, J
M. Ellis, J. Liu, and P. D. Christofides, Economic Model Pre- dictive Control: Theory, Formulations and Chemical Process Applications. Advances in Industrial Control, Springer, 2017
2017
-
[18]
Findeisen, L
R. Findeisen, L. Grüne, and M. A. Müller, eds., Economic Model Predictive Control. Cham: Springer, 2017
2017
-
[19]
Reinforcement learning: An intro- duction,
R. Sutton and A. Barto, “Reinforcement learning: An intro- duction,” IEEE Transactions on Neural Networks, vol. 9, no. 5, pp. 1054–1054, 1998
1998
-
[20]
Accelerating pytorch with cuda graphs
PyTorch Blog, “Accelerating pytorch with cuda graphs. ”https: //pytorch.org/blog/accelerating-pytorch-with-cuda-graphs/ ,
-
[21]
Accessed: 2026-02-14
2026
-
[22]
Cuda semantics – pytorch documentation
PyTorch Contributors, “Cuda semantics – pytorch documentation. ” https://docs.pytorch.org/docs/stable/ notes/cuda.html, 2026. Accessed: 2026-02-14
2026
-
[23]
Control-limited differential dynamic programming,
Y. Tassa, N. Mansard, and E. Todorov, “Control-limited differential dynamic programming,” in IEEE International Conference on Robotics and Automation (ICRA), pp. 1168– 1175, 2014
2014
-
[24]
A survey on transformers in reinforcement learning,
W. Li, H. Luo, Z. Lin, C. Zhang, Z. Lu, and D. Ye, “A survey on transformers in reinforcement learning,” 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.