DiffSpot: Can VLMs Spot Fine-Grained Visual Differences in Web Interfaces?
Pith reviewed 2026-06-29 08:05 UTC · model grok-4.3
The pith
Vision-language models identify only 40.7% of true fine-grained changes in web interfaces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
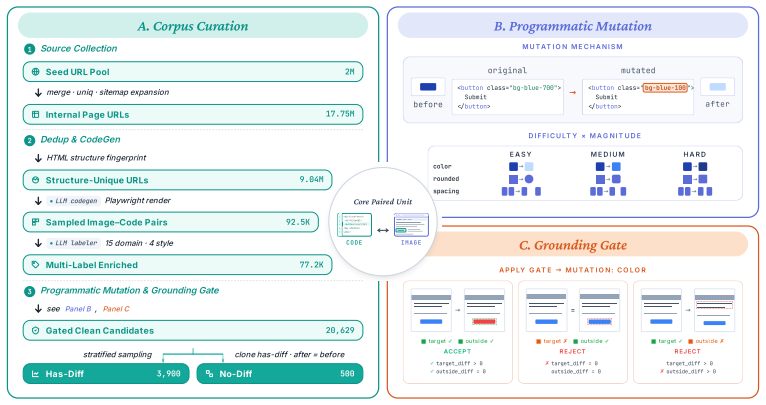
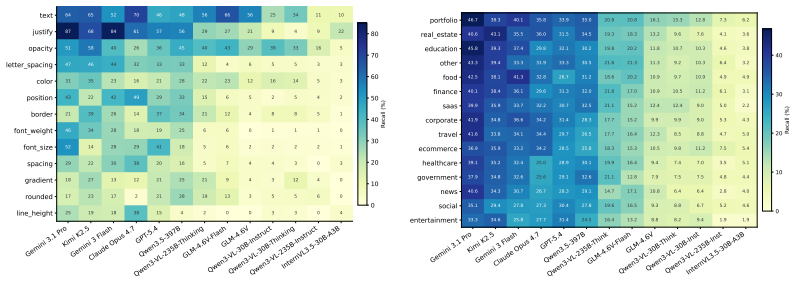
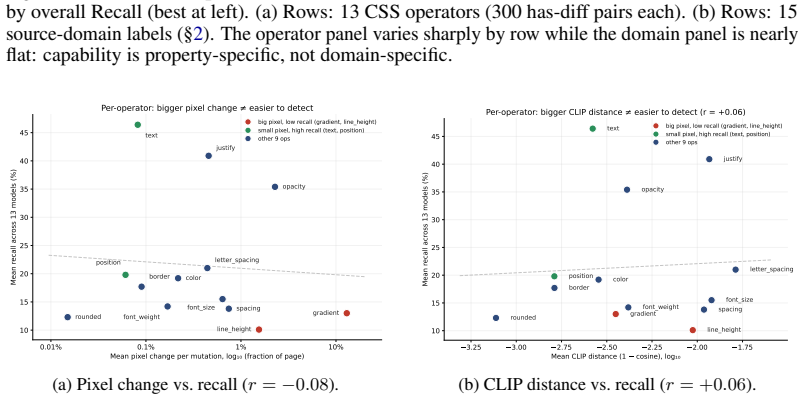
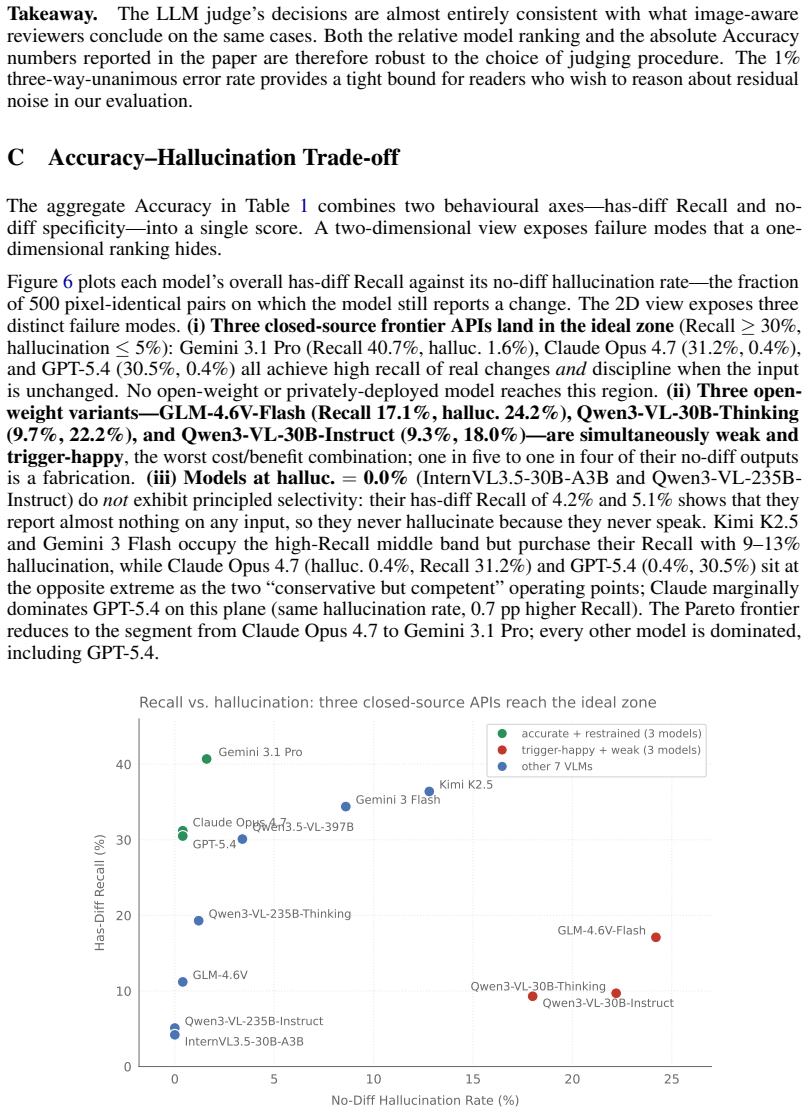
DiffSpot is a code-driven benchmark that constructs controlled image pairs by mutating a single CSS property of a target element in self-contained HTML, re-rendering the page, and retaining only pairs where the pixel difference is confined to the target element via a grounding gate. Evaluating 13 frontier VLMs zero-shot on 4,400 pairs reveals that the best model identifies only 40.7% of true changes, with Hard-tier Recall below 23% for every model, and that recall varies strongly by CSS operator without reliable prediction from pixel magnitude or CLIP distance.
What carries the argument
DiffSpot benchmark of single CSS property mutations with grounding gate to isolate visual differences to the target element.
If this is right
- Recall is strongly dependent on the CSS property being mutated.
- Pixel magnitude and CLIP distance do not reliably predict model recall.
- VLMs need improved fine-grained perception capabilities for GUI agent applications.
- Current high-level image-text alignment does not ensure low-level visual difference detection.
Where Pith is reading between the lines
- Specialized training on isolated pixel changes could address the observed gaps.
- The benchmark's property-dependent difficulty suggests prioritizing data collection for low-performing CSS operators.
- Extending the method to multi-element changes could test robustness to more complex real-world scenarios.
- Integration with GUI agents might reveal whether low DiffSpot performance correlates with task failure rates.
Load-bearing premise
Single CSS property mutations in self-contained HTML, filtered by a grounding gate that confines pixel differences to the target element, produce image pairs that constitute a valid and generalizable test of fine-grained visual perception.
What would settle it
A finding that models with low DiffSpot recall achieve high accuracy on spotting differences in natural, multi-change web screenshots would indicate the benchmark does not capture the relevant perceptual skills.
Figures

read the original abstract
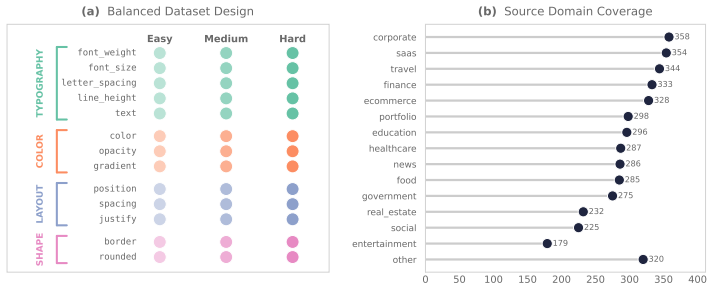
Vision-language models (VLMs) have made strong progress on high-level image-text alignment, yet their ability to perceive subtle visual differences remains limited. We study this problem in rendered web interfaces, where localized visual changes are both a diagnostic test of fine-grained perception and a practical requirement for GUI agents and design tools. We introduce \textbf{DiffSpot}, a code-driven benchmark for open-ended spot-the-difference on web interfaces. DiffSpot constructs controlled image pairs by mutating a single CSS property of a target element in self-contained HTML, re-rendering the page, and recording the changed property, element, and mutation magnitude. A grounding gate retains only pairs whose rendered pixel difference is confined to the target element. The benchmark contains 4{,}400 pairs, including 3{,}900 has-diff pairs balanced across 13 CSS-property operators and three difficulty tiers, plus 500 no-diff pairs for hallucination control. Evaluating 13 frontier VLMs zero-shot, we find that even the best model identifies only $40.7\%$ of true changes, with Hard-tier Recall below $23\%$ for every model. DiffSpot further shows that difficulty is strongly property-dependent: across CSS operators, neither pixel magnitude nor CLIP distance reliably predicts Recall.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DiffSpot, a benchmark for assessing vision-language models' ability to detect fine-grained visual differences in rendered web interfaces. It generates 4,400 image pairs by applying single CSS property mutations to self-contained HTML, re-rendering, and using a grounding gate to localize pixel changes to the target element. The benchmark includes has-diff pairs across 13 CSS operators and three difficulty tiers, plus no-diff pairs. Zero-shot evaluation of 13 frontier VLMs shows the best model achieving 40.7% recall on true changes, with hard-tier recall below 23% for all models. The work also finds that difficulty is property-dependent and not reliably predicted by pixel magnitude or CLIP distance.
Significance. If the benchmark construction provides a valid test of fine-grained perception, the results indicate substantial limitations in current VLMs for tasks requiring detection of subtle UI changes, which has implications for GUI agents and design tools. Strengths include the code-driven, controlled nature of the benchmark, the balance across properties and tiers, the inclusion of no-diff controls, and the observation that standard metrics do not predict performance. These elements make the benchmark potentially useful for future model development if its generalizability is established.
major comments (2)
- [Abstract] Abstract (benchmark construction): The central claim that VLMs have limited fine-grained perception on web interfaces (best recall 40.7%) depends on single-CSS-property mutations in self-contained HTML being a representative test. The construction excludes multi-element interactions, layout shifts, and content changes typical of live web pages. Without additional validation showing that low recall on these isolated mutations correlates with performance on more complex real-world diffs, the headline numbers may overstate the perceptual limitation.
- [Abstract] Abstract: The manuscript reports aggregate recall figures and tier-specific results but provides no details on the validation of the grounding gate, the criteria used to define the three difficulty tiers, or statistical controls. These elements are load-bearing for interpreting the property-dependent difficulty findings and the overall recall numbers.
minor comments (1)
- [Abstract] The abstract writes the benchmark size as '4{,}400'; this should follow standard notation as '4,400'.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and for recognizing the controlled design, balance across properties, and the finding that standard metrics do not predict performance. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract (benchmark construction): The central claim that VLMs have limited fine-grained perception on web interfaces (best recall 40.7%) depends on single-CSS-property mutations in self-contained HTML being a representative test. The construction excludes multi-element interactions, layout shifts, and content changes typical of live web pages. Without additional validation showing that low recall on these isolated mutations correlates with performance on more complex real-world diffs, the headline numbers may overstate the perceptual limitation.
Authors: DiffSpot is intentionally constructed as a minimal, code-driven diagnostic to isolate fine-grained perception of localized changes, which is a prerequisite capability for GUI agents and design tools. The single-property mutations combined with the grounding gate allow failures to be attributed specifically to perception rather than layout or content confounds. We do not claim the benchmark directly measures performance on arbitrary real-world diffs; however, consistent failure even on these isolated cases indicates fundamental limitations that would be expected to persist or worsen under more complex conditions. To clarify scope, we will add an explicit limitations paragraph discussing generalizability and the rationale for the controlled setting. revision: partial
-
Referee: [Abstract] Abstract: The manuscript reports aggregate recall figures and tier-specific results but provides no details on the validation of the grounding gate, the criteria used to define the three difficulty tiers, or statistical controls. These elements are load-bearing for interpreting the property-dependent difficulty findings and the overall recall numbers.
Authors: The manuscript body (Section 3) defines the grounding gate as retaining only pairs where pixel differences are confined to the target element and describes tier construction based on per-property visual impact and mutation magnitude. We agree, however, that the abstract is too concise and that expanded details on gate validation (e.g., inspection statistics), explicit tier criteria, and any statistical controls would strengthen interpretability. We will revise the methods section to include these additional descriptions and any supporting validation results. revision: yes
Circularity Check
No significant circularity; benchmark construction and evaluations are independent empirical steps
full rationale
The paper constructs DiffSpot via an explicit procedural pipeline (single CSS mutation in self-contained HTML, re-render, grounding gate to localize pixel change) and reports direct zero-shot recall measurements on the resulting 4400 pairs. These recall figures (40.7% best-model, <23% hard-tier) are straightforward counts against the generated test set rather than outputs of any fitted parameter, self-referential equation, or self-citation chain. No derivation reduces to its own inputs by construction, and the property-dependent difficulty finding is likewise an observation on the fixed benchmark. The work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Single CSS property mutations in self-contained HTML produce localized, controllable visual differences suitable for testing perception.
invented entities (1)
-
DiffSpot benchmark
no independent evidence
Reference graph
Works this paper leans on
-
[1]
arXiv:2510.22571. Junyang Wang, Yuhang Wang, Guohai Xu, Jing Zhang, Yukai Gu, Haitao Jia, Jiaqi Wang, Haiyang Xu, Ming Yan, Ji Zhang, and Jitao Sang. AMBER: An LLM-free multi-dimensional benchmark for MLLMs hallucination evaluation.arXiv preprint arXiv:2311.07397, 2023. Weiyun Wang, Zhangwei Gao, Lixin Gu, et al. Internvl3.5: Advancing open-source multimo...
-
[2]
What does the GT change describe (element, property, direction)?
-
[3]
Which parts of the VLM response could refer to this change? Quote the relevant text
-
[4]
reasoning
Apply the operator-specific principle above. Determine if the VLM’s description matches the ESSENCE or ACCEPT criteria. If no match, check whether it falls under REJECT or is simply unrelated. Step 2: Verdict. Assign one of: - correct: VLM identifies the GT element specifically AND describes a change matching the operator’s ACCEPT criteria. - wrong: VLM d...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.