Give it Space! Explicit Disentangling of Positional and Semantic Representations in Encoders
Pith reviewed 2026-06-29 07:22 UTC · model grok-4.3
The pith
Disentangling semantic and positional streams in Transformers preserves positional encodings and improves on 49 of 65 linguistic phenomena.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
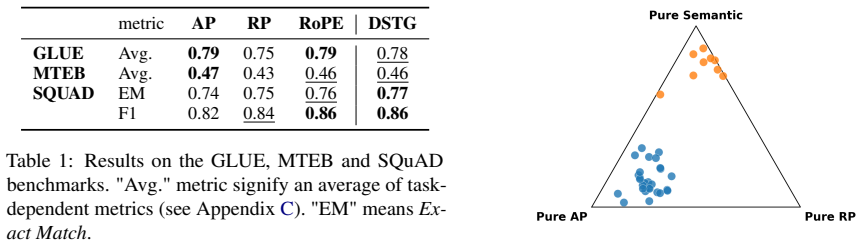
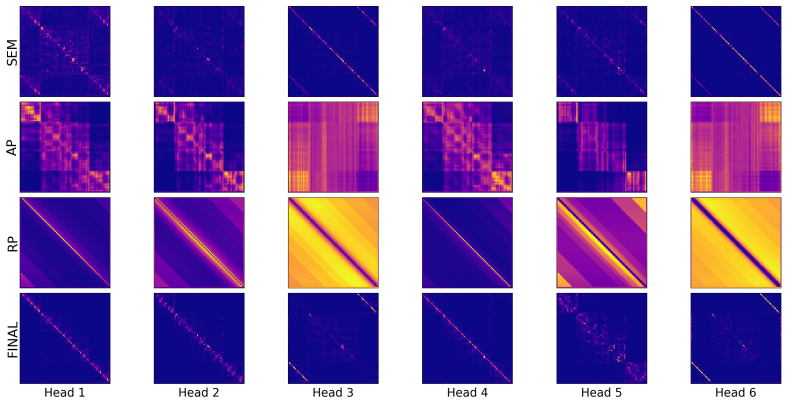
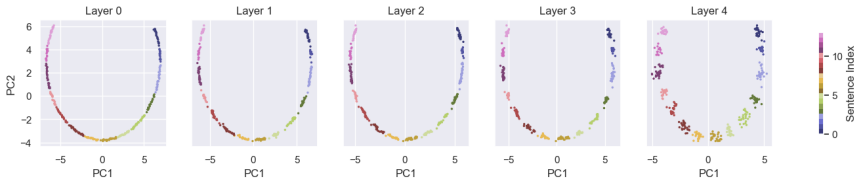
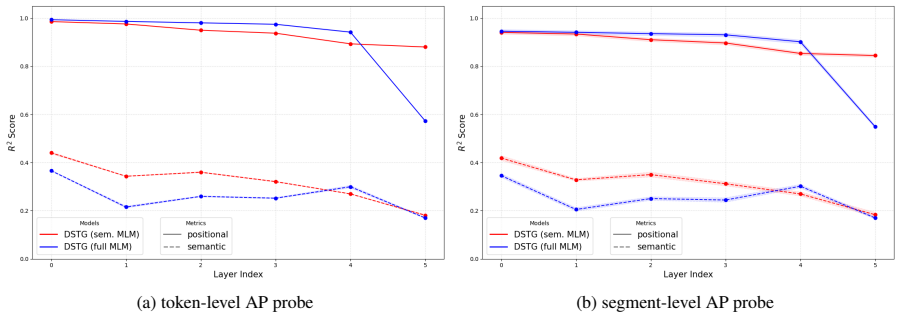
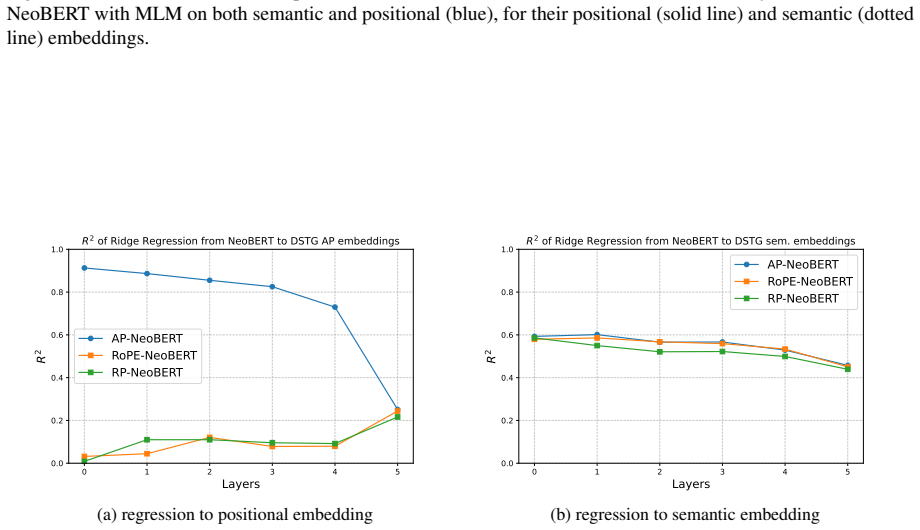
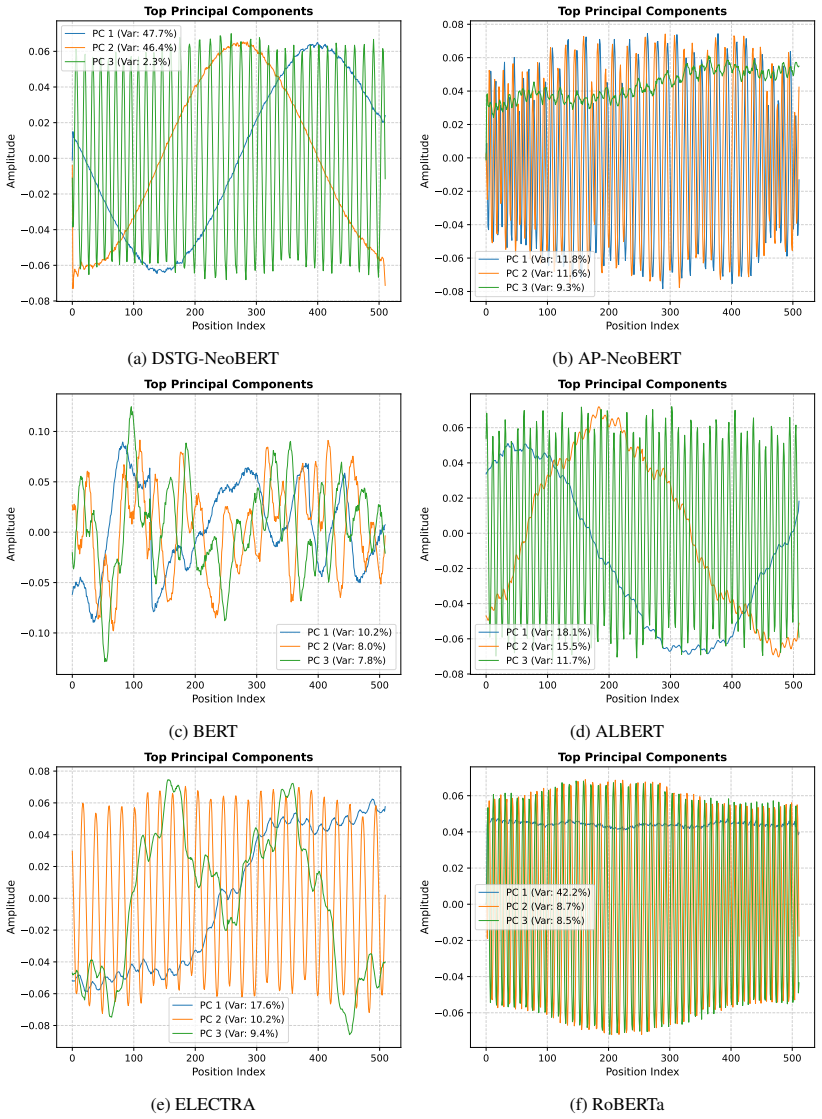
By processing semantic, absolute positional (AP), and relative positional (RP) signals in explicitly disentangled streams and restricting the MLM objective to the semantic stream, the isolated AP subspace collapses into a low-frequency two-dimensional manifold that captures the structure of the document, attention heads specialize into structure and semantic-oriented groups with RP supporting the latter, and the disentangled approach preserves positional encoding better than standard methods, improving linguistic representation on 49 of the 65 phenomena of the Flash-Holmes probing benchmark.
What carries the argument
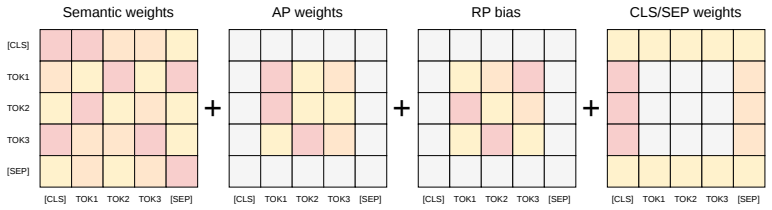
Three explicitly disentangled streams (semantic, absolute positional, relative positional) in an encoder Transformer with the MLM objective confined to the semantic stream.
If this is right
- The isolated absolute positional subspace spontaneously collapses into a low-frequency two-dimensional manifold capturing document structure.
- Attention heads specialize into structure-oriented and semantic-oriented groups, with relative positional encodings supporting semantic processing.
- Standard positional encodings such as RoPE and RP only weakly encode macroscopic structure, while entangled absolute positional encodings lose it in final layers under MLM pressure.
- The disentangled approach improves performance on 49 of 65 linguistic phenomena in the Flash-Holmes probing benchmark.
Where Pith is reading between the lines
- Explicit separation could allow targeted modifications to the positional streams for improving long-context understanding without affecting semantics.
- The 2D manifold might be encouraged in other positional encoding schemes to retain document-level information.
- Applying the disentangled model to retrieval or long-context tasks could test whether preserved structure yields practical gains beyond probing.
- This architecture might serve as a diagnostic tool for studying how positional information is processed separately from meaning.
Load-bearing premise
The three streams remain cleanly separated during training without the semantic-only MLM objective causing leakage or collapse in the positional streams.
What would settle it
Failure of the absolute positional subspace to collapse into a two-dimensional manifold, or absence of improvement on the Flash-Holmes benchmark under the disentangled training regime, would falsify the preservation claim.
Figures


read the original abstract
Positional encoding (PE) underpins how permutation-invariant Transformers represent sequence order, yet how positional information is processed and stored remains poorly understood. Modern PE methods such as RoPE still struggle on tasks such as long-context understanding or retrieval \cite{chen-etal-2025-hope}. Hence, a better understanding of the internal positional mechanism could help design better PE. Building on evidence that positional and semantic signals occupy nearly orthogonal subspaces in trained Transformers, we modify an encoder Transformer to process three explicitly disentangled streams: semantic, absolute positional (AP) and relative positional (RP), and confine the masked-language-modeling (MLM) objective to the semantic stream. This decoupling enables a clean mechanistic study and yields three take-aways. (1) The isolated AP subspace spontaneously collapses into a low-frequency two-dimensional manifold that captures the structure of the document; (2) Attention heads specialize into structure and semantic-oriented groups, with RP exclusively supporting the latter; (3) Standard positional encodings do not robustly retain macroscopic structure: RoPE and RP only weakly encode it, and entangled AP loses it in the final layers under MLM pressure. The disentangled approach preserves positional encoding, which improves linguistic representation on 49 of the 65 linguistic phenomena of the Flash-Holmes probing benchmark.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript modifies an encoder Transformer to maintain three explicitly disentangled streams (semantic, absolute positional AP, relative positional RP) and confines the MLM objective exclusively to the semantic stream. It reports that the isolated AP subspace spontaneously collapses to a low-frequency 2D manifold capturing document structure, that attention heads specialize (with RP supporting semantic processing), and that this disentangled model improves linguistic representation on 49 of 65 phenomena in the Flash-Holmes probing benchmark while standard encodings (RoPE, entangled AP) lose macroscopic structure under MLM pressure.
Significance. If the separation is verifiably clean and the reported gains are robust, the work supplies a mechanistic account of how positional information is stored and processed in Transformers and offers an empirical route to preserving positional structure that could inform better long-context encodings.
major comments (2)
- [model modification and training objective section] Model modification and training objective section: the claim of explicit disentanglement rests on confining MLM loss to the semantic stream, yet the text provides no mechanism (zeroed cross-stream attention, gradient blocking, or orthogonality constraint) that would provably prevent semantic signals from reaching AP/RP parameters via residuals or shared components. This is load-bearing for attributing the 2D AP collapse, head specialization, and 49/65 probing gains to isolation rather than training artifacts.
- [results and probing benchmark section] Results and probing benchmark section: the statement that the disentangled approach 'improves linguistic representation on 49 of the 65 linguistic phenomena' is presented without reported baseline scores per phenomenon, statistical significance, or ablation that isolates the contribution of stream separation from other architectural changes.
minor comments (1)
- [abstract] The abstract cites chen-etal-2025-hope but the reference list entry is not shown in the provided text; ensure all citations are complete.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below, clarifying the isolation mechanisms and the reporting of results. Revisions will be made where the manuscript can be strengthened without altering its core claims.
read point-by-point responses
-
Referee: [model modification and training objective section] Model modification and training objective section: the claim of explicit disentanglement rests on confining MLM loss to the semantic stream, yet the text provides no mechanism (zeroed cross-stream attention, gradient blocking, or orthogonality constraint) that would provably prevent semantic signals from reaching AP/RP parameters via residuals or shared components. This is load-bearing for attributing the 2D AP collapse, head specialization, and 49/65 probing gains to isolation rather than training artifacts.
Authors: The architecture maintains three streams with fully separate parameter sets and independent attention computations; no cross-stream attention is performed, and residuals remain stream-specific. The final MLM prediction head receives input exclusively from the semantic stream, so the loss produces no gradient signal to AP or RP parameters. We agree the manuscript would benefit from an explicit forward-pass diagram and gradient-flow description to make this isolation unambiguous. We will add both in the revision. revision: partial
-
Referee: [results and probing benchmark section] Results and probing benchmark section: the statement that the disentangled approach 'improves linguistic representation on 49 of the 65 linguistic phenomena' is presented without reported baseline scores per phenomenon, statistical significance, or ablation that isolates the contribution of stream separation from other architectural changes.
Authors: Per-phenomenon accuracies for all models appear in Appendix C. We will promote a compact table of the 65 scores to the main text, add McNemar tests for significance on the reported improvements, and include an explicit statement that the only architectural difference between the disentangled model and the entangled-AP baseline is the stream separation itself. revision: yes
Circularity Check
No circularity: empirical observations from model modification, no derivations or reductions to inputs
full rationale
The paper describes an architectural modification to create three disentangled streams and confines MLM loss to the semantic stream, then reports empirical observations such as AP subspace collapse and probing improvements. No equations, derivations, or fitted parameters are presented that could reduce predictions to inputs by construction. The work builds on prior evidence of orthogonal subspaces but does not rely on self-citations for load-bearing uniqueness theorems or ansatzes. All central claims are framed as experimental outcomes rather than tautological redefinitions, satisfying the criteria for a self-contained empirical study with no circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Positional and semantic signals occupy nearly orthogonal subspaces in trained Transformers
Reference graph
Works this paper leans on
-
[1]
Lola Le Breton, Quentin Fournier, John X Morris, Mariam El Mezouar, and Sarath Chandar. 2024. NeoBERT : A Next-Generation BERT
2024
-
[2]
Yuhan Chen, Ang Lv, Jian Luan, Bin Wang, and Wei Liu. 2025. https://doi.org/10.18653/v1/2025.acl-long.1123 H o PE : A novel positional encoding without long-term decay for enhanced context awareness and extrapolation . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 23044--23056, Vi...
-
[3]
Ta-Chung Chi, Ting-Han Fan, Peter J Ramadge, and Alexander Rudnicky. 2022. Kerple: Kernelized relative positional embedding for length extrapolation. Advances in Neural Information Processing Systems, 35:8386--8399
2022
-
[4]
Ta-Chung Chi, Ting-Han Fan, Alexander Rudnicky, and Peter Ramadge. 2023. https://doi.org/10.18653/v1/2023.acl-long.756 Dissecting transformer length extrapolation via the lens of receptive field analysis . In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13522--13537, Toronto, Canada...
-
[5]
ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
Kevin Clark, Minh-Thang Luong, Quoc V. Le, and Christopher D. Manning. 2020. https://doi.org/10.48550/arXiv.2003.10555 ELECTRA : Pre-training Text Encoders as Discriminators Rather Than Generators . Preprint, arXiv:2003.10555
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2003.10555 2020
-
[6]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. https://doi.org/10.18653/v1/N19-1423 BERT : Pre-training of deep bidirectional transformers for language understanding . In Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long a...
-
[7]
Rudolph Flesch. 1948. A new readability yardstick. Journal of applied psychology, 32(3):221
1948
-
[8]
Olga Golovneva, Tianlu Wang, Jason Weston, and Sainbayar Sukhbaatar. 2024. https://doi.org/10.48550/arXiv.2405.18719 Contextual Position Encoding : Learning to Count What 's Important . Preprint, arXiv:2405.18719
-
[9]
Zihan Gu, Ruoyu Chen, Han Zhang, Hua Zhang, and Yue Hu. 2026. https://openreview.net/forum?id=D0u0glT060 Deconstructing positional information: From attention logits to training biases . In The Fourteenth International Conference on Learning Representations
2026
-
[10]
Zhenyu He, Guhao Feng, Shengjie Luo, Kai Yang, Liwei Wang, Jingjing Xu, Zhi Zhang, Hongxia Yang, and Di He. 2024. https://doi.org/10.48550/arXiv.2401.16421 Two Stones Hit One Bird : Bilevel Positional Encoding for Better Length Extrapolation . Preprint, arXiv:2401.16421
-
[11]
Guolin Ke, Di He, and Tie-Yan Liu. 2021. https://doi.org/10.48550/arXiv.2006.15595 Rethinking Positional Encoding in Language Pre-training . Preprint, arXiv:2006.15595
-
[12]
Shun Kiyono, Sosuke Kobayashi, Jun Suzuki, and Kentaro Inui. 2021. https://doi.org/10.18653/v1/2021.emnlp-main.266 SHAPE : S hifted absolute position embedding for transformers . In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 3309--3321, Online and Punta Cana, Dominican Republic. Association for Computatio...
-
[13]
Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, and Radu Soricut. 2020. https://doi.org/10.48550/arXiv.1909.11942 ALBERT : A Lite BERT for Self-supervised Learning of Language Representations . Preprint, arXiv:1909.11942
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1909.11942 2020
-
[14]
Shanda Li, Chong You, Guru Guruganesh, Joshua Ainslie, Santiago Ontanon, Manzil Zaheer, Sumit Sanghai, Yiming Yang, Sanjiv Kumar, and Srinadh Bhojanapalli. 2024. https://doi.org/10.48550/arXiv.2310.04418 Functional Interpolation for Relative Positions Improves Long Context Transformers . Preprint, arXiv:2310.04418
-
[15]
Xuanqing Liu, Hsiang-Fu Yu, Inderjit Dhillon, and Cho-Jui Hsieh. 2020. Learning to Encode Position for Transformer with Continuous Dynamical Model . In Proceedings of the 37th International Conference on Machine Learning , pages 6327--6335. PMLR
2020
-
[16]
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. https://doi.org/10.48550/arXiv.1907.11692 RoBERTa : A Robustly Optimized BERT Pretraining Approach . Preprint, arXiv:1907.11692
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1907.11692 2019
-
[17]
Ilya Loshchilov and Frank Hutter. 2019. https://doi.org/10.48550/arXiv.1711.05101 Decoupled Weight Decay Regularization . Preprint, arXiv:1711.05101
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1711.05101 2019
-
[18]
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. 2016. https://arxiv.org/abs/1609.07843 Pointer sentinel mixture models . Preprint, arXiv:1609.07843
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[19]
Niklas Muennighoff, Nouamane Tazi, Loic Magne, and Nils Reimers. 2023. https://doi.org/10.18653/v1/2023.eacl-main.148 MTEB : Massive text embedding benchmark . In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, pages 2014--2037, Dubrovnik, Croatia. Association for Computational Linguistics
-
[20]
Guilherme Penedo, Hynek Kydl \' c ek, Loubna Ben allal , Anton Lozhkov, Margaret Mitchell, Colin Raffel, Leandro Von Werra, and Thomas Wolf. 2024. https://doi.org/10.52202/079017-0970 The FineWeb datasets: Decanting the web for the finest text data at scale . In Advances in Neural Information Processing Systems, volume 37, pages 30811--30849. Curran Assoc...
-
[21]
Bowen Peng, Jeffrey Quesnelle, Honglu Fan, and Enrico Shippole. 2023. https://doi.org/10.48550/arXiv.2309.00071 YaRN : Efficient Context Window Extension of Large Language Models . Preprint, arXiv:2309.00071
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2309.00071 2023
-
[22]
Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation
Ofir Press, Noah A. Smith, and Mike Lewis. 2022. https://doi.org/10.48550/arXiv.2108.12409 Train Short , Test Long : Attention with Linear Biases Enables Input Length Extrapolation . Preprint, arXiv:2108.12409
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2108.12409 2022
-
[23]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research, 21(140):1--67
2020
-
[24]
Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. 2016. https://doi.org/10.18653/v1/D16-1264 SQ u AD : 100,000+ questions for machine comprehension of text . In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 2383--2392, Austin, Texas. Association for Computational Linguistics
-
[25]
Andrew Rosenberg and Julia Hirschberg. 2007. https://aclanthology.org/D07-1043/ V -measure: A conditional entropy-based external cluster evaluation measure . In Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning ( EMNLP - C o NLL ) , pages 410--420, Prague, Czech Republi...
2007
-
[26]
Noam Shazeer. 2020. https://doi.org/10.48550/arXiv.2002.05202 GLU Variants Improve Transformer . Preprint, arXiv:2002.05202
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2002.05202 2020
-
[27]
Jiajun Song and Yiqiao Zhong. 2024. https://doi.org/10.48550/arXiv.2310.04861 Uncovering hidden geometry in Transformers via disentangling position and context . Preprint, arXiv:2310.04861
-
[28]
Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, and Yunfeng Liu. 2023. https://doi.org/10.48550/arXiv.2104.09864 RoFormer : Enhanced Transformer with Rotary Position Embedding . Preprint, arXiv:2104.09864
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2104.09864 2023
- [29]
-
[30]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, ukasz Kaiser, and Illia Polosukhin. 2017. Attention is All you Need . In Advances in Neural Information Processing Systems , volume 30. Curran Associates, Inc
2017
-
[31]
Andreas Waldis, Yotam Perlitz, Leshem Choshen, Yufang Hou, and Iryna Gurevych. 2024. https://doi.org/10.1162/tacl_a_00718 Holmes: A Benchmark to Assess the Linguistic Competence of Language Models . Transactions of the Association for Computational Linguistics, 12:1616--1647
-
[32]
Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R. Bowman. 2018. https://doi.org/10.18653/v1/W18-5446 GLUE : A multi-task benchmark and analysis platform for natural language understanding . In Proceedings of the 2018 EMNLP Workshop B lackbox NLP : Analyzing and Interpreting Neural Networks for NLP , pages 353--355, Brussels,...
-
[33]
Yu-An Wang and Yun-Nung Chen. 2020. https://doi.org/10.18653/v1/2020.emnlp-main.555 What do position embeddings learn? an empirical study of pre-trained language model positional encoding . In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6840--6849, Online. Association for Computational Linguistics
-
[34]
Wenhao Wu, Yizhong Wang, Guangxuan Xiao, Hao Peng, and Yao Fu. 2024. https://doi.org/10.48550/arXiv.2404.15574 Retrieval Head Mechanistically Explains Long-Context Factuality . Preprint, arXiv:2404.15574
-
[35]
Zijun Wu, Anup Anand Deshmukh, Yongkang Wu, Jimmy Lin, and Lili Mou. 2025. https://doi.org/10.1162/coli_a_00545 The emergence of chunking structures with hierarchical RNN . Computational Linguistics, 51(3):815--841
-
[36]
Biao Zhang and Rico Sennrich. 2019. Root mean square layer normalization. In Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc
2019
-
[37]
Chuanyang Zheng, Yihang Gao, Han Shi, Minbin Huang, Jingyao Li, Jing Xiong, Xiaozhe Ren, Michael Ng, Xin Jiang, Zhenguo Li, and 1 others. 2024. Dape: Data-adaptive positional encoding for length extrapolation. Advances in Neural Information Processing Systems, 37:26659--26700
2024
-
[38]
Chuanyang Zheng, Yihang Gao, Han Shi, Jing Xiong, Jiankai Sun, Jingyao Li, Minbin Huang, Xiaozhe Ren, Michael Ng, Xin Jiang, Zhenguo Li, and Yu Li. 2025. https://doi.org/10.18653/v1/2025.acl-long.522 DAPE v2: Process attention score as feature map for length extrapolation . In Proceedings of the 63rd Annual Meeting of the Association for Computational Lin...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.