RL2ML: Finite-Rollout Surrogate Objectives from Reinforcement Learning to Maximum Likelihood
Pith reviewed 2026-06-29 08:32 UTC · model grok-4.3
The pith
A family of finite-rollout surrogate objectives continuously connects reinforcement learning to maximum likelihood training while preserving unbiased gradient estimators under fixed rollout budgets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
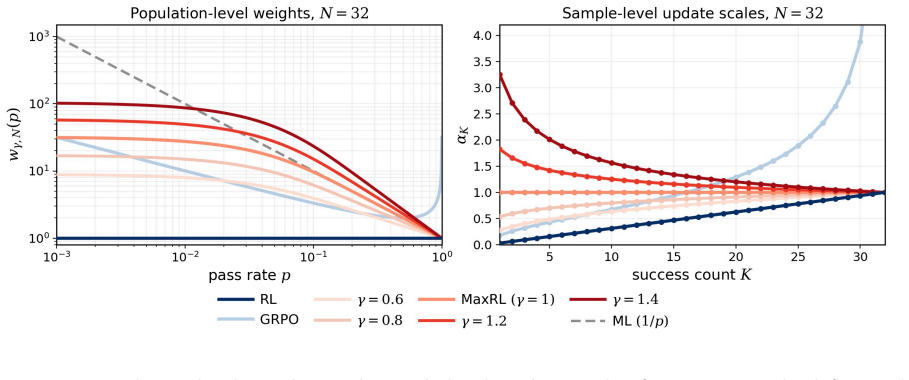
The RL2ML family supplies finite-rollout surrogate objectives equipped with closed-form exactly unbiased gradient estimators; the family interpolates between reinforcement learning, maximum-likelihood-like training, and beyond-maximum-likelihood objectives while keeping estimator-objective alignment under a fixed rollout budget, and the newly defined group-level update scale reveals a subcritical-supercritical transition in reweighting that population-level objective notation conceals.
What carries the argument
The RL2ML family of surrogate objectives together with the group-level update scale that records how each rollout group is reweighted once its empirical success count is observed.
If this is right
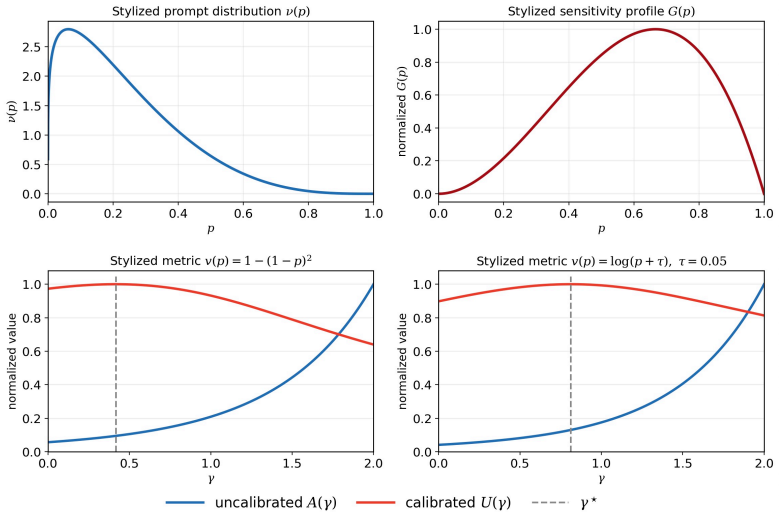
- The optimal surrogate is selected jointly by the evaluation metric, local sensitivity, and estimator variance rather than by nearness to maximum likelihood.
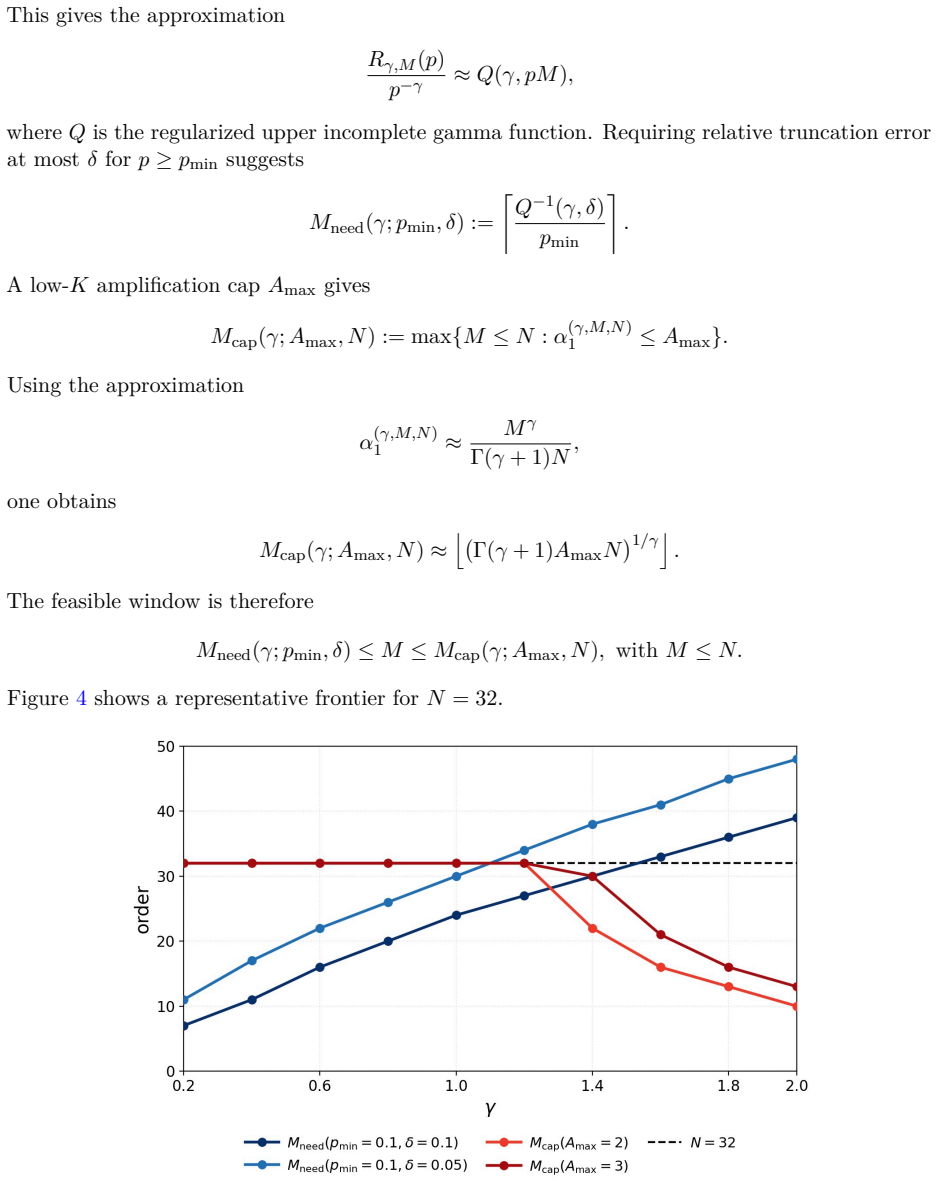
- The remaining free parameter in the family reduces to a one-dimensional optimization problem instead of an unconstrained hyperparameter.
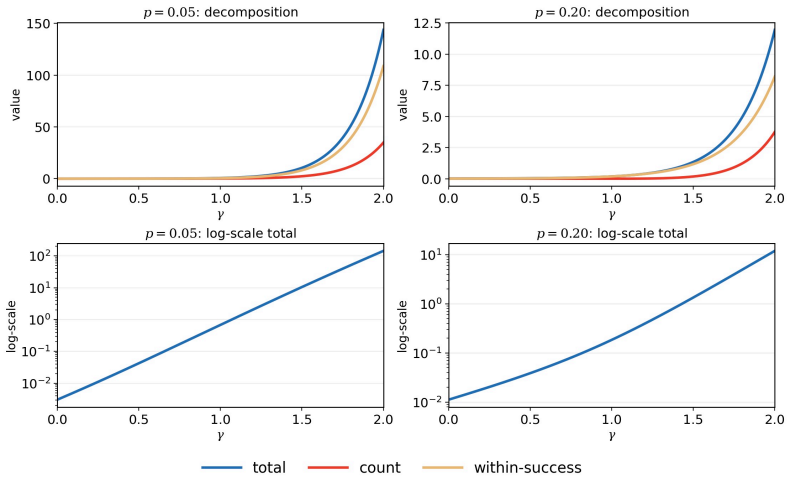
- Calibrated metric-gain analysis combined with exact variance decomposition determines the best surrogate for a given setting.
- Population-level objective notation alone hides the subcritical-supercritical update-scale transition.
- Estimator-objective alignment holds for the entire family under any fixed rollout budget.
Where Pith is reading between the lines
- The one-dimensional optimization could be performed adaptively during training by tracking running estimates of sensitivity and variance.
- The update-scale transition may appear in other reinforcement-learning settings that rely on small batches of rollouts rather than infinite-sample limits.
- The same finite-rollout construction could be applied to objectives with non-binary rewards by replacing success counts with appropriate summary statistics.
- If the transition point can be located analytically, training runs could switch surrogate mid-training to stay in the regime that minimizes variance for the target metric.
Load-bearing premise
A closed-form exactly unbiased gradient estimator exists for every member of the surrogate objective family when only finite rollout groups are used.
What would settle it
A direct computation or Monte Carlo check that demonstrates bias in the closed-form gradient estimator for any surrogate in the family under a concrete finite rollout budget would falsify the central claim.
Figures
read the original abstract
Correctness-based Reinforcement Learning with Verifiable Rewards (RLVR) trains language models from binary feedback on sampled outputs, but the objective optimized in expectation and the stochastic update geometry induced by finite rollout groups are often conflated. This paper develops RL2ML, a family of finite-rollout surrogate objectives with a closed-form, exactly unbiased gradient estimator. The family continuously connects standard reinforcement learning, maximum-likelihood-like training, and beyond-maximum-likelihood objectives while preserving estimator-objective alignment under a fixed rollout budget. We introduce the group-level update scale to characterize how a rollout group is reweighted after its empirical success count is observed, revealing a subcritical-supercritical update-scale transition that is hidden by population-level objective notation alone. Building on this distinction, calibrated metric-gain analysis and exact variance decomposition show that the best choice of surrogate objective is determined neither by proximity to maximum likelihood nor by the population-level weight alone. Instead, it depends jointly on the evaluation metric, local sensitivity, and estimator variance. The remaining degree of freedom in the surrogate objective family can therefore be formulated as a one-dimensional optimization problem rather than treated as an unconstrained hyperparameter.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes RL2ML, a family of finite-rollout surrogate objectives for correctness-based RL with verifiable rewards. It claims to provide a closed-form, exactly unbiased gradient estimator for the family, which continuously connects RL, ML-like, and beyond-ML objectives while maintaining alignment under fixed rollout budgets. The paper introduces the group-level update scale to characterize reweighting after observing empirical success counts, identifying a subcritical-supercritical transition. It further uses calibrated metric-gain analysis and exact variance decomposition to argue that the optimal surrogate is determined by the evaluation metric, local sensitivity, and estimator variance, allowing the remaining freedom to be optimized in one dimension.
Significance. If the unbiased estimator and the variance decomposition hold, this work offers a significant contribution by clarifying the distinction between population-level objectives and the stochastic geometry induced by finite groups in RLVR training. The update-scale transition and the reduction to a 1D optimization problem could provide practical guidance for choosing objectives in language model training with binary feedback, moving beyond ad-hoc hyperparameter tuning.
major comments (1)
- [Abstract (and presumed Methods derivation of the estimator)] The central claim of a closed-form, exactly unbiased gradient estimator for the entire surrogate objective family under finite rollout groups (stated in the abstract) is load-bearing for the continuous-connection and update-scale results. The derivation must be examined to confirm that no interchange of expectation and sampling occurs that holds only in the infinite-group limit, and that reweighting after empirical success counts introduces no uncanceled bias; otherwise the claimed preservation of estimator-objective alignment and the subcritical-supercritical transition cannot be realized with finite budgets.
minor comments (1)
- [Notation and surrogate family definition] Define the surrogate family parameter explicitly and show how it interpolates between standard RL and maximum-likelihood objectives with a concrete equation.
Simulated Author's Rebuttal
We thank the referee for their careful review and for focusing on the technical foundation of the unbiased estimator claim, which is indeed central to the paper's contributions. We address the concern point by point below.
read point-by-point responses
-
Referee: [Abstract (and presumed Methods derivation of the estimator)] The central claim of a closed-form, exactly unbiased gradient estimator for the entire surrogate objective family under finite rollout groups (stated in the abstract) is load-bearing for the continuous-connection and update-scale results. The derivation must be examined to confirm that no interchange of expectation and sampling occurs that holds only in the infinite-group limit, and that reweighting after empirical success counts introduces no uncanceled bias; otherwise the claimed preservation of estimator-objective alignment and the subcritical-supercritical transition cannot be realized with finite budgets.
Authors: We appreciate the referee highlighting this point. The derivation (Section 3, Equations 7–12) conditions explicitly on the observed success count within each finite-sized rollout group before taking the gradient. The reweighting is a deterministic function of the fully observed empirical count, and the expectation is computed exactly over the policy-induced distribution of that count; no interchange of limits or sampling is performed. The algebra shows that any potential bias terms from the reweighting cancel exactly for the parameterized family, yielding an unbiased estimator at any finite group size. This finite-group exactness is what permits the update-scale transition analysis. We have revised the manuscript to include an expanded step-by-step derivation in a new Appendix B that isolates the finite-group case and explicitly notes the absence of infinite-limit assumptions. revision: yes
Circularity Check
No circularity: derivation chain self-contained with independent estimator derivation
full rationale
The paper introduces RL2ML as a parameterized family of finite-rollout surrogate objectives and asserts a closed-form exactly unbiased gradient estimator for the entire family. The abstract and provided text derive the group-level update scale and subcritical-supercritical transition directly from the finite-group reweighting after observing empirical success counts, without reducing any claimed prediction or transition to a fitted quantity by construction. No self-citations are invoked as load-bearing uniqueness theorems, no ansatz is smuggled via prior work, and no renaming of known empirical patterns occurs. The one-dimensional optimization over the remaining degree of freedom is presented as an analysis result rather than a statistical fit. The central claims therefore rest on the (unverified here) algebraic derivation of the unbiased estimator rather than on any circular reduction to inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- surrogate family parameter
Reference graph
Works this paper leans on
-
[1]
Kevin P. Murphy. Machine Learning: A Probabilistic Perspective . MIT Press, 2012. 21
2012
-
[2]
Maximum likelihood reinforcement learning, 2026
Fahim Tajwar, Guanning Zeng, Yueer Zhou, Yuda Song, Daman Arora, Yiding Jiang, Jeff Schneider, Ruslan Salakhutdinov, Haiwen Feng, and Andrea Zanette. Maximum likelihood reinforcement learning. arXiv preprint arXiv:2602.02710 , 2026
-
[3]
Williams
Ronald J. Williams. Simple statistical gradient-following algorithms for connectionist rein- forcement learning. Machine Learning, 8(3–4):229–256, 1992
1992
-
[4]
Sutton, David McAllester, Satinder Singh, and Yishay Mansour
Richard S. Sutton, David McAllester, Satinder Singh, and Yishay Mansour. Policy gradient methods for reinforcement learning with function approximation. In Advances in Neural Information Processing Systems , volume 12, pages 1057–1063, 1999
1999
-
[5]
Damek Davis and Benjamin Recht. What is the objective of reasoning with reinforcement learning? arXiv preprint arXiv:2510.13651 , 2025
-
[6]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347 , 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[7]
Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. In Advances in Neural Information Processing Systems, volume 35, pages 27730–27744, 2022
2022
-
[8]
Back to basics: Revisiting REINFORCE-style optimization for learning from human feedback in LLMs
Arash Ahmadian, Chris Cremer, Matthias Gallé, Marzieh Fadaee, Julia Kreutzer, Olivier Pietquin, Ahmet Üstün, and Sara Hooker. Back to basics: Revisiting REINFORCE-style optimization for learning from human feedback in LLMs. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics , pages 12248–12267. Association for Compu...
2024
-
[9]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300 , 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning. arXiv preprint arXiv:2501.12948 , 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
W. N. Bailey. Generalized Hypergeometric Series, volume 32 of Cambridge Tracts in Mathe- matics and Mathematical Physics . Cambridge University Press, 1935
1935
-
[12]
Hypergeometric Summation: An Algorithmic Approach to Summation and Special Function Identities
Wolfram Koepf. Hypergeometric Summation: An Algorithmic Approach to Summation and Special Function Identities . Vieweg, 1998
1998
-
[13]
verl: Volcano engine reinforcement learning for LLMs
verl contributors. verl: Volcano engine reinforcement learning for LLMs. https://github. com/verl-project/verl, 2025. Accessed 2026-05-28
2025
-
[14]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, et al. DAPO: An open-source LLM reinforcement learning system at scale. arXiv preprint arXiv:2503.14476 , 2025. 22
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.