The Surface You Test Is Not the Surface That Breaks
Pith reviewed 2026-06-29 06:35 UTC · model grok-4.3
The pith
The same prompt-injection bytes succeed or fail depending on which channel delivers them to the model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
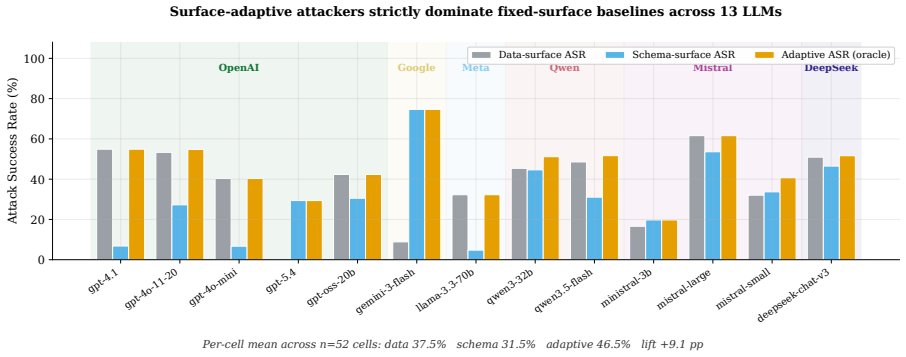
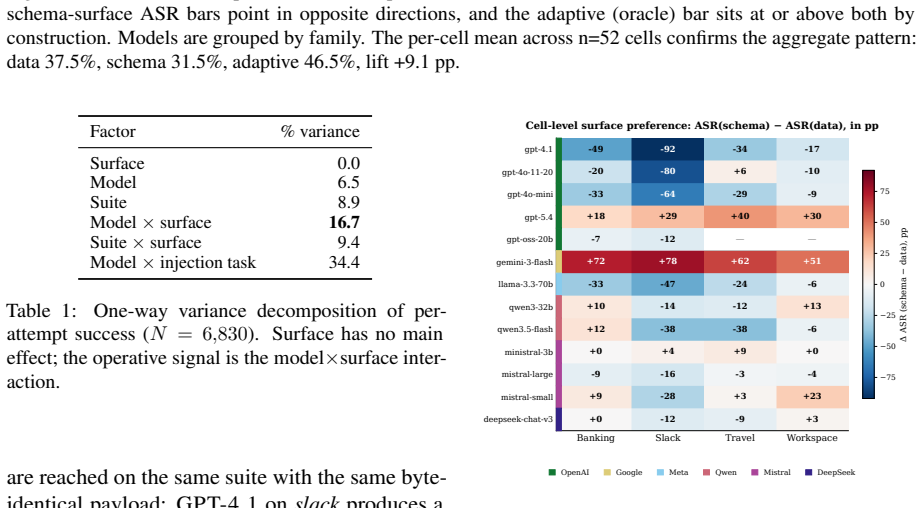
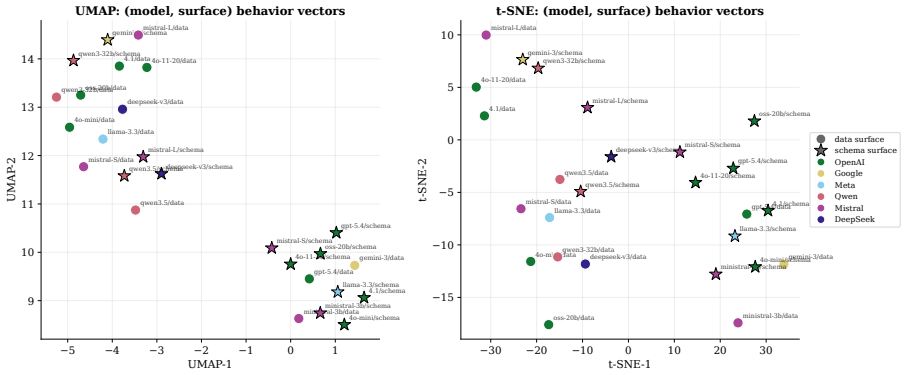
Holding the injection payload byte-identical and testing it on both the tool-output channel and the tool-description channel across thirteen models from six families reveals that success rates can reverse completely between models. GPT-4.1 reaches 96 percent success on outputs but only 4 percent on descriptions, while GEMINI-3-FLASH shows the opposite pattern at 20 percent and 98 percent. Variance decomposition attributes zero percent of attack-outcome variation to surface alone and 16.7 percent to the model-surface interaction. The per-cell maximum over surfaces, termed the Adaptive Attack Rate, exceeds the strongest single-surface baseline by 9.1 percentage points on average. Prompt-level
What carries the argument
The model-surface interaction that determines attack success when the identical payload is delivered through either the tool-output channel or the tool-description channel.
If this is right
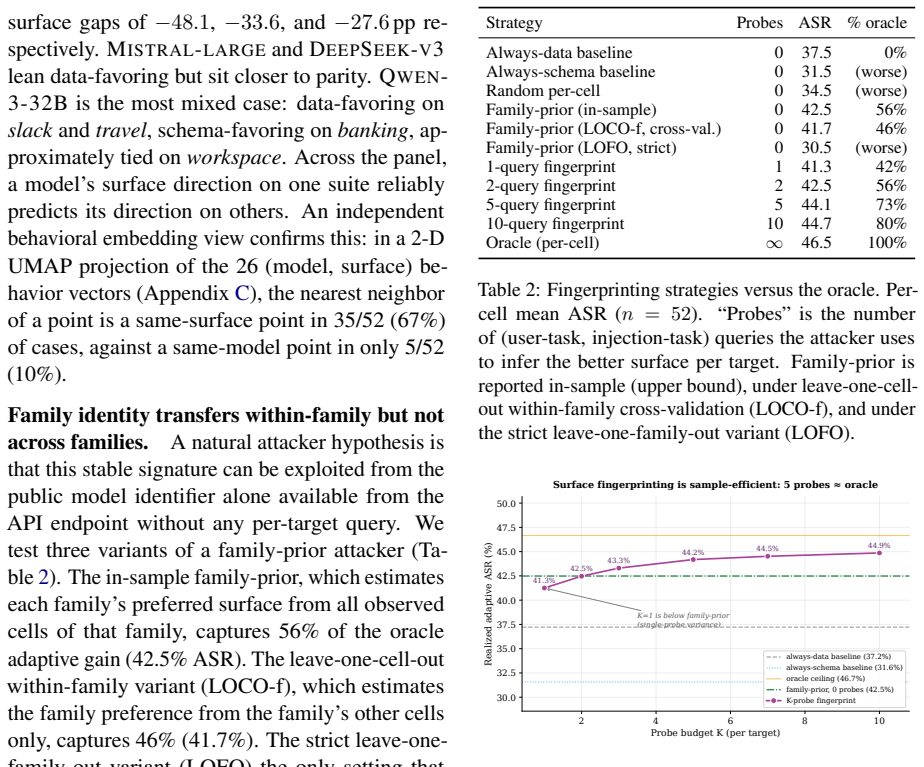
- The Adaptive Attack Rate, defined as the maximum success rate over the two surfaces for each model, is the relevant security metric rather than any single-channel rate.
- Prompt-level defenses must be evaluated separately on each surface or they will leave at least one channel open above 50 percent success.
- Benchmarking protocols that test only the tool-output channel systematically underestimate agent vulnerability.
- Attack and defense papers should report per-surface vulnerability numbers for every model examined.
Where Pith is reading between the lines
- Security testing of agents will need to enumerate every context channel an attacker can write into, not just the most obvious one.
- Model providers may need to apply different input sanitization or context-separation rules to tool descriptions versus tool outputs.
Load-bearing premise
That success-rate differences between the two channels can be attributed to the delivery surface rather than to how each model internally processes the same bytes.
What would settle it
A replication in which attack success rates on tool outputs and tool descriptions remain statistically indistinguishable across a new set of models and tasks would falsify the claim that vulnerability is a property of the pairing.
Figures


read the original abstract
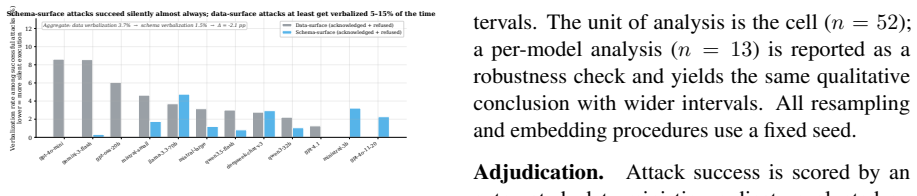
Tool-augmented LLM agents are vulnerable to prompt injection: a third party who controls part of the agent's context can plant instructions that the agent then executes as if they came from the user. Current evaluations report a single attack success rate per model on one channel, the tool output and treat that number as the model's vulnerability. But tool descriptions, which the agent reads at every turn before any tool is called, are themselves an injection surface that the attacker can choose instead. We hold the injection payload byte-identical and deliver it through both surfaces across 13 LLMs from six families and four task suites. The same bytes invert in success rate across models: GPT-4.1 is 96 percent vulnerable on tool outputs but only 4 percent on tool descriptions, while GEMINI-3-FLASH shows the mirror pattern at 20 percent and 98 percent. A variance decomposition over 6,830 attempts attributes 0 percent of the variation in attack outcomes to the surface alone, while the model-surface interaction accounts for 16.7 percent. Vulnerability is a property of the pairing, not the channel. The Adaptive Attack Rate, defined as the per-cell maximum over surfaces, exceeds the strongest fixed-surface baseline by +9.1 percentage points on average. Standard prompt-level defenses inherit the same blindspot, reducing tool-output ASR to 10-18 percent while leaving the description channel above 54 percent. Both attack and defense evaluation must report per-surface vulnerability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that prompt injection vulnerability in tool-augmented LLM agents is a property of the model-surface pairing rather than the channel alone. Holding payloads byte-identical, the authors test tool outputs versus tool descriptions across 13 LLMs from six families and four task suites. They report model-specific inversions (GPT-4.1: 96% outputs vs 4% descriptions; GEMINI-3-FLASH: 20% vs 98%), a variance decomposition over 6,830 attempts attributing 0% variation to surface main effect and 16.7% to model-surface interaction, an Adaptive Attack Rate (per-cell max) exceeding the strongest fixed-surface baseline by +9.1 pp on average, and standard defenses reducing output ASR to 10-18% while leaving descriptions above 54%. The conclusion is that both attack and defense evaluations must report per-surface vulnerability.
Significance. If the surfaces are shown to be comparable after addressing structural confounds, the result would meaningfully shift evaluation practices in LLM agent security by demonstrating that single-channel ASR reporting is insufficient and that adaptive, multi-surface testing is required. The scale of the experiment (13 models, multiple families and task suites, 6,830 attempts) and the concrete quantification of interaction effects and defense blind spots are strengths that provide falsifiable, actionable findings for the field.
major comments (1)
- [Abstract / Experimental Setup] Abstract and experimental design: the central claim that ASR differences can be attributed to the surface (rather than delivery differences) is load-bearing but rests on an assumption that byte-identical payloads through tool outputs versus tool descriptions constitute comparable attack surfaces. Tool descriptions are embedded in the initial system/tool schema (read every turn, structured XML/JSON), while tool outputs arrive later as function responses; these differ in position, surrounding tokens, attention patterns, and instruction-following stage. The reported variance decomposition (0% surface main effect, 16.7% interaction) does not isolate a true surface effect from these structural confounds, which could explain the observed model-specific inversions (e.g., GPT-4.1 96% vs 4%).
minor comments (2)
- The abstract states 'four task suites' but does not name them; the main text should explicitly list the suites and their characteristics to support reproducibility.
- Clarify in the methods how exactly the byte-identical payloads are embedded (e.g., exact prompt templates for each surface) so readers can assess the structural differences.
Simulated Author's Rebuttal
We thank the referee for highlighting the distinction between payload content and structural delivery. Our response addresses the concern directly while preserving the core empirical finding that model-specific inversions occur even under byte-identical payloads.
read point-by-point responses
-
Referee: [Abstract / Experimental Setup] Abstract and experimental design: the central claim that ASR differences can be attributed to the surface (rather than delivery differences) is load-bearing but rests on an assumption that byte-identical payloads through tool outputs versus tool descriptions constitute comparable attack surfaces. Tool descriptions are embedded in the initial system/tool schema (read every turn, structured XML/JSON), while tool outputs arrive later as function responses; these differ in position, surrounding tokens, attention patterns, and instruction-following stage. The reported variance decomposition (0% surface main effect, 16.7% interaction) does not isolate a true surface effect from these structural confounds, which could explain the observed model-specific inversions (e.g., GPT-4.1 96% vs 4%).
Authors: We agree that the two surfaces differ in structural embedding, position, surrounding tokens, and processing stage; these differences are intrinsic to the surfaces rather than extraneous confounds. Our operational definition of 'surface' encompasses the full delivery mechanism (including schema embedding for descriptions and function-response formatting for outputs). The byte-identical payload controls for content while allowing the structural and positional differences to vary naturally. The variance decomposition is consistent with this view: the 0% surface main effect indicates neither surface is universally stronger, while the 16.7% interaction term captures the model-specific sensitivity to each delivery structure. The striking inversions (e.g., GPT-4.1 vs. GEMINI-3-FLASH) are difficult to attribute solely to unmeasured confounds because the same payload produces opposite outcomes across models. We will revise the abstract, methods, and discussion to explicitly define 'surface' as the complete delivery channel (including structural properties) and to note that the experiment does not attempt to factor out those properties from the surface itself. revision: partial
Circularity Check
No circularity: purely empirical comparison of observed attack rates
full rationale
The paper reports experimental attack success rates (ASR) for byte-identical payloads delivered via two surfaces (tool outputs vs. tool descriptions) across 13 LLMs. Central results are the observed inversion patterns, variance decomposition (0% surface main effect, 16.7% interaction), and the definition of Adaptive Attack Rate as the per-cell maximum. These are direct aggregations and statistical summaries of measured outcomes, not derivations that reduce to fitted parameters or self-referential quantities. No equations, predictions, or uniqueness theorems appear; no self-citations are load-bearing for the claims. The evaluation is self-contained against external benchmarks (multiple models, task suites, and defense baselines).
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Maksym Andriushchenko, Nicolas Flammarion, and 1 others. 2025. Jailbreaking leading safety-aligned llms with simple adaptive attacks. In International Conference on Learning Representations, volume 2025, pages 40116--40143
2025
-
[2]
Usman Anwar, Abulhair Saparov, Javier Rando, Daniel Paleka, Miles Turpin, Peter Hase, Ekdeep Singh Lubana, Erik Jenner, Stephen Casper, Oliver Sourbut, and 1 others. 2024. Foundational challenges in assuring alignment and safety of large language models. arXiv preprint arXiv:2404.09932
-
[3]
Anish Athalye, Nicholas Carlini, and David Wagner. 2018. Obfuscated gradients give a false sense of security: Circumventing defenses to adversarial examples. In International conference on machine learning, pages 274--283. PMLR
2018
- [4]
-
[5]
Bochuan Cao, Yuanpu Cao, Lu Lin, and Jinghui Chen. 2024. Defending against alignment-breaking attacks via robustly aligned llm. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 10542--10560
2024
-
[6]
Nicholas Carlini, Anish Athalye, Nicolas Papernot, Wieland Brendel, Jonas Rauber, Dimitris Tsipras, Ian Goodfellow, Aleksander Madry, and Alexey Kurakin. 2019. On evaluating adversarial robustness. arXiv preprint arXiv:1902.06705
work page internal anchor Pith review Pith/arXiv arXiv 2019
- [7]
-
[8]
Patrick Chao, Alexander Robey, Edgar Dobriban, Hamed Hassani, George J Pappas, and Eric Wong. 2025. Jailbreaking black box large language models in twenty queries. In 2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML), pages 23--42. IEEE
2025
-
[9]
Francesco Croce and Matthias Hein. 2020. Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks. In International conference on machine learning, pages 2206--2216. PMLR
2020
-
[10]
Edoardo Debenedetti, Jie Zhang, Mislav Balunovic, Luca Beurer-Kellner, Marc Fischer, and Florian Tram \`e r. 2024. Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for llm agents. Advances in Neural Information Processing Systems, 37:82895--82920
2024
-
[11]
Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. 2023. Not what you've signed up for: Compromising real-world llm-integrated applications with indirect prompt injection. In Proceedings of the 16th ACM workshop on artificial intelligence and security, pages 79--90
2023
-
[12]
Keegan Hines, Gary Lopez, Matthew Hall, Federico Zarfati, Yonatan Zunger, and Emre Kiciman. 2024. Defending against indirect prompt injection attacks with spotlighting. arXiv preprint arXiv:2403.14720
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [13]
-
[14]
Milad Nasr, Nicholas Carlini, Chawin Sitawarin, Sander V Schulhoff, Jamie Hayes, Michael Ilie, Juliette Pluto, Shuang Song, Harsh Chaudhari, Ilia Shumailov, and 1 others. 2025. The attacker moves second: Stronger adaptive attacks bypass defenses against llm jailbreaks and prompt injections. arXiv preprint arXiv:2510.09023
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Shishir G Patil, Tianjun Zhang, Xin Wang, and Joseph E Gonzalez. 2024. Gorilla: Large language model connected with massive apis. Advances in Neural Information Processing Systems, 37:126544--126565
2024
-
[16]
F \'a bio Perez and Ian Ribeiro. 2022. Ignore previous prompt: Attack techniques for language models. arXiv preprint arXiv:2211.09527
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[17]
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, and 1 others. 2024. Toolllm: Facilitating large language models to master 16000+ real-world apis. In International Conference on Learning Representations, volume 2024, pages 9695--9717
2024
-
[18]
Alexander Robey, Eric Wong, Hamed Hassani, and George J Pappas. 2023. Smoothllm: Defending large language models against jailbreaking attacks. arXiv preprint arXiv:2310.03684
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Timo Schick, Jane Dwivedi-Yu, Roberto Dess \` , Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. 2023. Toolformer: Language models can teach themselves to use tools. Advances in neural information processing systems, 36:68539--68551
2023
-
[20]
Jiawen Shi, Zenghui Yuan, Guiyao Tie, Pan Zhou, Neil Zhenqiang Gong, and Lichao Sun. 2025. Prompt injection attack to tool selection in llm agents. arXiv preprint arXiv:2504.19793
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Florian Tramer, Nicholas Carlini, Wieland Brendel, and Aleksander Madry. 2020. On adaptive attacks to adversarial example defenses. Advances in neural information processing systems, 33:1633--1645
2020
-
[22]
Eric Wallace, Kai Xiao, Reimar Leike, Lilian Weng, Johannes Heidecke, and Alex Beutel. 2024. The instruction hierarchy: Training llms to prioritize privileged instructions. arXiv preprint arXiv:2404.13208
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Zhiqiang Wang, Yichao Gao, Yanting Wang, Suyuan Liu, Haifeng Sun, Haoran Cheng, Guanquan Shi, Haohua Du, and Xiangyang Li. 2026. Mcptox: A benchmark for tool poisoning on real-world mcp servers. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 35811--35819
2026
-
[24]
Alexander Wei, Nika Haghtalab, and Jacob Steinhardt. 2023. Jailbroken: How does llm safety training fail? Advances in neural information processing systems, 36:80079--80110
2023
-
[25]
Jingwei Yi, Yueqi Xie, Bin Zhu, Emre Kiciman, Guangzhong Sun, Xing Xie, and Fangzhao Wu. 2025. Benchmarking and defending against indirect prompt injection attacks on large language models. In Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 1, pages 1809--1820
2025
-
[26]
Qiusi Zhan, Richard Fang, Henil Shalin Panchal, and Daniel Kang. 2025. Adaptive attacks break defenses against indirect prompt injection attacks on llm agents. In Findings of the Association for Computational Linguistics: NAACL 2025, pages 7101--7117
2025
-
[27]
Qiusi Zhan, Zhixiang Liang, Zifan Ying, and Daniel Kang. 2024. Injecagent: Benchmarking indirect prompt injections in tool-integrated large language model agents. In Findings of the Association for Computational Linguistics: ACL 2024, pages 10471--10506
2024
-
[28]
Rupeng Zhang, Haowei Wang, Junjie Wang, Mingyang Li, Yuekai Huang, Dandan Wang, and Qing Wang. 2025. From allies to adversaries: Manipulating llm tool-calling through adversarial injection. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: L...
2025
-
[29]
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J Zico Kolter, and Matt Fredrikson. 2023. Universal and transferable adversarial attacks on aligned language models. arXiv preprint arXiv:2307.15043
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[31]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.