Learning Permutation-invariant Macroscopic Dynamics
Pith reviewed 2026-06-28 23:39 UTC · model grok-4.3
The pith
A permutation-invariant autoencoder learns macroscopic dynamics from unordered microscopic states.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
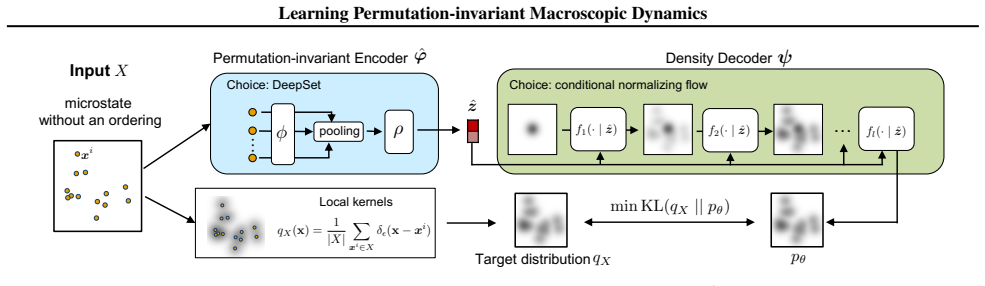
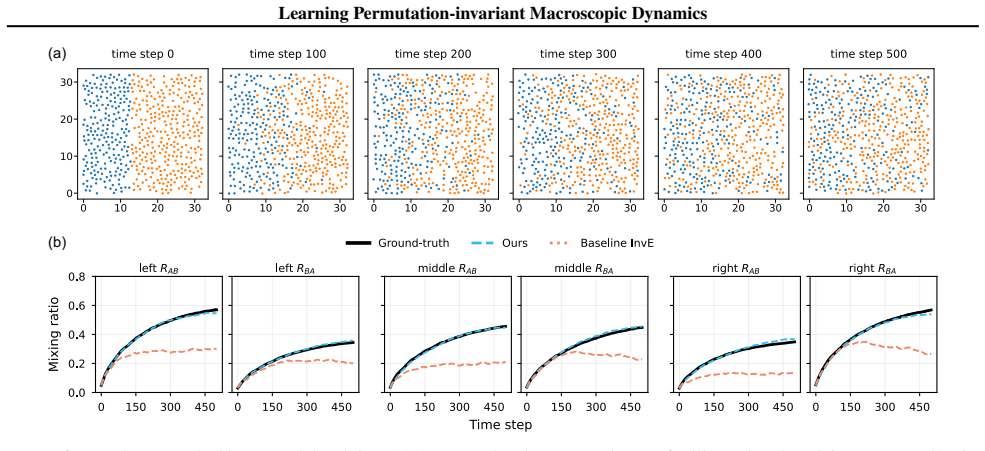
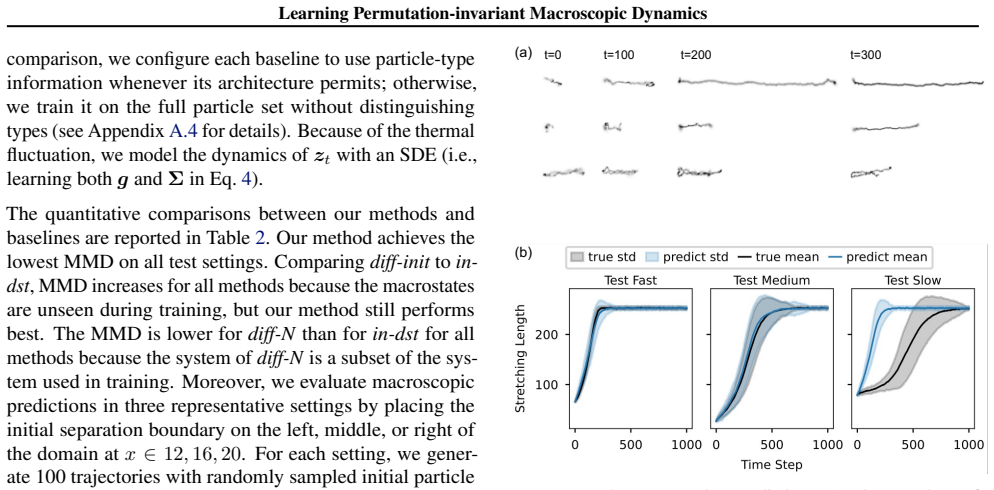
We adopt a permutation-invariant encoder and design the decoder to reconstruct the mass distribution centered at the observed points rather than per-sample reconstruction. We then jointly learn the macroscopic dynamics of the observables together with the latent states. The resulting framework is shown to be effective and robust across interacting particle systems, Lennard-Jones fluids, and video observations of polymers under elongational force.
What carries the argument
Permutation-invariant encoder together with mass-distribution decoder, which produces order-independent latent representations usable for dynamics prediction.
If this is right
- The method reproduces energy dynamics in interacting particle systems.
- It predicts mixing dynamics in Lennard-Jones fluids.
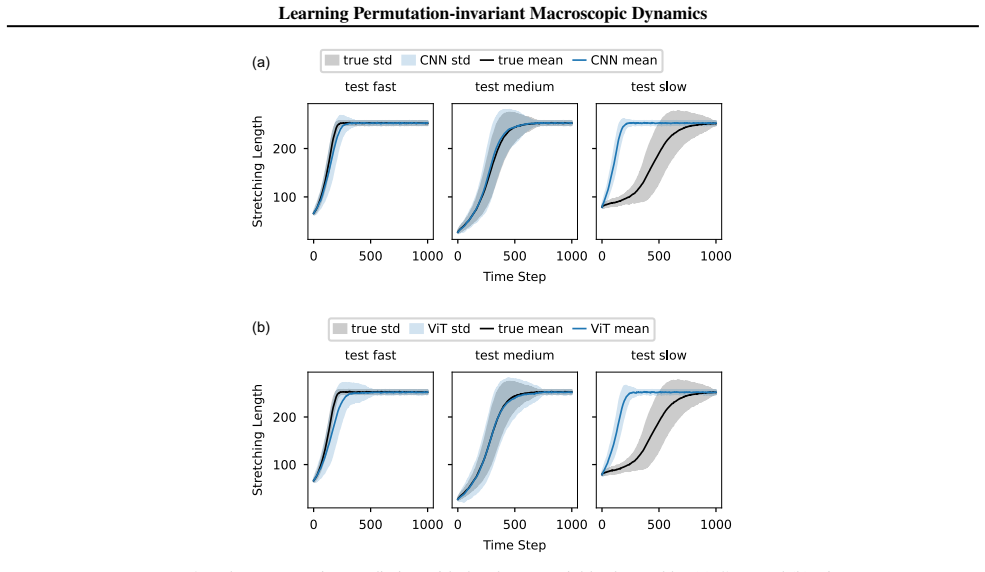
- It recovers stretching dynamics from video of polymers in an elongational force field.
- Performance holds across multiple microscopic settings without requiring fixed input order.
Where Pith is reading between the lines
- The same encoder-decoder pattern could be tested on other unordered data structures such as point clouds or sets in general machine-learning tasks.
- One could check whether the learned latent states transfer across simulations that differ only in how particles are labeled.
- A direct comparison on the same datasets with and without the mass-distribution reconstruction step would isolate its contribution to dynamics accuracy.
Load-bearing premise
Reconstructing the mass distribution rather than individual points supplies a latent representation sufficient to capture the dynamics of the macroscopic observables.
What would settle it
Running the trained model on inputs whose particle ordering has been randomly shuffled and checking whether the predicted macroscopic observables remain accurate to the same degree as on the original ordering.
Figures

read the original abstract
Accurately modeling the macroscopic dynamics of high-dimensional microscopic systems is of broad interest across the sciences. Many data-driven approaches learn a low-dimensional latent state through an autoencoder trained for pointwise input reconstruction. These methods typically assume a fixed ordering of microscopic degrees of freedom in the input. However, in many settings, such as particle systems, the microscopic state is inherently unordered. This motivates an autoencoder framework that learns permutation-invariant latent representations. To this end, we adopt a permutation-invariant encoder and design the decoder to reconstruct the mass distribution centered at the observed points rather than per-sample reconstruction. We then jointly learn the macroscopic dynamics of the observables together with the latent states. We demonstrate the effectiveness and robustness of the proposed method across a range of microscopic settings, including learning the energy dynamics in interacting particle systems, predicting mixing dynamics in Lennard-Jones fluids, and modeling the stretching dynamics from video data of polymers moving in an elongational force field.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a permutation-invariant autoencoder for modeling macroscopic dynamics of unordered microscopic systems (e.g., particle systems). A permutation-invariant encoder is paired with a decoder that reconstructs the mass distribution centered at observed points rather than per-sample reconstruction; macroscopic dynamics of observables are then learned jointly with the latent states. Effectiveness is demonstrated on energy dynamics in interacting particles, mixing in Lennard-Jones fluids, and stretching dynamics from polymer video data.
Significance. If the central claim holds, the framework offers a practical route to data-driven macroscopic modeling without assuming fixed ordering of degrees of freedom, which is common in physical systems. The joint training and cross-domain demonstrations could strengthen data-driven approaches in physics-informed machine learning.
major comments (2)
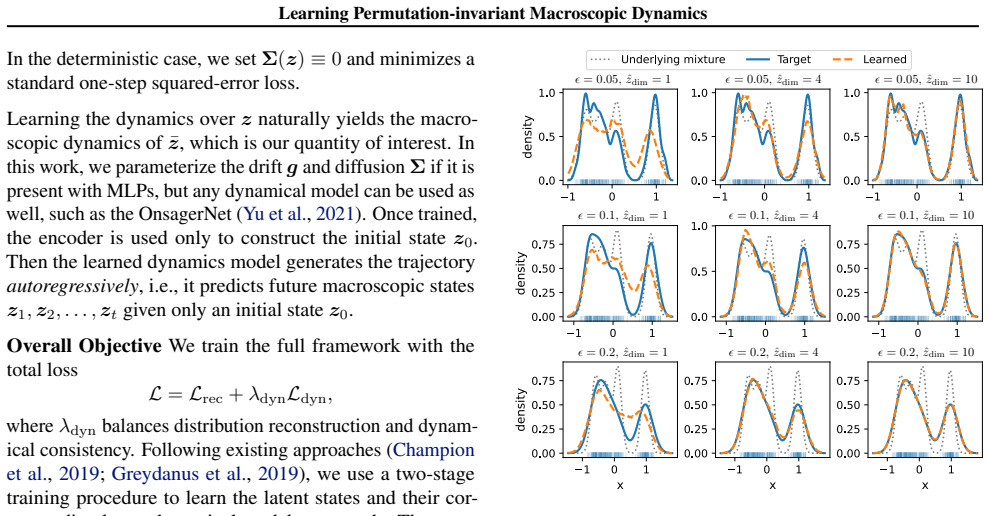
- [Decoder objective] Decoder objective (method description): the design reconstructs the mass distribution rather than individual points. This choice is load-bearing for the claim that the resulting latent state suffices to learn accurate macroscopic dynamics, yet the manuscript provides no derivation or controlled test showing that higher-order statistics or specific configurations (e.g., relative particle positions or chain connectivity) are preserved when they affect the observables.
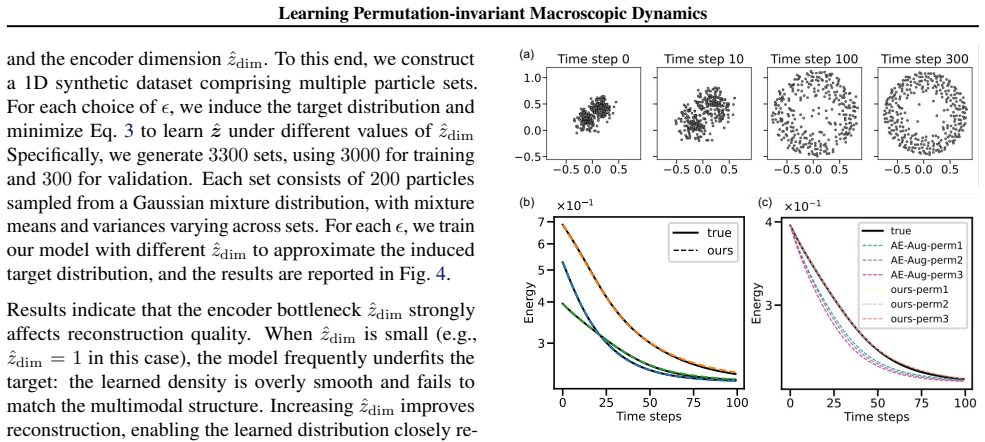
- [Experiments] Joint training procedure (experiments section): while results are reported across three settings, there is no ablation that isolates whether the mass-distribution decoder (versus a pointwise or permutation-equivariant alternative) is necessary for the reported dynamics accuracy; without this, it is unclear whether the permutation-invariance alone or the specific reconstruction objective drives the performance.
minor comments (2)
- [Method] Notation for the mass distribution and latent-state evolution equations could be introduced earlier and used consistently when describing the joint loss.
- [Figures] Figure captions should explicitly state the quantitative metric (e.g., prediction error on observables) used to assess dynamics learning in each panel.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and describe the revisions we will make.
read point-by-point responses
-
Referee: [Decoder objective] Decoder objective (method description): the design reconstructs the mass distribution rather than individual points. This choice is load-bearing for the claim that the resulting latent state suffices to learn accurate macroscopic dynamics, yet the manuscript provides no derivation or controlled test showing that higher-order statistics or specific configurations (e.g., relative particle positions or chain connectivity) are preserved when they affect the observables.
Authors: The mass-distribution decoder reconstructs the empirical measure, which encodes the full set of moments and statistics of the point cloud. This is sufficient for the permutation-invariant macroscopic observables considered in the work. We agree that an explicit derivation and controlled test would strengthen the justification. In the revision we will add a short derivation linking the decoder objective to preservation of distribution moments relevant to the dynamics, together with a controlled synthetic experiment that verifies retention of higher-order statistics when they influence the target observable. revision: yes
-
Referee: [Experiments] Joint training procedure (experiments section): while results are reported across three settings, there is no ablation that isolates whether the mass-distribution decoder (versus a pointwise or permutation-equivariant alternative) is necessary for the reported dynamics accuracy; without this, it is unclear whether the permutation-invariance alone or the specific reconstruction objective drives the performance.
Authors: We acknowledge that the current experiments do not isolate the contribution of the mass-distribution decoder from permutation invariance alone. In the revised manuscript we will add ablation studies that replace the mass-distribution decoder with a pointwise reconstruction baseline (adapted for unordered inputs) and with a permutation-equivariant decoder, reporting the resulting change in macroscopic dynamics accuracy on all three experimental domains. revision: yes
Circularity Check
No circularity; derivation is a methodological proposal without self-referential reductions
full rationale
The paper proposes a permutation-invariant autoencoder with mass-distribution decoder and joint dynamics learning for unordered microscopic systems. No equations, fitted parameters, or self-citations are present that reduce any claimed prediction or result to an input by construction. The central claims rest on design choices and empirical demonstrations across particle systems, fluids, and polymers, with no load-bearing self-definition, uniqueness theorems, or renamed known results. The derivation chain is self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
PMLR, 2019. Lee, K. and Carlberg, K. T. Model reduction of dynamical systems on nonlinear manifolds using deep convolutional autoencoders.Journal of Computational Physics, 404: 108973, 2020a. Lee, K. and Carlberg, K. T. Model reduction of dynamical systems on nonlinear manifolds using deep convolutional autoencoders.Journal of Computational Physics, 404: ...
-
[2]
test fast
ISBN 978-1-6654-2812-5. Yang, Y ., Feng, C., Shen, Y ., and Tian, D. Foldingnet: Point cloud auto-encoder via deep grid deformation. In2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 206–215. IEEE, 2018. ISBN 978-1-5386-6420-9. 11 Learning Permutation-invariant Macroscopic Dynamics Yu, H., Tian, X., Weinan, E., and Li, Q. O...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.