Quantum State Preparation via Neural Network Encoding in Quantum Machine Learning
Pith reviewed 2026-06-28 21:56 UTC · model grok-4.3
The pith
A trained neural network maps classical data to quantum circuit parameters for single-step high-fidelity state preparation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
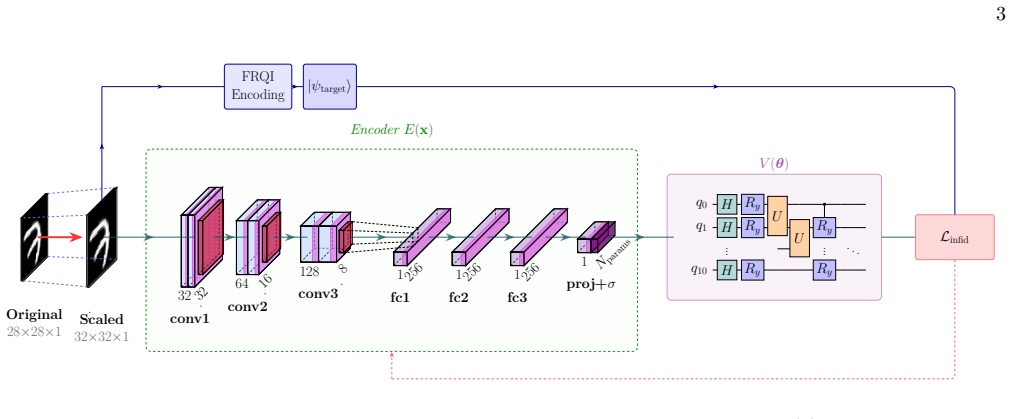
By training a neural network on optimized circuit parameters for training data, the network can predict suitable parameters for unseen data, enabling the fixed quantum circuit to prepare the corresponding quantum states with high fidelity without further optimization.
What carries the argument
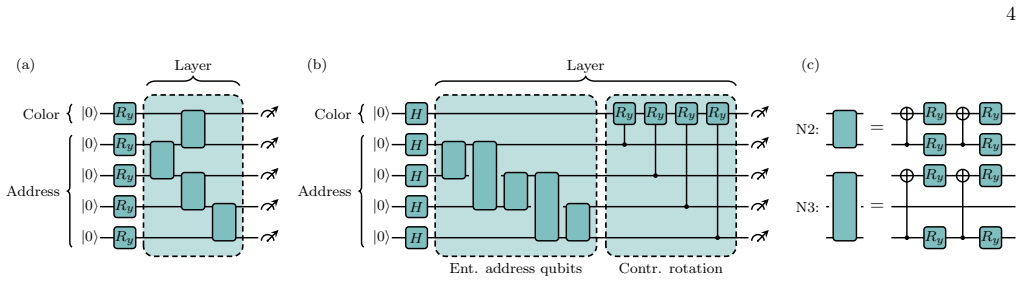
A classical neural network that takes classical data as input and outputs the continuous parameters of a fixed parameterized quantum circuit ansatz for amplitude encoding.
If this is right
- Quantum image states can be generated with high fidelity on data not seen during training.
- All optimization occurs once in training, so new inputs are encoded in one inference step.
- Per-data-instance runtime drops by more than 5000-fold compared to per-instance variational methods.
- The approach supplies a scalable route for data loading into near-term quantum algorithms.
Where Pith is reading between the lines
- The same trained network could be reused across different quantum algorithms that need fast amplitude encoding.
- If the chosen circuit ansatz cannot represent certain data distributions, fidelity on those distributions would fall even after training.
- Applying the method to non-image data or larger qubit counts would reveal how far the fixed-ansatz premise extends.
Load-bearing premise
A single fixed quantum circuit ansatz whose continuous parameters are predicted by the trained neural network is expressive enough to represent arbitrary high-dimensional classical data with high fidelity across the test distribution.
What would settle it
Finding average state preparation fidelity well below 0.99 on a large held-out test set of MNIST or Fashion-MNIST images would show the generalization claim does not hold.
Figures
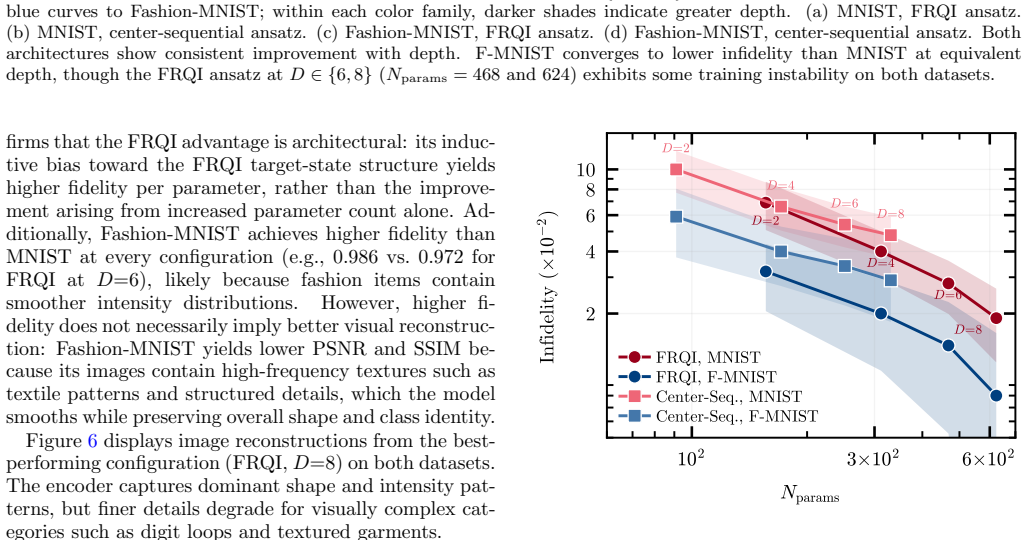
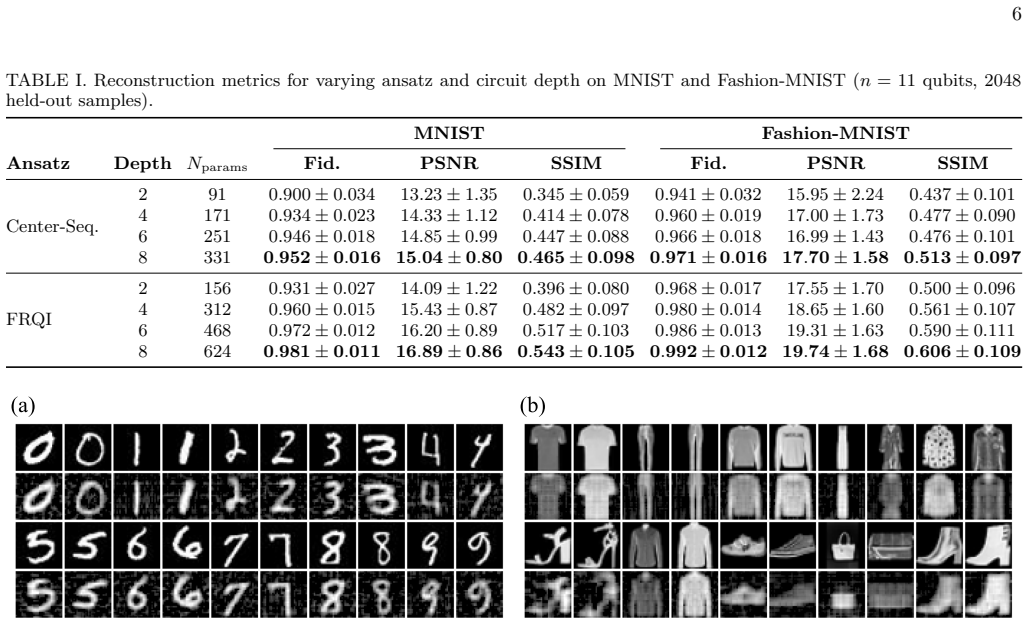
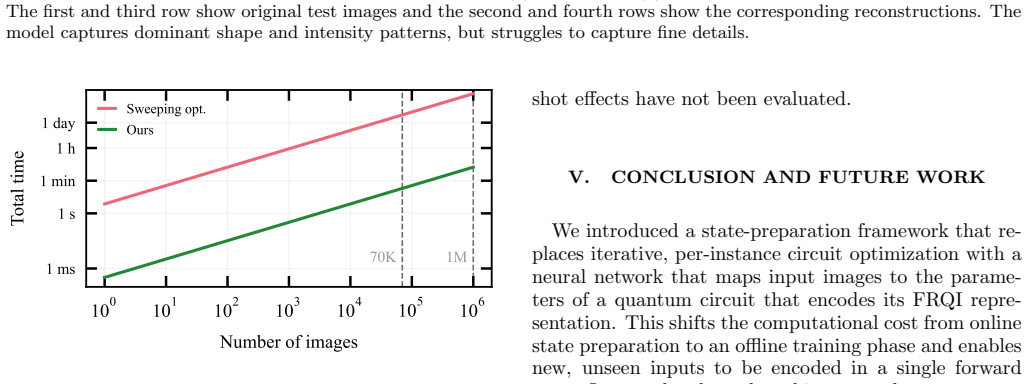
read the original abstract
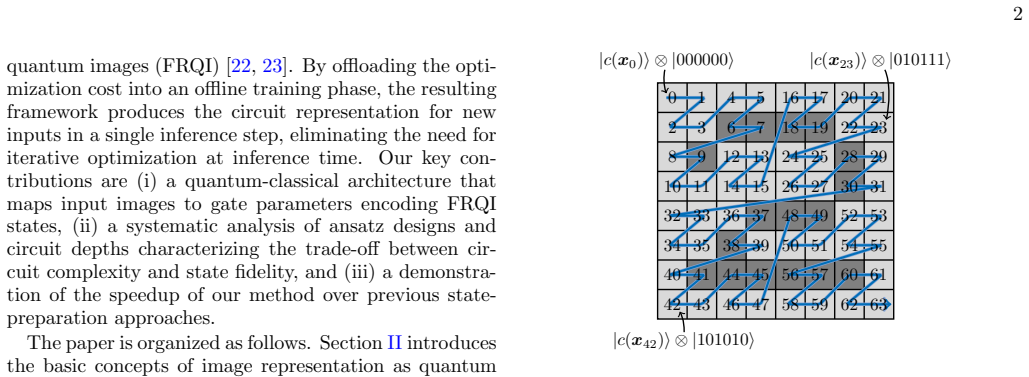
A central challenge in quantum machine learning is the state preparation bottleneck that describes the prohibitive computational cost of loading high-dimensional classical data into a quantum state. Although amplitude encoding can represent $2^n$-dimensional data using only $n$ qubits in principle, preparing arbitrary states remains computationally expensive, typically requiring variational optimization of a parameterized quantum circuit for each individual data instance. In this work, we propose a method that avoids iterative optimization by training a classical neural network to map input data directly to the continuous parameters of a fixed quantum circuit. We demonstrate the generation of quantum image states with high fidelity on data not seen during training. Since all optimization is performed once during training, the resulting model encodes new inputs in a single inference step, providing a scalable pathway for data loading in near-term quantum algorithms. We validate our method on the MNIST and Fashion-MNIST datasets, achieving fidelities up to 0.992 on unseen images and reducing the per-data-instance runtime by more than 5000-fold.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes training a classical neural network to directly predict the continuous parameters of a single fixed quantum circuit ansatz, enabling amplitude encoding of high-dimensional classical data (MNIST and Fashion-MNIST) into quantum states. This avoids per-instance variational optimization, yielding reported fidelities up to 0.992 on unseen test images and a >5000-fold reduction in per-instance runtime.
Significance. If the central empirical claims hold under a sufficiently expressive ansatz, the approach would meaningfully address the state-preparation bottleneck in near-term quantum machine learning by shifting all optimization to a one-time training phase. The reported runtime gains and generalization to held-out data would constitute a practical advance for data loading in variational quantum algorithms.
major comments (3)
- [Abstract, §3] Abstract and §3 (Method): the central claim that a single fixed ansatz whose parameters are NN-predicted can achieve fidelity ≥0.99 for arbitrary unseen 784-dimensional amplitude-encoded vectors is load-bearing, yet no description is given of the ansatz (qubit count, gate set, depth, or total number of continuous parameters). Without this, it is impossible to verify whether the parameter manifold is dense enough in the 2^n-dimensional space to support the reported test fidelities.
- [§4] §4 (Experiments): the 0.992 fidelity and 5000-fold runtime claims are presented without circuit diagrams, explicit parameter counts, training hyperparameters, or comparison to standard baselines (e.g., per-instance VQE or other state-preparation methods). These omissions prevent evaluation of whether the NN truly compensates for any limitations of the fixed ansatz.
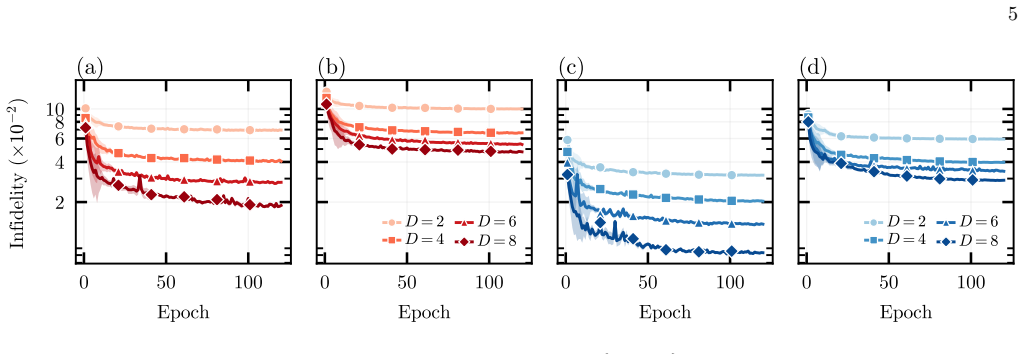
- [§3.2] §3.2 (Training procedure): the manuscript invokes a train/test split on unseen data but provides no error analysis, variance across random seeds, or ablation on ansatz depth, all of which are required to substantiate generalization claims for high-dimensional data.
minor comments (2)
- [Abstract] Notation for fidelity and runtime metrics should be defined explicitly on first use rather than assumed from context.
- [Figures] Figure captions for any circuit diagrams or fidelity plots should include the exact ansatz depth and qubit count.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed report. The comments correctly identify several omissions that limit the ability to assess the technical claims. We address each point below and will revise the manuscript to incorporate the requested information and analyses.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (Method): the central claim that a single fixed ansatz whose parameters are NN-predicted can achieve fidelity ≥0.99 for arbitrary unseen 784-dimensional amplitude-encoded vectors is load-bearing, yet no description is given of the ansatz (qubit count, gate set, depth, or total number of continuous parameters). Without this, it is impossible to verify whether the parameter manifold is dense enough in the 2^n-dimensional space to support the reported test fidelities.
Authors: We agree that the ansatz specification is essential for evaluating expressivity and reproducibility. The current manuscript provides only a high-level description in §3. In the revised version we will add an explicit subsection (with accompanying circuit diagram) stating the qubit count, gate set, depth, and total number of continuous parameters, allowing direct assessment of whether the parameterized manifold can support the reported fidelities on 784-dimensional inputs. revision: yes
-
Referee: [§4] §4 (Experiments): the 0.992 fidelity and 5000-fold runtime claims are presented without circuit diagrams, explicit parameter counts, training hyperparameters, or comparison to standard baselines (e.g., per-instance VQE or other state-preparation methods). These omissions prevent evaluation of whether the NN truly compensates for any limitations of the fixed ansatz.
Authors: We accept that the experimental section lacks the necessary implementation details and baselines. The revision will include circuit diagrams, the exact parameter count of the ansatz, all training hyperparameters (optimizer, learning rate, epochs, batch size, loss function), and direct runtime and fidelity comparisons against per-instance variational methods such as VQE to substantiate the claimed speed-up and to show how the NN compensates for ansatz limitations. revision: yes
-
Referee: [§3.2] §3.2 (Training procedure): the manuscript invokes a train/test split on unseen data but provides no error analysis, variance across random seeds, or ablation on ansatz depth, all of which are required to substantiate generalization claims for high-dimensional data.
Authors: We acknowledge that statistical robustness and ablation studies are required to support the generalization claims. The revised manuscript will report fidelity means and standard deviations across at least five independent random seeds, and will include an ablation study varying ansatz depth while keeping the NN architecture fixed, thereby quantifying the contribution of circuit expressivity to the observed test-set performance. revision: yes
Circularity Check
No significant circularity; empirical train/test validation on unseen data
full rationale
The paper describes training a neural network once to map input data to parameters of a fixed quantum circuit ansatz, then applying the model via single-pass inference to generate states for new inputs. Validation uses explicit train/test splits on MNIST and Fashion-MNIST with reported fidelities on unseen images. No equations or steps reduce by construction to fitted inputs renamed as predictions, no self-definitional mappings, and no load-bearing self-citations or uniqueness theorems from prior author work are invoked in the provided text. The derivation chain is self-contained as an empirical procedure whose central performance claims rest on external test-set measurements rather than internal redefinition.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Algorithms for quantum computation: dis- crete logarithms and factoring,
P. W. Shor, “Algorithms for quantum computation: dis- crete logarithms and factoring,” inProceedings 35th An- nual Symposium on Foundations of Computer Science. IEEE, 1994, pp. 124–134
1994
-
[2]
A fast quantum mechanical algorithm for database search,
L. K. Grover, “A fast quantum mechanical algorithm for database search,” inProceedings of the 28th Annual ACM Symposium on Theory of Computing. ACM, 1996, pp. 212–219
1996
-
[3]
Quantum al- gorithm for linear systems of equations,
A. W. Harrow, A. Hassidim, and S. Lloyd, “Quantum al- gorithm for linear systems of equations,”Physical Review Letters, vol. 103, no. 15, p. 150502, 2009
2009
-
[4]
Quantum machine learning,
J. Biamonte, P. Wittek, N. Pancotti, P. Rebentrost, N. Wiebe, and S. Lloyd, “Quantum machine learning,” Nature, vol. 549, no. 7671, pp. 195–202, 2017
2017
-
[5]
Quantum sup- port vector machine for big data classification,
P. Rebentrost, M. Mohseni, and S. Lloyd, “Quantum sup- port vector machine for big data classification,”Physical Review Letters, vol. 113, no. 13, p. 130503, 2014
2014
-
[6]
A rigorous and robust quantum speed-up in supervised machine learning,
Y. Liu, S. Arunachalam, and K. Temme, “A rigorous and robust quantum speed-up in supervised machine learning,”Nature Physics, vol. 17, no. 9, p. 1013–1017, Jul. 2021. [Online]. Available: http: //dx.doi.org/10.1038/s41567-021-01287-z
-
[7]
Read the fine print,
S. Aaronson, “Read the fine print,”Nature Physics, vol. 11, no. 4, pp. 291–293, 2015
2015
-
[8]
Schuld and F
M. Schuld and F. Petruccione,Machine Learning with Quantum Computers, 2nd ed. Cham: Springer Interna- tional Publishing, Oct. 2022
2022
-
[9]
Image compression and entanglement,
J. I. Latorre, “Image compression and entanglement,” arXiv:quant-ph/0510031, Oct. 2005
Pith/arXiv arXiv 2005
-
[10]
Data compression for quantum machine learning,
R. Dilip, Y.-J. Liu, A. Smith, and F. Pollmann, “Data compression for quantum machine learning,”Physical Review Research, vol. 4, p. 043007, Oct. 2022
2022
-
[11]
Tensor network based efficient quantum data loading of images,
J. Iaconis and S. Johri, “Tensor network based efficient quantum data loading of images,”arXiv:2310.05897, Oct. 2023
arXiv 2023
-
[12]
Efficient MPS representations and quan- tum circuits from the Fourier modes of classical image data,
B. Jobst, K. Shen, C. A. Riofr´ ıo, E. Shishenina, and F. Pollmann, “Efficient MPS representations and quan- tum circuits from the Fourier modes of classical image data,”Quantum, vol. 8, p. 1544, 2024
2024
-
[13]
Classification of the Fashion-MNIST dataset on a quan- tum computer,
K. Shen, B. Jobst, E. Shishenina, and F. Pollmann, “Classification of the Fashion-MNIST dataset on a quan- tum computer,”arXiv:2403.02405, Mar. 2024
arXiv 2024
-
[14]
Drastic circuit depth reductions with preserved adversarial ro- bustness by approximate encoding for quantum machine learning,
M. T. West, A. C. Nakhl, J. Heredge, F. M. Creevey, L. C. L. Hollenberg, M. Sevior, and M. Usman, “Drastic circuit depth reductions with preserved adversarial ro- bustness by approximate encoding for quantum machine learning,”Intelligent Computing, vol. 3, p. 0100, 2024
2024
-
[15]
Multigrid renor- malization,
M. Lubasch, P. Moinier, and D. Jaksch, “Multigrid renor- malization,”Journal of Computational Physics, vol. 372, pp. 587–602, Jun. 2018
2018
-
[16]
Variational quantum algorithms for nonlin- ear problems,
M. Lubasch, J. Joo, P. Moinier, M. Kiffner, and D. Jaksch, “Variational quantum algorithms for nonlin- ear problems,”Physical Review A, vol. 101, p. 010301, Jan. 2020
2020
-
[17]
A quantum-inspired approach to exploit turbulence struc- tures,
N. Gourianov, M. Lubasch, S. Dolgov, Q. Y. van den Berg, H. Babaee, P. Givi, M. Kiffner, and D. Jaksch, “A quantum-inspired approach to exploit turbulence struc- tures,”Nature Computational Science, vol. 2, pp. 30–37, Jan. 2022
2022
-
[18]
Quantum-inspired fluid simulation of two-dimensional turbulence with GPU acceleration,
L. H¨ olscher, P. Rao, L. M¨ uller, J. Klepsch, A. Luckow, T. Stollenwerk, and F. K. Wilhelm, “Quantum-inspired fluid simulation of two-dimensional turbulence with GPU acceleration,”Physical Review Research, vol. 7, p. 013112, Jan. 2025
2025
-
[19]
Quantics ten- sor cross interpolation for high-resolution parsimonious representations of multivariate functions,
M. K. Ritter, Y. N´ u˜ nez Fern´ andez, M. Wallerberger, J. von Delft, H. Shinaoka, and X. Waintal, “Quantics ten- sor cross interpolation for high-resolution parsimonious representations of multivariate functions,”Physical Re- view Letters, vol. 132, p. 056501, Jan. 2024
2024
-
[20]
Typical machine learning datasets as low- depth quantum circuits,
F. J. Kiwit, B. Jobst, A. Luckow, F. Pollmann, and C. A. Riofr´ ıo, “Typical machine learning datasets as low- depth quantum circuits,”Quantum Science and Technol- ogy, vol. 10, no. 4, p. 045035, 2025
2025
-
[21]
Quantum circuit gen- eration for amplitude encoding using a transformer de- coder,
S. Daimon and Y.-i. Matsushita, “Quantum circuit gen- eration for amplitude encoding using a transformer de- coder,”Physical Review Applied, vol. 22, p. L041001, 2024
2024
-
[22]
A flexible representa- tion of quantum images for polynomial preparation, im- age compression, and processing operations,
P. Q. Le, F. Dong, and K. Hirota, “A flexible representa- tion of quantum images for polynomial preparation, im- age compression, and processing operations,”Quantum Information Processing, vol. 10, no. 1, pp. 63–84, 2011
2011
-
[23]
A flexible representation and invertible transformations for images on quantum computers,
P. Q. Le, A. M. Iliyasu, F. Dong, and K. Hirota, “A flexible representation and invertible transformations for images on quantum computers,” inNew Advances in In- telligent Signal Processing, ser. Studies in Computational Intelligence. Berlin, Heidelberg: Springer, 2011, vol. 372
2011
-
[24]
A computer oriented geodetic data base and a new technique in file sequencing,
G. M. Morton, “A computer oriented geodetic data base and a new technique in file sequencing,” IBM Ltd., Tech. Rep., 1966
1966
-
[25]
Finitely correlated states on quantum spin chains,
M. Fannes, B. Nachtergaele, and R. F. Werner, “Finitely correlated states on quantum spin chains,”Communica- tions in Mathematical Physics, vol. 144, no. 3, pp. 443– 490, 1992
1992
-
[26]
Matrix product states and projected entangled pair states: Concepts, symmetries, theorems,
J. I. Cirac, D. P´ erez-Garc´ ıa, N. Schuch, and F. Ver- straete, “Matrix product states and projected entangled pair states: Concepts, symmetries, theorems,”Reviews of Modern Physics, vol. 93, no. 4, p. 045003, 2021
2021
-
[27]
Scaling quantum machine learning without tricks: High- resolution and diverse image generation,
J. J¨ ager, F. J. Kiwit, and C. A. Riofr´ ıo, “Scaling quantum machine learning without tricks: High- resolution and diverse image generation,” 2026. [Online]. Available: https://arxiv.org/abs/2603.00233
arXiv 2026
-
[28]
Gradient-based learning applied to document recogni- 8 tion,
Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner, “Gradient-based learning applied to document recogni- 8 tion,”Proceedings of the IEEE, vol. 86, no. 11, pp. 2278– 2324, 1998
1998
-
[29]
Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms,
H. Xiao, K. Rasul, and R. Vollgraf, “Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms,”arXiv preprint arXiv:1708.07747, 2017
Pith/arXiv arXiv 2017
-
[30]
Image quality assessment: from error visibility to structural similarity,
Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simon- celli, “Image quality assessment: from error visibility to structural similarity,”IEEE Transactions on Image Pro- cessing, vol. 13, no. 4, pp. 600–612, 2004
2004
-
[31]
Pennylane: Automatic dif- ferentiation of hybrid quantum-classical computations,
V. Bergholm, J. Izaac, M. Schuld, C. Gogolin, S. Ahmed, V. Ajber, M. S. Alam, G. Alonso-Linaje, B. Akash- Narayanan, A. Asberet al., “Pennylane: Automatic dif- ferentiation of hybrid quantum-classical computations,” arXiv preprint arXiv:1811.04968, 2018
Pith/arXiv arXiv 2018
-
[32]
A multi-channel representation for images on quantum computers using the RGBαcolor space,
B. Sun, P. Q. Le, A. M. Iliyasu, F. Yan, J. A. Garcia, F. Dong, and K. Hirota, “A multi-channel representation for images on quantum computers using the RGBαcolor space,” in2011 IEEE 7th International Symposium on Intelligent Signal Processing, Oct. 2011, pp. 1–6
2011
-
[33]
An RGB multi-channel representation for images on quantum computers,
B. Sun, A. M. Iliyasu, F. Yan, F. Dong, and K. Hi- rota, “An RGB multi-channel representation for images on quantum computers,”Journal of Advanced Compu- tational Intelligence and Intelligent Informatics, vol. 17, no. 3, pp. 404–417, Mar. 2013
2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.