Learning from Fine-Grained Visual Discrepancies: Mitigating Multimodal Hallucinations via In-Context Visual Contrastive Optimization
Pith reviewed 2026-06-28 22:41 UTC · model grok-4.3
The pith
Placing contrastive images in one shared prompt context produces a consistent objective for visual preference optimization that reduces multimodal hallucinations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
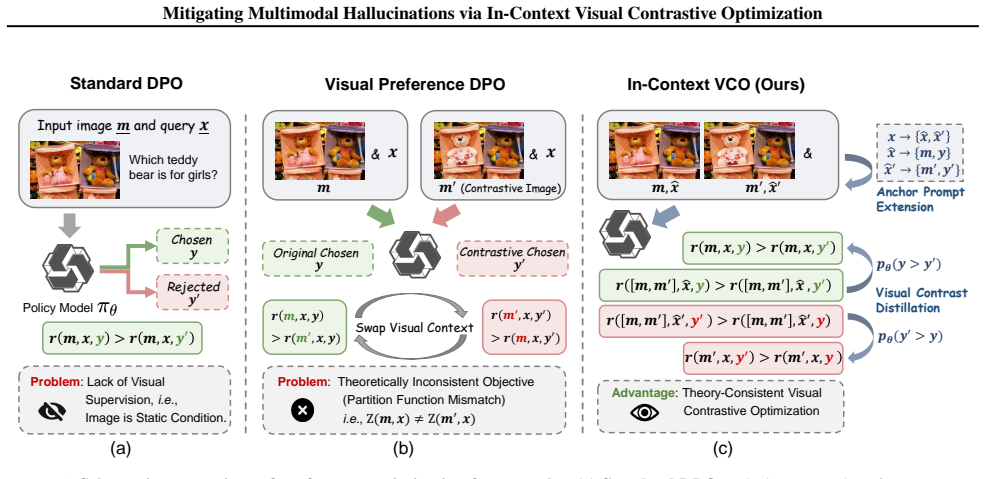
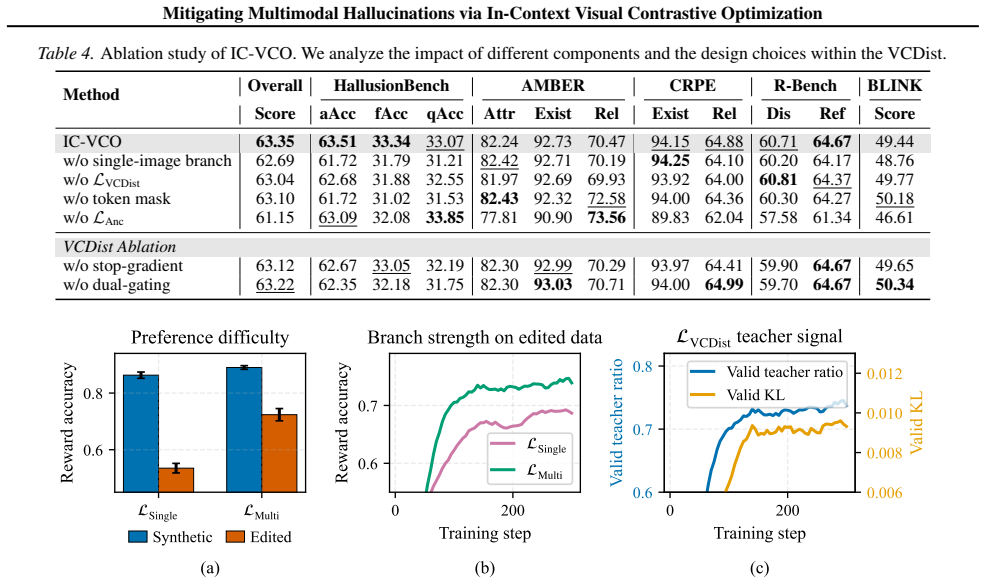
By placing contrastive images within a shared multi-image context, IC-VCO ensures a mathematically rigorous objective. The method further introduces Visual Contrast Distillation as a reliability-gated regularizer that maintains consistency between multi-image contrastive training and single-image inference, together with a contrastive sample editing strategy that generates hard negatives via precise semantic perturbations.
What carries the argument
In-Context Visual Contrastive Optimization (IC-VCO), the mechanism that embeds original and negative images inside one shared prompt context so the preference loss is computed without partition-function mismatch.
If this is right
- The preference objective becomes theoretically consistent because all images share the same context window.
- The auxiliary distillation term transfers the learned contrastive signal from training to ordinary single-image inference.
- Hard negatives generated by precise semantic edits reduce the opportunity for models to exploit coarse visual cues.
- Overall hallucination rates fall on every benchmark when both the shared-context loss and the editing strategy are used.
Where Pith is reading between the lines
- The same shared-context trick could be applied to preference optimization in other multimodal tasks where separate negative examples previously produced inconsistent gradients.
- The editing strategy for hard negatives might extend to text-only or audio preference data by applying analogous local semantic perturbations.
- If the method scales, it suggests that context length rather than model size may be the more direct lever for stabilizing visual alignment objectives.
Load-bearing premise
The dominant failure in earlier visual DPO comes from partition-function mismatch and that embedding the images in one context removes this mismatch without creating new inconsistencies when the model later sees single images.
What would settle it
A direct computation of the learned preference probabilities on held-out contrastive pairs that shows the shared-context loss still produces the same mismatched ratios as separate-image baselines, or no measurable drop in hallucination rates on the five evaluation sets.
Figures


read the original abstract
Multimodal hallucination remains a persistent challenge for Vision-Language Models (VLMs). Standard textual Direct Preference Optimization (DPO) often fails to mitigate it due to a lack of explicit visual supervision. While existing works introduce visual preference DPO by contrasting original images against negative ones, they suffer from a theoretically inconsistent objective caused by partition function mismatches and rely on coarse-grained negatives that could enable shortcut learning. In this work, we propose In-Context Visual Contrastive Optimization (IC-VCO). By placing contrastive images within a shared multi-image context, IC-VCO ensures a mathematically rigorous objective. We further introduce Visual Contrast Distillation (VCDist), an auxiliary reliability-gated regularizer that encourages consistency between multi-image contrastive training and single-image inference. Finally, we propose a contrastive sample editing strategy that generates hard negatives via precise semantic perturbations. Experiments on five benchmarks demonstrate IC-VCO's best overall performance and the effectiveness of our sample editing strategy. Code and data are available at https://github.com/OPPO-Mente-Lab/IC-VCO.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that standard textual DPO fails to mitigate multimodal hallucinations in VLMs due to missing visual supervision, while prior visual preference DPO variants suffer from partition-function mismatches yielding inconsistent objectives and from coarse negatives enabling shortcuts. It proposes IC-VCO, which places contrastive images in a shared multi-image context to produce a mathematically rigorous objective, introduces VCDist as a reliability-gated regularizer to enforce consistency between multi-image training and single-image inference, and adds a contrastive sample editing method for hard negatives via semantic perturbations. Experiments on five benchmarks are reported to show best overall performance.
Significance. If the claimed mathematical rigor of the IC-VCO objective can be formally established and the empirical gains prove robust under ablations and error bars, the work would advance visual preference tuning by directly addressing a known source of inconsistency in visual DPO. The public release of code and data strengthens the contribution by enabling direct verification.
major comments (2)
- [Abstract] Abstract: the assertion that placing contrastive images in a shared multi-image context 'ensures a mathematically rigorous objective' is unsupported by any derivation, proof, or explicit partition-function analysis; the introduction of VCDist to handle the train-test context mismatch indicates an approximation whose bias is not bounded.
- [Abstract] Abstract: the claim of 'best overall performance' on five benchmarks is presented without error bars, ablation tables, or statistical tests, preventing assessment of whether gains are reliable or attributable to the proposed components rather than implementation details.
minor comments (1)
- [Abstract] Abstract: the GitHub link for code and data is a positive step for reproducibility and should be retained.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address the two major comments point by point below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that placing contrastive images in a shared multi-image context 'ensures a mathematically rigorous objective' is unsupported by any derivation, proof, or explicit partition-function analysis; the introduction of VCDist to handle the train-test context mismatch indicates an approximation whose bias is not bounded.
Authors: We acknowledge that the manuscript does not provide an explicit derivation or partition-function analysis to support the claim of mathematical rigor. In the revised version we will add a formal analysis (in the main text or an appendix) showing how the shared multi-image context aligns the partition functions and yields a consistent objective, in contrast to prior visual DPO approaches. We will also expand the discussion of VCDist to clarify its role as a regularizer and include any available bounds or empirical analysis of the resulting approximation. revision: yes
-
Referee: [Abstract] Abstract: the claim of 'best overall performance' on five benchmarks is presented without error bars, ablation tables, or statistical tests, preventing assessment of whether gains are reliable or attributable to the proposed components rather than implementation details.
Authors: We agree that the abstract claim would be more robust with supporting details. The full paper reports results across five benchmarks, but we will revise the abstract to qualify the performance statement and ensure the experimental section (and any referenced tables) includes error bars, ablation studies, and statistical significance tests. This will allow readers to better evaluate the reliability and attribution of the gains. revision: yes
Circularity Check
No significant circularity; derivation self-contained
full rationale
The paper builds IC-VCO on standard DPO by introducing a shared multi-image context to address partition-function mismatch, then adds VCDist explicitly as an auxiliary regularizer to bridge the acknowledged train-inference gap and a separate contrastive editing strategy. No quoted step reduces a claimed prediction or rigorous objective to a fitted parameter defined inside the same work, nor does any load-bearing claim rest on a self-citation chain or imported uniqueness theorem. The central claim remains an independent architectural choice whose consistency is handled by an additional term rather than asserted by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Deng, H., Wang, C., Xin, L., Yuan, D., Zhan, J., Zhou, T., Ma, J., Gao, J., and Xu, R
URL https://openreview.net/forum? id=jznbgiynus. Deng, H., Wang, C., Xin, L., Yuan, D., Zhan, J., Zhou, T., Ma, J., Gao, J., and Xu, R. Webcites: Attributed query- focused summarization on chinese web search results with citations. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 15095–...
2024
-
[2]
Fu, X., Hu, Y ., Li, B., Feng, Y ., Wang, H., Lin, X., Roth, D., Smith, N
URL https://openreview.net/forum? id=7lpDn2MhM2. Fu, X., Hu, Y ., Li, B., Feng, Y ., Wang, H., Lin, X., Roth, D., Smith, N. A., Ma, W.-C., and Krishna, R. Blink: Multi- modal large language models can see but not perceive. In European Conference on Computer Vision, pp. 148–166. Springer, 2024. Geirhos, R., Jacobsen, J.-H., Michaelis, C., Zemel, R., Bren- ...
arXiv 2024
-
[3]
Jin, Z., Song, X., Wang, N., Liu, Y ., Li, C., Li, X., Wang, R., Li, Z., Qi, Q., Cheng, L., et al
URL https://openreview.net/forum? id=94kQgWXojH. Jin, Z., Song, X., Wang, N., Liu, Y ., Li, C., Li, X., Wang, R., Li, Z., Qi, Q., Cheng, L., et al. Andesvl technical re- port: An efficient mobile-side multimodal large language model.arXiv preprint arXiv:2510.11496, 2025. Leng, S., Zhang, H., Chen, G., Li, X., Lu, S., Miao, C., and Bing, L. Mitigating obje...
arXiv 2025
-
[4]
Li, C., Zhang, J., Zhang, Z., Wu, H., Tian, Y ., Sun, W., Lu, G., Min, X., Liu, X., Lin, W., et al
URL https://openreview.net/forum? id=zKv8qULV6n. Li, C., Zhang, J., Zhang, Z., Wu, H., Tian, Y ., Sun, W., Lu, G., Min, X., Liu, X., Lin, W., et al. R-bench: Are your large multimodal model robust to real-world corruptions? IEEE Journal of Selected Topics in Signal Processing, 2025b. Li, F., Zhang, R., Zhang, H., Zhang, Y ., Li, B., Li, W., Ma, Z., and Li...
Pith/arXiv arXiv 2024
-
[5]
Mitigating catastrophic forgetting in large language models with forgetting-aware pruning
URL https://openreview.net/forum? id=bhTBirS0qi. 11 Mitigating Multimodal Hallucinations via In-Context Visual Contrastive Optimization Manevich, A. and Tsarfaty, R. Mitigating hallucinations in large vision-language models (lvlms) via language- contrastive decoding (lcd). InFindings of the Association for Computational Linguistics ACL 2024, pp. 6008–6022...
-
[6]
Proximal Policy Optimization Algorithms
URL https://aclanthology.org/2025. emnlp-main.631/. Sch¨olkopf, B., Locatello, F., Bauer, S., Ke, N. R., Kalch- brenner, N., Goyal, A., and Bengio, Y . Toward causal representation learning.Proceedings of the IEEE, 109(5): 612–634, 2021. Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algo- rithms, 2017. UR...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2024.emnlp-main 2025
-
[7]
AMBER: An LLM-free Multi-dimensional Benchmark for MLLMs Hallucination Evaluation
URL https://aclanthology.org/2024. emnlp-main.460/. Wang, J., Wang, Y ., Xu, G., Zhang, J., Gu, Y ., Jia, H., Yan, M., Zhang, J., and Sang, J. An llm-free multi-dimensional benchmark for mllms hallucination evaluation.arXiv preprint arXiv:2311.07397, 2023. Wang, J., Gao, Y ., and Sang, J. Valid: Mitigating the hallucination of large vision language models...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2025.acl-long 2024
-
[8]
acl-long.1462/
URL https://aclanthology.org/2025. acl-long.1462/. Xie, Y ., Li, G., Xu, X., and Kan, M.-Y . V-dpo: Mitigating hallucination in large vision language models via vision- guided direct preference optimization. InFindings of the Association for Computational Linguistics: EMNLP 2024, pp. 13258–13273, 2024. Yang, Z., Luo, X., Han, D., Xu, Y ., and Li, D. Mitig...
2025
-
[9]
URL https: //aclanthology.org/2025.acl-long.640/
doi: 10.18653/v1/2025.acl-long.640. URL https: //aclanthology.org/2025.acl-long.640/. Yu, T., Yao, Y ., Zhang, H., He, T., Han, Y ., Cui, G., Hu, J., Liu, Z., Zheng, H.-T., Sun, M., et al. Rlhf-v: To- wards trustworthy mllms via behavior alignment from fine-grained correctional human feedback. InProceed- ings of the IEEE/CVF Conference on Computer Vision ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.