Generalized Intention Modeling in Multi-Agent Reinforcement Learning
Pith reviewed 2026-06-28 23:01 UTC · model grok-4.3
The pith
Opponent intent in multi-agent RL is best modeled by a performance-driven mixture of representations rather than any single fixed embedding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
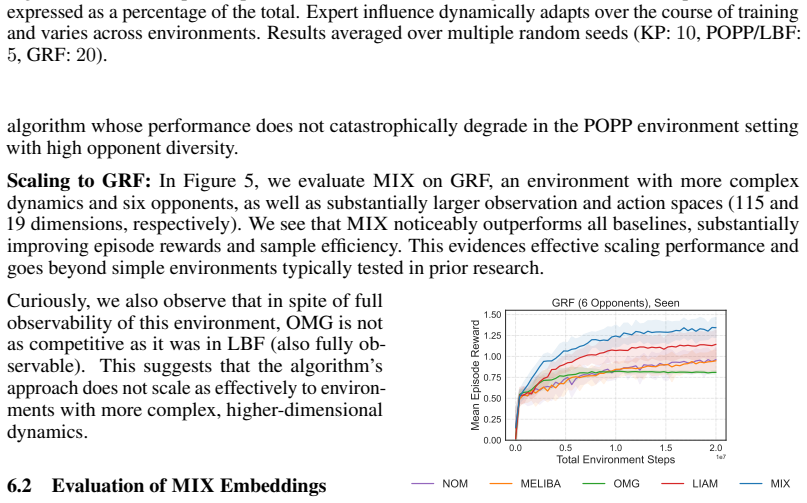
We introduce a task-adaptive opponent modeling framework that learns a performance-driven mixture of multiple intent representations. We further introduce a new intention representation that maximizes mutual information with the ego-agent's future returns, thereby capturing opponent information that is most directly relevant to performance. Our approach consistently matches or exceeds the performance of state-of-the-art baselines across diverse tasks and yields insights into when and why different opponent modeling strategies succeed.
What carries the argument
A performance-driven mixture of intent representations that includes a mutual-information maximizer between opponent features and the agent's future returns.
If this is right
- The framework adapts intent modeling to the specific task and environment without manual selection of features.
- It provides empirical insights into the conditions under which different opponent modeling strategies perform well.
- Agents can achieve competitive performance in non-cooperative and general-sum settings by focusing on performance-relevant opponent information.
Where Pith is reading between the lines
- This approach implies that intent representations should be evaluated by their downstream effect on returns rather than by how faithfully they reconstruct opponent behavior.
- Similar mixtures could be tested in single-agent settings where the 'opponent' is environmental uncertainty.
- The mutual information term may generalize to other value-based objectives beyond returns.
Load-bearing premise
That a performance-driven mixture of intent representations can be learned reliably without excessive overfitting or computational cost, and that the mutual-information representation captures the most performance-relevant opponent information.
What would settle it
A controlled experiment on a new multi-agent task where forcing the model to use only one fixed representation, such as next actions, yields higher returns than the learned mixture.
Figures









read the original abstract
Modeling an opponent's intent is critical for effective decision-making in non-cooperative, competitive, and general-sum multi-agent reinforcement learning. Existing opponent modeling methods encode intent using an embedding derived from episode information chosen a priori, such as the opponent's next action or a future environment state, and use this to guide the ego-agent's behavior. These approaches assume that the chosen information is universally representative of intent; however, we show empirically that this is not the case as intentions are often task- and environment-dependent. To address this, we introduce a task-adaptive opponent modeling framework that learns a performance-driven mixture of multiple intent representations. We further introduce a new intention representation that maximizes mutual information with the ego-agent's future returns, thereby capturing opponent information that is most directly relevant to performance. Our approach consistently matches or exceeds the performance of state-of-the-art baselines across diverse tasks and yields insights into when and why different opponent modeling strategies succeed.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a task-adaptive opponent modeling framework for multi-agent reinforcement learning. It learns a performance-driven mixture of multiple intent representations (rather than fixing one a priori such as next action or future state) and adds a new mutual-information representation that maximizes MI between opponent information and the ego agent's future returns. The central empirical claim is that the resulting method matches or exceeds state-of-the-art baselines across diverse tasks while also providing insights into when different opponent-modeling strategies succeed.
Significance. If the performance claims are supported by the experiments, the work would offer a practical way to relax the strong assumption that a single, hand-chosen intent encoding is universally representative. The MI-based representation is a concrete, performance-oriented alternative that could be useful in general-sum settings. The mixture approach also supplies a mechanism for task-dependent selection, which is a natural extension of existing opponent-modeling literature.
minor comments (3)
- The abstract states that the approach 'consistently matches or exceeds' baselines, but the provided text supplies no equations, algorithm pseudocode, or experimental protocol. The full manuscript should include the precise mixture-learning objective, the MI estimator, and the list of baselines with their hyper-parameters so that the performance claim can be reproduced.
- The claim that existing methods 'assume that the chosen information is universally representative' would be strengthened by a short table or paragraph in §2 or §3 that explicitly lists the information sources used by the cited baselines (e.g., action, state, reward) and shows the empirical counter-examples mentioned in the abstract.
- Notation for the new MI representation (I(opponent info; ego return)) should be introduced once, with a clear definition of the random variables involved, before any experimental results that rely on it.
Simulated Author's Rebuttal
We thank the referee for the positive review, accurate summary of our contributions, and recommendation for minor revision. The significance assessment aligns with our goals of relaxing fixed intent encodings via a performance-driven mixture and introducing an MI-based representation tied to ego-agent returns.
Circularity Check
No significant circularity detected
full rationale
The paper is an empirical contribution that introduces a new task-adaptive mixture framework and an MI-based intent representation for opponent modeling in MARL. No derivation chain, first-principles predictions, or equations are presented that reduce by construction to fitted parameters or self-citations. Claims rest on performance comparisons across tasks rather than any self-definitional or load-bearing self-citation structure. The approach is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Intentions are task- and environment-dependent rather than universally captured by any single fixed representation.
Reference graph
Works this paper leans on
-
[1]
OpenSpiel: A Framework for Reinforcement Learning in Games.CoRR, abs/1908.09453, 2019
Marc Lanctot, Edward Lockhart, Jean-Baptiste Lespiau, Vinicius Zambaldi, Satyaki Upadhyay, Julien Pérolat, Sriram Srinivasan, Finbarr Timbers, Karl Tuyls, Shayegan Omidshafiei, Daniel Hennes, Dustin Morrill, Paul Muller, Timo Ewalds, Ryan Faulkner, János Kramár, Bart De Vylder, Brennan Saeta, James Bradbury, David Ding, Sebastian Borgeaud, Matthew Lai, Ju...
-
[2]
Wang, Sarah A
Rose E. Wang, Sarah A. Wu, James A. Evans, Joshua B. Tenenbaum, David C. Parkes, and Max Kleiman-Weiner. Too many cooks: Coordinating multi-agent collaboration through inverse planning. InProceedings of the 19th International Conference on Autonomous Agents and MultiAgent Systems, page 2032–2034,
2032
-
[3]
Learning latent repre- sentations to influence multi-agent interaction
Annie Xie, Dylan Losey, Ryan Tolsma, Chelsea Finn, and Dorsa Sadigh. Learning latent repre- sentations to influence multi-agent interaction. InProceedings of the 2020 Conference on Robot Learning, volume 155, pages 575–588,
2020
-
[4]
Run to Score with Keeper
12 A Environment Implementation Details All environments use discrete action spaces. For Kuhn Poker, we train for 2 million steps, evaluating every 50 thousand steps over 10,000 episodes. For POPP, LBF, and GRF, we train for 20 million environment steps, evaluating over200 episodes every 120 thousand steps (POPP and LBF) or 400 thousand steps (GRF). A.1 K...
2019
-
[5]
Run to Score with Keeper
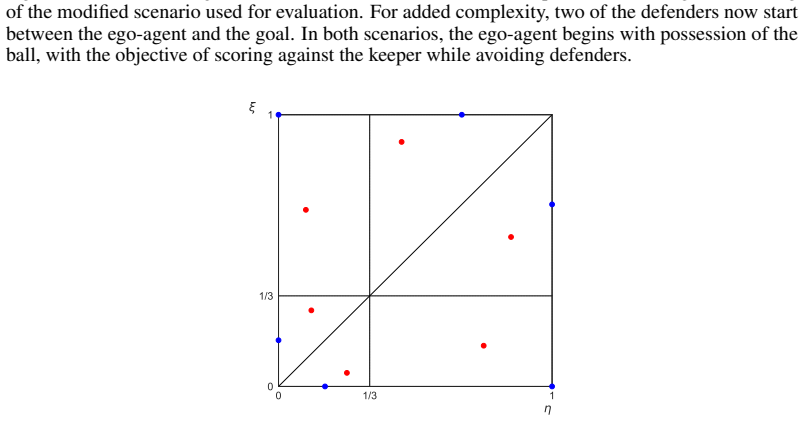
B Opponent Policies In our implementation of Kuhn Poker, the opponent always plays as the second player (P2 ). Viable P2 strategies can be parameterized by two variables, η and ξ, which govern the probability of betting at two specific decision points (facing a pass with a Jack, and facing a bet with a Queen) [Southey et al., 2009]. The optimal strategy l...
2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.