Scaling Conversational Hungarian ASR: The BEA-Dialogue+ Corpus
Pith reviewed 2026-06-28 22:45 UTC · model grok-4.3
The pith
BEA-Dialogue+ scales Hungarian dialogue ASR data to 200 hours by relaxing speaker-disjoint rules for non-primary roles.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
BEA-Dialogue+ demonstrates that increasing training data volume through controlled speaker overlap raises difficulty for unadapted models yet supports consistent performance gains via SOT-based fine-tuning on Whisper- and FastConformer-based systems, measured across standard error rates for dialogue transcription.
What carries the argument
The relaxed speaker-disjoint split that preserves complete separation of primary speakers while allowing overlap for experimenters and dialogue partners.
If this is right
- Without adaptation the larger corpus produces higher error rates than the smaller one.
- SOT fine-tuning delivers measurable reductions in all four error metrics on both corpus versions.
- The expanded resource supports training of dialogue transcription systems at greater scale.
- The design isolates the effect of data volume from primary-speaker overlap.
Where Pith is reading between the lines
- Similar relaxed-split strategies could scale dialogue corpora in other languages with limited speaker-disjoint data.
- The same size-versus-overlap trade-off could be tested by varying the degree of allowed overlap while tracking evaluation validity.
- Models trained on BEA-Dialogue+ might generalize better to real-world multi-speaker settings that include non-primary voices.
Load-bearing premise
Relaxing speaker separation only for experimenters and dialogue partners still yields evaluation splits whose difficulty matches that of the strictly disjoint original corpus.
What would settle it
A direct comparison in which unadapted models achieve equal or lower error rates on the 200-hour set than on the 85-hour set, or in which SOT adaptation fails to reduce WER, CER, cpWER, or cpCER.
Figures
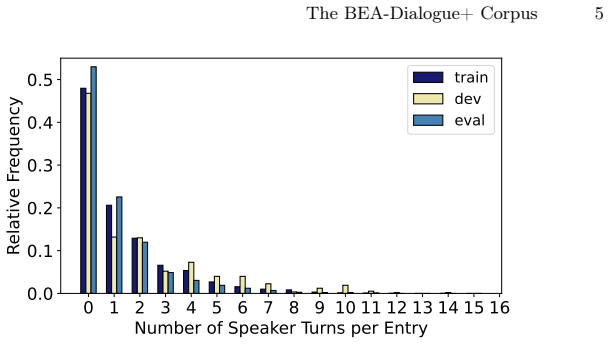
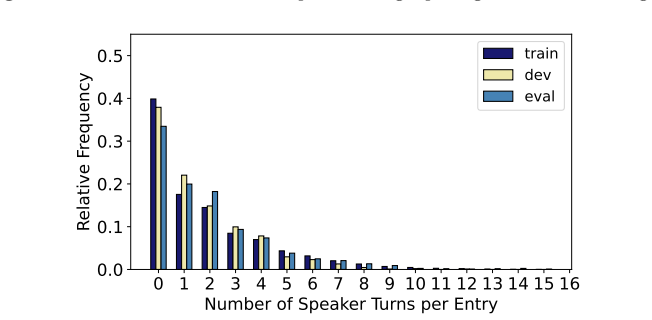
read the original abstract
Conversational automatic speech recognition in Hungarian is constrained by the limited amount of publicly available dialogue-style training data. The BEA-Dialogue corpus addresses this need, but its strictly speaker-disjoint train/dev/eval split reduces the usable material to only 85 hours. In this paper, we introduce BEA-Dialogue+, an expanded version of the corpus that relaxes the split criterion for experimenters and dialogue partners while preserving complete separation of the primary speakers. This results in 200 hours of transcribed natural conversations and enables a controlled study of the trade-off between additional training data and speaker overlap across the splits. We evaluate several Whisper- and FastConformer-based models on both corpus versions, including Serialized Output Training (SOT)-based fine-tuning for dialogue transcription. Our results show that the larger corpus is more challenging for models without fine-tuning, whereas SOT-based adaptation yields consistent improvements in WER, CER, cpWER, and cpCER. Overall, BEA-Dialogue+ provides a substantially larger yet still demanding benchmark for Hungarian dialogue ASR, and a practical resource for training and evaluating dialogue transcription systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BEA-Dialogue+, an expanded 200-hour Hungarian conversational ASR corpus obtained by relaxing the speaker-disjoint split criterion for experimenters and dialogue partners (while preserving separation of primary speakers) from the original 85-hour BEA-Dialogue corpus. It evaluates Whisper- and FastConformer-based models on both versions, with and without Serialized Output Training (SOT) fine-tuning, and claims that the larger corpus is more challenging without fine-tuning while SOT adaptation produces consistent gains in WER, CER, cpWER, and cpCER.
Significance. If the evaluation splits remain comparable in difficulty, the work supplies a substantially larger public benchmark for Hungarian dialogue ASR and demonstrates the practical value of SOT-based adaptation for multi-speaker transcription. The corpus release itself constitutes a concrete resource contribution for low-resource conversational ASR.
major comments (2)
- [Abstract and §3] Abstract and §3 (Corpus Construction): the central claim that the relaxed split 'enables a controlled study of the trade-off between additional training data and speaker overlap' rests on the unverified assumption that the new eval split has essentially the same inherent difficulty as the original 85-hour eval split. No quantitative comparison of turn-taking statistics, dialogue length distributions, or acoustic conditions between the two eval sets is reported, so the observed WER increase cannot be unambiguously attributed to data size versus overlap.
- [Results] Results section (and abstract claim of 'consistent improvements'): the reported gains from SOT adaptation are presented without error bars, statistical significance tests, or details on training procedures, hyper-parameters, data exclusion rules, or number of runs. This prevents verification of whether the improvements are robust or merely within-run variation.
minor comments (2)
- [Tables] Table captions and metric definitions (cpWER, cpCER) should explicitly state whether they are computed at the dialogue or utterance level and how speaker attribution is handled.
- [§3] The paper would benefit from an explicit statement of the exact hours retained after each filtering step when constructing the 200-hour training set.
Simulated Author's Rebuttal
We thank the referee for the thoughtful comments, which help clarify the presentation of our contributions. We respond to each major comment below and will incorporate revisions to address the concerns raised.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Corpus Construction): the central claim that the relaxed split 'enables a controlled study of the trade-off between additional training data and speaker overlap' rests on the unverified assumption that the new eval split has essentially the same inherent difficulty as the original 85-hour eval split. No quantitative comparison of turn-taking statistics, dialogue length distributions, or acoustic conditions between the two eval sets is reported, so the observed WER increase cannot be unambiguously attributed to data size versus overlap.
Authors: The controlled nature of the study derives from preserving complete separation of all primary speakers while relaxing the split only for experimenters and dialogue partners; this isolates the effect of increased training data volume under a specific, limited form of overlap. Nevertheless, we agree that explicit quantitative comparisons between the two evaluation sets would strengthen the interpretation. In the revised manuscript we will add a table (or subsection) in §3 reporting turn-taking statistics, dialogue length distributions, and any available acoustic metadata for both the original and expanded evaluation splits. This will allow readers to assess potential differences in inherent difficulty. revision: yes
-
Referee: [Results] Results section (and abstract claim of 'consistent improvements'): the reported gains from SOT adaptation are presented without error bars, statistical significance tests, or details on training procedures, hyper-parameters, data exclusion rules, or number of runs. This prevents verification of whether the improvements are robust or merely within-run variation.
Authors: We accept that the current Results section does not provide sufficient information to evaluate robustness. In the revision we will (i) report means and standard deviations across multiple independent runs with different random seeds, (ii) include statistical significance tests comparing SOT versus baseline performance, and (iii) add explicit details on training hyperparameters, data exclusion rules, and the number of runs. These additions will appear in the main Results section with supporting material placed in an appendix if needed. revision: yes
Circularity Check
No circularity: purely empirical corpus release and model evaluation
full rationale
The paper introduces an expanded dialogue corpus by relaxing speaker-disjoint rules for non-primary speakers and reports empirical WER/CER results on Whisper and FastConformer models with and without SOT fine-tuning. No equations, derivations, fitted parameters, or load-bearing self-citations appear in the provided text or abstract. The central claims are direct experimental observations (larger corpus more challenging without fine-tuning; SOT yields improvements) rather than any derived result that reduces to its own inputs by construction. The skeptic concern about eval-split comparability is a methodological question about experimental controls, not a circularity in any derivation chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Language modeling for au- tomatic turkish broadcast news transcription
Ebru Arısoy, Haşim Sak, and Murat Saraçlar. Language modeling for au- tomatic turkish broadcast news transcription. InInterspeech 2007, pages 2381–2384, 2007. https://doi.org/10.21437/Interspeech.2007-273
-
[2]
Bestdataismoresuperviseddata–evenforhungarianasr
Gergely Dobsinszki, Péter Mihajlik, Máté Soma Kádár, Tibor Fegyó, and KatalinMády. Bestdataismoresuperviseddata–evenforhungarianasr. In Alexey Karpov and Gábor Gosztolya, editors,Speech and Computer, pages 60–69, Cham, 2026. Springer Nature Switzerland. ISBN 978-3-032-07959-6
2026
-
[3]
Máté Gedeon, Piroska Zsófia Barta, Péter Mihajlik, Tekla Etelka Gráczi, Anna Kohári, and Katalin Mády. Toward conversational hungarian speech recognition: Introducing the BEA-Large and BEA-Dialogue datasets, 2025. URLhttps://arxiv.org/abs/2511.13529
arXiv 2025
-
[4]
Serializedoutputtrainingforend-to-endoverlappedspeechrecog- nition
Naoyuki Kanda, Yashesh Gaur, Xiaofei Wang, Zhong Meng, and Takuya Yoshioka. Serializedoutputtrainingforend-to-endoverlappedspeechrecog- nition. InInterspeech, 2020. URLhttps://api.semanticscholar.org/ CorpusID:214714409
2020
-
[5]
Leakage and the reproducibility crisis in machine-learning-based science.Patterns, 4(9):100804, 2023
Sayash Kapoor and Arvind Narayanan. Leakage and the reproducibility crisis in machine-learning-based science.Patterns, 4(9):100804, 2023. ISSN 2666-3899. https://doi.org/https://doi.org/10.1016/j.patter.2023.100804. URLhttps://www.sciencedirect.com/science/article/pii/ S2666389923001599
-
[6]
Oleksii Kuchaiev, Jason Li, Huyen Nguyen, Oleksii Hrinchuk, Ryan Leary, Boris Ginsburg, Samuel Kriman, Stanislav Beliaev, Vitaly Lavrukhin, Jack Cook, Patrice Castonguay, Mariya Popova, Jocelyn Huang, and Jonathan M. Cohen. Nemo: a toolkit for building ai applications using neural modules, 2019. URLhttps://arxiv.org/abs/1909.09577
arXiv 2019
-
[7]
Re- vised annotation conventions in hungarian speech corpora.Beszédtudomány / Speech Science, 4(1):185–202, 2024
Katalin Mády, Gráczi Tekla Etelka, Anna Kohári, and Péter Mihajlik. Re- vised annotation conventions in hungarian speech corpora.Beszédtudomány / Speech Science, 4(1):185–202, 2024. 18 p
2024
-
[8]
BEA-base: A benchmark for ASR of sponta- neous Hungarian
Peter Mihajlik, Andras Balog, Tekla Etelka Graczi, Anna Kohari, Balázs Tarján, and Katalin Mady. BEA-base: A benchmark for ASR of sponta- neous Hungarian. In Nicoletta Calzolari, Frédéric Béchet, Philippe Blache, Khalid Choukri, Christopher Cieri, Thierry Declerck, Sara Goggi, Hitoshi Isahara, Bente Maegaard, Joseph Mariani, Hélène Mazo, Jan Odijk, and St...
1970
-
[9]
Seza Doğruöz
Peter Mihajlik, Katalin Mády, Anna Kohári, Fruzsina Sára Fruzsina, Gábor Kiss, Tekla Etelka Gráczi, and A. Seza Doğruöz. Is spoken Hungarian low- resource?: A quantitative survey of Hungarian speech data sets. In Nicoletta Calzolari, Min-Yen Kan, Veronique Hoste, Alessandro Lenci, Sakriani Sakti, The BEA-Dialogue+ Corpus 11 and Nianwen Xue, editors,Procee...
2024
-
[10]
Development of a large sponta- neous speech database of agglutinative hungarian language
Tilda Neuberger, Dorottya Gyarmathy, Tekla Etelka Gráczi, Viktória Horváth, Mária Gósy, and András Beke. Development of a large sponta- neous speech database of agglutinative hungarian language. In Petr Sojka, Aleš Horák, Ivan Kopeček, and Karel Pala, editors,Text, Speech and Dia- logue, pages 424–431, Cham, 2014. Springer International Publishing. ISBN 9...
2014
-
[11]
Robust speech recognition via large-scale weak supervision, 2022
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision, 2022. URLhttps://arxiv.org/abs/2212.04356
Pith/arXiv arXiv 2022
-
[12]
Fast conformer with lin- early scalable attention for efficient speech recognition, 2023
Dima Rekesh, Nithin Rao Koluguri, Samuel Kriman, Somshubra Majum- dar, Vahid Noroozi, He Huang, Oleksii Hrinchuk, Krishna Puvvada, Ankur Kumar, Jagadeesh Balam, and Boris Ginsburg. Fast conformer with lin- early scalable attention for efficient speech recognition, 2023. URLhttps: //arxiv.org/abs/2305.05084
arXiv 2023
-
[13]
Vincent Roger, Jérôme Farinas, and Julien Pinquier. Deep neural networks for automatic speech processing: A survey from large corpora to limited data, 2020. URLhttps://arxiv.org/abs/2003.04241
arXiv 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.