DiffCrossGait: Trajectory-Level Alignment for 2D-3D Cross-Modal Gait Recognition via Latent Diffusion
Pith reviewed 2026-06-28 23:03 UTC · model grok-4.3
The pith
Driving both 2D silhouettes and 3D LiDAR data with shared Gaussian noise in a latent diffusion space aligns their full trajectories for cross-modal gait recognition.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
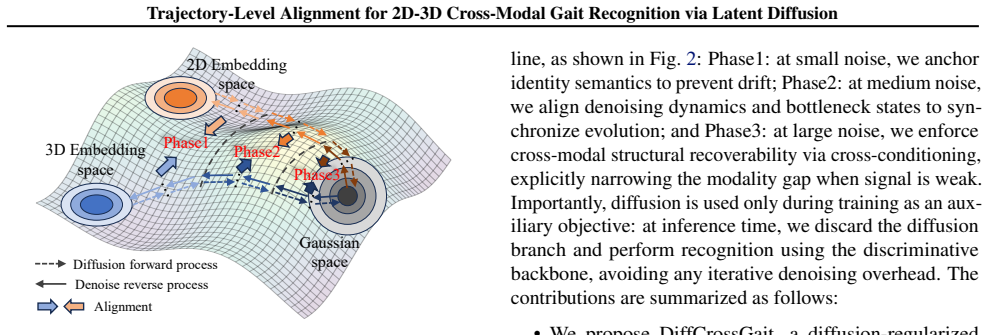
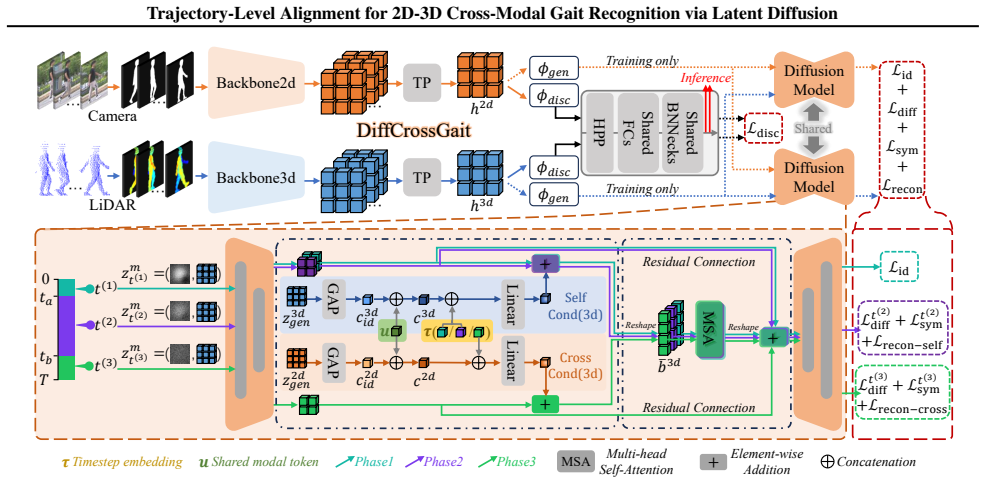
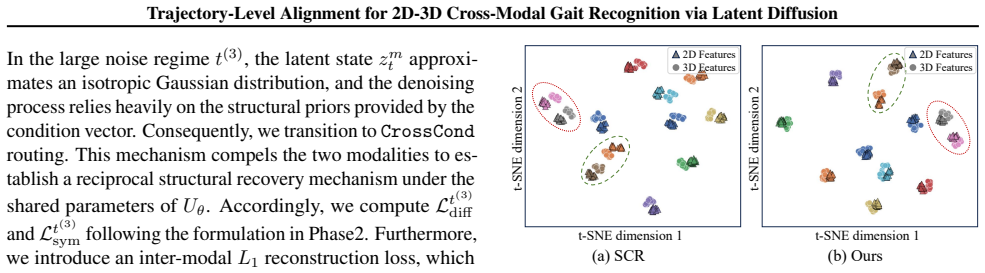
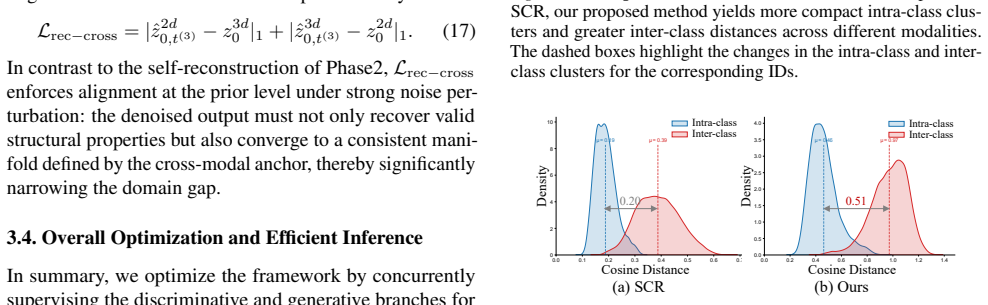
DiffCrossGait reformulates cross-modal matching as trajectory-level alignment in an identity-relevant latent diffusion space. By driving both modalities with shared Gaussian noise, continuous alignment occurs throughout the generative evolution. A Tri-Phase Alignment Strategy exploits varying noise intensities to enforce identity anchoring, dynamics consistency, and cross-modal structural recoverability, thereby constraining both modalities to share denoising dynamics and bottleneck structure. The framework decouples generative alignment from the discriminative backbone; the diffusion mechanism serves exclusively as a training objective, ensuring high inference efficiency by eliminating iter
What carries the argument
The Tri-Phase Alignment Strategy that exploits varying noise intensities to enforce identity anchoring, dynamics consistency, and cross-modal structural recoverability while sharing Gaussian noise across modalities in latent diffusion space.
If this is right
- Alignment occurs continuously across the full diffusion trajectory rather than only at final embeddings.
- Modality-invariant gait features emerge while the separate discriminative backbone retains its power.
- Iterative denoising is removed at inference, yielding high computational efficiency.
- State-of-the-art cross-modal performance is obtained on the SUSTech1K and FreeGait benchmarks.
Where Pith is reading between the lines
- The separation of the alignment objective from the backbone may permit the same recognition network to pair with multiple sensor-specific diffusion trainers.
- The approach could be tested on other cross-modal biometric tasks where one modality is easier to collect than the other.
- Further experiments could check whether the three-phase noise schedule is necessary or whether a single shared noise process suffices.
Load-bearing premise
Enforcing shared denoising dynamics and bottleneck structure via the Tri-Phase Alignment Strategy produces modality-invariant gait features while preserving the discriminative power of the separate backbone network.
What would settle it
Replacing the shared Gaussian noise schedule with independent noise for each modality during training and measuring whether cross-modal matching accuracy on the benchmarks falls below the reported state-of-the-art levels.
Figures

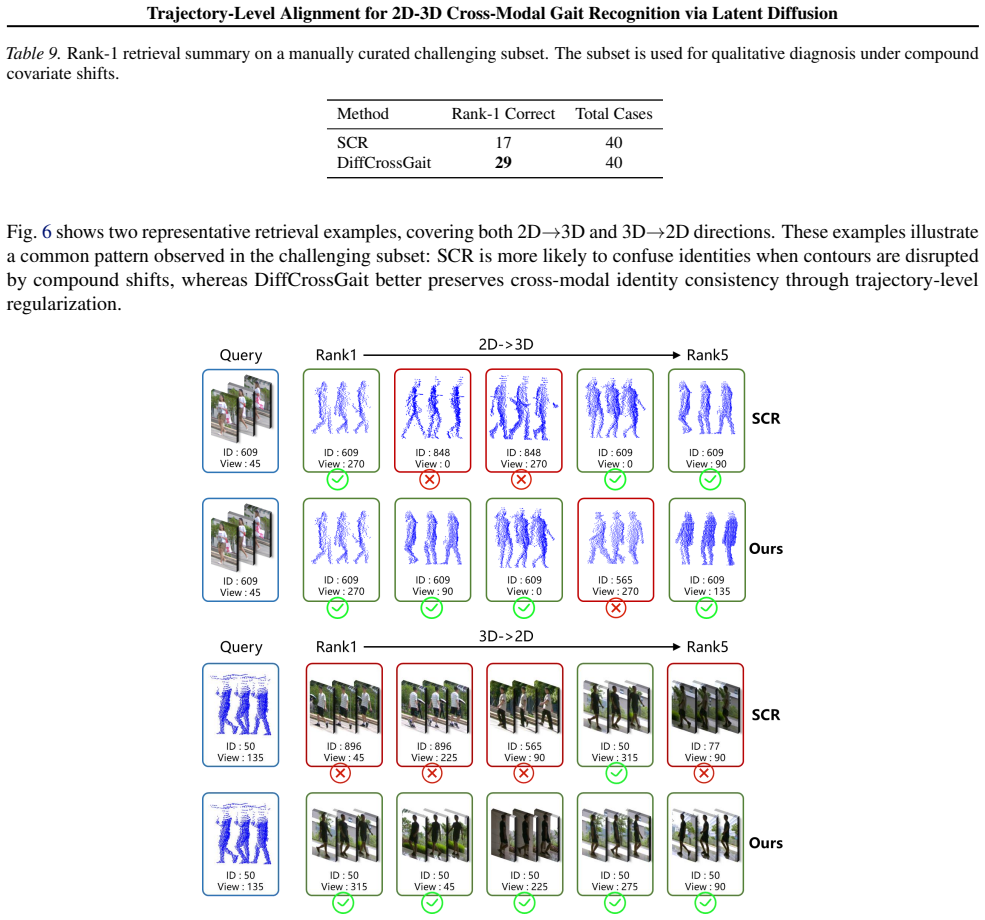
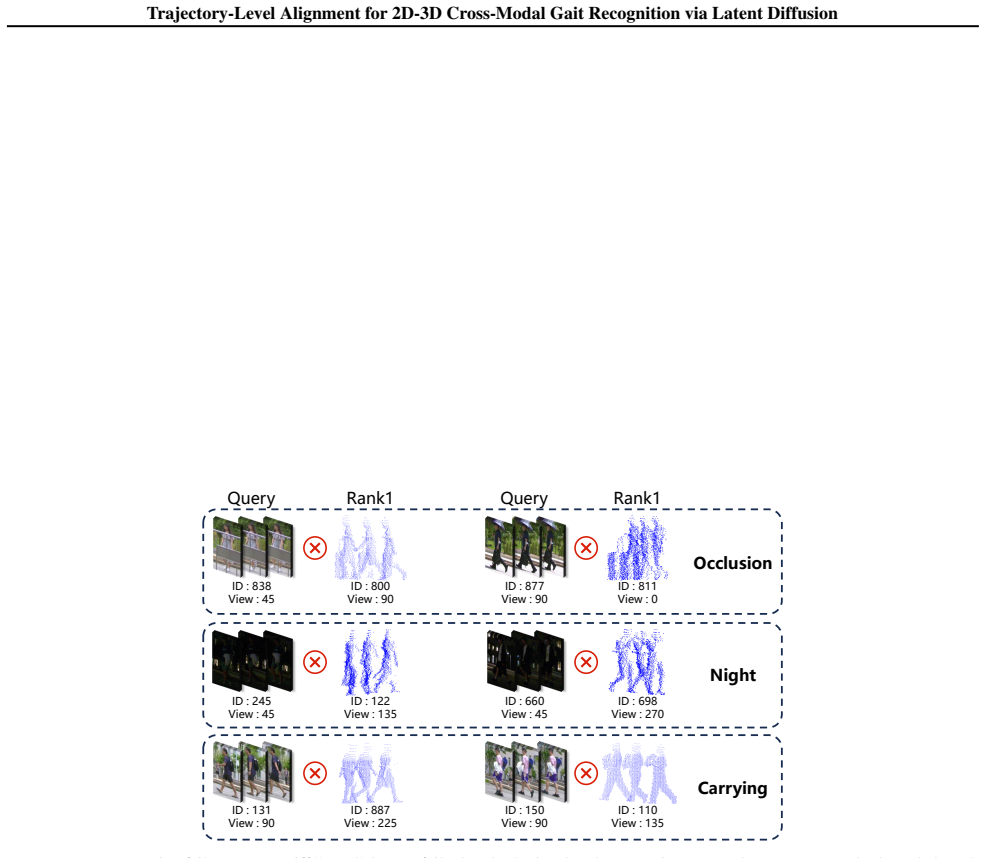
read the original abstract
Cross-modal 2D-3D gait recognition is impeded by inherent domain discrepancies between 2D silhouette and 3D LiDAR range-view representations. While prior methods align only final embeddings, we propose DiffCrossGait, which reformulates cross-modal matching as trajectory-level alignment in an identity-relevant latent diffusion space, rather than assuming full equivalence between 2D and 3D observations. By driving both modalities with shared Gaussian noise within a latent space, we enable continuous alignment throughout the generative evolution. We introduce a Tri-Phase Alignment Strategy that exploits varying noise intensities to enforce identity anchoring, dynamics consistency, and cross-modal structural recoverability, thereby constraining both modalities to share denoising dynamics and bottleneck structure, which promotes modality-invariant gait features. Crucially, our framework decouples generative alignment from the discriminative backbone; the diffusion mechanism serves exclusively as a training objective, ensuring high inference efficiency by eliminating the computational overhead of iterative denoising. Extensive experiments on the SUSTech1K and FreeGait benchmarks demonstrate that DiffCrossGait achieves state-of-the-art performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DiffCrossGait for 2D-3D cross-modal gait recognition. It reformulates matching as trajectory-level alignment in an identity-relevant latent diffusion space by driving both modalities with shared Gaussian noise. A Tri-Phase Alignment Strategy (identity anchoring, dynamics consistency, cross-modal structural recoverability) is introduced to constrain modalities to share denoising dynamics and bottleneck structure. The diffusion process is decoupled from the discriminative backbone and used only as a training objective. Experiments on SUSTech1K and FreeGait are stated to achieve SOTA performance.
Significance. If the central claim holds, the method offers a way to perform cross-modal alignment via generative dynamics during training without incurring iterative denoising costs at inference, which could improve efficiency in gait recognition pipelines while addressing domain gaps between 2D silhouettes and 3D LiDAR views.
major comments (1)
- [Abstract] Abstract (paragraph on Tri-Phase Alignment Strategy and decoupling): the claim that the Tri-Phase strategy 'constrains both modalities to share denoising dynamics and bottleneck structure, which promotes modality-invariant gait features' while the diffusion 'serves exclusively as a training objective' is load-bearing for the central claim, yet the text provides no indication of the mechanism (e.g., whether latents are extracted from backbone encoders, whether a joint loss back-propagates to the backbones, or whether encoders are updated during diffusion training). This leaves open whether the alignment actually reaches the inference-time embeddings.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the abstract. The concern about the mechanism linking the Tri-Phase Alignment Strategy to the inference-time embeddings is valid, and we will revise the abstract and method description to make this explicit.
read point-by-point responses
-
Referee: [Abstract] Abstract (paragraph on Tri-Phase Alignment Strategy and decoupling): the claim that the Tri-Phase strategy 'constrains both modalities to share denoising dynamics and bottleneck structure, which promotes modality-invariant gait features' while the diffusion 'serves exclusively as a training objective' is load-bearing for the central claim, yet the text provides no indication of the mechanism (e.g., whether latents are extracted from backbone encoders, whether a joint loss back-propagates to the backbones, or whether encoders are updated during diffusion training). This leaves open whether the alignment actually reaches the inference-time embeddings.
Authors: The latents are extracted directly from the modality-specific backbone encoders. The diffusion loss (computed on these latents under shared noise) is combined with the discriminative loss and back-propagates to update the encoders during training. Consequently, the alignment constraints are embedded in the final representations used at inference. The diffusion process itself is discarded after training and plays no role at test time. We will revise the abstract to state this mechanism explicitly and add a short paragraph in Section 3 clarifying the training flow. revision: yes
Circularity Check
No circularity; independent training objective with decoupled diffusion
full rationale
The paper introduces a new auxiliary training objective (latent diffusion with shared Gaussian noise and Tri-Phase Alignment Strategy) applied to the 2D/3D backbones during training only. The claimed modality-invariant features arise from gradients of this explicit loss rather than from any redefinition of the target embeddings, fitted parameters renamed as predictions, or self-citation chains. No equation or step reduces the final discriminative representations to the alignment mechanism by construction; the decoupling is stated explicitly and the performance claims rest on external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
International Conference on Machine Learning , pages=
Learning transferable visual models from natural language supervision , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[2]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Promptkd: Unsupervised prompt distillation for vision-language models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[3]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Align-KD: Distilling Cross-Modal Alignment Knowledge for Mobile Vision-Language Large Model Enhancement , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[4]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Move-kd: Knowledge distillation for vlms with mixture of visual encoders , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[5]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
VL2Lite: Task-Specific Knowledge Distillation from Large Vision-Language Models to Lightweight Networks , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[6]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
VLMs-Guided Representation Distillation for Efficient Vision-Based Reinforcement Learning , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[7]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Partdistill: 3d shape part segmentation by vision-language model distillation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[8]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Visual program distillation: Distilling tools and programmatic reasoning into vision-language models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[9]
International Journal of Computer Vision , volume=
Learning to prompt for vision-language models , author=. International Journal of Computer Vision , volume=. 2022 , publisher=
2022
-
[10]
IEEE Transactions on Image Processing , volume=
Clip-driven fine-grained text-image person re-identification , author=. IEEE Transactions on Image Processing , volume=. 2023 , publisher=
2023
-
[11]
IEEE Transactions on Multimedia , year=
Clip-driven semantic discovery network for visible-infrared person re-identification , author=. IEEE Transactions on Multimedia , year=
-
[12]
Proceedings of the 31st ACM international conference on multimedia , pages=
Symmetrical linguistic feature distillation with clip for scene text recognition , author=. Proceedings of the 31st ACM international conference on multimedia , pages=
-
[13]
European Conference on Computer Vision , pages=
Ttd: Text-tag self-distillation enhancing image-text alignment in clip to alleviate single tag bias , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[14]
IEEE Transactions on Information Forensics and Security , year=
Video-Level Language-Driven Video-Based Visible-Infrared Person Re-Identification , author=. IEEE Transactions on Information Forensics and Security , year=
-
[15]
IEEE Transactions on Multimedia , year=
CLIP-Based Modality Compensation for Visible-Infrared Image Re-Identification , author=. IEEE Transactions on Multimedia , year=
-
[16]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
Individual recognition using gait energy image , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=. 2005 , publisher=
2005
-
[17]
IEEE International Conference on Automatic Face Gesture Recognition , pages=
Silhouette-based human identification from body shape and gait , author=. IEEE International Conference on Automatic Face Gesture Recognition , pages=. 2002 , organization=
2002
-
[18]
European Conference on Computer Vision , pages=
Chrono-gait image: A novel temporal template for gait recognition , author=. European Conference on Computer Vision , pages=. 2010 , organization=
2010
-
[19]
IEEE Transactions on Multimedia , volume=
Human gait recognition based on frontal-view sequences using gait dynamics and deep learning , author=. IEEE Transactions on Multimedia , volume=. 2023 , publisher=
2023
-
[20]
IEEE Transactions on Multimedia , year=
GaitParsing: Human semantic parsing for gait recognition , author=. IEEE Transactions on Multimedia , year=
-
[21]
IEEE Transactions on Multimedia , year=
Gait Recognition With Multi-Level Skeleton-Guided Refinement , author=. IEEE Transactions on Multimedia , year=
-
[22]
IEEE Transactions on Multimedia , volume=
A strong and robust skeleton-based gait recognition method with gait periodicity priors , author=. IEEE Transactions on Multimedia , volume=. 2022 , publisher=
2022
-
[23]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Gaitset: Regarding gait as a set for cross-view gait recognition , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[24]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
GaitSet: Cross-view gait recognition through utilizing gait as a deep set , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=. 2021 , publisher=
2021
-
[25]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Opengait: Revisiting gait recognition towards better practicality , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[26]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Gaitpart: Temporal part-based model for gait recognition , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[27]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Context-sensitive temporal feature learning for gait recognition , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[28]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Gait recognition via effective global-local feature representation and local temporal aggregation , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[29]
European Conference on Computer Vision , pages=
Camera-LiDAR Cross-modality Gait Recognition , author=. European Conference on Computer Vision , pages=. 2025 , organization=
2025
-
[30]
IEEE International Joint Conference on Biometrics , pages=
Cross-Modality Gait Recognition: Bridging LiDAR and Camera Modalities for Human Identification , author=. IEEE International Joint Conference on Biometrics , pages=. 2024 , organization=
2024
-
[31]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Gait recognition in the wild with dense 3d representations and a benchmark , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[32]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Lidargait: Benchmarking 3d gait recognition with point clouds , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[33]
Proceedings of the ACM International Conference on Multimedia , pages=
Gait Recognition in Large-scale Free Environment via Single LiDAR , author=. Proceedings of the ACM International Conference on Multimedia , pages=
-
[34]
IEEE Transactions on Biometrics, Behavior, and Identity Science , year=
A Comprehensive Survey on Deep Gait Recognition: Algorithms, Datasets, and Challenges , author=. IEEE Transactions on Biometrics, Behavior, and Identity Science , year=
-
[35]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
SkeletonGait: Gait Recognition Using Skeleton Maps , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[36]
Pattern Recognition , volume=
A model-based gait recognition method with body pose and human prior knowledge , author=. Pattern Recognition , volume=. 2020 , publisher=
2020
-
[37]
IEEE International Conference on Image Processing , pages=
Gaitgraph: Graph convolutional network for skeleton-based gait recognition , author=. IEEE International Conference on Image Processing , pages=. 2021 , organization=
2021
-
[38]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
The humanid gait challenge problem: Data sets, performance, and analysis , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=. 2005 , publisher=
2005
-
[39]
IEEE Transactions on Information Forensics and Security , volume=
The OU-ISIR gait database comprising the large population dataset and performance evaluation of gait recognition , author=. IEEE Transactions on Information Forensics and Security , volume=. 2012 , publisher=
2012
-
[40]
International Conference on Pattern Recognition , volume=
A framework for evaluating the effect of view angle, clothing and carrying condition on gait recognition , author=. International Conference on Pattern Recognition , volume=. 2006 , organization=
2006
-
[41]
IEEE Transactions on Multimedia , year=
Gait Recognition With Drones: A Benchmark , author=. IEEE Transactions on Multimedia , year=
-
[42]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Gait recognition in the wild: A benchmark , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[43]
IEEE Transactions on Image Processing , volume=
Cross-view gait recognition by discriminative feature learning , author=. IEEE Transactions on Image Processing , volume=. 2019 , publisher=
2019
-
[44]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
3d local convolutional neural networks for gait recognition , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[45]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Relational knowledge distillation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[46]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
A comprehensive overhaul of feature distillation , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[47]
, author=
Visualizing data using t-SNE. , author=. Journal of Machine Learning Research , volume=
-
[48]
IEEE Transactions on Information Forensics and Security , year=
EGST: An Efficient Solution for Human Gaits Recognition Using Neuromorphic Vision Sensor , author=. IEEE Transactions on Information Forensics and Security , year=
-
[49]
International Conference on Machine Learning , pages=
Scaling up visual and vision-language representation learning with noisy text supervision , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[50]
International Conference on Machine Learning , pages=
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[51]
Advances in Neural Information Processing Systems , volume=
Flamingo: a visual language model for few-shot learning , author=. Advances in Neural Information Processing Systems , volume=
-
[52]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Deep residual learning for image recognition , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[53]
Advances in Neural Information Processing Systems , volume=
Attention is all you need , author=. Advances in Neural Information Processing Systems , volume=
-
[54]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Multi-modal gait recognition via effective spatial-temporal feature fusion , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[55]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Learning visual prompt for gait recognition , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[56]
RA-GAR: A Richly Annotated Benchmark for Gait Attribute Recognition , booktitle =
Wang, Chenye and Hou, Saihui and Li, Aoqi and Cai, Qingyuan and Huang, Yongzhen , year =. RA-GAR: A Richly Annotated Benchmark for Gait Attribute Recognition , booktitle =
-
[57]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
On Denoising Walking Videos for Gait Recognition , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[58]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Bridging gait recognition and large language models sequence modeling , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[59]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Exploring more from multiple gait modalities for human identification , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[60]
Advances in Neural Information Processing Systems , volume=
Empowering visible-infrared person re-identification with large foundation models , author=. Advances in Neural Information Processing Systems , volume=
-
[61]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Implicit discriminative knowledge learning for visible-infrared person re-identification , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[62]
IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
OpenGait: A Comprehensive Benchmark Study for Gait Recognition towards Better Practicality , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
-
[63]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Gpgait: Generalized pose-based gait recognition , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[64]
IEEE Transactions on Biometrics, Behavior, and Identity Science , volume=
A multi-stage adaptive feature fusion neural network for multimodal gait recognition , author=. IEEE Transactions on Biometrics, Behavior, and Identity Science , volume=. 2024 , publisher=
2024
-
[65]
IEEE Transactions on Circuits and Systems for Video Technology , year=
GaitC3: Robust cross-covariate gait recognition via causal intervention , author=. IEEE Transactions on Circuits and Systems for Video Technology , year=
-
[66]
Proceedings of the ACM International Conference on Multimedia , pages=
It takes two: Accurate gait recognition in the wild via cross-granularity alignment , author=. Proceedings of the ACM International Conference on Multimedia , pages=
-
[67]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
LidarGait++: Learning Local Features and Size Awareness from LiDAR Point Clouds for 3D Gait Recognition , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[68]
IEEE Transactions on Information Forensics and Security , year=
MOJO: MOtion Pattern Learning and JOint-based Fine-grained Mining for Person Re-identification Based on 4D LiDAR Point Clouds , author=. IEEE Transactions on Information Forensics and Security , year=
-
[69]
Advances in Neural Information Processing Systems , volume=
Cross-video identity correlating for person re-identification pre-training , author=. Advances in Neural Information Processing Systems , volume=
-
[70]
Pattern Recognition , volume=
Temporal knowledge graph reasoning based on discriminative neighboring semantic learning , author=. Pattern Recognition , volume=. 2025 , publisher=
2025
-
[71]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
DREAM: Decoupled Discriminative Learning with Bigraph-aware Alignment for Semi-supervised 2D-3D Cross-modal Retrieval , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[72]
European Conference on Computer Vision , pages=
X-instructblip: A framework for aligning image, 3d, audio, video to llms and its emergent cross-modal reasoning , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[73]
Advanced Science , volume=
Multimodal sensors with decoupled sensing mechanisms , author=. Advanced Science , volume=. 2022 , publisher=
2022
-
[74]
BMC Sports Science, Medicine and Rehabilitation , volume=
Accuracy validation of a wearable IMU-based gait analysis in healthy female , author=. BMC Sports Science, Medicine and Rehabilitation , volume=. 2024 , publisher=
2024
-
[75]
Optics & Laser Technology , volume=
Polymer optical fiber and fiber Bragg grating sensors for biomedical engineering Applications: A comprehensive review , author=. Optics & Laser Technology , volume=. 2024 , publisher=
2024
-
[76]
Engineering Applications of Artificial Intelligence , volume=
Advancements in artificial intelligence for biometrics: a deep dive into model-based gait recognition techniques , author=. Engineering Applications of Artificial Intelligence , volume=. 2024 , publisher=
2024
-
[77]
Multimedia Tools and Applications , volume=
Human gait recognition: A systematic review , author=. Multimedia Tools and Applications , volume=. 2023 , publisher=
2023
-
[78]
ACM Computing Surveys , volume=
Gait recognition based on deep learning: a survey , author=. ACM Computing Surveys , volume=. 2022 , publisher=
2022
-
[79]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Cloud-device collaborative learning for multimodal large language models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[80]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Fine-grained prototypical voting with heterogeneous mixup for semi-supervised 2d-3d cross-modal retrieval , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.