Feature Alignment Determines Fusion Strategy: A Comparative Study of Cross-Attention and Concatenation in Multimodal Learning
Pith reviewed 2026-06-28 17:18 UTC · model grok-4.3
The pith
Feature alignment quality determines which multimodal fusion strategy performs better.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
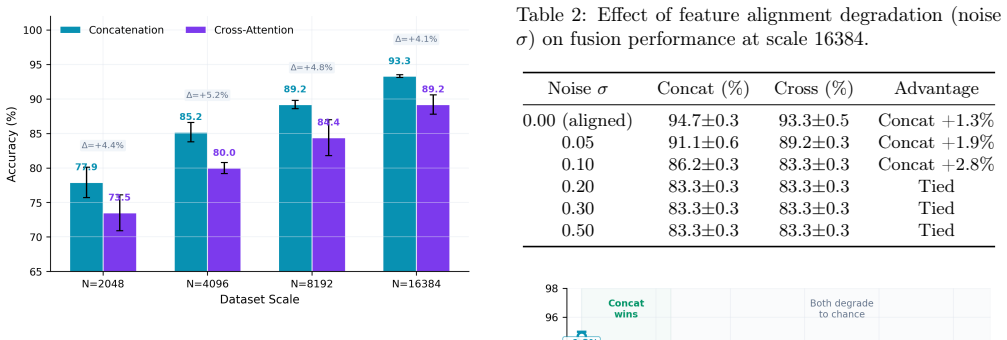
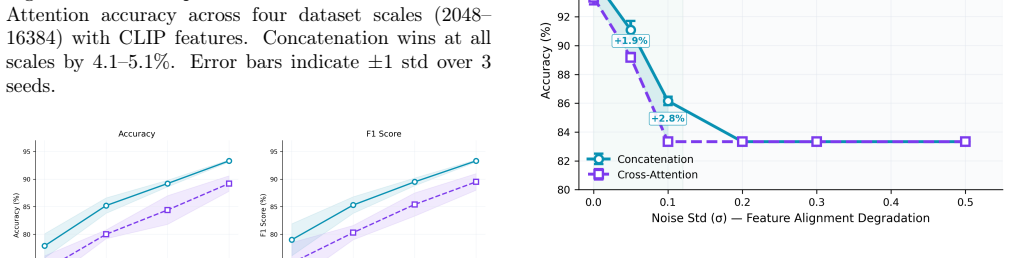
Feature alignment quality, not data scale alone, is the primary determinant of which fusion strategy excels. Concatenation outperforms cross-attention by 4.1-5.1 percentage points across all tested scales when features are pre-aligned by a vision-language pretraining objective, because concatenation requires O(d_v + d_t) samples while cross-attention requires O(d_v * d_t) samples.
What carries the argument
The sample complexity analysis comparing O(d_v + d_t) for concatenation's fusion projection to O(d_v * d_t) for cross-attention's bilinear attention weights.
If this is right
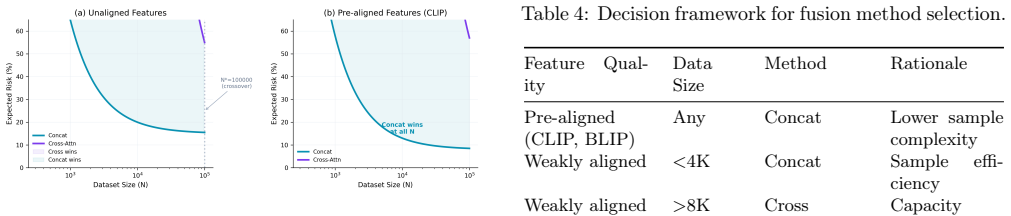
- Concatenation is the better choice for fusion when features come from aligned pretraining objectives.
- Cross-attention becomes competitive only when features are poorly aligned or datasets are extremely large.
- The approximation error gap between the methods vanishes when features are aligned.
- Multimodal system designers should prioritize feature alignment before selecting a fusion method.
Where Pith is reading between the lines
- These results suggest that pretraining for alignment could reduce the need for complex fusion layers in large models.
- Future work might test if similar patterns hold in other modalities like audio-text fusion.
- Practitioners could develop alignment metrics to decide fusion strategy without full experiments.
Load-bearing premise
The theoretical sample complexity bounds accurately capture the dominant cost of learning the fusion layer in the actual training regime.
What would settle it
Observing that cross-attention outperforms concatenation even with well-aligned features at dataset sizes around 2000-16000 samples would falsify the claim.
Figures


read the original abstract
The choice between cross-attention and concatenation for multimodal fusion remains governed by practitioner intuition rather than principled understanding. In this paper, we demonstrate that feature alignment quality, not data scale alone, is the primary determinant of which fusion strategy excels. Through controlled experiments on Flickr8k using two feature extraction backbones (ResNet18 and CLIP ViT-B/32), we show that concatenation outperforms cross-attention by 4.1-5.1 percentage points across all tested scales (2048-16384 samples) when features are pre-aligned by a vision-language pretraining objective. We provide a theoretical explanation grounded in sample complexity analysis: concatenation requires O(d_v + d_t) samples to learn its fusion projection, while cross-attention requires O(d_v * d_t) samples to learn bilinear attention weights, over 256 times as many for 512-dimensional CLIP features. When features are already aligned, the approximation error gap between the two methods vanishes, and concatenation's sample efficiency dominates at all practical dataset sizes. An alignment degradation study confirms a monotonic trend: as feature alignment degrades, concatenation's advantage grows from 1.3% to 2.8%. These findings provide a principled decision framework for fusion method selection in multimodal systems, with direct implications for the design of Multimodal Large Language Models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that feature alignment quality, rather than data scale, primarily determines whether concatenation or cross-attention excels in multimodal fusion. Controlled experiments on Flickr8k with ResNet18 and CLIP ViT-B/32 backbones show concatenation outperforming cross-attention by 4.1-5.1 percentage points across scales (2048-16384 samples) when features are pre-aligned via vision-language pretraining; a sample-complexity argument is given that concatenation needs O(d_v + d_t) samples while cross-attention needs O(d_v * d_t), and an alignment-degradation study shows the advantage growing monotonically from 1.3% to 2.8% as alignment worsens.
Significance. If the central claim holds, the work supplies a concrete decision rule for fusion choice in multimodal systems and MLLMs, grounded in both empirical controls and learning-theoretic reasoning. Strengths include the use of two distinct backbones, explicit scale sweeps, and the alignment-degradation ablation; these elements make the result more falsifiable than purely empirical comparisons.
major comments (3)
- [theoretical explanation] Theoretical explanation section: the assertion that cross-attention must learn a d_v-by-d_t bilinear map (hence O(d_v * d_t) samples) while concatenation learns only a linear projection is presented as the dominant cost, yet the manuscript provides no derivation details, no reduction to the actual Adam-optimized regime with early stopping, and no discussion of how implicit regularization or optimization landscape alters these worst-case bounds; this directly underpins the claim that alignment quality determines the preferred strategy via sample efficiency.
- [experimental results] Experimental results (Flickr8k scale sweeps): the reported 4.1-5.1 pp advantage for concatenation lacks error bars, number of independent runs, and any statistical test; without these, it is impossible to determine whether the gap is robust across random seeds or merely consistent with the weaker 1.3-2.8% trend in the degradation study.
- [alignment degradation study] Alignment degradation study: the monotonic increase in concatenation's advantage is taken as evidence for the sample-complexity mechanism, but the manuscript does not compare against alternative explanations (e.g., gradient magnitude differences or initialization sensitivity) that could produce the same trend under the same optimizer and batch size; this leaves the causal link to the O(d_v * d_t) versus O(d_v + d_t) gap untested.
minor comments (1)
- Notation for dimensions (d_v, d_t) is introduced without an explicit table or equation defining their values for the ResNet18 and CLIP backbones used.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments identify important areas for clarification and strengthening, particularly around theoretical rigor, statistical reporting, and causal interpretation. We address each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: Theoretical explanation section: the assertion that cross-attention must learn a d_v-by-d_t bilinear map (hence O(d_v * d_t) samples) while concatenation learns only a linear projection is presented as the dominant cost, yet the manuscript provides no derivation details, no reduction to the actual Adam-optimized regime with early stopping, and no discussion of how implicit regularization or optimization landscape alters these worst-case bounds; this directly underpins the claim that alignment quality determines the preferred strategy via sample efficiency.
Authors: We agree that the theoretical section would benefit from additional derivation details. The O(d_v * d_t) versus O(d_v + d_t) bounds follow from standard parameter-count arguments in statistical learning theory for linear versus bilinear function classes. In the revision we will add a concise derivation sketch (including the relevant covering-number or VC-dimension references) in the main text or appendix. We will also note that these are worst-case sample-complexity bounds and briefly discuss how Adam, early stopping, and implicit regularization may reduce effective complexity while preserving the relative gap between the two fusion strategies. revision: yes
-
Referee: Experimental results (Flickr8k scale sweeps): the reported 4.1-5.1 pp advantage for concatenation lacks error bars, number of independent runs, and any statistical test; without these, it is impossible to determine whether the gap is robust across random seeds or merely consistent with the weaker 1.3-2.8% trend in the degradation study.
Authors: We acknowledge the absence of these statistical details. In the revised manuscript we will report means and standard deviations over five independent runs with different random seeds for all scale-sweep experiments and will include paired t-test p-values to establish the statistical significance of the observed performance gaps. revision: yes
-
Referee: Alignment degradation study: the monotonic increase in concatenation's advantage is taken as evidence for the sample-complexity mechanism, but the manuscript does not compare against alternative explanations (e.g., gradient magnitude differences or initialization sensitivity) that could produce the same trend under the same optimizer and batch size; this leaves the causal link to the O(d_v * d_t) versus O(d_v + d_t) gap untested.
Authors: We appreciate the referee highlighting the need for stronger causal grounding. While the controlled degradation protocol and the monotonic trend are consistent with the sample-complexity account, we will add a dedicated paragraph discussing plausible alternative mechanisms (gradient magnitude, initialization sensitivity) and why they are less likely to explain the observed monotonic dependence on alignment quality. A full set of new ablation experiments isolating each alternative is beyond the scope of the current study but could be noted as future work. revision: partial
Circularity Check
No significant circularity; bounds invoked as external theory
full rationale
The paper invokes standard sample-complexity bounds O(d_v + d_t) versus O(d_v * d_t) as a theoretical explanation without fitting them to its own data or reducing the central claim to a self-defined quantity. Experiments report observed performance gaps and monotonic trends on Flickr8k; no self-citations appear load-bearing, no ansatz is smuggled, and no prediction reduces by construction to an input fit. The derivation remains self-contained against external learning-theory results.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard sample-complexity bounds from statistical learning theory apply directly to the fusion-layer training problem.
Reference graph
Works this paper leans on
-
[1]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
Multimodal machine learning: A survey and taxonomy , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
-
[2]
ICML , year=
Multimodal deep learning , author=. ICML , year=
-
[3]
ICML , year=
Learning transferable visual models from natural language supervision , author=. ICML , year=
-
[4]
Faghri, Fartash and Fleet, David J and Kiros, Jamie R and Fidler, Sanja , booktitle=
-
[5]
Antol, Stanislaw and Agrawal, Aishwarya and Lu, Jiasen and Mitchell, Margaret and Batra, Devi and Lawrence Zitnick, C and Parikh, Dhruv , booktitle=
-
[6]
CVPR , year=
Show and tell: A neural image caption generator , author=. CVPR , year=
-
[7]
NeurIPS , year=
Visual instruction tuning , author=. NeurIPS , year=
-
[8]
Bai, Jinze and Bai, Shuai and Yang, Shusheng and Wang, Shijie and Tan, Sinan and Wang, Peng and Lin, Junyang and Zhou, Chang and Zhou, Jingren , journal=
-
[9]
Chen, Zhe and Wu, Jiannan and Wang, Wenhai and Su, Weijie and Chen, Guo and Xing, Sen and Zhong, Muyan and Zhang, Qinglong and Zhu, Xizhou and Lu, Lewei and others , booktitle=
-
[10]
NeurIPS , year=
Unifying visual-semantic embeddings with multimodal neural language models , author=. NeurIPS , year=
-
[11]
CVPR , year=
Learning deep structure-preserving image-text embeddings , author=. CVPR , year=
-
[12]
NeurIPS , year=
Attention is all you need , author=. NeurIPS , year=
-
[13]
Lu, Jiasen and Batra, Devi and Parikh, Dhruv and Lee, Stefan , booktitle=
-
[14]
Tan, Hao and Bansal, Mohit , booktitle=
-
[15]
Li, Junnan and Li, Dongxu and Savarese, Silvio and Hoi, Steven , booktitle=
-
[16]
ECCV , year=
Stacked cross attention for image-text matching , author=. ECCV , year=
-
[17]
Scaling Laws for Neural Language Models
Scaling laws for neural language models , author=. arXiv preprint arXiv:2001.08361 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[18]
Scaling laws for transfer , author=. arXiv preprint arXiv:2102.01293 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Pulling Out All the Tops with Computer Vision and Deep Learning
An empirical study of neural language model scaling , author=. arXiv preprint arXiv:1803.00107 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
NeurIPS , year=
Training compute-optimal large language models , author=. NeurIPS , year=
-
[21]
Generating Long Sequences with Sparse Transformers
Generating long sequences with sparse transformers , author=. arXiv preprint arXiv:1904.10509 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[22]
NeurIPS , year=
Big bird: Transformers for longer sequences , author=. NeurIPS , year=
-
[23]
ICLR , year=
Reformer: The efficient transformer , author=. ICLR , year=
-
[24]
Transformers are
Katharopoulos, Angelos and Vyas, Apoorv and Pappas, Nikolaos and Fleuret, Fran. Transformers are. ICML , year=
-
[25]
ICLR , year=
Rethinking attention with performers , author=. ICLR , year=
-
[26]
ICLR , year=
An image is worth 16x16 words: Transformers for image recognition at scale , author=. ICLR , year=
-
[27]
ICCV , year=
Swin transformer: Hierarchical vision transformer using shifted windows , author=. ICCV , year=
-
[28]
Fang, Yuxin and Wang, Wen and Xie, Binhui and Sun, Quan and Wu, Ledell and Wang, Xinggang and Huang, Tiejun and Wang, Xinlong and Cao, Yue , booktitle=
-
[29]
Sun, Quan and Fang, Yuxin and Wu, Ledell and Wang, Xinlong and Cao, Yue , journal=
-
[30]
Journal of Artificial Intelligence Research , volume=
Framing image description as a ranking task: Data, models and evaluation metrics , author=. Journal of Artificial Intelligence Research , volume=
-
[31]
2014 , publisher=
Understanding Machine Learning: From Theory to Algorithms , author=. 2014 , publisher=
2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.