HomeFlow: A Data Flywheel for Smart Home Agent Training with Verifiable Simulation
Pith reviewed 2026-06-28 17:08 UTC · model grok-4.3
The pith
A data flywheel built on simulation and tree search trains smart home agents to outperform GPT-5.5.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
HomeFlow creates a self-improving loop where simulated environments generate verifiable multi-turn trajectories for training agents via supervised fine-tuning and step-wise reinforcement learning, resulting in HomeFlow-RL-8B reaching 87.03% task success on SmartHome-Bench, exceeding GPT-5.5.
What carries the argument
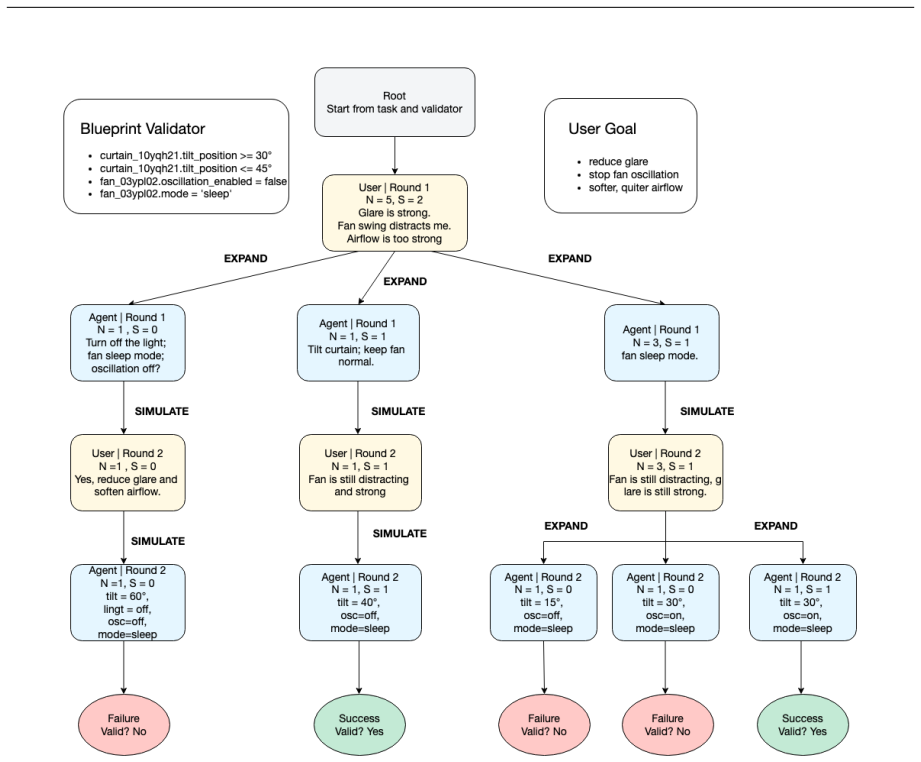
HomeFlow, which combines HomeEnv simulation, HomeMaker for procedural homes, Blueprint for intent compilation, MCTS-Flow for trajectory synthesis, and RLVE for optimization.
If this is right
- Smart home agents can be trained without relying solely on human-generated data.
- Agents improve iteratively through physical feedback in simulation.
- Performance on multi-turn reasoning tasks in dynamic settings increases.
- New benchmarks like SmartHome-Bench become available for evaluation.
Where Pith is reading between the lines
- Similar flywheels could be built for other embodied domains like robotics if simulators are available.
- The approach might reduce the need for expensive real-world data collection in agent training.
- Success in simulation suggests potential for safer initial training before real deployment.
Load-bearing premise
The HomeEnv simulator and success conditions from Blueprint accurately represent real smart home dynamics and user intents.
What would settle it
Running the HomeFlow-trained agent in a real smart home setup and comparing its task success rate to the simulated benchmark results.
Figures



read the original abstract
Large language model agents are moving beyond text-only interaction toward physical-world control, with smart homes as a representative domain. Real domestic interaction requires understanding ambiguous intents, operating in dynamic environments, and performing multi-turn reasoning. However, existing methods struggle to generate high-quality training data for smart home agents. We propose HomeFlow, a verifiable data flywheel for this domain. HomeFlow uses HomeEnv as a unified simulation environment and HomeMaker to procedurally generate diverse home settings. Subsequently, Blueprint compiles open-ended user intents into executable state-based success conditions, while MCTS-Flow synthesizes diverse, verifiable multi-turn trajectories through environment-guided tree search. We then optimize the agents via supervised fine-tuning and step-wise RLVE, which facilitates iterative improvement through authentic physical feedback. We further construct SmartHome-Bench to evaluate the agent across various smart home tasks. On this benchmark, HomeFlow-RL-4B and HomeFlow-RL-8B achieve task success rates of 84.60% and 87.03%. It is worth noting that HomeFlow-RL-8B even surpasses the leading GPT-5.5 by 1.23 percentage points.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HomeFlow, a data flywheel for training LLM-based smart home agents. It uses HomeEnv as a simulation environment, HomeMaker to procedurally generate home settings, Blueprint to convert open-ended user intents into state-based success conditions, and MCTS-Flow to synthesize multi-turn trajectories via environment-guided search. Agents are trained via supervised fine-tuning followed by step-wise RLVE, and evaluated on the newly constructed SmartHome-Bench, where HomeFlow-RL-4B and HomeFlow-RL-8B report task success rates of 84.60% and 87.03%, with the latter surpassing GPT-5.5 by 1.23 percentage points.
Significance. If the evaluation protocol and independence from the training pipeline can be established, the work would provide a scalable, verifiable method for generating training data in embodied agent domains where real-world data collection is costly. The emphasis on state-based success predicates and environment feedback during trajectory synthesis is a constructive contribution to reducing hallucination in multi-turn physical control tasks.
major comments (2)
- [Abstract] Abstract and evaluation description: the headline result (HomeFlow-RL-8B at 87.03% vs. GPT-5.5) is reported without any description of the experimental protocol, number of tasks, baseline implementations, statistical significance, or error bars. This absence makes the central performance claim impossible to verify or reproduce from the provided information.
- [Evaluation / SmartHome-Bench] SmartHome-Bench construction: the benchmark tasks, state-based success predicates, and environment dynamics are generated by the same HomeMaker/Blueprint/HomeEnv pipeline used to produce the MCTS-Flow training trajectories. No out-of-distribution test set, human validation of intent alignment, or explicit separation between training and test distributions is described, which directly undermines the claim that the reported success rates demonstrate generalization rather than in-distribution fitting.
minor comments (2)
- [Abstract] The term 'GPT-5.5' appears without citation or clarification of the exact model and prompting setup used for comparison.
- [Training] Notation for RLVE (step-wise reinforcement learning with verifiable environment feedback) is introduced without an equation or pseudocode definition in the abstract-level description.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and indicate where revisions will be made to improve the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract and evaluation description: the headline result (HomeFlow-RL-8B at 87.03% vs. GPT-5.5) is reported without any description of the experimental protocol, number of tasks, baseline implementations, statistical significance, or error bars. This absence makes the central performance claim impossible to verify or reproduce from the provided information.
Authors: We agree that the abstract, constrained by length, omits key experimental details. The full protocol (including 500 tasks in SmartHome-Bench, baseline implementations via the same environment, averaging over multiple seeds, and error bars) appears in Sections 4 and 5. We will revise the abstract to concisely note the benchmark scale and that results are reported with statistical measures to improve immediate verifiability. revision: yes
-
Referee: [Evaluation / SmartHome-Bench] SmartHome-Bench construction: the benchmark tasks, state-based success predicates, and environment dynamics are generated by the same HomeMaker/Blueprint/HomeEnv pipeline used to produce the MCTS-Flow training trajectories. No out-of-distribution test set, human validation of intent alignment, or explicit separation between training and test distributions is described, which directly undermines the claim that the reported success rates demonstrate generalization rather than in-distribution fitting.
Authors: This observation is correct regarding the current manuscript description. While the procedural pipeline is shared, test instances use distinct generation parameters and held-out intent sets. We will add an explicit subsection in the evaluation section describing the train-test separation criteria, distribution-shift statistics, and the lack of human validation as a limitation. revision: yes
Circularity Check
No significant circularity; results presented as empirical measurements on constructed benchmark
full rationale
The paper describes a procedural pipeline (HomeEnv + HomeMaker + Blueprint + MCTS-Flow) for generating training trajectories and a separate SmartHome-Bench for evaluation. No equations, fitted parameters, or self-referential definitions are shown that would reduce the reported success rates (84.60%, 87.03%) to the training inputs by construction. No load-bearing self-citations, uniqueness theorems, or ansatzes are invoked. The benchmark is presented as an independent evaluation set, and the central claims remain externally falsifiable via real-world testing even if the simulator is imperfect. This is the common case of a self-contained simulation study without definitional collapse.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Swe-bench: Can language models resolve real-world github issues?arXiv preprint arXiv:2310.06770. Evan King, Haoxiang Yu, Sangsu Lee, and Christine Julien. 2024. Sasha: Creative goal-oriented reasoning in smart homes with large language models.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, 8(1):1–38. Jing Yu Koh, Rober...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
• Each scene must describe continuous human behavior in a single physical location
Life Scene Construction • Generate a fixed number of daily-life scenes. • Each scene must describe continuous human behavior in a single physical location. • Scenes must reflect user profile characteristics and environment states. • Device states must be grounded in observed environment information. • Do not generate command-style or task-list-style descriptions
-
[3]
• Each task must originate from exactly one scene
Atomic Task Decomposition • Decompose each scene into atomic tasks. • Each task must originate from exactly one scene. • Each task must represent a single user intent only. 16 • No new devices or attributes may be introduced. Hard Constraints
-
[4]
• Device identifiers must match exactly
Device Constraint • Only devices explicitly defined in the environment are allowed. • Device identifiers must match exactly
-
[5]
• No inferred or hallucinated attributes are allowed
Attribute Constraint • Only attributes listed in device service definitions may be used. • No inferred or hallucinated attributes are allowed
-
[6]
• Multi-intent or composite tasks are not allowed
Atomicity Constraint • Each task must contain exactly one user intent. • Multi-intent or composite tasks are not allowed
-
[7]
• Device state transitions must be realistic and valid
Physical Consistency Constraint • All actions must be physically executable in the given environment. • Device state transitions must be realistic and valid
-
[8]
• If device is inactive, activation must be included before modifying dependent attributes
Device State Dependency Constraint • Functional attributes (e.g., temperature, brightness) are only valid when device is active. • If device is inactive, activation must be included before modifying dependent attributes. Output Format.Strict JSON only, no explanation or additional text. User Profile Generation Prompt Task Definition.You are an expert syst...
-
[9]
Smart Home GroundingAll attributes must map to controllable system behaviors: • Physiology→environment adaptation • Health→HV AC / air quality control • Habits→automation scheduling • Preferences→scene control policies
-
[10]
Completeness Constraints • All modules must be present: basic, physiology, health, habit, preference • No missing or null fields • Full internal consistency required
-
[11]
17 User Query Generation Prompt Task Definition.You are an expert system for generating natural user requests in a smart home environment
Realism Constraints • Cover full demographic spectrum • Include realistic health conditions • Ensure physically plausible values Output Format.Strict JSON only, no explanation. 17 User Query Generation Prompt Task Definition.You are an expert system for generating natural user requests in a smart home environment. Objective.Convert structured task states ...
-
[12]
Task-Centric GroundingAll outputs must strictly align with the current task list: • Focus only onunfinished tasks • Ignore historical dialogue unless task-relevant • Ensure every query directly contributes to task completion
-
[13]
Device-State AwarenessGeneration must consider real-time home state: • Room-level and device-level status constraints • Avoid redundant or already-satisfied operations • Adjust actions based on current device conditions
-
[14]
Natural User Expression ConstraintEnsure outputs reflect realistic user behavior: • Avoid enumerating multiple parameters or rooms in a rigid format • Avoid overly structured or machine-like command patterns • Use short, conversational, and implicit instructions
-
[15]
Minimalism Principle • One unified query per generation step • No task IDs, no explanations, no reasoning traces • Merge actions only when naturally expressed
-
[16]
all devices
Tool-Execution Requirement • Output must be passed throughpost_processtool • Must include: –query: a single executable instruction string –reason: structured justification of generation logic •querymust never be empty or null Output Format.Strict tool-call format only. No free-text response. 18 Smart Home Agent Prompt Task Definition.You are an intelligen...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.