Evidence-Gated LLM Priors for Multi-Objective Bayesian Optimization
Pith reviewed 2026-06-28 14:39 UTC · model grok-4.3
The pith
Dynamic objective-wise calibration of LLM priors improves robustness over fixed priors in multi-objective Bayesian optimization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
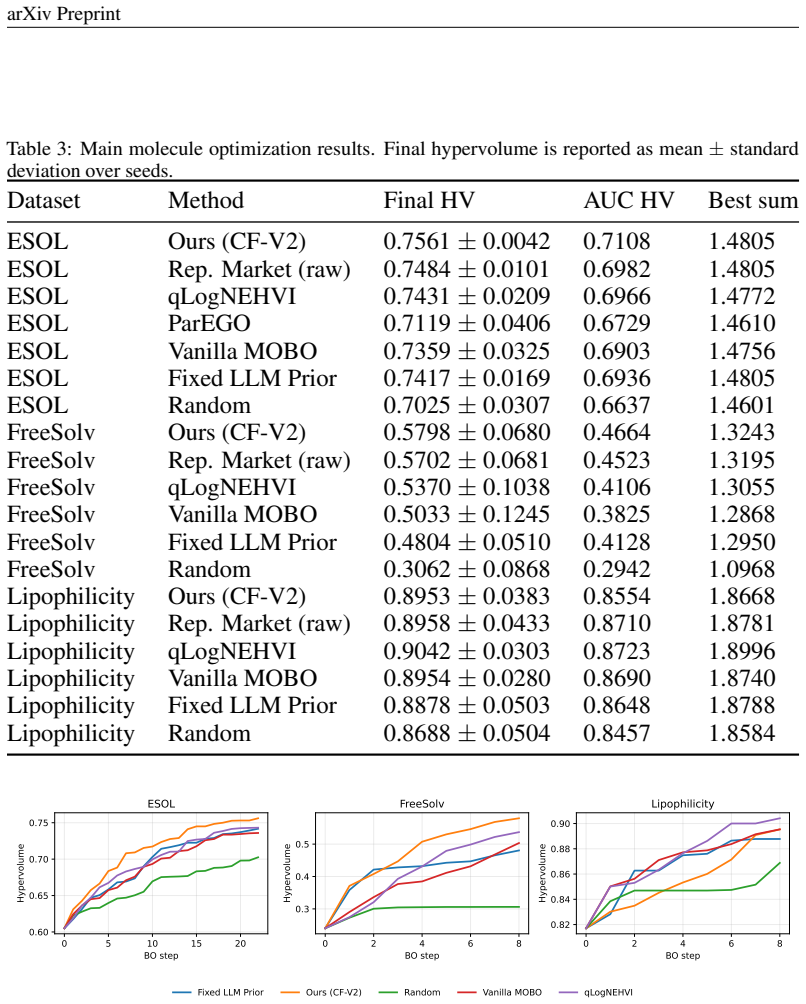
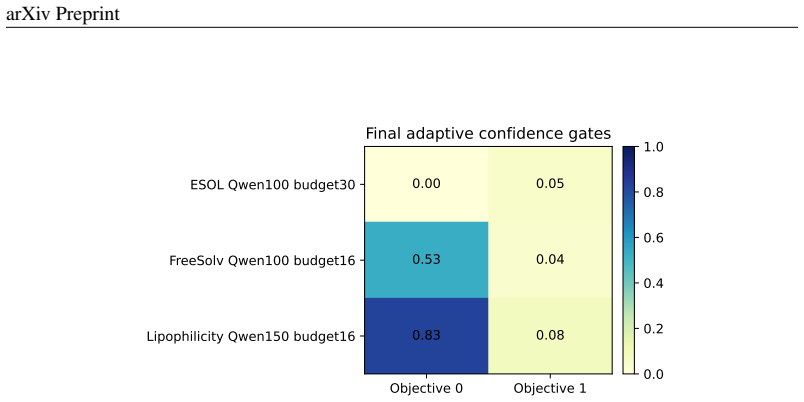
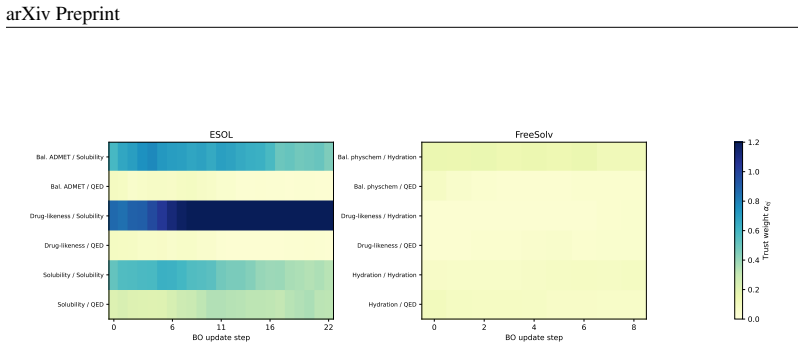
The central claim is that an objective-wise reputation-market mechanism, which updates expert weights from observed objective feedback and applies a decoupled counterfactual gate, enables reliable use of LLM priors in multi-objective Bayesian optimization; this dynamic calibration improves robustness over fixed priors on synthetic tests and molecule benchmarks, while LLM self-reported confidence shows inconsistent benefit and a margin portfolio approach reveals that selection must be acquisition-aware.
What carries the argument
Objective-wise reputation-market mechanism that updates per-expert-objective weights from feedback, discounted over time and gated by market trust, together with a decoupled counterfactual gate deciding among prior without confidence, prior with confidence, or abstention.
If this is right
- Dynamic objective-wise calibration yields more robust optimization than fixed LLM priors across controlled tests and molecule benchmarks.
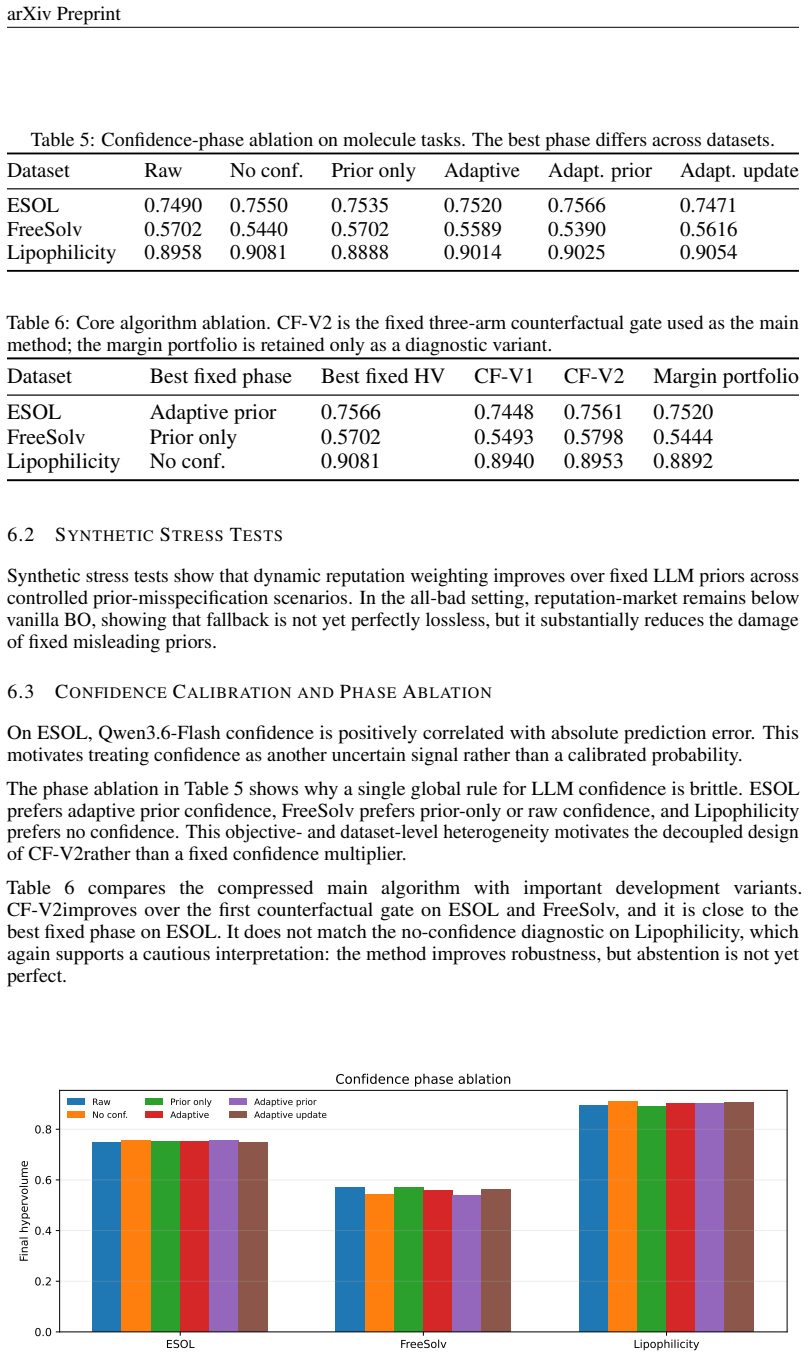
- Raw LLM confidence scores are not reliably beneficial and can correlate negatively with prediction error on some datasets such as ESOL.
- A fixed three-arm counterfactual gate improves results over the initial gate variant on ESOL and FreeSolv.
- Margin-based portfolio selection using only one-step prior error underperforms and requires acquisition-aware design.
Where Pith is reading between the lines
- The reputation update rule could extend to continuous or non-LLM heuristic priors in other black-box settings.
- Additional debiasing steps may be needed if acquisition functions induce strong selection effects on the feedback used for weight updates.
- The gating logic might transfer to hybrid optimization pipelines that combine multiple non-LLM information sources.
Load-bearing premise
Observed objective feedback after each evaluation supplies a reliable, unbiased signal for updating expert weights without selection bias from the acquisition function.
What would settle it
A controlled run in which acquisition-driven sampling produces systematically biased feedback that causes the dynamic weight updates to degrade performance below that of fixed LLM priors.
Figures

read the original abstract
Large language models (LLMs) are increasingly used as heuristic advisors for black-box optimization, yet their suggestions and self-reported confidence are not necessarily calibrated to downstream objective values. This issue becomes more pronounced in multi-objective Bayesian optimization, where different objectives may require different expert knowledge and where an LLM expert can be useful for one objective but misleading for another. We study how to use LLM-generated expert priors in discrete multi-objective Bayesian optimization without blindly trusting them. We propose an objective-wise reputation-market mechanism that treats each expert-objective pair as a falsifiable prior source. Expert weights are updated online from observed objective feedback, discounted over time, and gated by market-level trust. We then introduce a decoupled counterfactual gate that can use the LLM prior without confidence, use it with confidence, or abstain from the LLM prior entirely. Across controlled synthetic stress tests and three molecule optimization benchmarks with \qwenflash{}-generated expert priors, we find that dynamic objective-wise calibration improves robustness over fixed LLM priors. However, raw LLM confidence is not reliably beneficial: on ESOL, confidence is positively correlated with prediction error; on FreeSolv, confidence can help; and on Lipophilicity, ignoring confidence remains strongest. Our fixed three-arm counterfactual gate improves over the first counterfactual variant on ESOL and FreeSolv, while an attempted margin portfolio exposes a useful negative result: margin selection should be acquisition-aware rather than based only on one-step prior error.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an objective-wise reputation-market mechanism that treats each LLM expert-objective pair as a falsifiable prior source, updating expert weights online from discounted observed objective feedback and gating by market-level trust. It introduces a decoupled counterfactual gate allowing use of the LLM prior without confidence, with confidence, or abstention. Experiments across synthetic stress tests and three molecule optimization benchmarks (ESOL, FreeSolv, Lipophilicity) with Qwen-generated priors show dynamic calibration improves robustness over fixed LLM priors, while raw LLM confidence yields mixed results and a margin portfolio variant produces a negative result indicating acquisition-aware selection is needed.
Significance. If the central robustness claim holds after addressing potential biases, the work provides a practical, falsifiable approach to incorporating uncalibrated LLM priors into multi-objective BO without blind trust, which is relevant given increasing use of LLMs as heuristic advisors. The explicit negative result on the margin portfolio is a strength, as is the objective-wise treatment of expert reliability. The method could influence how priors are handled in black-box optimization pipelines.
major comments (2)
- [§3 (Reputation-Market Mechanism)] §3 (Reputation-Market Mechanism) and the weight-update rule: the online update from post-evaluation objective values (discounted, market-gated) occurs after points selected by an acquisition function that already mixes the LLM priors being calibrated. This introduces potential selection bias, so the observed feedback is not an unbiased sample of prior quality. The decoupled counterfactual gate addresses usage but not this upstream bias in weight updates; a formal analysis, bias-correction term, or ablation isolating the effect is required for the robustness claim to be load-bearing.
- [§4 (Experiments)] §4 (Experiments) and Table/Figure results: the abstract states consistent improvement from dynamic calibration, but the full acquisition functions, statistical significance tests (e.g., p-values or confidence intervals on robustness metrics), and details of how synthetic stress tests probe selection bias are not visible. Without these, it is unclear whether the reported gains over fixed priors survive the bias concern or are driven by it.
minor comments (2)
- [§3] Notation for the reputation market and counterfactual gate should be introduced with explicit equations rather than descriptive prose to improve reproducibility.
- [§3.3] The three-arm counterfactual gate is described as 'fixed'; clarify whether its thresholds are tuned on held-out data or fixed a priori, as this affects the 'parameter-free' interpretation.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which identify a substantive methodological concern around selection bias and highlight gaps in experimental reporting. We address both points directly below and commit to revisions that strengthen the robustness claims without overstating current evidence.
read point-by-point responses
-
Referee: [§3 (Reputation-Market Mechanism)] §3 (Reputation-Market Mechanism) and the weight-update rule: the online update from post-evaluation objective values (discounted, market-gated) occurs after points selected by an acquisition function that already mixes the LLM priors being calibrated. This introduces potential selection bias, so the observed feedback is not an unbiased sample of prior quality. The decoupled counterfactual gate addresses usage but not this upstream bias in weight updates; a formal analysis, bias-correction term, or ablation isolating the effect is required for the robustness claim to be load-bearing.
Authors: We agree that the online updates occur on data selected under an acquisition function that incorporates the same priors, creating a plausible selection bias. The synthetic stress tests deliberately include regimes with deliberately misaligned or anti-correlated priors to surface this effect, and the objective-wise reputation updates are intended to down-weight unreliable experts over time. However, we lack a formal bias analysis or explicit correction term in the current manuscript. We will add (i) an explicit discussion of the bias mechanism in §3, (ii) an ablation that freezes the reputation weights after an initial burn-in period (thereby isolating the effect of continued biased updates), and (iii) a comparison against a simple bias-correction heuristic that re-weights feedback by the inverse of the acquisition density at the evaluated point. These additions will be reported as a new subsection and will qualify the robustness claim accordingly. revision: partial
-
Referee: [§4 (Experiments)] §4 (Experiments) and Table/Figure results: the abstract states consistent improvement from dynamic calibration, but the full acquisition functions, statistical significance tests (e.g., p-values or confidence intervals on robustness metrics), and details of how synthetic stress tests probe selection bias are not visible. Without these, it is unclear whether the reported gains over fixed priors survive the bias concern or are driven by it.
Authors: The acquisition functions are defined in §4.2 and the appendix; the synthetic stress-test protocol (including the deliberate injection of selection bias via prior-acquisition correlation) is described in §4.1. These sections were not sufficiently prominent. We will (i) move the complete acquisition-function equations and hyper-parameter settings into the main text, (ii) report bootstrap confidence intervals and paired Wilcoxon signed-rank p-values on the primary robustness metric (hypervolume improvement over fixed-prior baselines) for all three molecular benchmarks, and (iii) add a dedicated paragraph in §4.1 explaining how each stress-test variant isolates selection bias. With these changes the abstract claim will be revised to “dynamic calibration improves robustness on the tested benchmarks, subject to the selection-bias analysis added in §3.” revision: yes
Circularity Check
No circularity; derivation relies on external feedback
full rationale
The paper's core mechanism updates expert weights from post-evaluation objective values (external data) and uses a decoupled counterfactual gate. No equations or steps reduce by construction to fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations. The robustness claims rest on empirical benchmarks against fixed priors, which are independent inputs. This is self-contained against external objective signals.
Axiom & Free-Parameter Ledger
invented entities (2)
-
objective-wise reputation market
no independent evidence
-
decoupled counterfactual gate
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Journal of Global Optimization , volume=
Efficient Global Optimization of Expensive Black-Box Functions , author=. Journal of Global Optimization , volume=. 1998 , publisher=
1998
-
[2]
A Tutorial on Bayesian Optimization
A Tutorial on Bayesian Optimization , author=. arXiv preprint arXiv:1807.02811 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
2006 , organization=
Knowles, Joshua , booktitle=. 2006 , organization=
2006
-
[4]
Advances in Neural Information Processing Systems , volume=
Differentiable Expected Hypervolume Improvement for Parallel Multi-Objective Bayesian Optimization , author=. Advances in Neural Information Processing Systems , volume=
-
[5]
Advances in Neural Information Processing Systems , volume=
Parallel Bayesian Optimization of Multiple Noisy Objectives with Expected Hypervolume Improvement , author=. Advances in Neural Information Processing Systems , volume=
-
[6]
and Daulton, Samuel and Letham, Benjamin and Wilson, Andrew Gordon and Bakshy, Eytan , booktitle=
Balandat, Maximilian and Karrer, Brian and Jiang, Daniel R. and Daulton, Samuel and Letham, Benjamin and Wilson, Andrew Gordon and Bakshy, Eytan , booktitle=
-
[7]
International Conference on Learning Representations , year=
Large Language Models to Enhance Bayesian Optimization , author=. International Conference on Learning Representations , year=
-
[8]
Chen, Lichang and Chen, Jiuhai and Goldstein, Tom and Huang, Heng and Zhou, Tianyi , booktitle=
-
[9]
International Conference on Machine Learning , pages=
On Calibration of Modern Neural Networks , author=. International Conference on Machine Learning , pages=. 2017 , organization=
2017
-
[10]
Transactions on Machine Learning Research , year=
Teaching Models to Express Their Uncertainty in Words , author=. Transactions on Machine Learning Research , year=
-
[11]
Language Models (Mostly) Know What They Know
Language Models (Mostly) Know What They Know , author=. arXiv preprint arXiv:2207.05221 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Journal of Computer and System Sciences , volume=
A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting , author=. Journal of Computer and System Sciences , volume=. 1997 , publisher=
1997
-
[13]
2006 , publisher=
Prediction, Learning, and Games , author=. 2006 , publisher=
2006
-
[14]
Advances in Neural Information Processing Systems , year=
Model Fusion through Bayesian Optimization in Language Model Fine-Tuning , key=. Advances in Neural Information Processing Systems , year=
-
[15]
Findings of the Association for Computational Linguistics: EMNLP , year=
Adaptive Feature-based Low-Rank Compression of Large Language Models via Bayesian Optimization , author=. Findings of the Association for Computational Linguistics: EMNLP , year=
-
[16]
International Conference on Learning Representations , year=
Searching for Optimal Solutions with LLMs via Bayesian Optimization , key=. International Conference on Learning Representations , year=
-
[17]
International Conference on Learning Representations , year=
Bayesian Optimization of Antibodies Informed by a Generative Model of Evolving Sequences , key=. International Conference on Learning Representations , year=
-
[18]
International Conference on Machine Learning , year=
-
[19]
International Conference on Machine Learning , year=
Hyperband-based Bayesian Optimization for Black-box Prompt Selection , author=. International Conference on Machine Learning , year=
-
[20]
International Conference on Machine Learning , year=
Maximizing Intermediate Checkpoint Value in LLM Pretraining with Bayesian Optimization , author=. International Conference on Machine Learning , year=
-
[21]
Advances in Neural Information Processing Systems , year=
Data Mixture Optimization: A Multi-fidelity Multi-scale Bayesian Framework , key=. Advances in Neural Information Processing Systems , year=
-
[22]
Advances in Neural Information Processing Systems , year=
Adaptive Kernel Design for Bayesian Optimization Is a Piece of CAKE with LLMs , key=. Advances in Neural Information Processing Systems , year=
-
[23]
International Conference on Learning Representations , year=
Adaptive Acquisition Selection for Bayesian Optimization with Large Language Models , key=. International Conference on Learning Representations , year=
-
[24]
International Conference on Learning Representations , year=
Unleashing LLMs in Bayesian Optimization: Preference-Guided Framework for Scientific Discovery , key=. International Conference on Learning Representations , year=
-
[25]
International Conference on Learning Representations , year=
Scaling Multi-Task Bayesian Optimization with Large Language Models , key=. International Conference on Learning Representations , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.