Task-Induced Representational Invariances Depend on Learning Objective in Deep RL
Pith reviewed 2026-06-28 15:25 UTC · model grok-4.3
The pith
Value-based RL learns representations invariant to MDP homomorphism symmetries while policy-gradient RL learns invariance to action symmetries even at matched performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
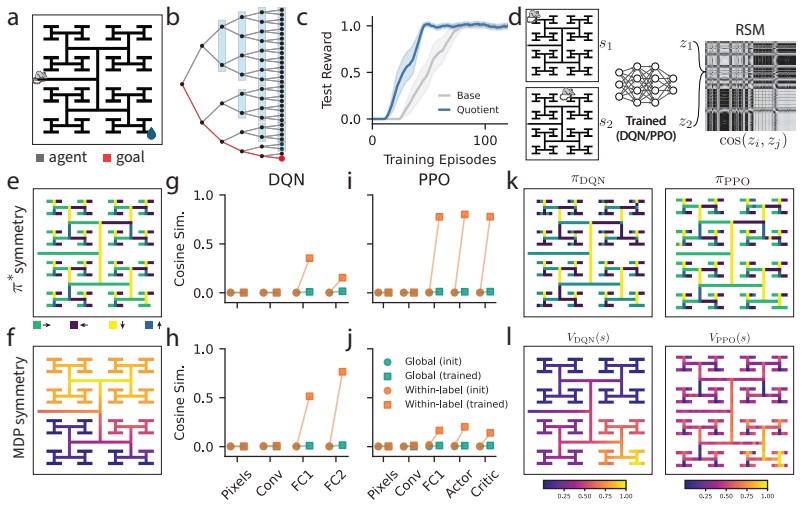
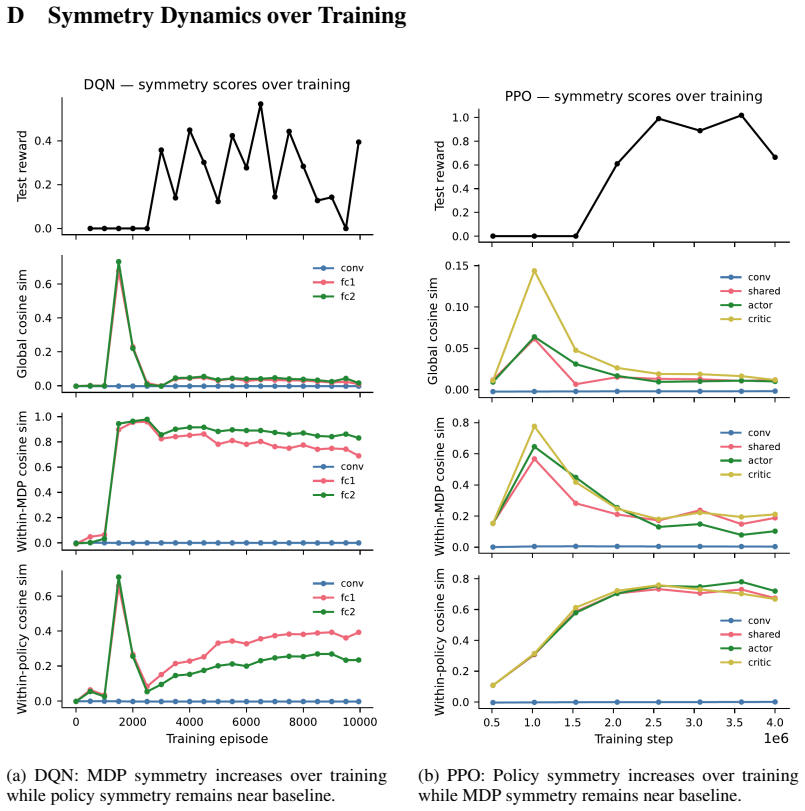
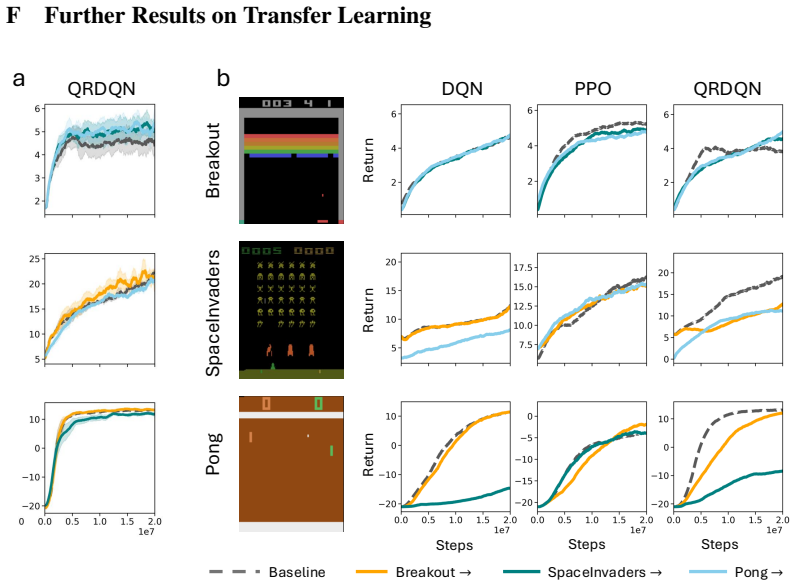
In navigation tasks, DQN and PPO reach comparable performance yet DQN representations become invariant to MDP homomorphism symmetries while PPO representations become invariant to action symmetries. The same contrast appears consistently across domains, produces different transfer-learning outcomes, and manifests in large language models in a prompt-dependent manner. MDP reduction theory supplies the formal lens that distinguishes these two classes of invariance.
What carries the argument
MDP reduction theory, which formalizes symmetries (homomorphisms and action equivalences) that learned representations can ignore or preserve.
If this is right
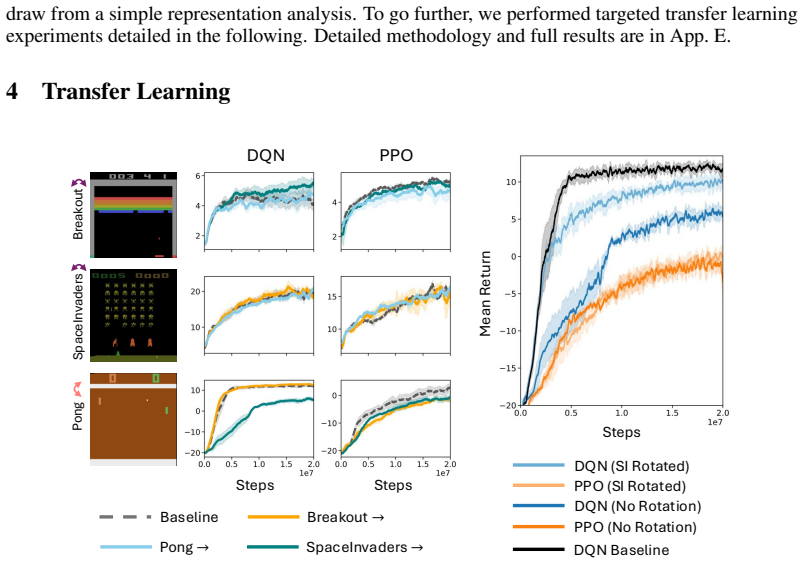
- Representations produced by value-based and policy-gradient methods will support different kinds of transfer between tasks.
- The same contrast between homomorphism invariance and action invariance will appear in domains other than navigation.
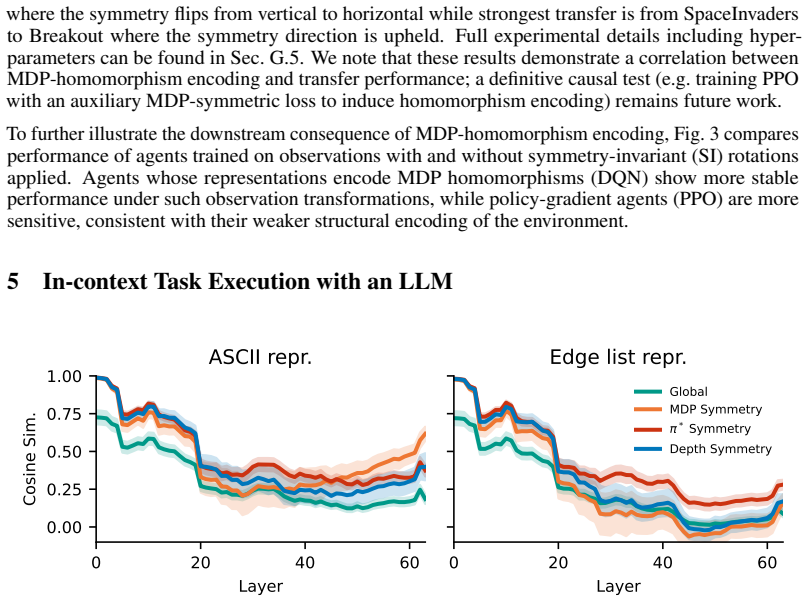
- Large language models will display prompt-dependent shifts between these two classes of invariance.
Where Pith is reading between the lines
- The distinction supplies a concrete handle for relating model representations to neural coding in goal-directed animal behavior.
- Applying the same analysis to actor-critic or other hybrid algorithms would map a wider range of possible invariances.
- If confirmed, the result implies that training objective should be treated as a design variable when engineering networks for desired symmetry properties.
Load-bearing premise
The navigation task together with DQN, PPO, and the MDP reduction lens suffice to expose general rules linking learning objectives to representational invariances without hidden dependence on architecture, training details, or task-specific symmetries.
What would settle it
If DQN and PPO representations in multiple tasks and architectures exhibit identical patterns of invariance to both MDP homomorphisms and action symmetries, the claim that the learning objective selects the invariance type would be falsified.
Figures


read the original abstract
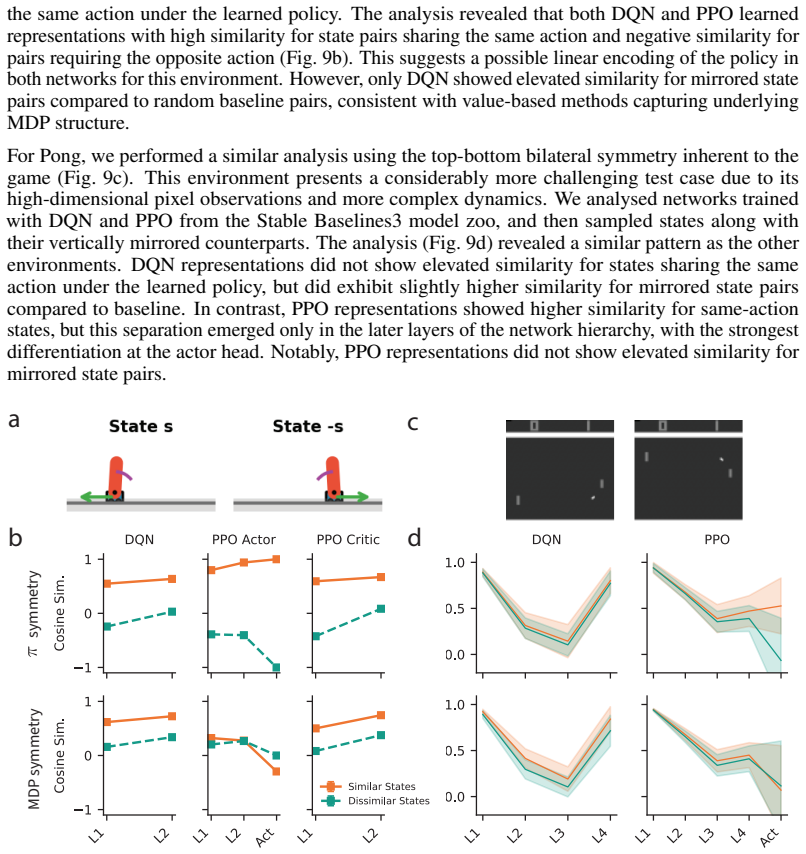
Reinforcement Learning (RL) has long served as a model for goal-directed animal behavior in neuroscience. Modern deep RL has shown remarkable success across many domains, further strengthening this connection. The ability to learn abstract representations of high-dimensional state spaces underlies much of this success. However, theoretical understanding of these learned representations remains limited, hindering direct comparisons between models and animal learning. We address this gap by analyzing deep RL representations through the lens of MDP reduction theory. Investigating canonical RL algorithms in a navigation task, we find that even when performance is comparable, the value-based method (DQN) learns representations that are invariant to MDP homomorphism symmetries, while the policy-gradient method (PPO) learns representations invariant to action symmetries. These differences emerge consistently across domains, have downstream consequences for transfer learning, and appear in LLMs in a prompt-dependent manner. Our findings provide a principled approach to comparing learned representations across RL algorithms, with demonstrated practical implications and possible insights for neural coding in the brain.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that in deep RL, representational invariances depend on the learning objective: value-based methods (DQN) learn representations invariant to MDP homomorphism symmetries, while policy-gradient methods (PPO) learn representations invariant to action symmetries, even with comparable performance. These differences are reported to emerge consistently across domains, affect transfer learning, and appear in LLMs in a prompt-dependent manner. The analysis applies MDP reduction theory to a navigation task as the primary setting.
Significance. If the causal attribution to learning objective holds after controls, the work would supply a formal MDP-reduction lens for comparing representations across RL algorithms and highlight practical consequences for transfer. The explicit use of reduction theory to ground the empirical observations is a methodological strength. The extension to LLMs adds relevance, though the neuroscience connection is secondary and not load-bearing.
major comments (2)
- [Results / Experimental Setup] The central claim requires that the DQN/PPO split is caused by the objective rather than architecture, optimizer, or task symmetries. No ablation experiments that hold the objective fixed while varying network architecture or training details are described; the primary evidence remains the single navigation task with two canonical algorithms, leaving the causal link unsecured.
- [Methods] Quantification of invariances (metrics, statistical tests, baselines, number of independent runs) is not detailed sufficiently to evaluate the consistency claim across domains or the downstream transfer consequences.
minor comments (1)
- [Abstract] The abstract would benefit from naming the additional domains used to support the 'consistent across domains' statement.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comments point-by-point below, clarifying our experimental design and committing to improvements where appropriate.
read point-by-point responses
-
Referee: [Results / Experimental Setup] The central claim requires that the DQN/PPO split is caused by the objective rather than architecture, optimizer, or task symmetries. No ablation experiments that hold the objective fixed while varying network architecture or training details are described; the primary evidence remains the single navigation task with two canonical algorithms, leaving the causal link unsecured.
Authors: We agree that stronger isolation of the learning objective would bolster the causal interpretation. Our study deliberately employs canonical DQN and PPO implementations (with their standard architectures, optimizers, and hyperparameters) to reflect how these algorithms are typically used in the literature, where the objective is the primary distinguishing factor. The observed representational differences are consistent across multiple domains beyond the primary navigation task, as reported in the results. Nevertheless, we acknowledge the limitation and will revise the manuscript to include an expanded discussion of potential confounds (architecture, optimizer, task symmetries) along with any feasible additional controls or ablations that can be performed without altering the core experimental scope. revision: partial
-
Referee: [Methods] Quantification of invariances (metrics, statistical tests, baselines, number of independent runs) is not detailed sufficiently to evaluate the consistency claim across domains or the downstream transfer consequences.
Authors: We appreciate this observation and agree that greater methodological transparency is needed. The current manuscript describes the invariance metrics derived from MDP reduction theory and reports results across domains and transfer settings, but we will expand the Methods and supplementary sections to explicitly detail the metric formulations, statistical tests employed, baseline comparisons, and the number of independent runs (typically 5–10 seeds per condition) to allow full evaluation of the consistency and transfer findings. revision: yes
Circularity Check
No significant circularity; paper is empirical analysis without load-bearing derivations or self-referential fits
full rationale
The manuscript reports experimental comparisons of DQN and PPO representations on navigation tasks, analyzed via MDP reduction theory, with observations of invariance differences that are claimed to hold across domains. No mathematical derivation chain is presented that reduces a claimed prediction or result to its own inputs by construction, nor are there fitted parameters renamed as predictions, self-citation load-bearing premises, or ansatzes smuggled via prior work. The central claims rest on empirical measurements and downstream transfer tests rather than any self-definitional or uniqueness-imported structure. This is the expected non-finding for an empirical RL paper whose evidence is externally falsifiable via replication on the reported tasks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption MDP reduction theory provides a valid lens for characterizing learned representations in deep RL
Reference graph
Works this paper leans on
-
[1]
Loss of plasticity in continual deep reinforcement learning
Zaheer Abbas, Rosie Zhao, Joseph Modayil, Adam White, and Marlos C Machado. Loss of plasticity in continual deep reinforcement learning. InConference on lifelong learning agents, pages 620–636. PMLR, 2023
2023
-
[2]
α-req: Assessing representation quality in self-supervised learning by measuring eigenspectrum decay.Advances in Neural Information Processing Systems, 35:17626–17638, 2022
Kumar K Agrawal, Arnab Kumar Mondal, Arna Ghosh, and Blake Richards. α-req: Assessing representation quality in self-supervised learning by measuring eigenspectrum decay.Advances in Neural Information Processing Systems, 35:17626–17638, 2022
2022
-
[3]
Intrinsic dimension of data representations in deep neural networks.Advances in Neural Information Processing Systems, 32, 2019
Alessio Ansuini, Alessandro Laio, Jakob H Macke, and Davide Zoccolan. Intrinsic dimension of data representations in deep neural networks.Advances in Neural Information Processing Systems, 32, 2019
2019
-
[4]
A geometric perspective on optimal representations for reinforcement learning.Advances in neural information processing systems, 32, 2019
Marc Bellemare, Will Dabney, Robert Dadashi, Adrien Ali Taiga, Pablo Samuel Castro, Nicolas Le Roux, Dale Schuurmans, Tor Lattimore, and Clare Lyle. A geometric perspective on optimal representations for reinforcement learning.Advances in neural information processing systems, 32, 2019
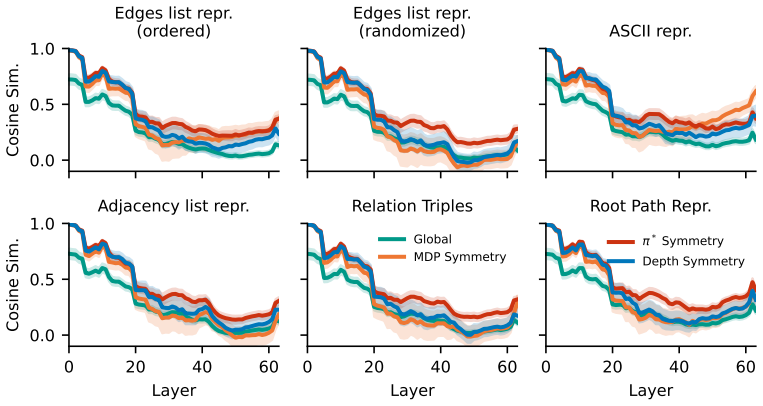
2019
-
[5]
Online abstraction with mdp homomorphisms for deep learning
Ondrej Biza and Robert Platt. Online abstraction with mdp homomorphisms for deep learning. arXiv preprint arXiv:1811.12929, 2018
-
[6]
Hierarchical reinforcement learning and decision making.Current opinion in neurobiology, 22(6):956–962, 2012
Matthew Michael Botvinick. Hierarchical reinforcement learning and decision making.Current opinion in neurobiology, 22(6):956–962, 2012
2012
-
[7]
Greg Brockman, Vicki Cheung, Ludwig Pettersson, Jonas Schneider, John Schulman, Jie Tang, and Wojciech Zaremba. Openai gym.arXiv preprint arXiv:1606.01540, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[8]
Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
1901
-
[9]
MICo: Improved representations via sampling-based state similarity for Markov decision processes
Pablo Samuel Castro, Tyler Kastner, Prakash Panangaden, and Mark Rowland. MICo: Improved representations via sampling-based state similarity for Markov decision processes. InAdvances in Neural Information Processing Systems, volume 34, pages 30113–30126, 2021
2021
-
[10]
Geometry linked to untangling efficiency reveals structure and computation in neural populations.bioRxiv, pages 2024–02, 2024
Chi-Ning Chou, Royoung Kim, Luke A Arend, Yao-Yuan Yang, Brett D Mensh, Won Mok Shim, Matthew G Perich, and SueYeon Chung. Geometry linked to untangling efficiency reveals structure and computation in neural populations.bioRxiv, pages 2024–02, 2024
2024
-
[11]
Classification and geometry of general perceptual manifolds.Physical Review X, 8(3):031003, 2018
SueYeon Chung, Daniel D Lee, and Haim Sompolinsky. Classification and geometry of general perceptual manifolds.Physical Review X, 8(3):031003, 2018
2018
-
[12]
Separability and geometry of object manifolds in deep neural networks.Nature communications, 11(1):746, 2020
Uri Cohen, SueYeon Chung, Daniel D Lee, and Haim Sompolinsky. Separability and geometry of object manifolds in deep neural networks.Nature communications, 11(1):746, 2020
2020
-
[13]
Using deep reinforcement learning to reveal how the brain encodes abstract state-space representations in high-dimensional environments.Neuron, 109(4):724–738, 2021
Logan Cross, Jeff Cockburn, Yisong Yue, and John P O’Doherty. Using deep reinforcement learning to reveal how the brain encodes abstract state-space representations in high-dimensional environments.Neuron, 109(4):724–738, 2021. 10
2021
-
[14]
The value-improvement path: Towards better representations for reinforcement learning
Will Dabney, André Barreto, Mark Rowland, Robert Dadashi, John Quan, Marc G Bellemare, and David Silver. The value-improvement path: Towards better representations for reinforcement learning. InProceedings of the AAAI conference on artificial intelligence, volume 35, pages 7160–7168, 2021
2021
-
[15]
Reliability of cka as a similarity measure in deep learning.arXiv preprint arXiv:2210.16156, 2022
MohammadReza Davari, Stefan Horoi, Amine Natik, Guillaume Lajoie, Guy Wolf, and Eu- gene Belilovsky. Reliability of cka as a similarity measure in deep learning.arXiv preprint arXiv:2210.16156, 2022
-
[16]
Model minimization in markov decision processes
Thomas Dean and Robert Givan. Model minimization in markov decision processes. In AAAI/IAAI, pages 106–111, 1997
1997
-
[17]
Untangling invariant object recognition.Trends in cognitive sciences, 11(8):333–341, 2007
James J DiCarlo and David D Cox. Untangling invariant object recognition.Trends in cognitive sciences, 11(8):333–341, 2007
2007
-
[18]
Loss of plasticity in deep continual learning.Nature, 632 (8026):768–774, 2024
Shibhansh Dohare, J Fernando Hernandez-Garcia, Qingfeng Lan, Parash Rahman, A Rupam Mahmood, and Richard S Sutton. Loss of plasticity in deep continual learning.Nature, 632 (8026):768–774, 2024
2024
-
[19]
Ching Fang and Kimberly L Stachenfeld. Predictive auxiliary objectives in deep rl mimic learning in the brain.arXiv preprint arXiv:2310.06089, 2023
-
[20]
Explaining dopamine through prediction errors and beyond.Nature neuroscience, 27(9):1645–1655, 2024
Samuel J Gershman, John A Assad, Sandeep Robert Datta, Scott W Linderman, Bernardo L Sabatini, Naoshige Uchida, and Linda Wilbrecht. Explaining dopamine through prediction errors and beyond.Nature neuroscience, 27(9):1645–1655, 2024
2024
-
[21]
Paul W Glimcher. Understanding dopamine and reinforcement learning: the dopamine re- ward prediction error hypothesis.Proceedings of the National Academy of Sciences, 108 (supplement_3):15647–15654, 2011
2011
-
[22]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Stable baselines
Ashley Hill, Antonin Raffin, Maximilian Ernestus, Adam Gleave, Anssi Kanervisto, Rene Traore, Prafulla Dhariwal, Christopher Hesse, Oleg Klimov, Alex Nichol, Matthias Plappert, Alec Radford, John Schulman, Szymon Sidor, and Yuhuai Wu. Stable baselines. https: //github.com/hill-a/stable-baselines, 2018
2018
-
[24]
Eghbal Hosseini and Evelina Fedorenko. Large language models implicitly learn to straighten neural sentence trajectories to construct a predictive representation of natural language.Ad- vances in Neural Information Processing Systems, 36:43918–43930, 2023
2023
-
[25]
Navigraph: A graph- based framework for multimodal analysis of spatial decision-making.bioRxiv, pages 2025–05, 2025
Amit Koren Iton, Elior Iton, Daniel M Michaelson, and Pablo Blinder. Navigraph: A graph- based framework for multimodal analysis of spatial decision-making.bioRxiv, pages 2025–05, 2025
2025
-
[26]
Notes on state abstractions
Nan Jiang. Notes on state abstractions. Lecture notes, University of Illinois at Urbana- Champaign, 2018. URL https://nanjiang.cs.illinois.edu/files/cs598/note4. pdf
2018
-
[27]
Provably efficient reinforcement learning with linear function approximation
Chi Jin, Zhuoran Yang, Zhaoran Wang, and Michael I Jordan. Provably efficient reinforcement learning with linear function approximation. InConference on learning theory, pages 2137–
-
[28]
Near-optimal reinforcement learning in polynomial time
Michael Kearns and Satinder Singh. Near-optimal reinforcement learning in polynomial time. Machine learning, 49(2):209–232, 2002
2002
-
[29]
Similarity of neural network representations revisited
Simon Kornblith, Mohammad Norouzi, Honglak Lee, and Geoffrey Hinton. Similarity of neural network representations revisited. InInternational conference on machine learning, pages 3519–3529. PMlR, 2019
2019
-
[30]
Neuroscience needs behavior: correcting a reductionist bias.Neuron, 93(3):480–490, 2017
John W Krakauer, Asif A Ghazanfar, Alex Gomez-Marin, Malcolm A MacIver, and David Poeppel. Neuroscience needs behavior: correcting a reductionist bias.Neuron, 93(3):480–490, 2017. 11
2017
-
[31]
Representational similarity analysis-connecting the branches of systems neuroscience.Frontiers in systems neuroscience, 2:249, 2008
Nikolaus Kriegeskorte, Marieke Mur, and Peter A Bandettini. Representational similarity analysis-connecting the branches of systems neuroscience.Frontiers in systems neuroscience, 2:249, 2008
2008
-
[32]
Grid cell symmetry is shaped by environmental geometry.Nature, 518(7538):232–235, 2015
Julija Krupic, Marius Bauza, Stephen Burton, Caswell Barry, and John O’Keefe. Grid cell symmetry is shaped by environmental geometry.Nature, 518(7538):232–235, 2015
2015
-
[33]
Building machines that learn and think like people.Behavioral and brain sciences, 40:e253, 2017
Brenden M Lake, Tomer D Ullman, Joshua B Tenenbaum, and Samuel J Gershman. Building machines that learn and think like people.Behavioral and brain sciences, 40:e253, 2017
2017
-
[34]
Sebastian Lee, Stefano Sarao Mannelli, Claudia Clopath, Sebastian Goldt, and Andrew Saxe. Maslow’s hammer for catastrophic forgetting: Node re-use vs node activation.arXiv preprint arXiv:2205.09029, 2022
-
[35]
Towards a unified theory of state abstraction for mdps.AI&M, 1(2):3, 2006
Lihong Li, Thomas J Walsh, and Michael L Littman. Towards a unified theory of state abstraction for mdps.AI&M, 1(2):3, 2006
2006
-
[36]
Local explanations for reinforcement learning
Ronny Luss, Amit Dhurandhar, and Miao Liu. Local explanations for reinforcement learning. InProceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 9002–9010, 2023
2023
-
[37]
On the effect of auxiliary tasks on representation dynamics
Clare Lyle, Mark Rowland, Georg Ostrovski, and Will Dabney. On the effect of auxiliary tasks on representation dynamics. InInternational Conference on Artificial Intelligence and Statistics, pages 1–9. PMLR, 2021
2021
-
[38]
Playing Atari with Deep Reinforcement Learning
V olodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, and Martin Riedmiller. Playing atari with deep reinforcement learning.arXiv preprint arXiv:1312.5602, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[39]
Human-level control through deep reinforcement learning.nature, 518(7540):529–533, 2015
V olodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A Rusu, Joel Veness, Marc G Bellemare, Alex Graves, Martin Riedmiller, Andreas K Fidjeland, Georg Ostrovski, et al. Human-level control through deep reinforcement learning.nature, 518(7540):529–533, 2015
2015
-
[40]
Llms are in-context bandit reinforcement learners.arXiv preprint arXiv:2410.05362, 2024
Giovanni Monea, Antoine Bosselut, Kianté Brantley, and Yoav Artzi. Llms are in-context bandit reinforcement learners.arXiv preprint arXiv:2410.05362, 2024
-
[41]
Ng, Daishi Harada, and Stuart J
Andrew Y . Ng, Daishi Harada, and Stuart J. Russell. Policy invariance under reward transforma- tions: Theory and application to reward shaping. InProceedings of the Sixteenth International Conference on Machine Learning, pages 278–287, 1999
1999
-
[42]
Learning predictable and robust neural representations by straightening image sequences.Advances in Neural Information Processing Systems, 37:40316–40335, 2024
Julie Xueyan Niu, Cristina Savin, and Eero Simoncelli. Learning predictable and robust neural representations by straightening image sequences.Advances in Neural Information Processing Systems, 37:40316–40335, 2024
2024
-
[43]
Reinforcement learning in the brain.Journal of Mathematical Psychology, 53(3): 139–154, 2009
Yael Niv. Reinforcement learning in the brain.Journal of Mathematical Psychology, 53(3): 139–154, 2009
2009
-
[44]
Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
2022
-
[45]
Policy gradient methods in the presence of symmetries and state abstractions.Journal of Machine Learning Research, 25(71):1–57, 2024
Prakash Panangaden, Sahand Rezaei-Shoshtari, Rosie Zhao, David Meger, and Doina Precup. Policy gradient methods in the presence of symmetries and state abstractions.Journal of Machine Learning Research, 25(71):1–57, 2024
2024
-
[46]
Hippocampus supports multi-task reinforcement learning under partial observability.Nature Communications, 16(1):9619, 2025
Dabal Pedamonti, Samia Mohinta, Martin V Dimitrov, Hugo Malagon-Vina, Stephane Ciocchi, and Rui Ponte Costa. Hippocampus supports multi-task reinforcement learning under partial observability.Nature Communications, 16(1):9619, 2025
2025
-
[47]
John Wiley & Sons, 2014
Martin L Puterman.Markov decision processes: discrete stochastic dynamic programming. John Wiley & Sons, 2014
2014
-
[48]
Univer- sity of Massachusetts Amherst, 2004
Balaraman Ravindran.An algebraic approach to abstraction in reinforcement learning. Univer- sity of Massachusetts Amherst, 2004. 12
2004
-
[49]
Symmetries and model minimization in markov decision processes, 2001
Balaraman Ravindran and Andrew G Barto. Symmetries and model minimization in markov decision processes, 2001
2001
-
[50]
Continuous mdp homomorphisms and homomorphic policy gradient.Advances in Neural Information Processing Systems, 35:20189–20204, 2022
Sahand Rezaei-Shoshtari, Rosie Zhao, Prakash Panangaden, David Meger, and Doina Precup. Continuous mdp homomorphisms and homomorphic policy gradient.Advances in Neural Information Processing Systems, 35:20189–20204, 2022
2022
-
[51]
Mice in a labyrinth show rapid learning, sudden insight, and efficient exploration.Elife, 10:e66175, 2021
Matthew Rosenberg, Tony Zhang, Pietro Perona, and Markus Meister. Mice in a labyrinth show rapid learning, sudden insight, and efficient exploration.Elife, 10:e66175, 2021
2021
-
[52]
Rummery and Mahesan Niranjan
Graeme A. Rummery and Mahesan Niranjan. On-line Q-learning using connectionist systems. Technical report, Department of Engineering, University of Cambridge, Cambridge, 1994
1994
-
[53]
A mathematical theory of semantic development in deep neural networks.Proceedings of the National Academy of Sciences, 116 (23):11537–11546, 2019
Andrew M Saxe, James L McClelland, and Surya Ganguli. A mathematical theory of semantic development in deep neural networks.Proceedings of the National Academy of Sciences, 116 (23):11537–11546, 2019
2019
-
[54]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[55]
Predictive reward signal of dopamine neurons.Journal of neurophysiology, 1998
Wolfram Schultz. Predictive reward signal of dopamine neurons.Journal of neurophysiology, 1998
1998
-
[56]
Mas- tering the game of go with deep neural networks and tree search.nature, 529(7587):484–489, 2016
David Silver, Aja Huang, Chris J Maddison, Arthur Guez, Laurent Sifre, George Van Den Driess- che, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, et al. Mas- tering the game of go with deep neural networks and tree search.nature, 529(7587):484–489, 2016
2016
-
[57]
Neural representational geometry underlies few-shot concept learning.Proceedings of the National Academy of Sciences, 119 (43):e2200800119, 2022
Ben Sorscher, Surya Ganguli, and Haim Sompolinsky. Neural representational geometry underlies few-shot concept learning.Proceedings of the National Academy of Sciences, 119 (43):e2200800119, 2022
2022
-
[58]
Neuropixels 2.0: A miniaturized high-density probe for stable, long-term brain recordings.Science, 372(6539): eabf4588, 2021
Nicholas A Steinmetz, Cagatay Aydin, Anna Lebedeva, Michael Okun, Marius Pachitariu, Marius Bauza, Maxime Beau, Jai Bhagat, Claudia Böhm, Martijn Broux, et al. Neuropixels 2.0: A miniaturized high-density probe for stable, long-term brain recordings.Science, 372(6539): eabf4588, 2021
2021
-
[59]
Getting aligned on representa- tional alignment.arXiv preprint arXiv:2310.13018, 2023
Ilia Sucholutsky, Lukas Muttenthaler, Adrian Weller, Andi Peng, Andreea Bobu, Been Kim, Bradley C Love, Erin Grant, Iris Groen, Jascha Achterberg, et al. Getting aligned on representa- tional alignment.arXiv preprint arXiv:2310.13018, 2023
-
[60]
Bounding performance loss in ap- proximate mdp homomorphisms.Advances in Neural Information Processing Systems, 21, 2008
Jonathan Taylor, Doina Precup, and Prakash Panagaden. Bounding performance loss in ap- proximate mdp homomorphisms.Advances in Neural Information Processing Systems, 21, 2008
2008
-
[61]
Qwen2.5: A party of foundation models, September 2024
Qwen Team. Qwen2.5: A party of foundation models, September 2024. URL https:// qwenlm.github.io/blog/qwen2.5/
2024
-
[62]
Analysis of temporal-diffference learning with function approximation.Advances in neural information processing systems, 9, 1996
John Tsitsiklis and Benjamin Van Roy. Analysis of temporal-diffference learning with function approximation.Advances in neural information processing systems, 9, 1996
1996
-
[63]
Mdp homomorphic networks: Group symmetries in reinforcement learning.Advances in Neural Information Processing Systems, 33:4199–4210, 2020
Elise Van der Pol, Daniel Worrall, Herke van Hoof, Frans Oliehoek, and Max Welling. Mdp homomorphic networks: Group symmetries in reinforcement learning.Advances in Neural Information Processing Systems, 33:4199–4210, 2020
2020
-
[64]
Investigating the properties of neural network representations in reinforcement learning.Artificial Intelligence, 330:104100, 2024
Han Wang, Erfan Miahi, Martha White, Marlos C Machado, Zaheer Abbas, Raksha Ku- maraswamy, Vincent Liu, and Adam White. Investigating the properties of neural network representations in reinforcement learning.Artificial Intelligence, 330:104100, 2024
2024
-
[65]
Reinforcement learning with general value function approximation: Provably efficient approach via bounded eluder dimension
Ruosong Wang, Russ R Salakhutdinov, and Lin Yang. Reinforcement learning with general value function approximation: Provably efficient approach via bounded eluder dimension. Advances in Neural Information Processing Systems, 33:6123–6135, 2020
2020
-
[66]
Q-learning.Machine learning, 8(3):279–292, 1992
Christopher JCH Watkins and Peter Dayan. Q-learning.Machine learning, 8(3):279–292, 1992. 13
1992
-
[67]
The tolman-eichenbaum machine: unifying space and relational memory through generalization in the hippocampal formation.Cell, 183(5):1249– 1263, 2020
James CR Whittington, Timothy H Muller, Shirley Mark, Guifen Chen, Caswell Barry, Neil Burgess, and Timothy EJ Behrens. The tolman-eichenbaum machine: unifying space and relational memory through generalization in the hippocampal formation.Cell, 183(5):1249– 1263, 2020
2020
-
[68]
Ten simple rules for the computational modeling of behavioral data.elife, 8:e49547, 2019
Robert C Wilson and Anne GE Collins. Ten simple rules for the computational modeling of behavioral data.elife, 8:e49547, 2019
2019
-
[69]
An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Chengpeng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, Guanting Dong, Haoran Wei, Huan Lin, Jialong Tang, Jialin Wang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Ma, Jin Xu, Jingren Zhou, Jinze Bai, Jinzheng He, Junyang Lin, Kai Dang, Keming Lu, Keqin Chen, Kexin Yang, Mei Li, Mingfeng ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[70]
Efficient coding of natural images using maximum manifold capacity representations.Adv
TE Yerxa, Yilun Kuang, EP Simoncelli, and SueYeon Chung. Efficient coding of natural images using maximum manifold capacity representations.Adv. Neural Information Processing Systems (NeurIPS), 36, 2023
2023
-
[71]
Graying the black box: Understanding dqns
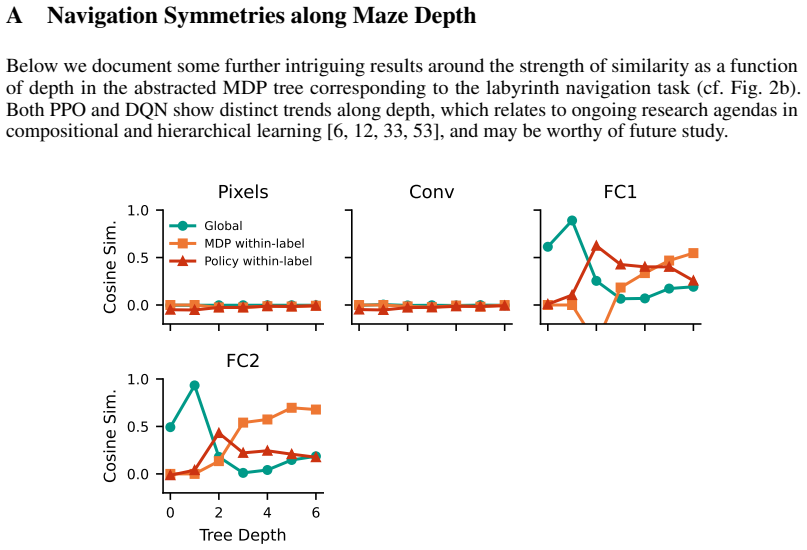
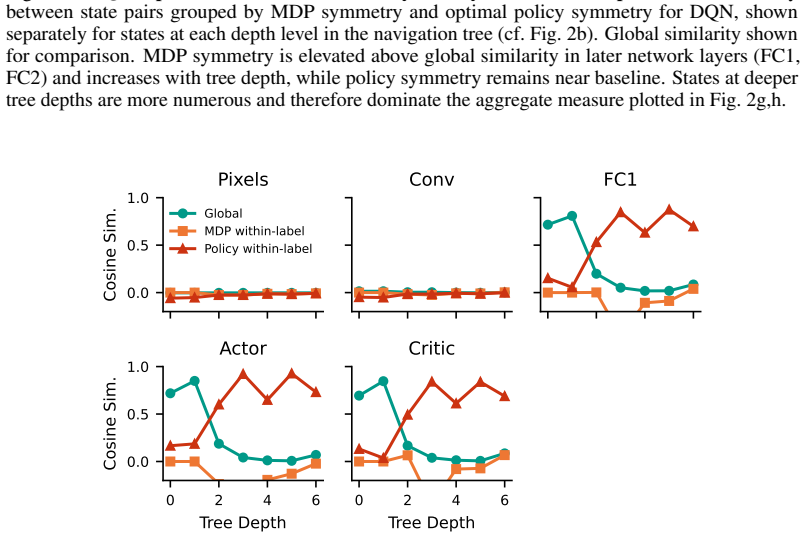
Tom Zahavy, Nir Ben-Zrihem, and Shie Mannor. Graying the black box: Understanding dqns. InInternational conference on machine learning, pages 1899–1908. PMLR, 2016. 14 A Navigation Symmetries along Maze Depth Below we document some further intriguing results around the strength of similarity as a function of depth in the abstracted MDP tree corresponding ...
1908
-
[72]
This format preserves structural information through ordering
Directed Edge List (Ordered):Each edge listed as NodeA –Direction–> NodeB, pre- sented in hierarchical order following the tree structure from root to leaves. This format preserves structural information through ordering
-
[73]
Directed Edge List (Randomized):Identical edge notation to (1), but edges are randomly shuffled, removing structural cues from presentation order
-
[74]
Node relationships and directions are explicitly displayed in a spatially organized format
ASCII Tree Diagram:A visual text representation using indentation and ASCII characters to show the hierarchical tree structure. Node relationships and directions are explicitly displayed in a spatially organized format. 20 (a) Edge List (Ordered) 9 -- North - - > 14 9 -- South - - > 8 14 -- South - - > 9 8 -- North - - > 9 14 -- West - - > 7 14 -- East - ...
-
[75]
( Start ) | + - - North - - >
-
[76]
( came from North ) | + - - West - - >
-
[77]
( came from West ) | + - - North - - >
-
[78]
( came from North ) | + - - South - - >
-
[79]
1": { " North
( came from South ) ... You are c u r r e n t l y at Nodex. Your goal is to reach Node 11. (d) Adjacency List (JSON) { "1": { " North ": 13 } , "10": { " North ": 7 } , "6": { " North ": 2 , " West ": 8 , " South ": 11 } , "8": { " West ": 13 , " North ": 9 , " East ": 6 } , ... } You are c u r r e n t l y at Nodex. Your goal is to reach Node 11. (e) Rela...
-
[80]
Both node order and direction order within each entry are randomized
Adjacency List (JSON):A dictionary mapping each node to its neighbors with direction labels. Both node order and direction order within each entry are randomized
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.