Entropy Minimization without Model Collapse: Mitigating Prediction Bias in Medical Imaging
Pith reviewed 2026-06-28 15:55 UTC · model grok-4.3
The pith
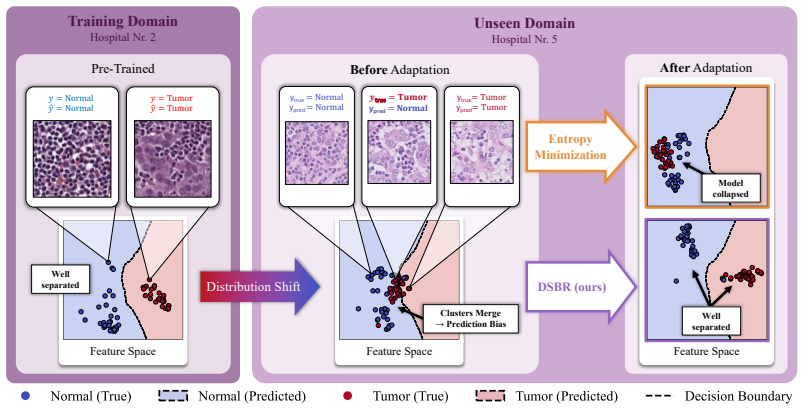
Entropy minimization amplifies prediction bias from merged feature clusters, leading to model collapse during test-time adaptation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Distribution shifts cause feature clusters corresponding to distinct classes to merge in representation space with a fixed decision boundary, inducing prediction bias; entropy minimization amplifies this bias by tightening the clusters until all predictions collapse to a trivial solution; DSBR mitigates the failure mode by equalizing the contribution of each predicted class to the unsupervised entropy minimization loss at test time.
What carries the argument
Distribution Shift Bias Reduction (DSBR), an objective that equalizes the contribution of each predicted class to the entropy minimization loss.
If this is right
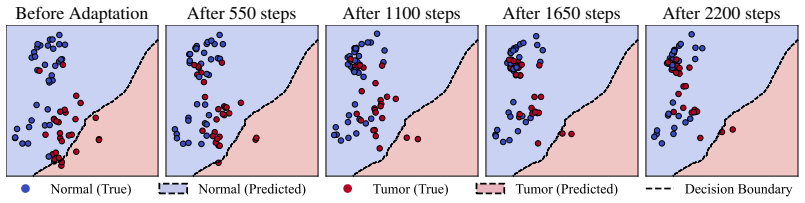
- DSBR stabilizes test-time adaptation and prevents model collapse on medical imaging data.
- DSBR matches or outperforms state-of-the-art methods while operating solely at test time.
- Equalizing class contributions in the entropy loss directly addresses the identified amplification mechanism.
- The approach applies to adaptation settings on four medical-imaging datasets and ImageNet-C.
Where Pith is reading between the lines
- If cluster merging under fixed boundaries is a common response to distribution shift, DSBR may extend to other unsupervised adaptation tasks outside medical imaging.
- Testing DSBR on shifts that do not produce merged clusters could isolate whether the equalization step introduces performance costs when bias is absent.
- The mechanism suggests similar bias-amplification risks may exist in other entropy-based objectives beyond test-time adaptation.
Load-bearing premise
The observed prediction bias arises specifically from merged feature clusters with a fixed decision boundary, and equalizing class contributions directly counters the amplification mechanism without side effects.
What would settle it
An experiment in which feature clusters merge under a distribution shift but DSBR still produces collapse, or in which collapse occurs without prior cluster merging.
Figures

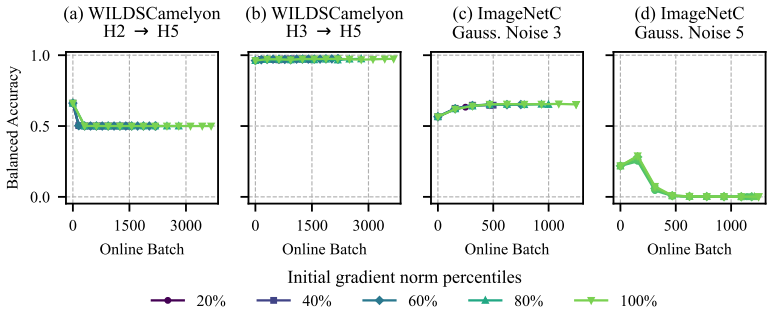
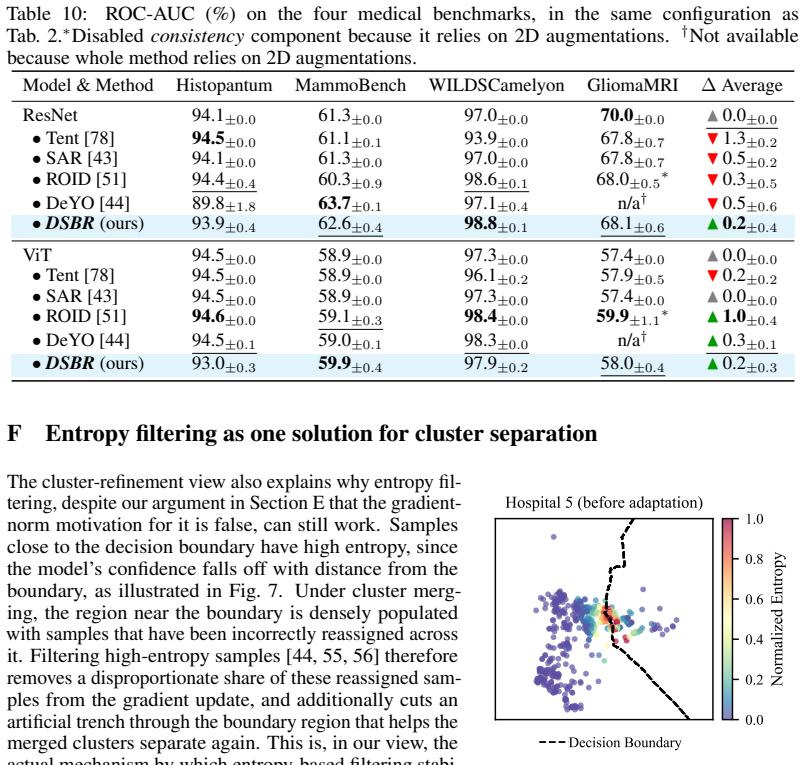
read the original abstract
Entropy minimization (EM) is the dominant objective for test-time adaptation, yet its failure mode, model collapse, remains poorly understood. In this work, we show that distribution shifts can cause feature clusters corresponding to distinct classes in the model's representation space to merge, while the decision boundary remains fixed. This induces a systematic skew in the predicted class distribution, referred to as prediction bias. Prediction bias refers to a shift in the predicted class distribution, with some classes overrepresented and others suppressed. We show that entropy minimization amplifies this prediction bias by tightening the existing clusters, reinforcing the incorrect groupings until all predictions collapse to a trivial solution. Next, to demonstrate the significance of prediction bias and mitigate it, we further propose Distribution Shift Bias Reduction (DSBR), a bias-correcting objective that specifically targets this failure mode by equalizing the contribution of each predicted class to the unsupervised entropy minimization loss. To study this failure mode, we design suitable adaptation settings using four medical-imaging datasets and additionally evaluate on ImageNet-C. We find that DSBR consistently stabilizes test-time adaptation, prevents model collapse, and matches or outperforms state-of-the-art methods. Moreover, DSBR operates solely at test-time.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that entropy minimization (EM) for test-time adaptation (TTA) fails via model collapse because distribution shifts merge feature clusters of distinct classes while the decision boundary remains fixed, inducing prediction bias (skewed predicted class distribution) that EM then amplifies by tightening clusters. It introduces Distribution Shift Bias Reduction (DSBR), which equalizes each predicted class's contribution to the unsupervised entropy loss to target this mechanism. Experiments on four medical imaging datasets plus ImageNet-C show DSBR stabilizes TTA, prevents collapse, and matches or exceeds SOTA methods while operating only at test time.
Significance. If the mechanistic account and DSBR's targeted mitigation hold under the reported conditions, the result is significant for reliable TTA deployment in medical imaging, where shifts are common and collapse is costly. The test-time-only nature and multi-dataset evaluation (including real medical data) are practical strengths; the work directly addresses an identified empirical failure mode rather than proposing a generic regularizer.
major comments (3)
- [§3.1] §3.1 (mechanism description): The account that merged clusters plus fixed boundary induce prediction bias which EM amplifies is presented descriptively without an isolation experiment (e.g., controlled synthetic data with measured inter-cluster distances before/after EM) or gradient analysis showing the amplification step; this premise is load-bearing for both the diagnosis and the design of DSBR.
- [§4.1] §4.1, DSBR objective: The equalizing term is motivated as directly countering class skew, yet no derivation or ablation demonstrates that it avoids side effects such as reduced adaptation speed on already-balanced shifts or new failure modes when cluster merging is absent; the central claim that DSBR 'specifically targets this failure mode' therefore rests on an untested assumption.
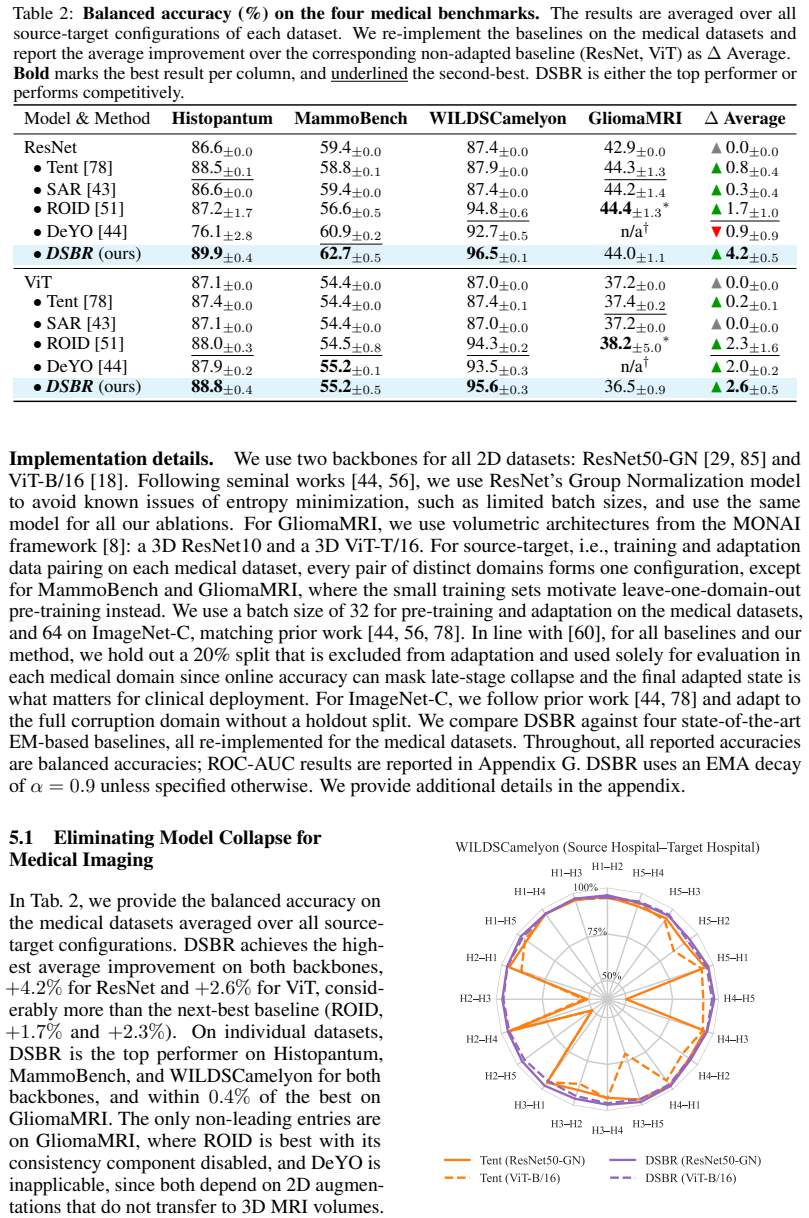
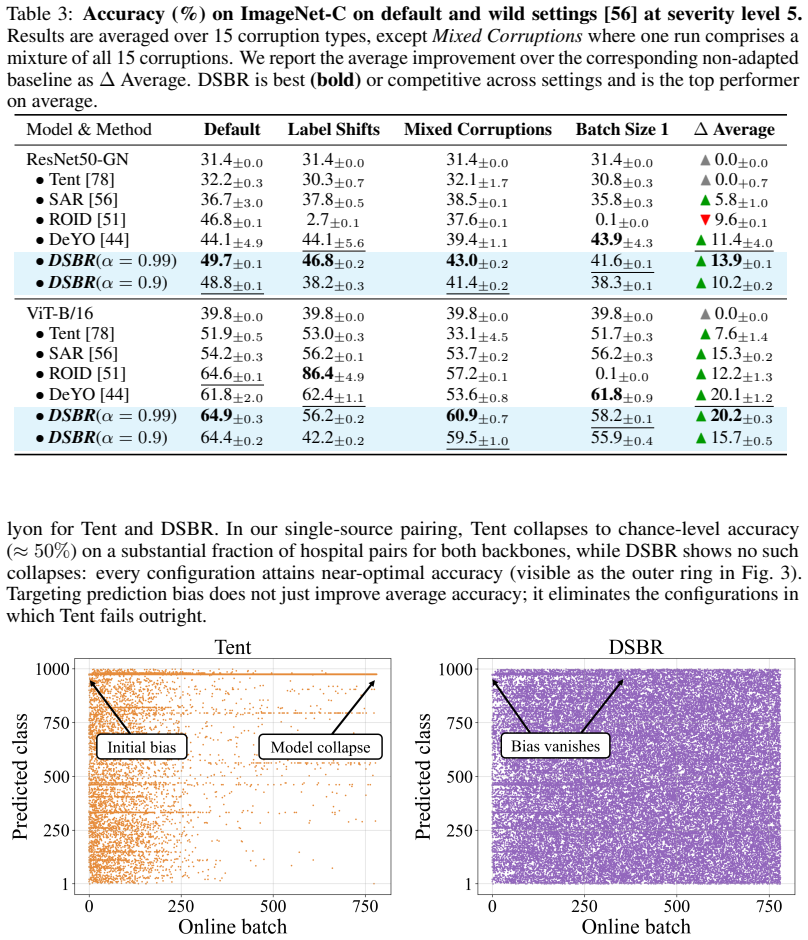
- [Table 3] Table 3 (medical dataset results): While DSBR is reported to prevent collapse where EM fails, the tables do not include variance across random seeds, frequency of collapse events, or statistical tests; without these, the claim of 'consistent stabilization' and outperformance cannot be assessed as load-bearing evidence.
minor comments (3)
- [Abstract] The four medical imaging datasets are referenced in the abstract and §5 but not named until later; early explicit listing would improve readability.
- [§4] Notation for the entropy loss and the DSBR correction term is introduced piecewise; a single consolidated equation block would reduce ambiguity.
- [Figure 2] Figure 2 (cluster visualizations) would benefit from quantitative metrics (e.g., cluster purity or silhouette score) alongside qualitative plots.
Simulated Author's Rebuttal
Thank you for the constructive review and for recognizing the practical significance of addressing model collapse in test-time adaptation for medical imaging. We address each major comment below and will incorporate revisions to strengthen the empirical support for the mechanism, the DSBR objective, and the reported results.
read point-by-point responses
-
Referee: [§3.1] §3.1 (mechanism description): The account that merged clusters plus fixed boundary induce prediction bias which EM amplifies is presented descriptively without an isolation experiment (e.g., controlled synthetic data with measured inter-cluster distances before/after EM) or gradient analysis showing the amplification step; this premise is load-bearing for both the diagnosis and the design of DSBR.
Authors: We acknowledge that §3.1 presents the mechanism through descriptive analysis supported by t-SNE visualizations of merged clusters and prediction skew on the medical datasets, rather than a fully isolated controlled experiment. To directly address this, we will add a synthetic experiment using controlled Gaussian mixture models in the revision: we will measure inter-cluster distances and prediction bias before/after EM, and include a gradient analysis of the entropy loss under biased class distributions to isolate the amplification effect. revision: yes
-
Referee: [§4.1] §4.1, DSBR objective: The equalizing term is motivated as directly countering class skew, yet no derivation or ablation demonstrates that it avoids side effects such as reduced adaptation speed on already-balanced shifts or new failure modes when cluster merging is absent; the central claim that DSBR 'specifically targets this failure mode' therefore rests on an untested assumption.
Authors: The DSBR term is introduced to equalize per-class contributions to the entropy loss precisely when prediction bias is present. While the primary experiments target shifted medical data where collapse occurs, we agree that explicit checks for side effects are needed. In revision we will add ablations on balanced (non-shifted) settings and on synthetic data without cluster merging, reporting adaptation speed and any new instabilities to confirm the targeted nature of the mitigation. revision: yes
-
Referee: [Table 3] Table 3 (medical dataset results): While DSBR is reported to prevent collapse where EM fails, the tables do not include variance across random seeds, frequency of collapse events, or statistical tests; without these, the claim of 'consistent stabilization' and outperformance cannot be assessed as load-bearing evidence.
Authors: We agree that variance, collapse frequency, and statistical tests are required for robust evaluation of stabilization claims. In the revised manuscript we will rerun all medical-dataset experiments across five random seeds, report mean and standard deviation in Table 3, tabulate the observed frequency of collapse events per method, and include paired statistical tests (e.g., t-tests) against baselines. revision: yes
Circularity Check
No significant circularity
full rationale
The paper's central contribution is an empirical description of a failure mode (merged clusters inducing prediction bias that EM then amplifies) followed by the introduction of a new corrective objective DSBR that equalizes class contributions in the entropy loss. No equations, fitted parameters, or self-citations are presented that reduce the claimed result to its own inputs by construction. The method is motivated by observed behavior on medical imaging datasets and evaluated externally rather than defined tautologically.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Entropy minimization is a suitable starting objective for test-time adaptation whose failure modes can be diagnosed via feature cluster behavior.
Reference graph
Works this paper leans on
-
[1]
Agarwal, Z
S. Agarwal, Z. Zhang, L. Yuan, J. Han, and H. Peng. The unreasonable effectiveness of entropy minimization in LLM reasoning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URLhttps://openreview.net/forum?id=UfFTBEsLgI
2026
-
[2]
A. S. Alsolami, W. Shalash, W. Alsaggaf, S. Ashoor, H. Refaat, and M. Elmogy. King abdulaziz university breast cancer mammogram dataset (kau-bcmd).Data, 6(11):111, 2021
2021
-
[3]
Bakas, H
S. Bakas, H. Akbari, A. Sotiras, M. Bilello, M. Rozycki, J. S. Kirby, J. B. Freymann, K. Farahani, and C. Davatzikos. Advancing the cancer genome atlas glioma mri collections with expert segmentation labels and radiomic features.Scientific data, 4(1):170117, 2017
2017
-
[4]
Balendran, C
A. Balendran, C. Beji, F. Bouvier, O. Khalifa, T. Evgeniou, P. Ravaud, and R. Porcher. A scoping review of robustness concepts for machine learning in healthcare.npj Digital Medicine, 8(1):38, 2025
2025
-
[5]
Y . Bar, S. Shaer, and Y . Romano. Protected test-time adaptation via online entropy matching: A betting approach. InAdvances in Neural Information Processing Systems, 2024
2024
-
[6]
Bernhardt, F
M. Bernhardt, F. D. S. Ribeiro, and B. Glocker. Failure detection in medical image classification: A reality check and benchmarking testbed.Transactions on Machine Learning Research, 2022. ISSN 2835-8856. URLhttps://openreview.net/forum?id=VBHuLfnOMf
2022
-
[7]
Calabrese, J
E. Calabrese, J. E. Villanueva-Meyer, J. D. Rudie, A. M. Rauschecker, U. Baid, S. Bakas, S. Cha, J. T. Mongan, and C. P. Hess. The university of california san francisco preoperative diffuse glioma mri dataset.Radiology: Artificial Intelligence, 4(6):e220058, 2022
2022
-
[8]
M. J. Cardoso, W. Li, R. Brown, N. Ma, E. Kerfoot, Y . Wang, B. Murrey, A. Myronenko, C. Zhao, D. Yang, et al. Monai: An open-source framework for deep learning in healthcare. arXiv preprint arXiv:2211.02701, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[9]
D. Chen, D. Wang, T. Darrell, and S. Ebrahimi. Contrastive test-time adaptation. InIEEE Conference on Computer Vision and Pattern Recognition, pages 295–305, 2022
2022
-
[10]
H. Chen, G. Zheng, A. Awadallah, and Y . Ji. Pathologies of pre-trained language models in few-shot fine-tuning. InProceedings of the Third Workshop on Insights from Negative Results in NLP, pages 144–153, 2022
2022
-
[11]
C. Cui, L. Li, H. Cai, Z. Fan, L. Zhang, T. Dan, J. Li, and J. Wang. The chinese mammography database (cmmd): An online mammography database with biopsy confirmed types for machine diagnosis of breast.The Cancer Imaging Archive, 1, 2021
2021
-
[12]
H. Dang, T. Tran, S. Osher, H. Tran-The, N. Ho, and T. Nguyen. Neural collapse in deep linear networks: from balanced to imbalanced data. InProceedings of the 40th International Conference on Machine Learning, ICML’23. JMLR.org, 2023
2023
-
[13]
M. Z. Darestani, J. Liu, and R. Heckel. Test-time training can close the natural distribution shift performance gap in deep learning based compressed sensing. InInternational Conference on Machine Learning, 2022
2022
-
[14]
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei. ImageNet: A large-scale hierarchical image database. InIEEE Conference on Computer Vision and Pattern Recognition, pages 248–255, 2009
2009
-
[15]
R. Deng, W. Bao, T. Wei, and J. He. Panda: Test-time adaptation with negative data augmenta- tion. InProceedings of the AAAI Conference on Artificial Intelligence, 2026
2026
-
[16]
Dohmatob, Y
E. Dohmatob, Y . Feng, and J. Kempe. Model collapse demystified: The case of regression. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https://openreview.net/forum?id=bioHNTRnQk
2024
-
[17]
Dohmatob, Y
E. Dohmatob, Y . Feng, A. Subramonian, and J. Kempe. Strong model collapse. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview. net/forum?id=et5l9qPUhm. 11
2025
-
[18]
Dosovitskiy, L
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representations, 2020
2020
-
[19]
Evans and D
H. Evans and D. Snead. Understanding the errors made by artificial intelligence algorithms in histopathology in terms of patient impact.NPJ Digital Medicine, 7(1):89, 2024
2024
-
[20]
Foret, A
P. Foret, A. Kleiner, H. Mobahi, and B. Neyshabur. Sharpness-aware minimization for efficiently improving generalization.International Conference on Learning Representations (ICLR), 2021
2021
-
[21]
Learning by Surprise: Adaptive Mitigation of Model Collapse in Large Language Models
D. Gambetta, G. Gezici, F. Giannotti, D. Pedreschi, A. Knott, and L. Pappalardo. Learning by surprise: Surplexity for mitigating model collapse in generative ai, 2025. URL https: //arxiv.org/abs/2410.12341
work page internal anchor Pith review arXiv 2025
-
[22]
N. P. Gaurav Bhole, S Suba. Mammo-bench: A large-scale benchmark dataset of mammography images. 2025
2025
-
[23]
Goyal, M
S. Goyal, M. Sun, A. Raghunathan, and J. Z. Kolter. Test time adaptation via conjugate pseudo-labels. InAdvances in Neural Information Processing Systems, 2022
2022
-
[24]
Gretton, A
A. Gretton, A. Smola, J. Huang, M. Schmittfull, K. Borgwardt, B. Schölkopf, et al. Covariate shift by kernel mean matching.Dataset shift in machine learning, 3(4):5, 2009
2009
-
[25]
Gulrajani and D
I. Gulrajani and D. Lopez-Paz. In search of lost domain generalization. InInternational Conference on Learning Representations, 2021. URL https://openreview.net/forum? id=lQdXeXDoWtI
2021
-
[26]
C. Guo, G. Pleiss, Y . Sun, and K. Q. Weinberger. On calibration of modern neural networks. In International Conference on Machine Learning, pages 1321–1330. PMLR, 2017
2017
-
[27]
Y . Guo, M. Guo, J. Su, Z. Yang, M. Zhu, H. Li, M. Qiu, and S. S. Liu. Bias in large language models: Origin, evaluation, and mitigation.arXiv preprint arXiv:2411.10915, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
J. Han, J. Na, and W. Hwang. Ranked entropy minimization for continual test-time adap- tation. InForty-second International Conference on Machine Learning, 2025. URL https://openreview.net/forum?id=lHaGLJ65J9
2025
-
[29]
K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. InIEEE Conference on Computer Vision and Pattern Recognition, pages 770–778, 2016
2016
-
[30]
Hendrycks and T
D. Hendrycks and T. Dietterich. Benchmarking neural network robustness to common cor- ruptions and perturbations.International Conference on Learning Representations (ICLR), 2019
2019
-
[31]
Hoffman, E
J. Hoffman, E. Tzeng, T. Park, J.-Y . Zhu, P. Isola, K. Saenko, A. Efros, and T. Darrell. Cycada: Cycle-consistent adversarial domain adaptation. InInternational Conference on Machine Learning, 2018
2018
-
[32]
Huang, A
J. Huang, A. Gretton, K. Borgwardt, B. Schölkopf, and A. Smola. Correcting sample selection bias by unlabeled data.Advances in neural information processing systems, 19, 2006
2006
-
[33]
Iwasawa and Y
Y . Iwasawa and Y . Matsuo. Test-time classifier adjustment module for model-agnostic domain generalization. InAdvances in Neural Information Processing Systems, volume 34, 2021
2021
-
[34]
Karani, E
N. Karani, E. Erdil, K. Chaitanya, and E. Konukoglu. Test-time adaptable neural networks for robust medical image segmentation.Medical Image Analysis, 68:101907, 2021
2021
- [35]
-
[36]
Khaled, M
R. Khaled, M. Helal, O. Alfarghaly, O. Mokhtar, A. Elkorany, H. El Kassas, and A. Fahmy. Cate- gorized digital database for low energy and subtracted contrast enhanced spectral mammography images.The Cancer Imaging Archive, 16, 2021. 12
2021
-
[37]
Kilim, A
O. Kilim, A. Olar, T. Joó, T. Palicz, P. Pollner, and I. Csabai. Physical imaging parameter variation drives domain shift.Scientific Reports, 12(1):21302, 2022
2022
-
[38]
E. Kim, M. Sun, C. Baek, A. Raghunathan, and J. Z. Kolter. Test-time adaptation induces stronger accuracy and agreement-on-the-line. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https://openreview.net/forum?id= giXUx4VH9t
2024
-
[39]
D. P. Kingma and J. Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[40]
P. W. Koh, S. Sagawa, H. Marklund, S. M. Xie, M. Zhang, A. Balsubramani, W. Hu, M. Ya- sunaga, R. L. Phillips, I. Gao, et al. Wilds: A benchmark of in-the-wild distribution shifts. In International Conference on Machine Learning, 2021
2021
-
[41]
Kopans, R
D. Kopans, R. Moore, K. Bowyer, P. Kegelmeyer, and P. Shile. Ddsm: digital database for screening mammography, 2020
2020
-
[42]
Lee et al
D.-H. Lee et al. Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks. InWorkshop on challenges in representation learning, International Conference on Machine Learning (ICML), page 896, 2013
2013
-
[43]
J. Lee, D. Das, J. Choo, and S. Choi. Towards open-set test-time adaptation utilizing the wisdom of crowds in entropy minimization. InIEEE International Conference on Computer Vision, 2023
2023
-
[44]
J. Lee, D. Jung, S. Lee, J. Park, J. Shin, U. Hwang, and S. Yoon. Entropy is not enough for test-time adaptation: From the perspective of disentangled factors. InInternational Conference on Learning Representations, 2024
2024
-
[45]
Lekadir, A
K. Lekadir, A. F. Frangi, A. R. Porras, B. Glocker, C. Cintas, C. P. Langlotz, E. Weicken, F. W. Asselbergs, F. Prior, G. S. Collins, et al. Future-ai: international consensus guideline for trustworthy and deployable artificial intelligence in healthcare.bmj, 388, 2025
2025
-
[46]
Liang, R
J. Liang, R. He, and T. Tan. A comprehensive survey on test-time adaptation under distribution shifts.International Journal of Computer Vision, 133(1):31–64, 2025
2025
- [47]
-
[48]
Lipton, Y .-X
Z. Lipton, Y .-X. Wang, and A. Smola. Detecting and correcting for label shift with black box predictors. InInternational conference on machine learning, pages 3122–3130. PMLR, 2018
2018
-
[49]
Y . Liu, P. Kothari, B. van Delft, B. Bellot-Gurlet, T. Mordan, and A. Alahi. Ttt++: When does self-supervised test-time training fail or thrive? InAdvances in Neural Information Processing Systems, volume 34, 2021
2021
-
[50]
D. N. Louis, A. Perry, P. Wesseling, D. J. Brat, I. A. Cree, D. Figarella-Branger, C. Hawkins, H. Ng, S. M. Pfister, G. Reifenberger, et al. The 2021 who classification of tumors of the central nervous system: a summary.Neuro-oncology, 23(8):1231–1251, 2021
2021
-
[51]
R. A. Marsden, M. Döbler, and B. Yang. Universal test-time adaptation through weight ensembling, diversity weighting, and prior correction. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 2555–2565, 2024
2024
-
[52]
I. C. Moreira, I. Amaral, I. Domingues, A. Cardoso, M. J. Cardoso, and J. S. Cardoso. Inbreast: toward a full-field digital mammographic database.Academic radiology, 19(2):236–248, 2012
2012
-
[53]
Mounsaveng, F
S. Mounsaveng, F. Chiaroni, M. Boudiaf, M. Pedersoli, and I. Ben Ayed. Bag of tricks for fully test-time adaptation. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 1936–1945, 2024
1936
- [54]
-
[55]
S. Niu, J. Wu, Y . Zhang, Y . Chen, S. Zheng, P. Zhao, and M. Tan. Efficient test-time model adaptation without forgetting. InInternational Conference on Machine Learning, 2022
2022
-
[56]
S. Niu, J. Wu, Y . Zhang, Z. Wen, Y . Chen, P. Zhao, and M. Tan. Towards stable test-time adaptation in dynamic wild world. InInternational Conference on Learning Representations, 2023
2023
-
[57]
P. Oza, R. Oza, U. Oza, P. Sharma, S. Patel, P. Kumar, and B. Gohel. Digital mam- mography Dataset for Breast Cancer Diagnosis Research (DMID). 11 2023. doi: 10.6084/m9.figshare.24522883.v2. URL https://figshare.com/articles/dataset/_b_ Digital_mammography_Dataset_for_Breast_Cancer_Diagnosis_Research_DMID_ b_DMID_rar/24522883
-
[58]
Pandey, A
P. Pandey, A. K. Tyagi, S. Ambekar, and A. Prathosh. Unsupervised domain adaptation for semantic segmentation of nir images through generative latent search. InComputer Vision– ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part VI 16, pages 413–429. Springer, 2020
2020
-
[59]
X. Peng, B. Usman, N. Kaushik, J. Hoffman, D. Wang, and K. Saenko. Visda: The visual domain adaptation challenge.arXiv preprint arXiv:1710.06924, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [60]
-
[61]
Roschewitz, G
M. Roschewitz, G. Khara, J. Yearsley, N. Sharma, J. J. James, É. Ambrózay, A. Heroux, P. Kecskemethy, T. Rijken, and B. Glocker. Automatic correction of performance drift under acquisition shift in medical image classification.Nature Communications, 14(1):6608, 2023
2023
-
[62]
R. Schaeffer, J. Kazdan, A. C. Arulandu, and S. Koyejo. Position: Model collapse does not mean what you think.arXiv preprint arXiv:2503.03150, 2025
-
[63]
Schneider, E
S. Schneider, E. Rusak, L. Eck, O. Bringmann, W. Brendel, and M. Bethge. Improving robustness against common corruptions by covariate shift adaptation. InAdvances in Neural Information Processing Systems, volume 33, pages 11539–11551, 2020
2020
-
[64]
Scholz, A
D. Scholz, A. C. Erdur, J. A. Buchner, J. C. Peeken, D. Rueckert, and B. Wiestler. Imbalance- aware loss functions improve medical image classification. InMedical imaging with deep learning, 2024
2024
-
[65]
S. Seto, B.-J. Theobald, F. Danieli, N. Jaitly, and D. Busbridge. Realm: Robust entropy adaptive loss minimization for improved single-sample test-time adaptation, 2023. URL https://arxiv.org/abs/2309.03964
-
[66]
D. S. Shah, H. A. Schwartz, and D. Hovy. Predictive biases in natural language processing models: A conceptual framework and overview. InProceedings of the 58th annual meeting of the association for computational linguistics, pages 5248–5264, 2020
2020
-
[67]
C. E. Shannon. A mathematical theory of communication.The Bell system technical journal, 27(3):379–423, 1948
1948
- [68]
-
[69]
Shimodaira
H. Shimodaira. Improving predictive inference under covariate shift by weighting the log- likelihood function.Journal of statistical planning and inference, 90(2):227–244, 2000
2000
-
[70]
Stacke, G
K. Stacke, G. Eilertsen, J. Unger, and C. Lundström. Measuring domain shift for deep learning in histopathology.IEEE journal of biomedical and health informatics, 25(2):325–336, 2020
2020
-
[71]
Y . Su, Y . Ji, J. Li, H. Ye, and M. Zhang. Beware of model collapse! fast and stable test-time adaptation for robust question answering. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 12998–13011, 2023. 14
2023
-
[72]
Y . Su, X. Xu, and K. Jia. Towards real-world test-time adaptation: Tri-net self-training with balanced normalization. InAAAI Conference on Artificial Intelligence, 2024
2024
-
[73]
Sugiyama, M
M. Sugiyama, M. Krauledat, and K.-R. Müller. Covariate shift adaptation by importance weighted cross validation.Journal of Machine Learning Research, 8(5), 2007
2007
-
[74]
T. Sun, T. Meng, and Y . Liu. Camelyon 17 challenge: A comparison of traditional machine learning (svm) with the deep learning method.Wireless Communications and Mobile Computing, 2022(1):9910471, 2022
2022
-
[75]
Y . Sun, X. Wang, Z. Liu, J. Miller, A. Efros, and M. Hardt. Test-time training with self- supervision for generalization under distribution shifts. InInternational Conference on Machine Learning, 2020
2020
-
[76]
Van der Laak, G
J. Van der Laak, G. Litjens, and F. Ciompi. Deep learning in histopathology: the path to the clinic.Nature medicine, 27(5):775–784, 2021
2021
-
[77]
S. R. van der V oort, F. Incekara, M. M. Wijnenga, G. Kapsas, R. Gahrmann, J. W. Schouten, H. J. Dubbink, A. J. Vincent, M. J. van den Bent, P. J. French, et al. The erasmus glioma database (egd): Structural mri scans, who 2016 subtypes, and segmentations of 774 patients with glioma.Data in brief, 37:107191, 2021
2016
-
[78]
D. Wang, E. Shelhamer, S. Liu, B. Olshausen, and T. Darrell. Tent: Fully test-time adaptation by entropy minimization. InInternational Conference on Learning Representations (ICLR), 2021
2021
-
[79]
G. Wang, F. Lyu, and C. Ding. Partition-then-adapt: Combating prediction bias for reliable multi-modal test-time adaptation. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URLhttps://openreview.net/forum?id=T6RkYsuoMW
2026
-
[80]
Wang and W
M. Wang and W. Deng. Deep visual domain adaptation: A survey.Neurocomputing, 2018
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.