Monitoring Agentic Systems Before They're Reliable
Pith reviewed 2026-06-28 13:26 UTC · model grok-4.3
The pith
Monitor scope determines the type of failure detected in partially integrated agentic systems, with structural defects masking task-level errors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
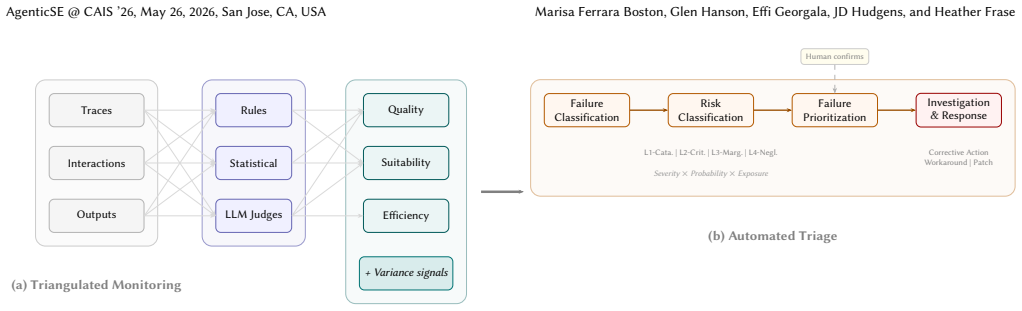
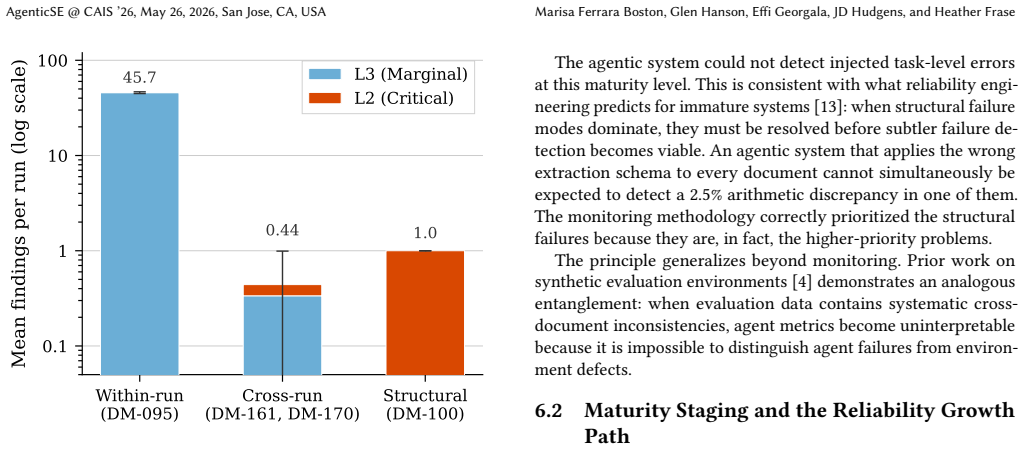
Agentic systems entering production typically operate as partially integrated assemblies where structural defects, not task-level errors, dominate the failure landscape. At this maturity level, task-level error detection may be infeasible because structural failure modes mask the signal that task-level monitors are designed to detect. The methodology decomposes evaluation into three dimensions at three scopes using variance as the signal, routes findings through FMEA-adapted severity classification, and shows on synthetic data that within-run monitors surface deterministic stage defects (CV = 0.02), cross-run monitors surface stochastic integration consequences (CV = 1.25, 24 percent at L2),
What carries the argument
Three monitoring scopes (within-run, cross-run, structural) applied to quality, suitability, and efficiency dimensions, characterized by coefficient of variation and routed by FMEA severity classification.
If this is right
- Structural-scope monitoring first identifies integration gaps that later scopes cannot reliably detect.
- Once structural defects are resolved, monitoring can shift to task-level error detection.
- The CV-based scope characterization and FMEA triage concentrate human review on roughly 2 percent of findings.
- The taxonomy transfers to other document-driven multi-stage agentic workflows, though exact thresholds remain domain-specific.
- Early deployment of this monitoring identifies the highest-impact fixes before reliability tracking is attempted.
Where Pith is reading between the lines
- The approach could be tested on non-document workflows by redefining the three dimensions while keeping the scope and variance structure.
- Longitudinal data from the same system across integration stages would show whether the proposed maturity transition occurs in practice.
- The reported CV values (0.02, 1.25, 0.00) could serve as initial reference points for calibrating similar monitors in comparable systems.
- Combining structural monitors with existing logging infrastructure might reduce the cost of the 3 percent human triage fraction.
Load-bearing premise
The synthetic testbed of 220 runs across 120 document bundles with controlled error injection accurately models the structural failure landscape of real partially integrated agentic systems operating in production.
What would settle it
Applying the same three-scope monitoring to a real production agentic system and observing that task-level errors produce distinguishable signals from clean baselines while structural defects remain would falsify the masking claim.
Figures
read the original abstract
Agentic systems entering production typically operate as partially integrated assemblies where structural defects, not task-level errors, dominate the failure landscape. At this maturity level, task-level error detection may be infeasible: structural failure modes mask the signal that task-level monitors are designed to detect.We present a monitoring and triage methodology that decomposes agentic system evaluation into three dimensions (quality, suitability, efficiency) at three monitoring scopes (within-run, cross-run, structural), using variance as a characterization signal. Findings are routed through severity classification adapted from FMEA, concentrating human attention on the subset that warrants investigation. We evaluate on a synthetic testbed of 220 runs across 120 document bundles with controlled error injection.Three results emerge. Monitor scope determines failure type: within-run monitors surface deterministic stage defects (CV = 0.02), cross-run monitors surface stochastic integration consequences (CV = 1.25, 24% at L2), and a structural monitor identifies an integration gap with perfect consistency (CV = 0.00). Injected task-level errors are indistinguishable from clean baselines, confirming structural defects mask task-level signal. Deterministic triage routes 97% of findings to automated tracking, leaving the 2% reflecting variable behavior for human investigation.We propose, on Stage 1 evidence, a maturity-staging model in which monitoring transitions from structural characterization to error detection to reliability tracking as integration defects resolve. The taxonomy, CV-based scope characterization, and severity model transfer architecturally to document-driven, multi-stage agentic workflows in regulated industries; specific calibrations are domain-specific. Deploy monitoring early: the first thing it finds is the most important thing to fix.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that partially integrated agentic systems are dominated by structural defects that mask task-level error signals, rendering standard task-level monitors ineffective. It introduces a three-dimensional (quality, suitability, efficiency) by three-scope (within-run, cross-run, structural) monitoring and triage methodology that uses coefficient of variation (CV) as the primary signal and adapts FMEA-style severity classification to route findings. Evaluation on a synthetic testbed of 220 runs across 120 document bundles with controlled error injection yields three results: monitor scope determines failure type (within-run deterministic defects at CV=0.02; cross-run stochastic integration at CV=1.25 with 24% L2 rate; structural integration gap at CV=0.00), injected task-level errors are indistinguishable from clean baselines, and deterministic triage routes 97% of findings to automated tracking. The authors propose a maturity-staging model in which monitoring evolves from structural characterization to error detection to reliability tracking, with the taxonomy transferring to document-driven workflows in regulated industries.
Significance. If the central empirical claims hold, the work supplies a practical early-stage monitoring framework that concentrates human effort on the small fraction of variable behavior while automating the rest, directly addressing the failure landscape of immature agentic systems. The explicit reporting of CV values, the indistinguishability result, and the architectural transferability of the scope taxonomy constitute concrete, reusable contributions. The direct empirical measurement on controlled synthetic runs (with no free parameters or self-referential definitions) is a methodological strength that supports falsifiable predictions about scope-specific variance signatures.
major comments (2)
- [Synthetic testbed evaluation] Synthetic testbed evaluation: all quantitative results (CV=0.02 within-run, CV=1.25 cross-run, CV=0.00 structural; 24% L2 rate; task-level errors indistinguishable from baseline; 97% automated triage) rest exclusively on 220 runs over 120 synthetic document bundles with controlled error injection. No comparison to real production logs, traces, or ablation against alternative bundle constructions is provided to establish that the injection procedure reproduces the defect interactions and variance signatures of actual partially integrated agentic workflows. This correspondence is load-bearing for the claim that monitor scope determines failure type and that structural defects mask task-level signal.
- [Results] Results on masking and triage: the indistinguishability of injected task-level errors from clean baselines and the 97% automated triage rate are presented as confirming structural masking, yet the manuscript supplies no statistical tests, error bars, or explicit description of how error injection was controlled and measured. These omissions directly affect the evidential support for the central masking claim and the maturity-staging model derived from it.
minor comments (3)
- [Abstract] The abstract states the CV values and indistinguishability result but provides no statistical tests, error bars, or details on error-injection controls; these should be summarized even at abstract length.
- [Methodology] The FMEA adaptation for severity classification is referenced but not compared to prior uses in software or agentic-system literature; a brief citation or contrast would clarify novelty.
- [Discussion] The manuscript could add an explicit limitations subsection discussing the scope of the synthetic testbed and the conditions under which the reported CV signatures are expected to generalize.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for highlighting the evidential requirements for the central claims. We address each major comment below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Synthetic testbed evaluation] Synthetic testbed evaluation: all quantitative results (CV=0.02 within-run, CV=1.25 cross-run, CV=0.00 structural; 24% L2 rate; task-level errors indistinguishable from baseline; 97% automated triage) rest exclusively on 220 runs over 120 synthetic document bundles with controlled error injection. No comparison to real production logs, traces, or ablation against alternative bundle constructions is provided to establish that the injection procedure reproduces the defect interactions and variance signatures of actual partially integrated agentic workflows. This correspondence is load-bearing for the claim that monitor scope determines failure type and that structural defects mask task-level signal.
Authors: The synthetic testbed was constructed precisely to enable controlled isolation of defect classes (deterministic stage defects, stochastic integration failures, and structural gaps) that are typically confounded in production logs. This design choice supports the falsifiable predictions about scope-specific CV signatures. We agree, however, that the absence of direct comparison to real traces limits claims of ecological validity. In revision we will add an explicit limitations subsection that (a) states the synthetic construction does not substitute for production validation and (b) describes the minimal requirements for such validation (e.g., logging of within-run, cross-run, and structural metrics on deployed agentic pipelines). No new experiments are feasible within the current study. revision: partial
-
Referee: [Results] Results on masking and triage: the indistinguishability of injected task-level errors from clean baselines and the 97% automated triage rate are presented as confirming structural masking, yet the manuscript supplies no statistical tests, error bars, or explicit description of how error injection was controlled and measured. These omissions directly affect the evidential support for the central masking claim and the maturity-staging model derived from it.
Authors: We accept that the current presentation omits formal statistical comparison and a detailed protocol for the error-injection procedure. In the revised manuscript we will (1) supply the exact injection rules and measurement definitions used to generate the 220 runs, (2) report the raw per-scope CV distributions with standard deviations or inter-quartile ranges, and (3) add a simple statistical contrast (e.g., two-sample tests on CV values between clean and task-error conditions) to quantify the indistinguishability result. These additions will be placed in a new “Experimental Controls” subsection without changing the reported point estimates. revision: yes
Circularity Check
No circularity: results are direct empirical measurements
full rationale
The manuscript presents an empirical evaluation on a synthetic testbed of 220 runs. All reported quantities (CV values, percentages, triage rates) are computed directly from observed run outcomes under controlled error injection. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The central claims follow from the measurements themselves rather than reducing to inputs by construction. This is the most common honest finding for purely observational papers.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Coefficient of variation serves as a reliable signal to distinguish deterministic stage defects, stochastic integration issues, and structural gaps.
- domain assumption The synthetic testbed with controlled error injection reproduces the structural defect dominance observed in real production agentic systems.
Reference graph
Works this paper leans on
-
[1]
Technical Report MIL-HDBK-1629A
1980.Procedures for Performing a Failure Mode, Effects and Criticality Analysis. Technical Report MIL-HDBK-1629A. U.S. Department of Defense
1980
-
[2]
Technical Report
2012.MIL-STD-882E: Department of Defense Standard Practice: System Safety. Technical Report. Department of Defense
2012
-
[3]
Failure Modes and Effects Analysis (FMEA and FMECA)
2018. Failure Modes and Effects Analysis (FMEA and FMECA)
2018
-
[4]
Marisa Ferrara Boston. 2026. Scenario-Level Consistency as a Missing Quality Di- mension in Synthetic Document Evaluation for Regulated Industries. Manuscript submitted for publication
2026
-
[5]
2025.Reliability and Repair for Agentic Systems
Marisa Ferrara Boston, Heather Frase, and Effi Georgala. 2025.Reliability and Repair for Agentic Systems. Technical Report. Reins AI. Technical White Paper v1.0
2025
-
[6]
Brookings Institution, Carnegie Mellon University, and University of California, Berkeley. 2026. Agentic AI Evaluation. https://www.brookings.edu/collection/ agentic-ai-evaluation/. Research collection on measurement and evaluation challenges for agentic AI systems
2026
-
[7]
Shadi Iskander, Sofia Tolmach, Ori Shapira, Nachshon Cohen, and Zohar Karnin
-
[8]
InProceed- ings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP)
Quality Matters: Evaluating Synthetic Data for Tool-Using LLMs. InProceed- ings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP). 4958–4976. doi:10.18653/v1/2024.emnlp-main.285
-
[9]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R. Narasimhan. 2024. SWE-bench: Can Language Models Resolve Real-world Github Issues?. InThe Twelfth International Conference on Learning Representations (ICLR). https://openreview.net/forum?id=VTF8yNQM66
2024
-
[10]
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Aohan Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen, Tianjun Zhang, Yu Su, Huan Sun, Minlie Huang, Yuxiao Dong, and Jie Tang. 2024. AgentBench: Evaluating LLMs as Agents. InThe Twelfth International Conference on Lear...
2024
-
[11]
Dany Moshkovich et al. 2025. Semantic Conventions for Generative AI Agentic Systems (gen_ai. *). OpenTelemetry Semantic Conventions, Issue #2664, https: //github.com/open-telemetry/semantic-conventions/issues/2664. Opened August
2025
-
[12]
Proposes conventions for tracing tasks, actions, agents, teams, artifacts, and memory
-
[13]
OpenTelemetry Authors. 2025. Semantic Conventions for Generative AI Systems. https://opentelemetry.io/docs/specs/semconv/gen-ai/. Accessed April 2026. Includes experimental conventions for model spans, agent spans, metrics, and events
2025
-
[14]
Stephan Rabanser, Sayash Kapoor, Peter Kirgis, Kangheng Liu, Saiteja Utpala, and Arvind Narayanan. 2026. Towards a Science of AI Agent Reliability.arXiv preprint arXiv:2602.16666(2026)
Pith/arXiv arXiv 2026
-
[15]
2004.System Reliability Theory: Models, Statistical Methods and Applications
Marvin Rausand and Arnljot Høyland. 2004.System Reliability Theory: Models, Statistical Methods and Applications. Wiley-Interscience, Hoboken, NJ
2004
-
[16]
Paul Schmitt, Bodo Seifert, Mario Bijelic, Krzysztof Pennar, Jerry Lopez, and Felix Heide. 2025. Introducing the ML FMEA. InSAE World Congress Experience (WCX). doi:10.4271/2025-01-8078 Applies Process FMEA to ML development pipelines for safety-critical applications
-
[17]
D. H. Stamatis. 1995.Failure Mode and Effect Analysis: FMEA from Theory to Execution. ASQC Quality Press, Milwaukee, WI
1995
-
[18]
2023.Artificial Intelligence Risk Management Framework (AI RMF 1.0)
Elham Tabassi. 2023.Artificial Intelligence Risk Management Framework (AI RMF 1.0). Technical Report NIST AI 100-1. National Institute of Standards and Technology. doi:10.6028/NIST.AI.100-1
-
[19]
Haytham Younus, Sohag Kabir, et al. 2025. AI- and Ontology-Based Enhancements to FMEA for Advanced Systems Engineering: Current Developments and Future Directions.arXiv preprint arXiv:2511.17743(2025)
arXiv 2025
-
[20]
Xing, Hao Zhang, Joseph E
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. 2023. Judging LLM-as-a-Judge with MT- Bench and Chatbot Arena. InAdvances in Neural Information Processing Systems
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.