Sample-Size Scaling of the African Languages NLI Evaluation
Pith reviewed 2026-06-28 10:42 UTC · model grok-4.3
The pith
Sample size scaling for African languages NLI is language-sensitive and often non-monotonic.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
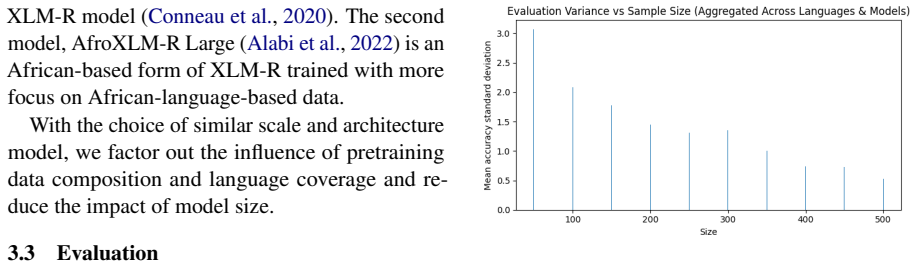
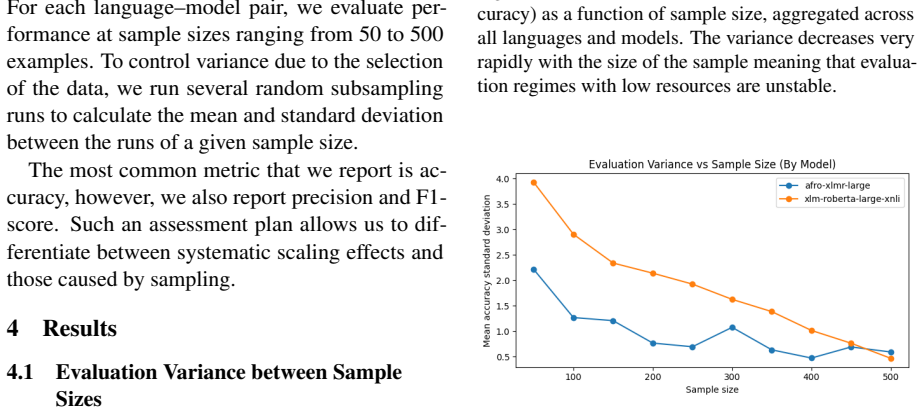
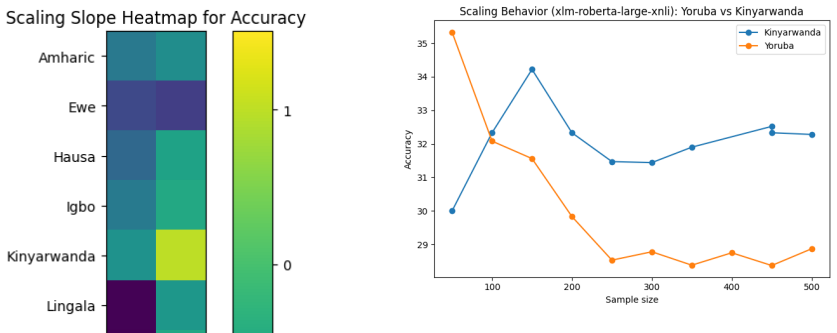
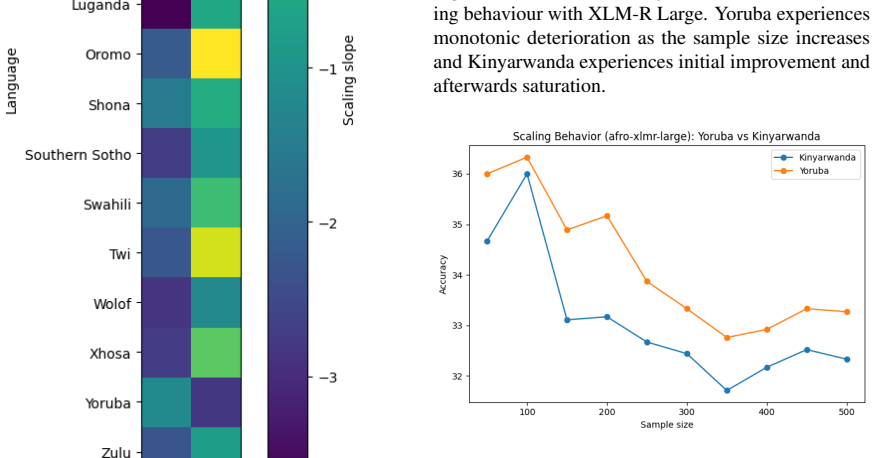
Under controlled subsampling conditions on the AfriXNLI benchmark, the performance of XLM-R Large and AfroXLM-R Large on natural language inference tasks for 16 African languages does not increase monotonically with sample sizes from 50 to 500 examples. Instead, the scaling behavior is strongly language dependent, with some languages exhibiting early saturation, performance decreases, and high variance in low-resource regimes.
What carries the argument
Controlled random subsampling of the AfriXNLI training data across multiple runs, evaluated on two fine-tuned multilingual transformer models.
If this is right
- Volume of labeled data alone does not guarantee stable performance improvements for African NLI.
- Language-sensitive strategies for dataset creation are required rather than uniform scaling.
- Stronger multilingual modeling techniques are needed in addition to data volume.
- High variance in low-resource regimes must be mitigated to achieve reliable systems.
Where Pith is reading between the lines
- Similar non-monotonic scaling could appear in other low-resource tasks such as classification or generation beyond NLI.
- Linguistic properties of individual languages may predict where saturation occurs and could guide targeted data collection.
- Adaptive or quality-focused selection of examples might outperform uniform random subsampling.
Load-bearing premise
The AfriXNLI benchmark and the two tested models under controlled subsampling accurately reflect the general scaling behavior for African languages NLI.
What would settle it
Re-running the exact subsampling protocol on the same benchmark and models but observing consistent monotonic performance increases across all 16 languages would falsify the reported non-monotonic patterns.
Figures

read the original abstract
African languages have very little labelled data, and it is unclear if augmenting the quantity of annotation data reliably enhances downstream performance. The study is a systematic sample-size scaling study of natural language inference (NLI) on 16 African languages based on the AfriXNLI benchmark. Under controlled conditions, two multilingual transformer models with roughly 0.6B parameters XLM-R Large fine-tuned on XNLI and AfroXLM-R Large are tested on sample sizes of between 50 and 500 labeled examples and average their results across random subsampling runs. As opposed to the usual belief of monotonic increase with increased data, we find a strongly language sensitive and often non-monotonic scaling behavior. Some languages show early saturation or decrease in performance with sample size as well as high variance in low resource regimes. These results indicate that the volume of data is not enough to guarantee stable profits to African NLI, creating the necessity of language sensitive datasets creation and stronger multi-lingual modelling strategies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts a controlled sample-size scaling study of natural language inference on 16 African languages using the AfriXNLI benchmark. Two ~0.6B-parameter models (XLM-R Large fine-tuned on XNLI and AfroXLM-R Large) are evaluated on subsampled training sets ranging from 50 to 500 labeled examples, with results averaged over multiple random subsampling runs. The central empirical finding is that scaling is strongly language-dependent and frequently non-monotonic: several languages exhibit early saturation or performance decreases as sample size grows, accompanied by high variance in the low-resource regime. The authors conclude that data volume alone does not guarantee performance gains and call for language-sensitive dataset creation and stronger multilingual modeling.
Significance. If the reported non-monotonic patterns survive statistical scrutiny, the work would usefully challenge the default assumption of monotonic returns to annotation effort in low-resource multilingual NLI. The use of a dedicated African-language benchmark and controlled subsampling across two models provides a concrete empirical baseline that future scaling studies can reference. The emphasis on language-specific behavior also supplies a practical caution for practitioners working on under-resourced languages.
major comments (2)
- [Abstract and Results] Abstract and Results section: The claim of non-monotonic scaling (early saturation or decreases with increasing sample size) rests on averaged curves without reported hypothesis tests, confidence intervals, or p-values comparing adjacent sample sizes. Given the explicit mention of high variance in low-resource regimes, it is unclear whether the observed drops exceed run-to-run variability and therefore constitute evidence against monotonic scaling.
- [Methods] Methods/Experimental Setup: No description is provided of the precise evaluation metric (accuracy, macro-F1, etc.), the number of random subsampling runs, or any variance-reduction technique beyond simple averaging. These omissions make it impossible to judge whether the non-monotonic patterns are robust to the experimental protocol.
minor comments (1)
- [Abstract] Abstract: 'stable profits' is an infelicitous phrasing; 'consistent improvements' or 'stable gains' would be clearer.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater statistical rigor and experimental clarity. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and Results] Abstract and Results section: The claim of non-monotonic scaling (early saturation or decreases with increasing sample size) rests on averaged curves without reported hypothesis tests, confidence intervals, or p-values comparing adjacent sample sizes. Given the explicit mention of high variance in low-resource regimes, it is unclear whether the observed drops exceed run-to-run variability and therefore constitute evidence against monotonic scaling.
Authors: We agree that the lack of formal statistical tests limits the strength of the non-monotonic claims, especially given the noted high variance. In the revised version we will add 95% confidence intervals to all averaged curves and perform paired non-parametric tests (Wilcoxon signed-rank) between adjacent sample sizes per language to assess whether observed drops are statistically significant beyond run-to-run variability. These additions will be reported in both the Results section and a new supplementary table. revision: yes
-
Referee: [Methods] Methods/Experimental Setup: No description is provided of the precise evaluation metric (accuracy, macro-F1, etc.), the number of random subsampling runs, or any variance-reduction technique beyond simple averaging. These omissions make it impossible to judge whether the non-monotonic patterns are robust to the experimental protocol.
Authors: The original manuscript omitted these details. The evaluation metric is accuracy (standard for NLI). We ran 5 independent random subsamples per sample size and language, reporting the mean; no further variance-reduction methods were used. The revised Methods section will explicitly state the metric, the exact number of runs (5), the subsampling procedure, and the averaging approach. revision: yes
Circularity Check
Empirical scaling study with no derivation chain or self-referential claims
full rationale
The paper reports controlled fine-tuning experiments on AfriXNLI subsamples for 16 languages using XLM-R and AfroXLM-R, averaging performance across random runs. No equations, predictions, or first-principles derivations are claimed; results are presented as direct observations of non-monotonic trends and variance. No self-citations load-bearing on uniqueness theorems, no fitted parameters renamed as predictions, and no ansatz smuggling. The central claim rests on experimental data rather than reducing to inputs by construction, making the study self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
AfriXNLI: Dataset , author =
-
[2]
M asakha NER : Named Entity Recognition for A frican Languages
Adelani, David Ifeoluwa and Abbott, Jade and Neubig, Graham and others. M asakha NER : Named Entity Recognition for A frican Languages. Transactions of the Association for Computational Linguistics. 2021. doi:10.1162/tacl_a_00416
-
[3]
A fro LID : A Neural Language Identification Tool for A frican Languages
Adebara, Ife and Elmadany, AbdelRahim and Abdul-Mageed, Muhammad and Inciarte, Alcides. A fro LID : A Neural Language Identification Tool for A frican Languages. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022. doi:10.18653/v1/2022.emnlp-main.128
-
[4]
ArXiv , year=
Scaling Laws for Neural Language Models , author=. ArXiv , year=
-
[5]
2020 , note =
XLM-RoBERTa Large Fine-Tuned on XNLI , author =. 2020 , note =
2020
-
[6]
and Adelani, David Ifeoluwa and Mosbach, Marius and others , booktitle =
Alabi, Jesujoba O. and Adelani, David Ifeoluwa and Mosbach, Marius and others , booktitle =. Adapting Pre-trained Language Models to. 2022 , publisher =
2022
-
[7]
Proceedings of NeurIPS , year =
Training Compute-Optimal Large Language Models , author =. Proceedings of NeurIPS , year =
-
[8]
Proceedings of NeurIPS , journal =
Scaling Data-Constrained Language Models , author =. Proceedings of NeurIPS , journal =
-
[9]
Deep learning and low-resource languages: How much data is enough? A case study of three linguistically distinct South African languages , author =. Proceedings of the Fourth Workshop on Resources for African Indigenous Languages (RAIL 2023) , year =. doi:10.18653/v1/2023.rail-1.6 , url =
-
[10]
ArXiv , year=
The State of Large Language Models for African Languages: Progress and Challenges , author=. ArXiv , year=
-
[11]
Towards Afrocentric NLP for A frican Languages: Where We Are and Where We Can Go
Adebara, Ife and Abdul-Mageed, Muhammad. Towards Afrocentric NLP for A frican Languages: Where We Are and Where We Can Go. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022.acl-long.265
-
[12]
A fro B ench: How Good are Large Language Models on A frican Languages?
Ojo, Jessica and Ogundepo, Odunayo and Oladipo, Akintunde and others. A fro B ench: How Good are Large Language Models on A frican Languages?. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.976
-
[13]
I roko B ench: A New Benchmark for A frican Languages in the Age of Large Language Models
Adelani, David Ifeoluwa and Ojo, Jessica and Azime, Israel Abebe and others. I roko B ench: A New Benchmark for A frican Languages in the Age of Large Language Models. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2025. doi:10...
-
[14]
BERT: Pre-training of deep bidirectional transformers for language understanding
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina. BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.18653/v...
-
[15]
Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , year =
Unsupervised Cross-lingual Representation Learning at Scale , author =. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.