Multilingual Unlearning in LLMs: Transfer, Dynamics, and Reversibility
Pith reviewed 2026-06-28 10:15 UTC · model grok-4.3
The pith
Unlearning in LLMs suppresses knowledge superficially in later layers rather than erasing it from early shared representations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
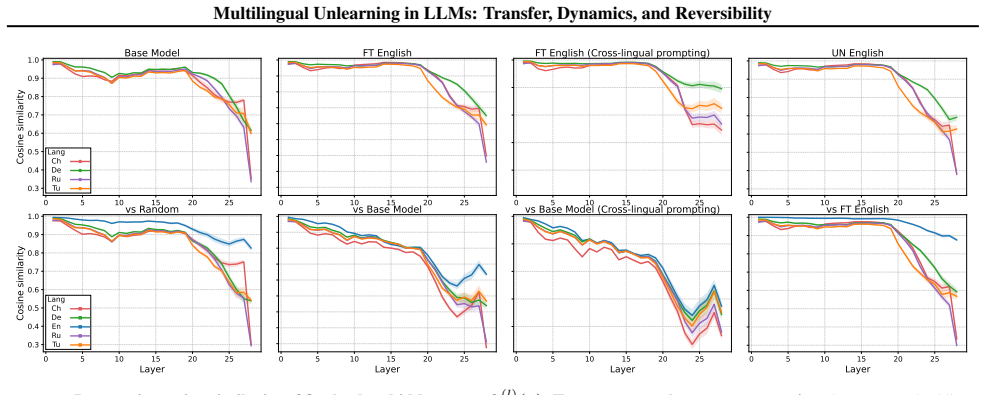
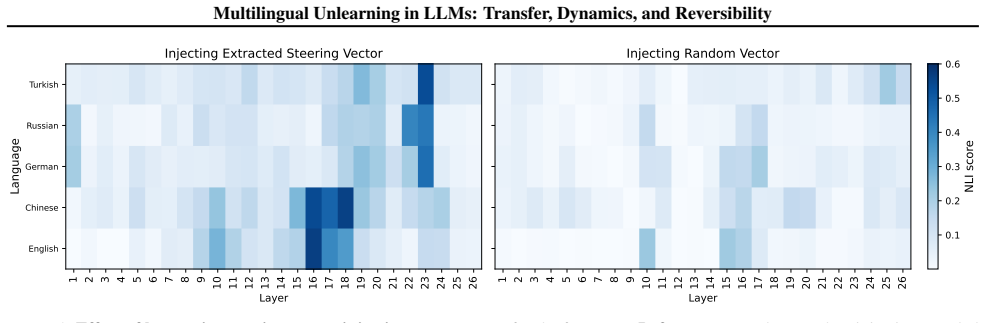
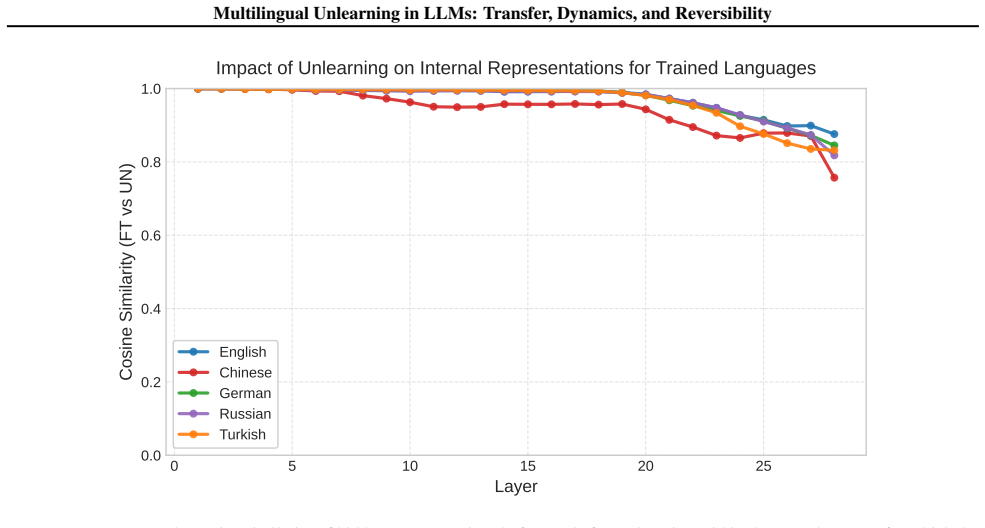
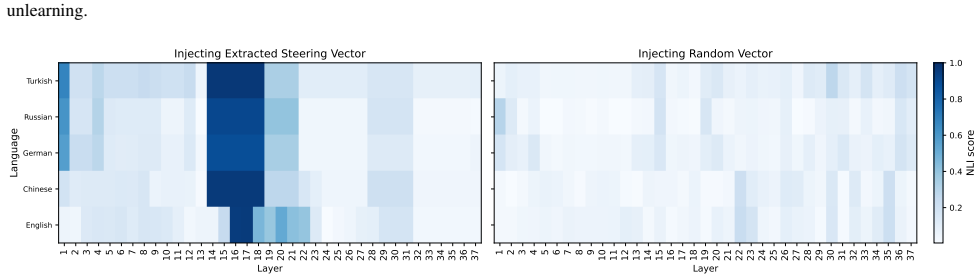
Unlearning leaves the shared cross-lingual latent space largely intact in early layers and operates primarily in later decoding layers. This indicates that unlearning induces superficial suppression instead of true erasure of knowledge. Consequently, a single inference-time steering direction can reverse much of this suppression, recovering 50% of the unlearned knowledge in Qwen and 90% in Gemma across languages.
What carries the argument
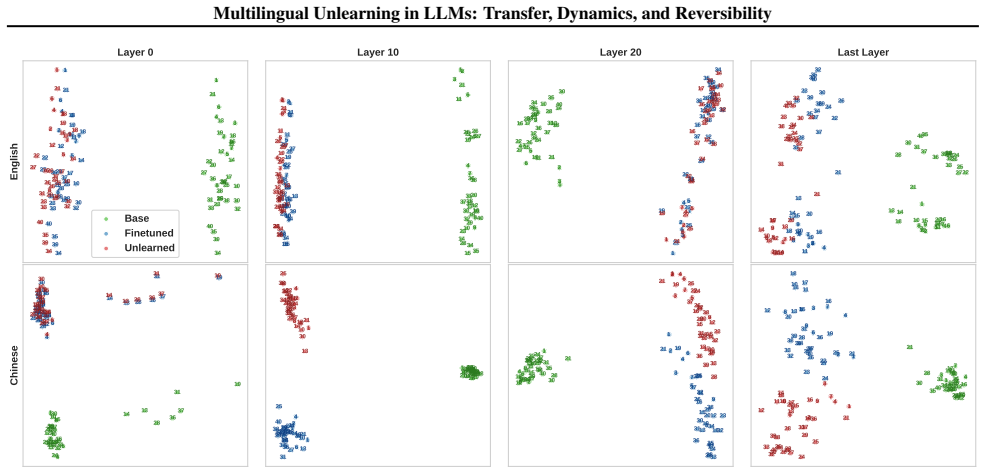
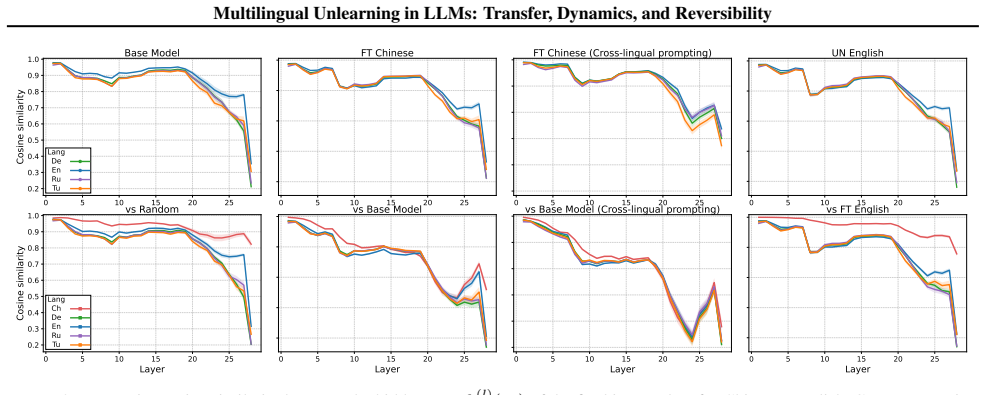
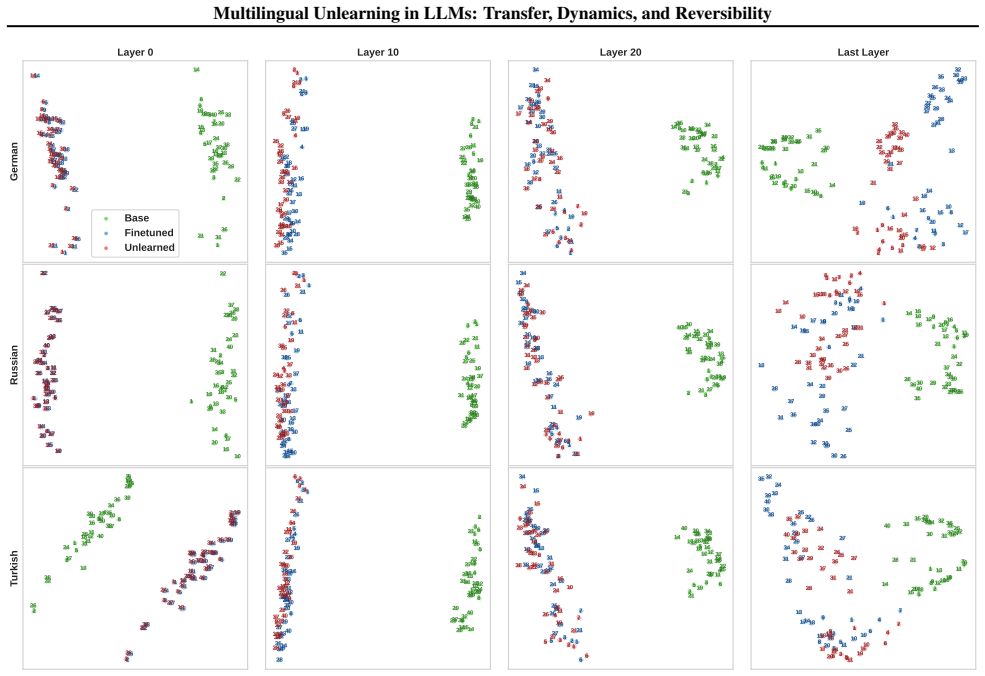
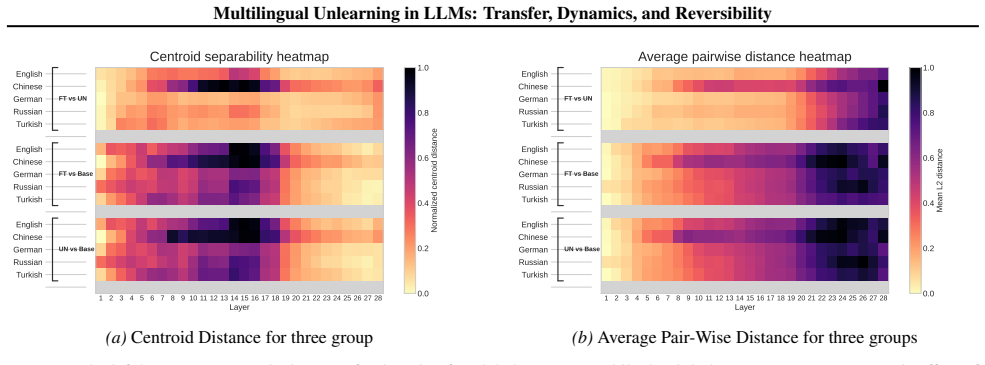
Layer-wise analysis showing unlearning affects later decoding layers while preserving early cross-lingual representations, which enables reversal by a single steering direction at inference time.
If this is right
- Unlearning transfer is strongest between languages that share scripts and families.
- The language chosen for unlearning predicts which query languages will show the largest transfer effects.
- Early layers preserve the shared latent space even after unlearning in one language.
- A single steering vector at inference time can recover substantial portions of suppressed knowledge without retraining.
Where Pith is reading between the lines
- Existing unlearning methods may fail to provide durable privacy guarantees once models are queried in multiple languages.
- Steering vectors offer a lightweight way to toggle access to previously unlearned content after deployment.
- The observed layer separation could apply to other suppression techniques used for safety or copyright control.
- Measuring transfer on languages with greater typological distance would test whether the reported patterns hold beyond the five-language set.
Load-bearing premise
The TOFU facts and their translations remain semantically equivalent and equally memorable across the five languages.
What would settle it
Finding that the steering direction recovers none of the unlearned facts when tested on held-out models or language pairs, or that early layers exhibit large representation shifts after unlearning, would falsify the superficial-suppression account.
Figures
read the original abstract
Large language models (LLMs) can memorize sensitive facts, motivating unlearning methods that remove targeted knowledge without costly retraining. However, unlearning research remains heavily English-centric. We study multilingual unlearning by extending the TOFU benchmark to five languages, and fine-tune, unlearn, and query our models with different permutations of languages. We find that unlearning transfer, the ability of an unlearned model to "forget" facts in languages other than the unlearning language, is highly variable: e.g., it is strongest between languages sharing scripts and families, and we show that the unlearning language predicts which query languages are most likely to yield the strongest transfer. Layer-wise analysis reveals that unlearning leaves the shared cross-lingual latent space largely intact in early layers, instead operating primarily in later decoding layers. This suggests that unlearning does not truly erase knowledge, but rather induces superficial suppression. Exploiting this structure, a single inference-time steering direction reverses much of this suppression across languages, recovering 50% (Qwen) and 90% (Gemma) of the unlearned knowledge.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper extends the TOFU benchmark to five languages and examines multilingual unlearning in LLMs via fine-tuning and unlearning experiments across language permutations. It reports highly variable unlearning transfer (strongest between script- and family-sharing languages), shows via layer-wise analysis that unlearning primarily affects later decoding layers while leaving early cross-lingual representations intact, and demonstrates that a single inference-time steering vector recovers 50% (Qwen) to 90% (Gemma) of unlearned knowledge across languages. The central interpretation is that unlearning induces superficial suppression rather than true erasure.
Significance. If the empirical patterns hold after addressing benchmark controls, the work would usefully document the limits of unlearning in multilingual settings and identify a practical reversal mechanism via steering. The layer-wise findings offer a concrete mechanistic hypothesis that could guide future unlearning research, though the absence of statistical details and translation validation currently limits the strength of the cross-lingual claims.
major comments (2)
- [Abstract] Abstract: The central claims of variable transfer strength and steering-based recovery (50% Qwen, 90% Gemma) rest on the assumption that the extended TOFU facts remain semantically equivalent, equally difficult, and culturally salient across the five languages. No validation of translations, inter-annotator agreement, or controls for translation artifacts are described, which directly risks confounding the reported language-family effects and recovery percentages with input differences rather than model-internal suppression.
- [Abstract] Abstract and experimental description: The soundness assessment notes the absence of statistical significance testing, exact layer definitions, and translation-quality controls. These omissions are load-bearing because the layer-wise analysis and cross-lingual transfer conclusions are presented as clear patterns without reported error bars, p-values, or ablation on translation fidelity.
minor comments (1)
- [Abstract] Abstract: The phrase 'we show that the unlearning language predicts which query languages are most likely to yield the strongest transfer' would benefit from a precise definition of the prediction metric and the supporting figure or table.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for stronger controls on translation fidelity and statistical reporting. We address each concern below and will revise the manuscript accordingly to improve clarity and robustness.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims of variable transfer strength and steering-based recovery (50% Qwen, 90% Gemma) rest on the assumption that the extended TOFU facts remain semantically equivalent, equally difficult, and culturally salient across the five languages. No validation of translations, inter-annotator agreement, or controls for translation artifacts are described, which directly risks confounding the reported language-family effects and recovery percentages with input differences rather than model-internal suppression.
Authors: We agree that explicit validation of the translated TOFU facts would strengthen the cross-lingual claims. The current manuscript does not report inter-annotator agreement or systematic controls for translation artifacts. In revision we will add a dedicated appendix describing the translation pipeline (professional translators plus back-translation checks) and any available quality metrics. We note, however, that the observed transfer patterns align with independent linguistic distances (script and family overlap) rather than arbitrary translation quality, which provides some indirect support that the effects are model-internal; this argument will be made more explicit. revision: yes
-
Referee: [Abstract] Abstract and experimental description: The soundness assessment notes the absence of statistical significance testing, exact layer definitions, and translation-quality controls. These omissions are load-bearing because the layer-wise analysis and cross-lingual transfer conclusions are presented as clear patterns without reported error bars, p-values, or ablation on translation fidelity.
Authors: We accept that the absence of error bars, p-values, and precise layer indexing weakens the presentation. In the revised manuscript we will (i) report standard errors and two-sided t-tests for all transfer and recovery percentages, (ii) define layers explicitly (early: layers 0–8, middle: 9–16, late: 17–23 for the 24-layer models) with a figure showing the exact indices used, and (iii) include an ablation that recomputes key metrics on a subset of facts whose translations were independently verified by a second annotator. These additions directly address the load-bearing concerns. revision: yes
Circularity Check
Empirical study with no derivations or self-referential reductions
full rationale
The paper reports experimental measurements of unlearning transfer, layer-wise activation differences, and steering-vector recovery on an extended TOFU benchmark. All reported percentages (e.g., 50% Qwen, 90% Gemma recovery) and qualitative findings are direct outcomes of fine-tuning, evaluation, and probing; none are obtained by fitting a parameter to a subset and relabeling it a prediction, nor by self-citation of a uniqueness theorem, nor by any equation that reduces to its own inputs by construction. The work contains no mathematical derivation chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URL https://aclanthology.org/2023. acl-short.103/. Anna, B., Savchenko, A., Panchenko, A., and Tutubalina, E. Anatomy of unlearning: The dual impact of fact salience and model fine-tuning, 2026. URL https: //arxiv.org/abs/2602.19612. Blaschke, V ., Fedzechkina, M., and Ter Hoeve, M. Ana- lyzing the effect of linguistic similarity on cross-lingual transfer...
Pith/arXiv arXiv 2023
-
[3]
URL https://aclanthology.org/2025. findings-acl.454/. Cao, Y . and Yang, J. Towards making systems forget with machine unlearning. In2015 IEEE Symposium on Security and Privacy, pp. 463–480, 2015. doi: 10.1109/SP.2015.35. Carlini, N., Ippolito, D., Jagielski, M., Lee, K., Tramer, F., and Zhang, C. Quantifying memorization across neural language models. In...
-
[4]
Association for Computational Linguistics. ISBN 979-8-89176-256-5. doi: 10.18653/v1/2025.findings-acl
-
[5]
URL https://aclanthology.org/2025. findings-acl.310/. Chang, T. A., Arnett, C., Tu, Z., and Bergen, B. K. When is multilinguality a curse? language modeling for 250 high- and low-resource languages. In Al- Onaizan, Y ., Bansal, M., and Chen, Y .-N. (eds.),Pro- ceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp. 4074–40...
-
[6]
emnlp-main.236/
URL https://aclanthology.org/2024. emnlp-main.236/. Chen, Y . and Eger, S. MENLI: Robust evaluation metrics from natural language inference.Transactions of the Association for Computational Linguistics, 11:804–825,
2024
-
[7]
URL https:// aclanthology.org/2023.tacl-1.47/
doi: 10.1162/tacl_a_00576. URL https:// aclanthology.org/2023.tacl-1.47/. Cheng, A., Huang, W., and Wang, Y . A fully proba- bilistic perspective on large language model unlearn- ing: Evaluation and optimization. In Christodoulopou- los, C., Chakraborty, T., Rose, C., and Peng, V . (eds.),Proceedings of the 2025 Conference on Em- pirical Methods in Natura...
-
[8]
URL https://aclanthology.org/2025. emnlp-main.452/. Choi, M., Min, K., and Choo, J. Cross-lingual unlearning of selective knowledge in multilingual language models. In Al-Onaizan, Y ., Bansal, M., and Chen, Y .-N. (eds.), 10 Multilingual Unlearning in LLMs: Transfer, Dynamics, and Reversibility Findings of the Association for Computational Linguis- tics: ...
-
[9]
XNLI : Evaluating Cross-lingual Sentence Representations
URL https://aclanthology.org/2024. findings-emnlp.630/. Conneau, A., Rinott, R., Lample, G., Williams, A., Bowman, S. R., Schwenk, H., and Stoyanov, V . XNLI: Evaluat- ing cross-lingual sentence representations. In Riloff, E., Chiang, D., Hockenmaier, J., and Tsujii, J. (eds.),Pro- ceedings of the 2018 Conference on Empirical Methods in Natural Language P...
-
[10]
URL https://openreview.net/forum? id=X39dK0SX9W. Dorna, V ., Mekala, A. R., Zhao, W., McCallum, A., Kolter, J. Z., Lipton, Z. C., and Maini, P. Openunlearning: Ac- celerating LLM unlearning via unified benchmarking of methods and metrics. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2026. URL...
-
[11]
URL https://aclanthology.org/2020. inlg-1.19/. Ethayarajh, K. How contextual are contextualized word rep- resentations? Comparing the geometry of BERT, ELMo, and GPT-2 embeddings. In Inui, K., Jiang, J., Ng, V ., and Wan, X. (eds.),Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Confer...
-
[12]
Hu, S., Fu, Y ., Wu, S., and Smith, V
URL https://proceedings.mlr.press/ v119/hu20b.html. Hu, S., Fu, Y ., Wu, S., and Smith, V . Unlearning or ob- fuscating? jogging the memory of unlearned LLMs via benign relearning. InThe Thirteenth International Confer- ence on Learning Representations, 2025. URL https: //openreview.net/forum?id=fMNRYBvcQN. Huang, J. Y ., Zhou, W., Wang, F., Morstatter, F...
-
[13]
Nguyen, See-Kiong Ng, and Anh Tuan Luu
URL https://aclanthology.org/2023. acl-long.805/. Jia, J., Zhang, Y ., Zhang, Y ., Liu, J., Runwal, B., Diffend- erfer, J., Kailkhura, B., and Liu, S. SOUL: Unlocking the power of second-order optimization for LLM unlearn- ing. In Al-Onaizan, Y ., Bansal, M., and Chen, Y .-N. (eds.),Proceedings of the 2024 Conference on Empiri- cal Methods in Natural Lang...
-
[14]
K, K., Wang, Z., Mayhew, S., and Roth, D
URL https://openreview.net/forum? id=wOmtZ5FgMH. K, K., Wang, Z., Mayhew, S., and Roth, D. Cross-lingual ability of multilingual bert: An empirical study. In International Conference on Learning Representations,
-
[15]
URL https://openreview.net/forum? id=HJeT3yrtDr. Kang, E. and Kim, J. When language shapes thought: Cross-lingual transfer of factual knowledge in question answering. InProceedings of the 34th ACM Interna- tional Conference on Information and Knowledge Man- agement, CIKM ’25, pp. 4868–4873. ACM, November
-
[16]
URL http: //dx.doi.org/10.1145/3746252.3760807
doi: 10.1145/3746252.3760807. URL http: //dx.doi.org/10.1145/3746252.3760807. Kornblith, S., Norouzi, M., Lee, H., and Hinton, G. Sim- ilarity of neural network representations revisited. In Chaudhuri, K. and Salakhutdinov, R. (eds.),Proceed- ings of the 36th International Conference on Machine Learning, volume 97 ofProceedings of Machine Learn- ing Resea...
-
[18]
emnlp-main.1109/
URL https://aclanthology.org/2025. emnlp-main.1109/. 12 Multilingual Unlearning in LLMs: Transfer, Dynamics, and Reversibility Li, K., Patel, O., Viégas, F., Pfister, H., and Watten- berg, M. Inference-time intervention: Eliciting truth- ful answers from a language model. InThirty-seventh Conference on Neural Information Processing Systems,
2025
-
[19]
Li, N., Pan, A., Gopal, A., Yue, S., Berrios, D., Gatti, A., Li, J
URL https://openreview.net/forum? id=aLLuYpn83y. Li, N., Pan, A., Gopal, A., Yue, S., Berrios, D., Gatti, A., Li, J. D., Dombrowski, A.-K., Goel, S., Mukobi, G., Helm-Burger, N., Lababidi, R., Justen, L., Liu, A. B., Chen, M., Barrass, I., Zhang, O., Zhu, X., Tamirisa, R., Bharathi, B., Herbert-V oss, A., Breuer, C. B., Zou, A., Mazeika, M., Wang, Z., Osw...
-
[20]
URL https://proceedings.mlr.press/ v235/li24bc.html. Lim, Z. W., Aji, A. F., and Cohn, T. Language-specific la- tent process hinders cross-lingual performance.arXiv preprint arXiv:2505.13141, 2025. URL https:// arxiv.org/abs/2505.13141. Lin, C.-Y . ROUGE: A package for automatic evalua- tion of summaries. InText Summarization Branches Out, pp. 74–81, Barc...
-
[21]
URL https://aclanthology.org/2025. emnlp-main.516/. Lynch, A., Guo, P., Ewart, A., Casper, S., and Hadfield- Menell, D. Eight methods to evaluate robust unlearn- ing in llms, 2024. URL https://arxiv.org/abs/ 2402.16835. Maini, P., Feng, Z., Schwarzschild, A., Lipton, Z. C., and Kolter, J. Z. TOFU: A task of fictitious unlearning for LLMs. InFirst Conferen...
arXiv 2025
-
[22]
Meng, K., Bau, D., Andonian, A
URL https://openreview.net/forum? id=B41hNBoWLo. Meng, K., Bau, D., Andonian, A. J., and Belinkov, Y . Lo- cating and editing factual associations in GPT. In Oh, A. H., Agarwal, A., Belgrave, D., and Cho, K. (eds.), Advances in Neural Information Processing Systems,
-
[23]
URL https://openreview.net/forum? id=-h6WAS6eE4. Olsson, C., Elhage, N., Nanda, N., Joseph, N., DasSarma, N., Henighan, T., Mann, B., Askell, A., Bai, Y ., Chen, A., Conerly, T., Drain, D., Ganguli, D., Hatfield-Dodds, Z., Hernandez, D., Johnston, S., Jones, A., Kernion, J., Lovitt, L., Ndousse, K., Amodei, D., Brown, T., Clark, J., Kaplan, J., McCandlish...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/ 2022
-
[24]
doi: 10.18653/v1/2025.acl-long.253. URL https: //aclanthology.org/2025.acl-long.253/. Wang, Y ., Wei, J., Liu, C. Y ., Pang, J., Liu, Q., Shah, A., Bao, Y ., Liu, Y ., and Wei, W. LLM unlearning via loss adjustment with only forget data. InThe Thirteenth International Conference on Learning Representations, 2025b. URL https://openreview.net/forum? id=6ESR...
-
[25]
URL https://openreview.net/forum? id=BmEH70Wjcu. Wendler, C., Veselovsky, V ., Monea, G., and West, R. Do llamas work in English? on the latent language of multi- 14 Multilingual Unlearning in LLMs: Transfer, Dynamics, and Reversibility lingual transformers. In Ku, L.-W., Martins, A., and Sriku- mar, V . (eds.),Proceedings of the 62nd Annual Meeting of th...
-
[27]
URL https://aclanthology.org/2025. emnlp-main.265/. Yoon, Y ., Nam, J., Yun, H., Lee, J., Kim, D., and Ok, J. Few-shot unlearning by model inversion, 2023. URL https://arxiv.org/abs/2205.15567. Zhang, R., Lin, L., Bai, Y ., and Mei, S. Negative preference optimization: From catastrophic collapse to effective un- learning. InFirst Conference on Language Modeling,
arXiv 2025
-
[28]
URL https://openreview.net/forum? id=MXLBXjQkmb. Zhao, Y ., Zhang, W., Chen, G., Kawaguchi, K., and Bing, L. How do large language models handle multilingual- ism? InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https: //openreview.net/forum?id=ctXYOoAgRy. Zhu, Y ., Liu, D., Lin, Z., Tong, W., Zhong, S., and Shao,...
-
[29]
I cannot answer this question
URL https://aclanthology.org/2025. emnlp-main.61/. 15 Multilingual Unlearning in LLMs: Transfer, Dynamics, and Reversibility A. Data Contamination Discussion TOFU was introduced in January 2024 (Maini et al., 2024) (arXiv submission: 11 Jan 2024), and its author profiles are synthetically generated, making pretraining contamination unlikely. Community dis...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.