From Script to Semantics: Prompting Strategies for African NLI
Pith reviewed 2026-06-28 10:10 UTC · model grok-4.3
The pith
Contrastive prompting gives the most reliable gains for natural language inference in Swahili, Yoruba, and Hausa.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Contrastive prompting is the most reliable and steadily improving strategy across languages and models; it maintains better balance across answer classes and overall accuracy gains, and well-constructed prompts suffice to surpass baselines supplied with few-shot examples and chain-of-thought reasoning.
What carries the argument
Contrastive prompting, a prompt structure that presents options for explicit comparison during inference.
If this is right
- Prompt design can substitute for few-shot examples when performing inference on low-resource languages.
- Language-aware decision structuring improves robustness without requiring model fine-tuning.
- Neutral-class collapse can be reduced by changing how the prompt organizes possible answers.
- Performance ordering among prompt strategies holds across at least two different mid-sized models.
Where Pith is reading between the lines
- The same contrastive structure might transfer to other classification tasks beyond NLI in the same languages.
- Adding statistical controls or more models could clarify whether prompt effects remain dominant.
- The approach could be checked on languages outside the three studied to test broader applicability.
Load-bearing premise
Differences in results across the five prompt strategies come mainly from the wording of the prompts rather than from interactions with the two chosen models or the single benchmark dataset.
What would settle it
Repeating the five strategies on a third model or an additional African-language NLI dataset and finding no consistent advantage or better class balance for the contrastive version.
Figures

read the original abstract
Large language models (LLMs) are increasingly evaluated in multilingual settings, yet their inference behavior in low-resource African languages remains underexplored especially under pure prompting without fine-tuning. We present a systematic study of prompting strategies for Natural Language Inference (NLI) in Swahili, Yoruba, and Hausa using the AfriXNLI benchmark. We evaluate five prompting strategies Baseline (zero-shot), Script-Aware, Language Specific, Contrastive, and Native-Label Self-Translation (NL-STP) across two mid-sized open weight models (Llama3.2-3B and Gemma3-4B). To isolate the effect of prompt design, the effect of few-shot examples and Chain-of-Thought reasoning is eliminated in our study. We find a significant difference in performance of class wise across strategies with highly neutral class collapse and high prediction skew in some configurations. Contrastive prompting proves to be the most reliable and steadily improving strategy over language and model and has better balance of class behavior and balance of overall accuracy gains. Notably, well-constructed prompts are sufficient to beat more powerful baselines that are provided with few-shot prompts and Chain-of-Thought prompts. We have found that prompt formulation is essential to multilingual NLI with low-resource languages and that language aware decision structuring can be used to meaningfully enhance robustness in resource challenged settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates five prompting strategies (Baseline zero-shot, Script-Aware, Language Specific, Contrastive, and Native-Label Self-Translation) for NLI on the AfriXNLI benchmark in Swahili, Yoruba, and Hausa, using Llama3.2-3B and Gemma3-4B. Few-shot examples and Chain-of-Thought are eliminated internally to isolate prompt effects. It reports class-wise performance differences including neutral-class collapse and prediction skew in some setups, identifies Contrastive prompting as the most reliable strategy with steady improvement across languages/models and better class balance/accuracy gains, and claims that well-constructed prompts suffice to outperform more powerful few-shot/CoT baselines. The conclusion stresses the importance of prompt formulation for robustness in low-resource multilingual NLI.
Significance. If the attribution of gains to prompt design holds under expanded testing, the work would provide concrete evidence that targeted prompting can mitigate class imbalance and improve NLI reliability in African languages without fine-tuning, offering actionable guidance for low-resource multilingual settings and underscoring language-aware decision structuring as a low-cost robustness tool.
major comments (3)
- [Abstract] Abstract: the statement of a 'significant difference in performance of class wise across strategies' is unsupported because no quantitative metrics, error bars, sample sizes per language/model, or statistical significance tests are reported, leaving the magnitude and reliability of observed differences (including neutral collapse and skew) unquantified.
- [Abstract] Abstract and experimental setup: the central attribution that performance differences (class balance, accuracy gains, reliability across languages) can be attributed primarily to the five prompting strategies is under-supported, as the study uses only two models and one benchmark without additional controls, ablations for model pretraining overlap, label skew, or statistical tests; the claim of 'steadily improving over language and model' therefore extrapolates from a narrow sample.
- [Abstract] Abstract: the claim that 'well-constructed prompts are sufficient to beat more powerful baselines that are provided with few-shot prompts and Chain-of-Thought prompts' requires explicit reporting of the external baseline numbers, models, and exact configurations used for comparison, since the internal experiments eliminate few-shot/CoT and the manuscript provides no side-by-side table or quantitative delta.
minor comments (2)
- The five strategy names are introduced without a dedicated table or section summarizing their exact prompt templates, making it hard to reproduce the 'well-constructed' variants.
- No mention of the total number of test instances per language or any handling of label distribution in AfriXNLI, which is relevant given the reported class-collapse issues.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below and have revised the manuscript to strengthen the claims where appropriate while maintaining accuracy to our experimental scope.
read point-by-point responses
-
Referee: [Abstract] Abstract: the statement of a 'significant difference in performance of class wise across strategies' is unsupported because no quantitative metrics, error bars, sample sizes per language/model, or statistical significance tests are reported, leaving the magnitude and reliability of observed differences (including neutral collapse and skew) unquantified.
Authors: We agree that 'significant' implies statistical testing not performed in the study. In the revised version we have changed the phrasing to 'notable differences in class-wise performance' and added explicit per-class accuracy numbers, sample sizes from AfriXNLI (approximately 2,000 examples per language), and error bars on the relevant figures in the results section. revision: yes
-
Referee: [Abstract] Abstract and experimental setup: the central attribution that performance differences (class balance, accuracy gains, reliability across languages) can be attributed primarily to the five prompting strategies is under-supported, as the study uses only two models and one benchmark without additional controls, ablations for model pretraining overlap, label skew, or statistical tests; the claim of 'steadily improving over language and model' therefore extrapolates from a narrow sample.
Authors: We acknowledge the limited scope (two models, three languages, single benchmark) and have added an explicit limitations paragraph noting that broader validation is required. Within the controlled setting that isolates prompt design by removing few-shot and CoT, the observed trends remain consistent; we have revised the abstract wording to 'demonstrates consistent improvement across the three evaluated languages and two models' and included additional discussion of label distribution in AfriXNLI. revision: partial
-
Referee: [Abstract] Abstract: the claim that 'well-constructed prompts are sufficient to beat more powerful baselines that are provided with few-shot prompts and Chain-of-Thought prompts' requires explicit reporting of the external baseline numbers, models, and exact configurations used for comparison, since the internal experiments eliminate few-shot/CoT and the manuscript provides no side-by-side table or quantitative delta.
Authors: The manuscript references external few-shot and CoT results from the AfriXNLI benchmark paper, but we accept that a direct side-by-side comparison is missing. We have added a new table in the results section that reports the exact baseline numbers, model sizes, and configurations from the cited works alongside our contrastive-prompt results with quantitative deltas. revision: yes
Circularity Check
No circularity: direct empirical comparison of prompting strategies
full rationale
The paper reports results from running five prompting strategies on two models and one benchmark (AfriXNLI). No equations, fitted parameters, derivations, or self-referential claims appear in the abstract or described methodology. Performance differences are presented as observations from model runs rather than predictions derived from prior results by the same authors. The central claim (contrastive prompting superiority) rests on experimental outcomes, not on any reduction to inputs by construction or load-bearing self-citation. This is a standard empirical evaluation with no detectable circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introduction Largelanguagemodels(LLMs)haveshownhighef- ficiency in performing most natural language under- standing tasks, however, their performance in low- resource multilingual conditions has been under- characterized. Specifically, Natural Language Infer- ence (NLI) is one of the fundamental tasks that can beusedtoassessreasoningandsemanticcompre- hen...
Pith/arXiv arXiv 2024
-
[2]
Related Work 2.1. African Language Benchmarks and Multilingual Evaluation Recent large-scale evaluation efforts have high- lighted persistent performance gaps between African languages and high-resource languages in large language models. IrokoBench (Adelani et al., 2025) presents assessment suites includ- ing AfriXNLI, AfriMGSM and AfriMMLU across 17 Afr...
2025
-
[3]
and AfriTeVa (Jude Ogundepo et al., 2023) in the situations where supervised data exists. While these benchmarks provide performance comparison in a broad way, they a small number of prompt templates do not systematically design the promptsuchasinstructionframing,labelsemantics, or cultural grounding. Consequently, the role of promptstructurehasbecomeanun...
2023
-
[4]
All strategies require the model to output exactly one English label (entailment, con- tradiction, or neutral) without explanations
Prompting Strategies We evaluate five zero-shot prompting strategies de- signed to systematically vary linguistic grounding anddecisionstructurewhilekeepingthetaskformu- lation constant. All strategies require the model to output exactly one English label (entailment, con- tradiction, or neutral) without explanations. Full prompt templates are provided in...
-
[5]
Dataset We evaluate our prompting strategies on the AfriXNLI benchmark, a multilingual Natural Lan- guage Inference (NLI) dataset covering several African languages
Experimental Setup 4.1. Dataset We evaluate our prompting strategies on the AfriXNLI benchmark, a multilingual Natural Lan- guage Inference (NLI) dataset covering several African languages. We are targeting three lan- guages; Swahili, Yoruba, and Hausa. in all lan- guages, the full test set of 600 examples (equally balanced by the three labels entailment,...
-
[6]
Metrics are reported on complete 600 example test split of each language
Results We evaluate five prompting strategies across three languages (Swahili, Yoruba, Hausa) and two mid sized open weight models (Llama3.2-3B and Gemma3-4B). Metrics are reported on complete 600 example test split of each language. The overall results are summarized in the Table 1 of Appendix, which reports accuracy and macro-F1 score values across all ...
-
[7]
Overall Performance In all languages and models, there are signifi- cant variations between performance based on prompt formulation
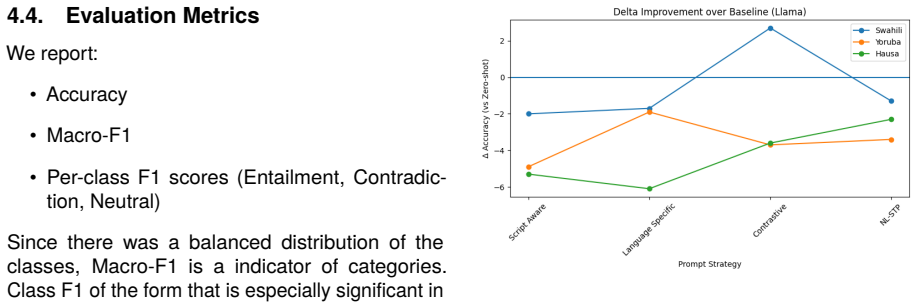
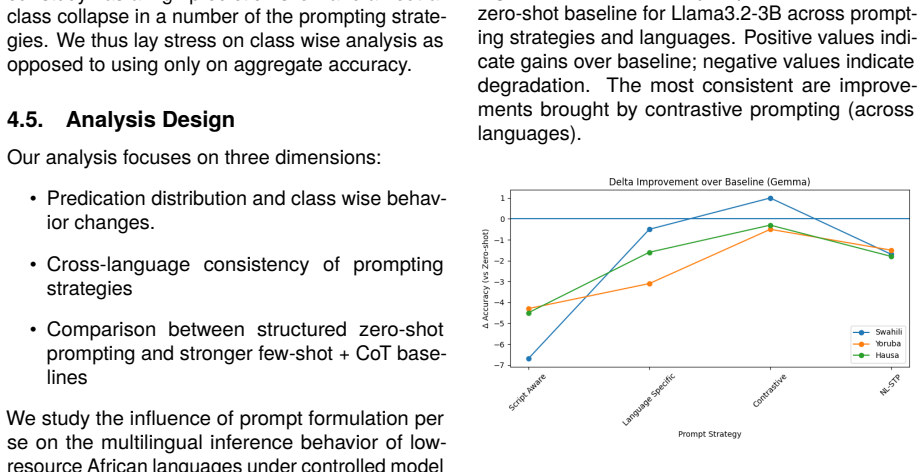
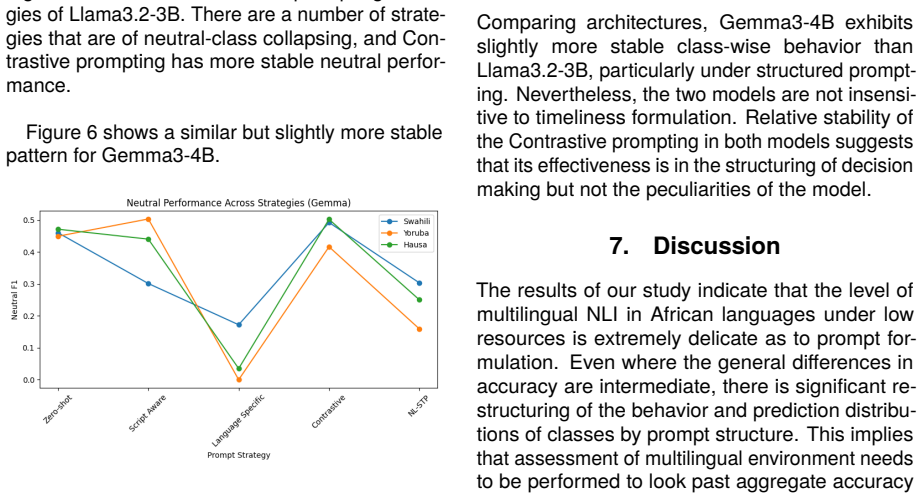
Analysis 6.1. Overall Performance In all languages and models, there are signifi- cant variations between performance based on prompt formulation. The zero-shot prompt base- line has a moderate level of accuracy, but contains Figure 1: Delta accuracy improvement over the zero-shot baseline for Llama3.2-3B across prompt- ing strategies and languages. Posit...
-
[8]
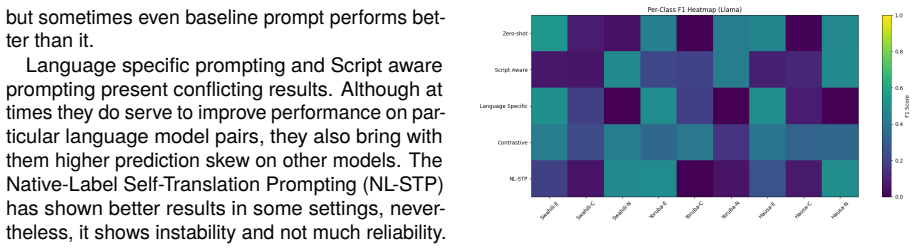
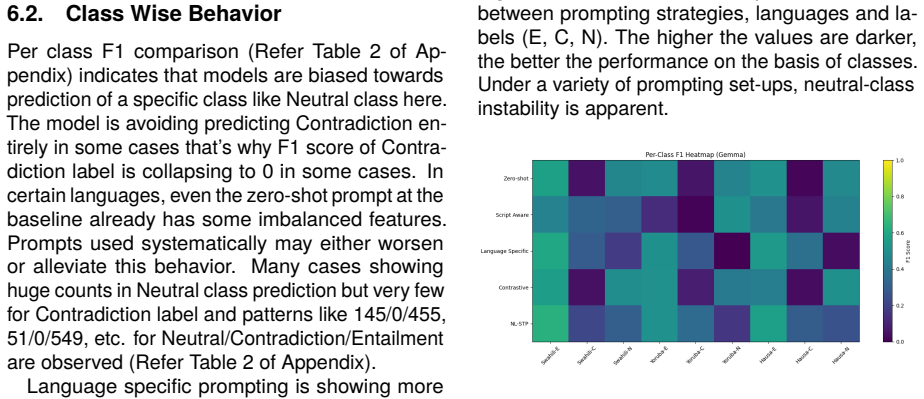
Even where the general differences in accuracy are intermediate, there is significant re- structuring of the behavior and prediction distribu- tions of classes by prompt structure
Discussion The results of our study indicate that the level of multilingual NLI in African languages under low resources is extremely delicate as to prompt for- mulation. Even where the general differences in accuracy are intermediate, there is significant re- structuring of the behavior and prediction distribu- tions of classes by prompt structure. This ...
-
[9]
Our results show that prompt design signif- icantly shapes class-wise behavior and prediction stability, even when overall accuracy differences are modest
Conclusion In AfriXNLI benchmark and with two open-weight models with middle size, we performed a system- atic survey of zero-shot prompting methods on Nat- ural Language Inference in Swahili, Yoruba, and Hausa. Our results show that prompt design signif- icantly shapes class-wise behavior and prediction stability, even when overall accuracy differences a...
-
[10]
The finding might not be generaliz- able to other low-resource languages
Ethical Considerations and Limitations • Low coverage of the languages: We only as- sess three African languages (Swahili, Yoruba, Hausa). The finding might not be generaliz- able to other low-resource languages. • Single benchmark: Experiments are done on the AfriXNLI only. It would be improved by testing other NLI data. • Model scale constraints: We use...
-
[11]
Bibliographical References David Ifeoluwa Adelani, Marek Masiak, Is- rael Abebe Azime, and Others. 2023. MasakhaNEWS: News topic classification for African languages. InProceedings of the 13th International Joint Conference on Natural Language Processing and the 3rd Conference of the Asia-Pacific Chapter of the Associa- tion for Computational Linguistics ...
2023
-
[12]
Reason as a native {lang} speaker would in daily conversation, not using formal logic
-
[13]
Consider what a typical speaker would naturally infer from the first sentence about the second
-
[14]
Decide the relationship based on common-sense and pragmatic understanding in {lang}
-
[16]
{premise}
Do NOT output explanations or any extra text. Decision rules (according to native {lang} usage): - entailment: a typical {lang} speaker would accept the second sentence as true because of the first. - contradiction: a typical {lang} speaker would judge the second sentence as incompatible with the first. - neutral: a typical {lang} speaker would find that ...
-
[17]
Consider each of the three possibilities below
-
[18]
Decide which one best matches the relationship between the sentences
-
[19]
Output exactly ONE English word: entailment, contradiction, or neutral
-
[20]
{premise}
Do NOT output explanations or any extra text. Interpretations: - entailment: the premise makes the hypothesis true. - contradiction: the premise makes the hypothesis false. - neutral: the premise neither guarantees nor contradicts the hypothesis. Premise: "{premise}" Hypothesis: "{hypothesis}" Which interpretation fits best? Answer: """ A.3. Native-Label ...
-
[21]
Do NOT output it
Internally transliterate the text into {lang} written in Latin script. Do NOT output it
-
[23]
{premise}
Output exactly ONE English word: entailment, contradiction, or neutral. Decision rules: - entailment: premise makes hypothesis true. - contradiction: premise makes hypothesis false. - neutral: neither true nor false. Premise (Ajami): "{premise}" Hypothesis (Ajami): "{hypothesis}" Answer: """ Latin Script Variant: PROMPT = """ You are a fluent {lang} speak...
-
[24]
Read and reason in {lang}
-
[25]
Decide the relationship
-
[26]
{premise}
Output exactly ONE English word: entailment, contradiction, or neutral. Decision rules: - entailment: premise makes hypothesis true. - contradiction: premise makes hypothesis false. - neutral: neither true nor false. Premise: "{premise}" Hypothesis: "{hypothesis}" Answer: """ B. Appendix - Full Results Strategy Lang Model Acc Macro-F1 Script Aware Sw Llam...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.