InfoMem: Training Long-Context Memory Agents with Answer-Conditioned Information Gain
Pith reviewed 2026-06-28 10:28 UTC · model grok-4.3
The pith
InfoMem improves long-context memory agents by using a reward that measures how much the final memory increases the likelihood of the ground-truth answer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
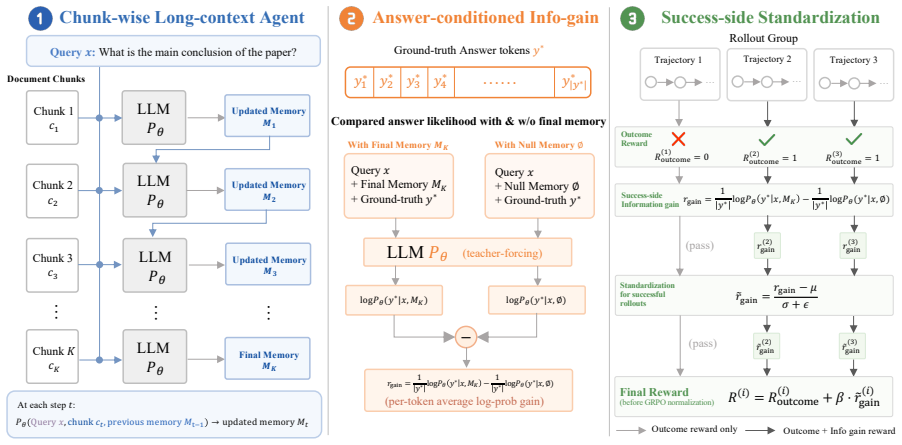
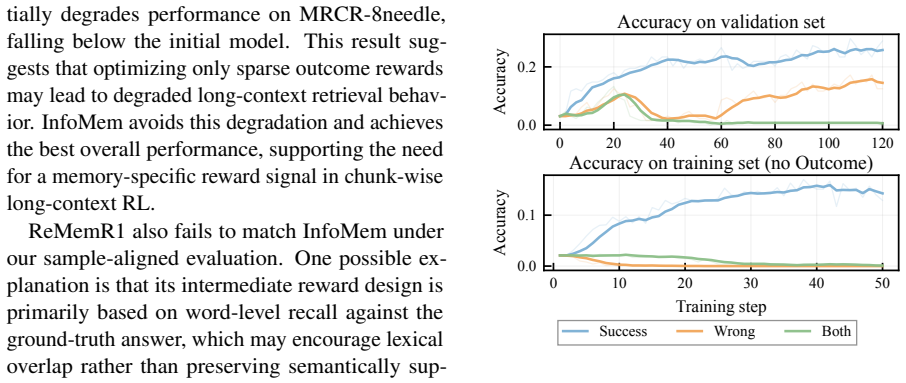
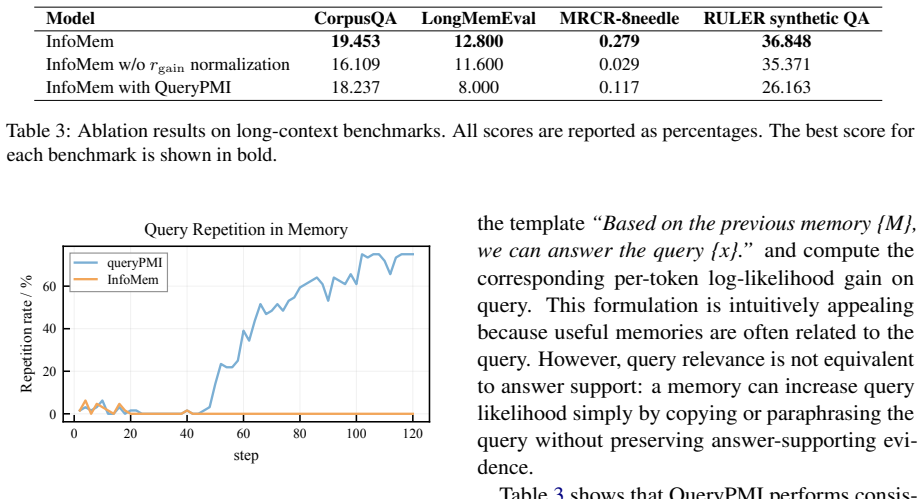
InfoMem quantifies final-memory utility as the increase in per-token log-likelihood of the ground-truth answer caused by the memory. The method applies this measure exclusively to successful trajectories and normalizes the resulting value before reward composition. Under identical GRPO training conditions and budget, agents trained with InfoMem outperform memory-agent RL baselines on long-context tasks.
What carries the argument
Answer-conditioned information gain, the measured increase in the model's per-token log-likelihood of the ground-truth answer attributable to the final memory.
If this is right
- Chunk-wise agents learn to preserve answer-relevant information more effectively across long documents.
- RL training for memory updates improves when the reward is conditioned on the answer rather than the query.
- Restricting the reward signal to successful trajectories and normalizing it before composition stabilizes optimization.
- Comparable performance gains are possible without changes to the underlying GRPO framework or added training compute.
Where Pith is reading between the lines
- The same reward structure could be tested in other sequential state-update settings where final outcome quality must guide intermediate decisions.
- Extending the approach beyond chunk-wise agents to alternative memory architectures might reveal broader applicability.
- Evaluating the method on additional long-context benchmarks outside the current experiments could identify task-specific patterns.
Load-bearing premise
The increase in per-token log-likelihood of the ground-truth answer due to the final memory is a reliable and superior signal for supervising memory updates.
What would settle it
Reproducing the experiments and observing no performance gain for InfoMem over the compared memory-agent RL baselines would falsify the central claim.
Figures

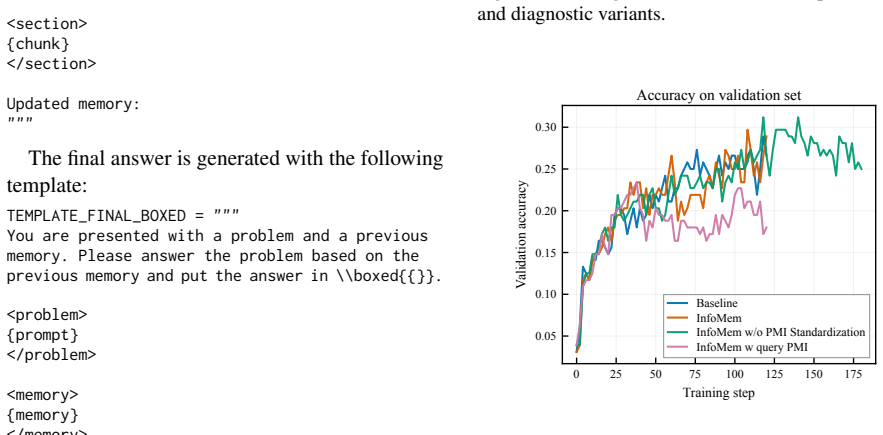
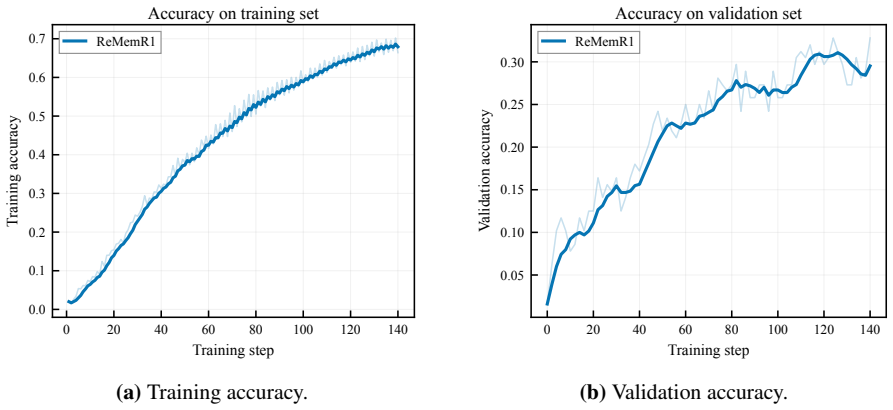
read the original abstract
Long-context tasks require LLMs to identify and preserve answer-relevant information from large contexts. Chunk-wise memory agents address this issue by sequentially reading document chunks, updating a compact memory, and generating the final answer from the accumulated memory. However, existing RL-based chunk-wise agents either rely on sparse final-answer rewards or use lexical intermediate rewards for memory and retrieval actions. These signals supervise task success or local overlap, but do not directly evaluate whether the final memory supports the ground-truth answer. We propose InfoMem, a reward mechanism for training chunk-wise memory agents that evaluates final-memory utility using answer-conditioned information. InfoMem measures how much the final memory increases the model's per-token log-likelihood of the ground-truth answer. To stabilize RL optimization, InfoMem applies this signal only to successful trajectories and normalizes it before reward composition. Under the same GRPO framework and training budget, InfoMem improves long-context memory-agent performance over comparable memory-agent RL baselines. Analyses show that effective final-memory rewards should operate on successful trajectories, be normalized before reward composition, and be conditioned on the answer rather than the query. Our code is available at https://github.com/GenSouKa1/InfoMem.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes InfoMem, a reward mechanism for training chunk-wise memory agents on long-context tasks via RL. InfoMem defines the reward as the increase in the model's per-token log-likelihood of the ground-truth answer attributable to the final memory (answer-conditioned information gain). The signal is restricted to successful trajectories, normalized before composition, and used within the GRPO framework. The paper claims performance gains over lexical-overlap and sparse final-answer reward baselines under matched training budgets, and provides analyses showing that effective rewards should operate on successful trajectories, be normalized, and be conditioned on the answer rather than the query. Code is released.
Significance. If the reported gains hold under the stated controls, the work supplies a more direct utility signal for memory updates than existing sparse or lexical alternatives, which could improve training of memory agents. The accompanying analyses on reward properties (successful trajectories, normalization, answer conditioning) offer reusable design guidance. Releasing code supports reproducibility and is a clear strength.
minor comments (3)
- Abstract: the performance claim would be strengthened by including at least one key quantitative result (e.g., accuracy delta or win rate) alongside the qualitative statement of improvement.
- Method section: the precise definition of the per-token log-likelihood difference (including how the 'attributable to final memory' term is isolated) should be given as an explicit equation for clarity and reproducibility.
- Experiments: confirm that all baselines use identical GRPO hyperparameters, context lengths, and success criteria so that the 'same training budget' comparison is unambiguous.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of InfoMem, including recognition of the performance gains, the analyses on reward properties (successful trajectories, normalization, and answer conditioning), and the value of releasing code. The recommendation for minor revision is noted, and we will incorporate any minor adjustments in the revised version.
Circularity Check
No significant circularity detected
full rationale
The paper defines InfoMem as an external reward signal computed from the increase in the model's per-token log-likelihood of a fixed ground-truth answer when the final memory is provided. This quantity is independent of the RL training loop itself, is restricted to successful trajectories, and is normalized before composition with other rewards. No derivation step reduces a claimed prediction or result to a fitted parameter, self-citation, or input by construction; the central performance claim is an empirical comparison under fixed GRPO budget against lexical and sparse-reward baselines. The design is self-contained against external benchmarks and contains no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption GRPO is an appropriate RL algorithm for training these agents
invented entities (1)
-
InfoMem reward signal
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2025 , eprint=
MemAgent: Reshaping Long-Context LLM with Multi-Conv RL-based Memory Agent , author=. 2025 , eprint=
2025
-
[2]
2026 , eprint=
When Does Divide and Conquer Work for Long Context LLM? A Noise Decomposition Framework , author=. 2026 , eprint=
2026
-
[3]
2026 , eprint=
Recursive Language Models , author=. 2026 , eprint=
2026
-
[4]
Zhao, Qingfei and Wang, Ruobing and Cen, Yukuo and Zha, Daren and Tan, Shicheng and Dong, Yuxiao and Tang, Jie. L ong RAG : A Dual-Perspective Retrieval-Augmented Generation Paradigm for Long-Context Question Answering. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.1259
-
[5]
2025 , eprint=
Demystifying Reasoning Dynamics with Mutual Information: Thinking Tokens are Information Peaks in LLM Reasoning , author=. 2025 , eprint=
2025
-
[6]
SQuAD: 100, 000+ Questions for Machine Comprehension of Text , booktitle =
Rajpurkar, Pranav and Zhang, Jian and Lopyrev, Konstantin and Liang, Percy. SQ u AD : 100,000+ Questions for Machine Comprehension of Text. Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. 2016. doi:10.18653/v1/D16-1264
-
[7]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[8]
2025 , eprint=
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models , author=. 2025 , eprint=
2025
-
[9]
Chen, Jianlyu and Xiao, Shitao and Zhang, Peitian and Luo, Kun and Lian, Defu and Liu, Zheng. M 3-Embedding: Multi-Linguality, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.137
-
[10]
2024 , month =
Wang, Liang and Yang, Nan and Huang, Xiaolong and Yang, Linjun and Majumder, Rangan and Wei, Furu , title =. 2024 , month =
2024
-
[11]
2024 , eprint=
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author=. 2024 , eprint=
2024
-
[12]
2026 , howpublished =
Gemini 3 Flash Preview , author =. 2026 , howpublished =
2026
-
[13]
RULER: What’s the Real Context Size of Your Long-Context Language Models? , author=
-
[14]
Cohen, Ruslan Salakhut- dinov, and Christopher D
Yang, Zhilin and Qi, Peng and Zhang, Saizheng and Bengio, Yoshua and Cohen, William and Salakhutdinov, Ruslan and Manning, Christopher D. H otpot QA : A Dataset for Diverse, Explainable Multi-hop Question Answering. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018. doi:10.18653/v1/D18-1259
-
[15]
2025 , howpublished =
OpenAI MRCR: Long Context Multiple Needle in a Haystack Benchmark , author =. 2025 , howpublished =
2025
-
[16]
2026 , eprint=
CorpusQA: A 10 Million Token Benchmark for Corpus-Level Analysis and Reasoning , author=. 2026 , eprint=
2026
-
[17]
LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory , author=
-
[18]
2026 , url =
Kimi K2.6: Advancing Open-Source Coding , author =. 2026 , url =
2026
-
[19]
2025 , eprint=
QwenLong-L1.5: Post-Training Recipe for Long-Context Reasoning and Memory Management , author=. 2025 , eprint=
2025
-
[20]
2024 , eprint=
Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention , author=. 2024 , eprint=
2024
-
[21]
Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation , author=
-
[22]
2024 , eprint=
MemGPT: Towards LLMs as Operating Systems , author=. 2024 , eprint=
2024
-
[23]
2025 , eprint=
MEM1: Learning to Synergize Memory and Reasoning for Efficient Long-Horizon Agents , author=. 2025 , eprint=
2025
-
[24]
International Conference on Machine Learning , pages=
A Human-Inspired Reading Agent with Gist Memory of Very Long Contexts , author=. International Conference on Machine Learning , pages=. 2024 , organization=
2024
-
[25]
Transformer- XL : Attentive Language Models beyond a Fixed-Length Context
Dai, Zihang and Yang, Zhilin and Yang, Yiming and Carbonell, Jaime and Le, Quoc and Salakhutdinov, Ruslan. Transformer- XL : Attentive Language Models beyond a Fixed-Length Context. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019. doi:10.18653/v1/P19-1285
-
[26]
Block-Recurrent Transformers , url =
Hutchins, DeLesley and Schlag, Imanol and Wu, Yuhuai and Dyer, Ethan and Neyshabur, Behnam , booktitle =. Block-Recurrent Transformers , url =
-
[27]
ERNIE-Doc: A retrospective long-document modeling transformer , author=. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , pages=
-
[28]
Nature , volume=
DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning , author=. Nature , volume=. 2025 , publisher=
2025
-
[29]
LongRLVR: Long-Context Reinforcement Learning Requires Verifiable Context Rewards , author=
-
[30]
2026 , eprint=
Evidence-Augmented Policy Optimization with Reward Co-Evolution for Long-Context Reasoning , author=. 2026 , eprint=
2026
-
[31]
2026 , eprint=
LongR: Unleashing Long-Context Reasoning via Reinforcement Learning with Dense Utility Rewards , author=. 2026 , eprint=
2026
-
[32]
2026 , eprint=
Look Back to Reason Forward: Revisitable Memory for Long-Context LLM Agents , author=. 2026 , eprint=
2026
-
[33]
Proceedings of the Twentieth European Conference on Computer Systems , pages=
Hybridflow: A flexible and efficient rlhf framework , author=. Proceedings of the Twentieth European Conference on Computer Systems , pages=
-
[34]
doi:10.5281/zenodo.12608602 , url =
Gao, Leo and Tow, Jonathan and Abbasi, Baber and Biderman, Stella and Black, Sid and DiPofi, Anthony and Foster, Charles and Golding, Laurence and Hsu, Jeffrey and Le Noac'h, Alain and Li, Haonan and McDonell, Kyle and Muennighoff, Niklas and Ociepa, Chris and Phang, Jason and Reynolds, Laria and Schoelkopf, Hailey and Skowron, Aviya and Sutawika, Lintang...
-
[35]
2026 , eprint=
GDPO: Group reward-Decoupled Normalization Policy Optimization for Multi-reward RL Optimization , author=. 2026 , eprint=
2026
-
[36]
Woosuk Kwon and Zhuohan Li and Siyuan Zhuang and Ying Sheng and Lianmin Zheng and Cody Hao Yu and Joseph Gonzalez and Hao Zhang and Ion Stoica , editor =. Efficient Memory Management for Large Language Model Serving with PagedAttention , booktitle =. 2023 , url =. doi:10.1145/3600006.3613165 , timestamp =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.