When Attention Collapses: Stage-Aware Visual Token Pruning from Structure to Semantics
Pith reviewed 2026-06-28 10:49 UTC · model grok-4.3
The pith
Vision-language models can avoid attention collapse in token pruning by first spreading tokens for structural coverage then filtering by semantic relevance to the prompt.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
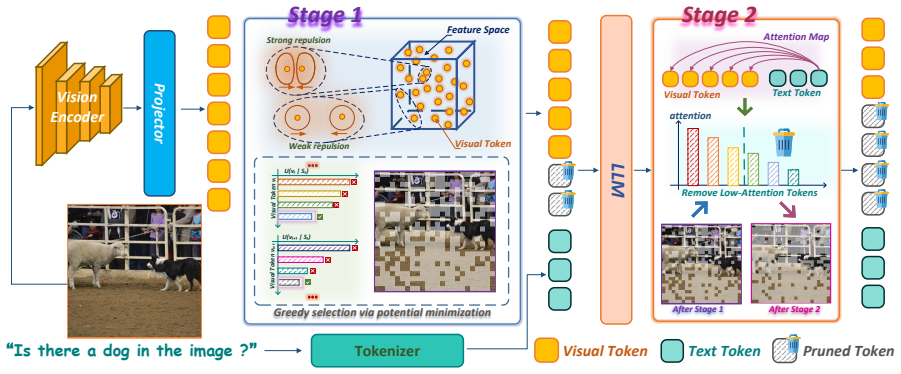
The paper claims that its Structure-to-Semantics framework, by decoupling pruning into a repulsion sampling stage for geometric coverage and an instruction-aware cross-attention stage for semantic relevance, addresses the flaw in single-metric attention pruning where scores collapse onto similar regions, thereby improving structural diversity and fine-grained task alignment of retained visual tokens.
What carries the argument
The two-stage Structure-to-Semantics (STS) framework, where repulsion-based sampling first maximizes spatial and structural diversity and instruction-aware cross-attention then removes prompt-irrelevant tokens.
If this is right
- Retained tokens cover a wider range of spatial positions and structural features than attention-only selection.
- Prompt-irrelevant visual content is removed more precisely in the second stage.
- Overall visual feature diversity rises, limiting the loss of contextual details that attention collapse causes.
- Fewer tokens can be kept while preserving or improving fine-grained performance on vision-language tasks.
Where Pith is reading between the lines
- The staged separation could be tested on other attention-based models that suffer from token redundancy.
- Diversity metrics measured after each stage separately would show whether the claimed synergy actually occurs.
- The repulsion step might be adapted to other sampling problems where uniform coverage is needed before relevance filtering.
Load-bearing premise
That single-metric attention pruning always collapses onto similar semantic regions and that the added repulsion and cross-attention steps fix the problem without creating new losses or extra cost.
What would settle it
A direct comparison on standard VLM benchmarks where the two-stage method shows no gain in token diversity metrics or downstream task accuracy over plain attention pruning.
Figures


read the original abstract
Vision-Language Models (VLMs) have demonstrated remarkable capabilities but suffer from significant computational overhead during inference. While visual token pruning offers a promising solution, existing methods predominantly rely on initial attention scores. This single-metric paradigm presents a critical flaw: high attention scores inherently collapse onto semantically similar regions, thereby severely reducing feature diversity and discarding vital contextual details. To address this, we introduce Structure-to-Semantics (STS), a novel two-stage visual token pruning framework that explicitly decouples the pruning process. The first stage employs a repulsion-based sampling mechanism to maximize spatial and structural diversity. The second stage leverages instruction-aware cross-attention to precisely filter out prompt-irrelevant tokens. This two-stage synergy constitutes the core of STS, first ensuring geometric coverage and then refining the retained tokens according to semantic relevance. Extensive evaluations demonstrate that STS mitigates the redundancy caused by attention-based selection, improving both structural diversity and fine-grained task alignment of the preserved visual tokens.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that attention-based visual token pruning in VLMs collapses onto semantically similar regions due to reliance on a single metric, reducing feature diversity and discarding contextual details. It introduces the Structure-to-Semantics (STS) two-stage framework: repulsion-based sampling in stage one to maximize spatial and structural diversity, followed by instruction-aware cross-attention in stage two to filter prompt-irrelevant tokens. The core claim is that this decoupling ensures geometric coverage before semantic refinement, mitigating redundancy and improving structural diversity and task alignment, as supported by extensive evaluations.
Significance. If the experimental results validate the two-stage synergy, the work could meaningfully advance efficient VLM inference by offering a principled alternative to single-metric pruning that better preserves both structural coverage and semantic relevance.
Simulated Author's Rebuttal
We thank the referee for the positive recommendation to accept and for the accurate summary of our contributions. No major comments were raised.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents STS as a novel algorithmic framework consisting of repulsion-based sampling followed by instruction-aware cross-attention. No equations, fitted parameters, or predictions are described that reduce to the inputs by construction. The central claim of two-stage synergy is introduced directly as a design choice targeting attention collapse, without self-definitional loops, load-bearing self-citations, or imported uniqueness theorems. The method is self-contained as an empirical proposal rather than a derived result.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Quan- tifying attention flow in transformers.Preprint, arXiv:2005.00928. Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, and 1 others
-
[2]
Qwen technical report.Preprint, arXiv:2309.16609. Daniel Bolya, Cheng-Yang Fu, Xiaoliang Dai, Peizhao Zhang, Christoph Feichtenhofer, and Judy Hoffman
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Token Merging: Your ViT But Faster
Token merging: Your vit but faster.arXiv preprint arXiv:2210.09461. Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, and 1 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin
Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901. Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin
1901
-
[5]
Emerging Properties in Self-Supervised Vision Transformers
Emerging properties in self-supervised vision transformers.Preprint, arXiv:2104.14294. Liang Chen, Haozhe Zhao, Tianyu Liu, Shuai Bai, Jun- yang Lin, Chang Zhou, and Baobao Chang. 2024a. An image is worth 1/2 tokens after layer 2: Plug-and- play inference acceleration for large vision-language models.Preprint, arXiv:2403.06764. Zhe Chen, Jiannan Wu, Wenha...
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Attention is not all you need: Pure attention loses rank doubly exponentially with depth. Preprint, arXiv:2103.03404. Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Nova DasSarma, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Andy Jones, Jackson Kern...
-
[7]
Https://transformer- circuits.pub/2021/framework/index.html
A mathemati- cal framework for transformer circuits.Trans- former Circuits Thread. Https://transformer- circuits.pub/2021/framework/index.html. Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, Yunsheng Wu, Rongrong Ji, Caifeng Shan, and Ran He
2021
-
[8]
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models
Mme: A compre- hensive evaluation benchmark for multimodal large language models.Preprint, arXiv:2306.13394. Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Making the V in VQA Matter: Elevating the Role of Image Understanding in Visual Question Answering
Making the v in vqa matter: Elevating the role of image under- standing in visual question answering.Preprint, arXiv:1612.00837. Danna Gurari, Qing Li, Abigale J. Stangl, Anhong Guo, Chi Lin, Kristen Grauman, Jiebo Luo, and Jeffrey P. Bigham
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Vizwiz grand challenge: Answer- ing visual questions from blind people.Preprint, arXiv:1802.08218. Drew A. Hudson and Christopher D. Manning
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
GQA: A New Dataset for Real-World Visual Reasoning and Compositional Question Answering
Gqa: A new dataset for real-world visual reason- ing and compositional question answering.Preprint, arXiv:1902.09506. Alex Kulesza and Ben Taskar
work page internal anchor Pith review Pith/arXiv arXiv 1902
-
[12]
Efficient Memory Management for Large Language Model Serving with PagedAttention
Ef- ficient memory management for large language model serving with pagedattention.Preprint, arXiv:2309.06180. Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Evaluating Object Hallucination in Large Vision-Language Models
Eval- uating object hallucination in large vision-language models.Preprint, arXiv:2305.10355. James Liang, Tianfei Zhou, Dongfang Liu, and Wen- guan Wang
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Youwei Liang, Chongjian Ge, Zhan Tong, Yibing Song, Jue Wang, and Pengtao Xie
Clustseg: Clustering for universal segmentation.Preprint, arXiv:2305.02187. Youwei Liang, Chongjian Ge, Zhan Tong, Yibing Song, Jue Wang, and Pengtao Xie
-
[15]
arXiv preprint arXiv:2202.07800 (2022) 4
Not all patches are what you need: Expediting vision transformers via token reorganizations.Preprint, arXiv:2202.07800. Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, and Li Yuan
-
[16]
Video-LLaVA: Learning United Visual Representation by Alignment Before Projection
Video-llava: Learn- ing united visual representation by alignment before projection.Preprint, arXiv:2311.10122. Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. 2024a. Improved baselines with visual instruc- tion tuning.Preprint, arXiv:2310.03744. Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. 2024b. Llava- ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Learn to explain: Multimodal reasoning via thought chains for science question answering, 2022
Learn to explain: Multimodal reasoning via thought chains for science question answering.Preprint, arXiv:2209.09513. Xin Men, Mingyu Xu, Qingyu Zhang, Bingning Wang, Hongyu Lin, Yaojie Lu, Xianpei Han, and Weipeng Chen
-
[18]
Shortgpt: Layers in large language mod- els are more redundant than you expect.Preprint, arXiv:2403.03853. Reiner Pope, Sholto Douglas, Aakanksha Chowdhery, Jacob Devlin, James Bradbury, Jonathan Heek, Kefan Xiao, Shivani Agrawal, and Jeff Dean
-
[19]
Towards VQA Models That Can Read
Towards vqa models that can read.Preprint, arXiv:1904.08920. Jiaming Tang, Yilong Zhao, Kan Zhu, Guangxuan Xiao, Baris Kasikci, and Song Han
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[20]
Quest: Query-Aware Sparsity for Efficient Long-Context LLM Inference
Quest: Query- aware sparsity for efficient long-context llm inference. Preprint, arXiv:2406.10774. Yi Tay, Mostafa Dehghani, Dara Bahri, and Donald Metzler
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Efficient transformers: A survey. Preprint, arXiv:2009.06732. Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean- Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Mil- lican, and 1 others
-
[22]
Gemini: A Family of Highly Capable Multimodal Models
Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805. Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned
Analyzing multi-head self-attention: Specialized heads do the heavy lifting, the rest can be pruned.Preprint, arXiv:1905.09418. Hanrui Wang, Zhekai Zhang, and Song Han
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[24]
arXiv preprint arXiv:2502.11494 (2025) 4, 10
Stop looking for important tokens in multimodal language models: Duplication matters more.Preprint, arXiv:2502.11494. Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis
-
[25]
PyramidDrop: Accelerating Your Large Vision-Language Models via Pyramid Visual Redundancy Reduction
Pyra- middrop: Accelerating your large vision-language models via pyramid visual redundancy reduction. Preprint, arXiv:2410.17247. Ruyi Xu, Yuan Yao, Zonghao Guo, Junbo Cui, Zan- lin Ni, Chunjiang Ge, Tat-Seng Chua, Zhiyuan Liu, Maosong Sun, and Gao Huang
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Senqiao Yang, Yukang Chen, Zhuotao Tian, Chengyao Wang, Jingyao Li, Bei Yu, and Jiaya Jia
Llava-uhd: an lmm perceiving any aspect ratio and high-resolution images.Preprint, arXiv:2403.11703. Senqiao Yang, Yukang Chen, Zhuotao Tian, Chengyao Wang, Jingyao Li, Bei Yu, and Jiaya Jia
-
[27]
Hongxu Yin, Arash Vahdat, Jose Alvarez, Arun Mallya, Jan Kautz, and Pavlo Molchanov
Vi- sionzip: Longer is better but not necessary in vision language models.Preprint, arXiv:2412.04467. Hongxu Yin, Arash Vahdat, Jose Alvarez, Arun Mallya, Jan Kautz, and Pavlo Molchanov
-
[28]
Adavit: Adaptive tokens for efficient vision transformer. Preprint, arXiv:2112.07658. Kai Zhang, Xingyu Chen, and Xiaofeng Zhang. 2025a. Adatoken-3d: Dynamic spatial gating for efficient 3d large multimodal-models reasoning. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 16702–16709. Qizhe Zhang, Aosong Cheng, Min...
-
[29]
H$_2$O: Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models
H2o: Heavy-hitter ora- cle for efficient generative inference of large language models.Preprint, arXiv:2306.14048. Qiyan Zhao, Xiaofeng Zhang, Yiheng Li, Yun Xing, Xiaosong Yuan, Feilong Tang, Sinan Fan, Xuhang Chen, Xuyao Zhang, and Dahan Wang
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Mca- llava: Manhattan causal attention for reducing hallu- cination in large vision-language models.Preprint, arXiv:2507.09184. Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, Zhangwei Gao, Erfei Cui, Xue- hui Wang, Yue Cao, Yangzhou Liu, Xingguang Wei, Hongjie Zhang, Haomin Wang, Weiye ...
-
[31]
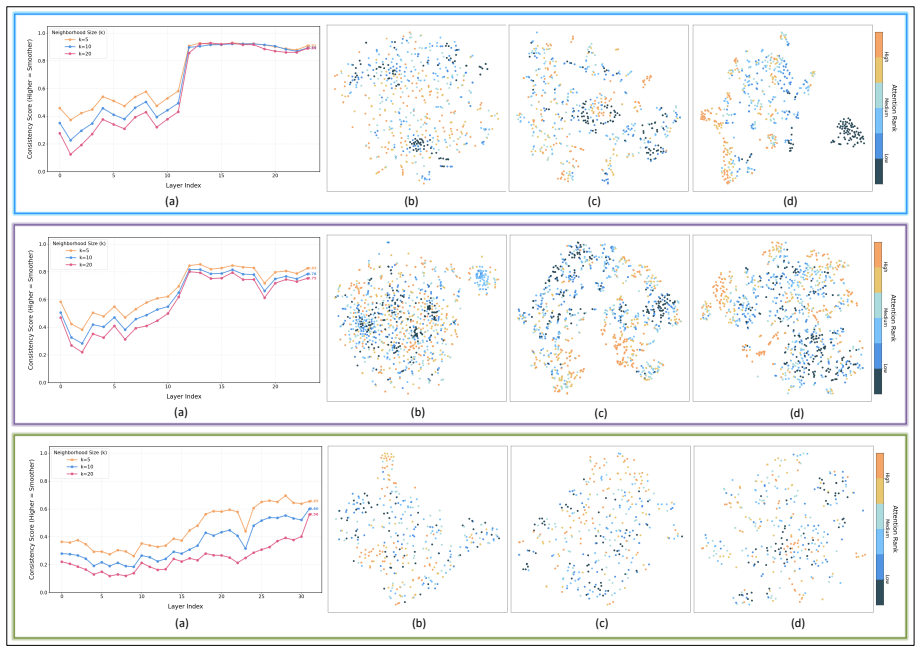
Internvl3: Exploring advanced train- ing and test-time recipes for open-source multimodal models.Preprint, arXiv:2504.10479. Appendix A Additional Analysis and Algorithm Details A.1 Background and Rationale K-nearest neighbors (KNN) is used in this work not as a classifier, but as a diagnostic tool for probing the local geometry of visual token representa...
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
:This model adopts a native multimodal pre-training paradigm within a ViT-MLP-LLM framework, acquiring lin- guistic and multimodal capabilities simultaneously. By incorporating Variable Visual Position Encod- ing, InternVL3 demonstrates superior performance in handling extended contexts and specialized tasks such as industrial image analysis and 3D percep...
2023
-
[33]
TextVQA targets the interpretation of textual information embedded within visual scenes. It demands that models not only perceive visual content but also detect, read, and reason about text in images to answer questions accurately, thereby evaluating integrated optical Method GQA MMB MME POPE SQA VQA v2 VQAText VizWiz Avg. LLaV A-1.5-13B Upper Bound (100%...
2018
-
[34]
These tokens are largely unrelated to the textual prompt, indicating a potential attention bias that wastes the limited token budget and can negatively affect the final prediction
We observe that when pruning relies solely on LLM attention scores, the selected tokens tend to concentrate in the lower- right region of the image (Zhao et al., 2025; Zhang et al., 2024a). These tokens are largely unrelated to the textual prompt, indicating a potential attention bias that wastes the limited token budget and can negatively affect the fina...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.