The Shape of Addition: Geometric Structures of Arithmetic in Large Language Models
Pith reviewed 2026-06-28 23:42 UTC · model grok-4.3
The pith
Large language models represent multi-operand addition as an Iso-Raw-Sum Trajectory in residual streams, anchored by semantic digits and modulated by continuous carry fibers, with errors as geometric slippages from noisy quantization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
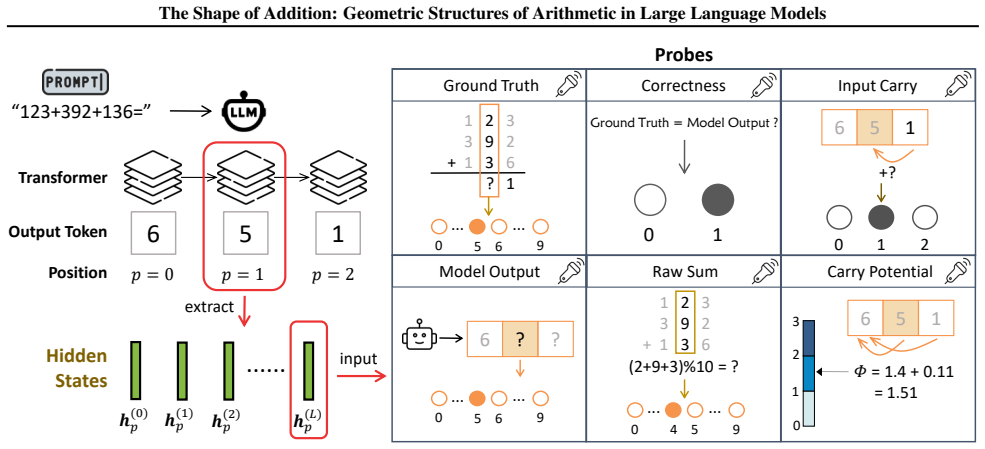
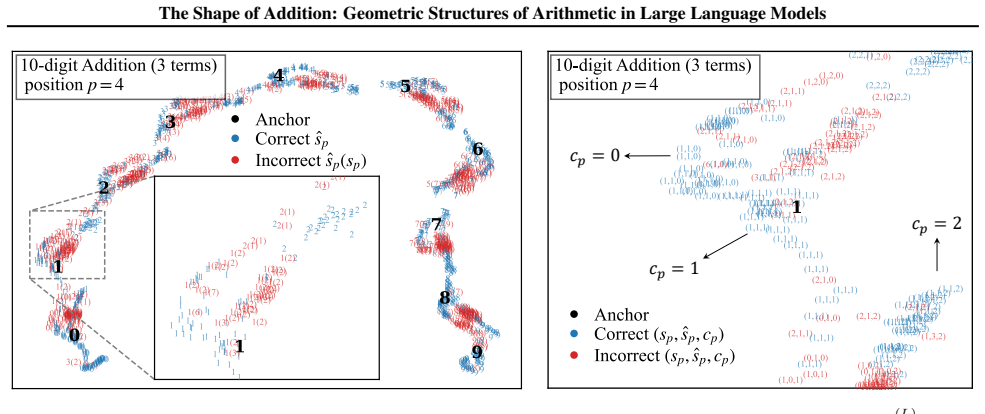
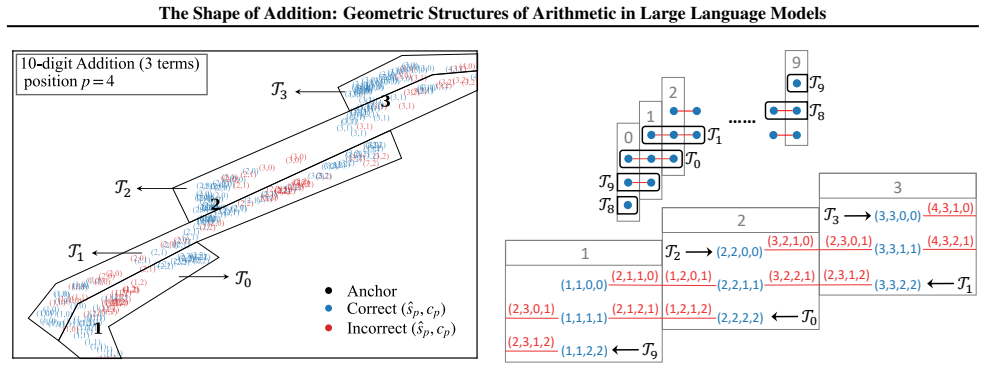
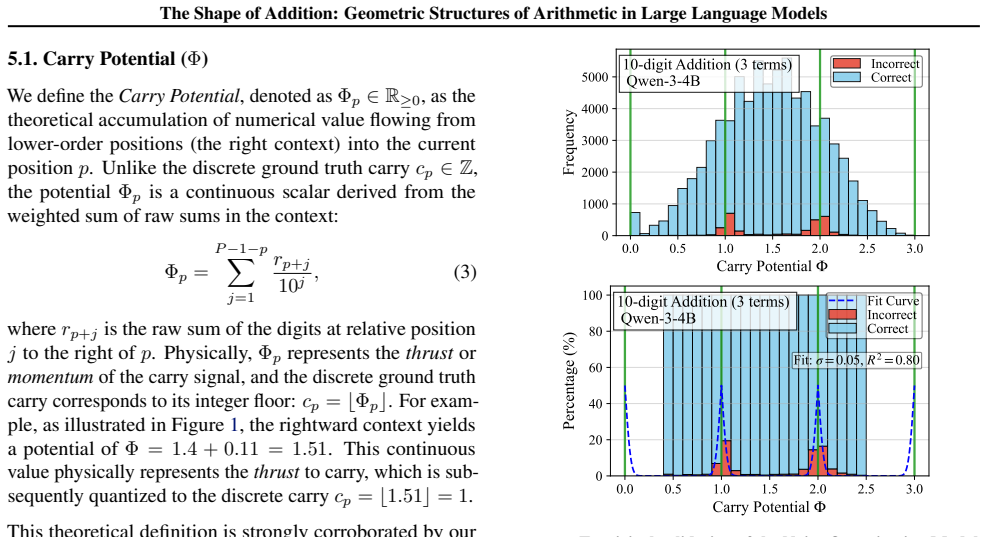
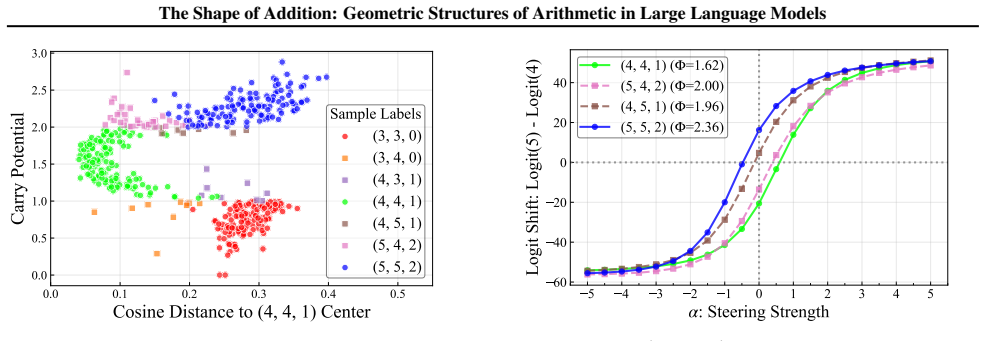
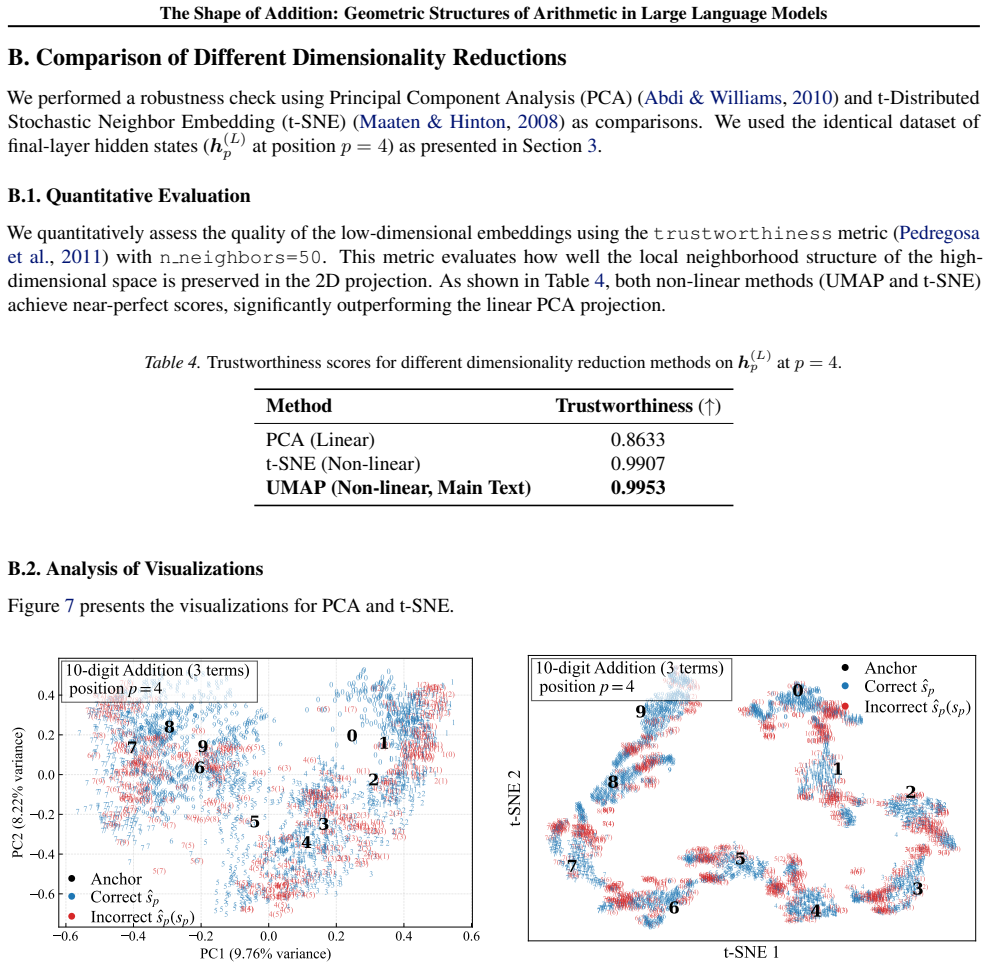
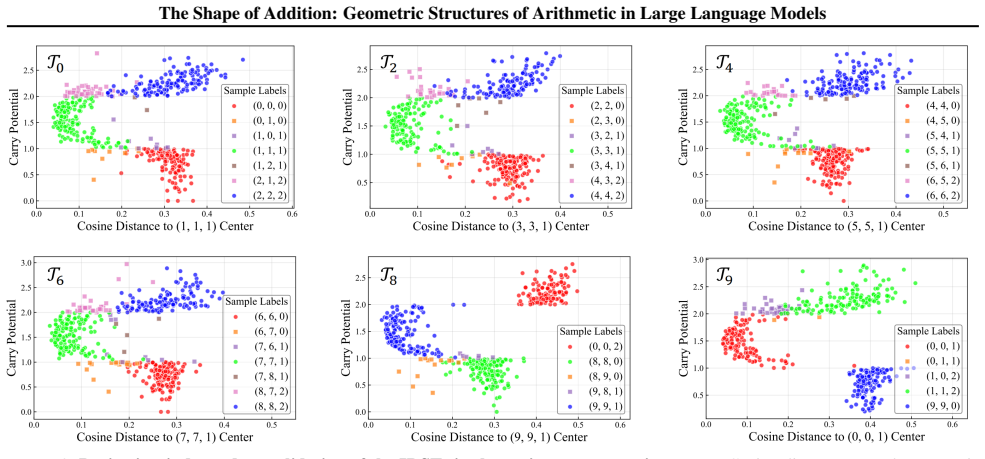
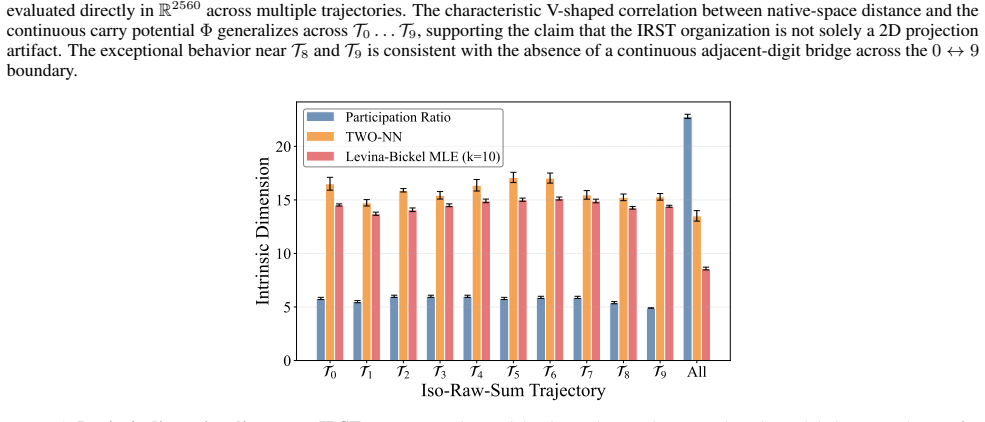
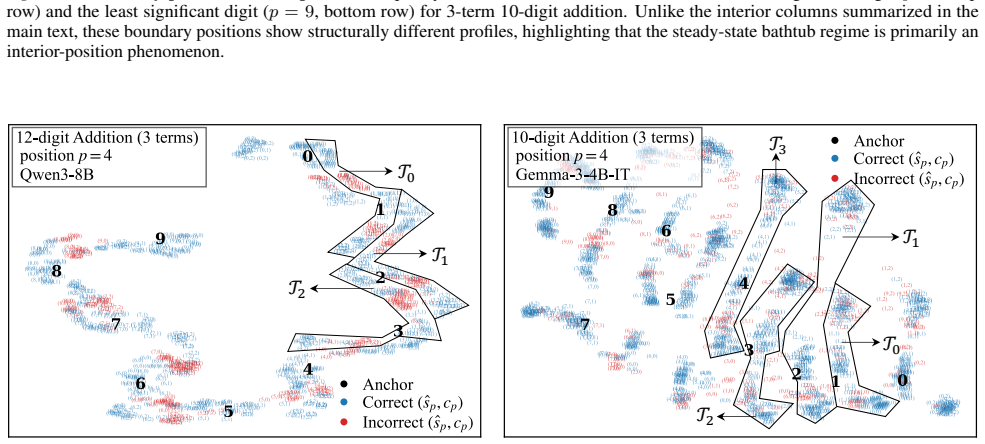
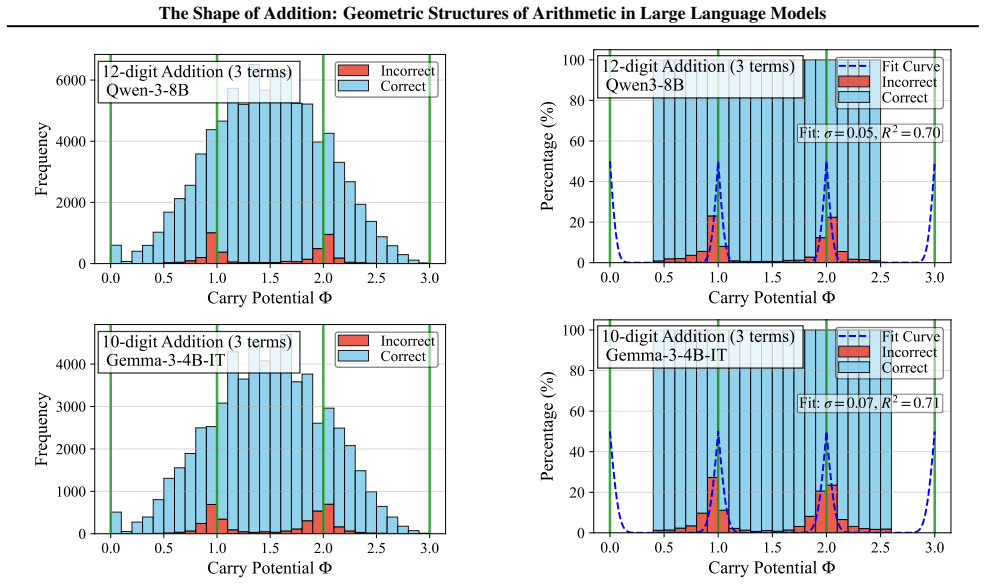
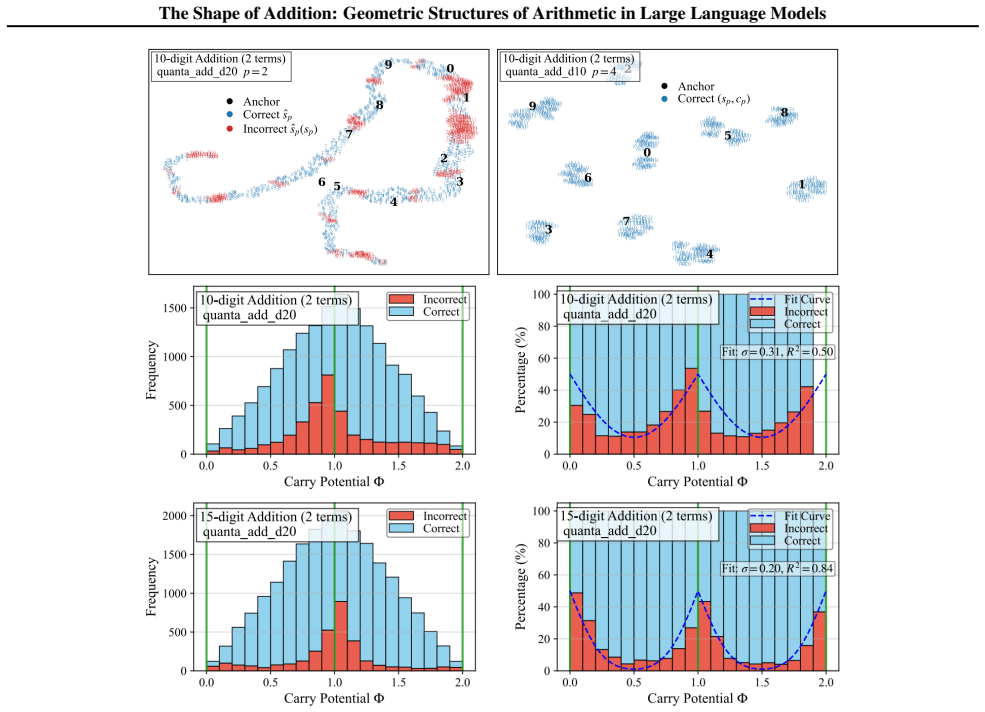
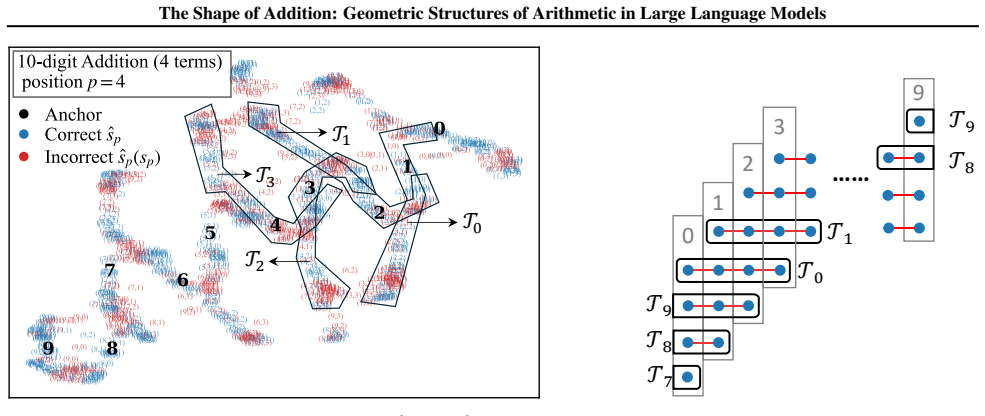
By analyzing the residual stream geometry during multi-operand addition, the authors identify the Iso-Raw-Sum Trajectory (IRST), a geometric structure where representations are anchored by semantic digits and modulated by continuous carry fibers. They propose the Noisy Quantization Model to explain this geometry, framing arithmetic errors as Geometric Slippages caused by internal neural noise pushing a continuous, latent Carry Potential across quantization thresholds. This geometric framework elucidates Probe Versatility, explaining how lightweight probes can disentangle coexisting latent signals from a single activation vector, and validates the insights through a geometric consistency chec
What carries the argument
The Iso-Raw-Sum Trajectory (IRST), a geometric structure in the residual stream where representations are anchored by semantic digits and modulated by continuous carry fibers, together with the Noisy Quantization Model that attributes errors to noise-driven crossings of quantization thresholds.
Load-bearing premise
The observed trajectories and error patterns are produced by a continuous carry potential that is quantized at discrete thresholds rather than by other mechanisms such as attention patterns, token embeddings, or training data statistics.
What would settle it
An experiment that clamps or suppresses the continuous carry dimension in the residual stream during addition and checks whether the specific patterns of geometric slippage errors disappear; persistence of those error patterns would falsify the model.
Figures
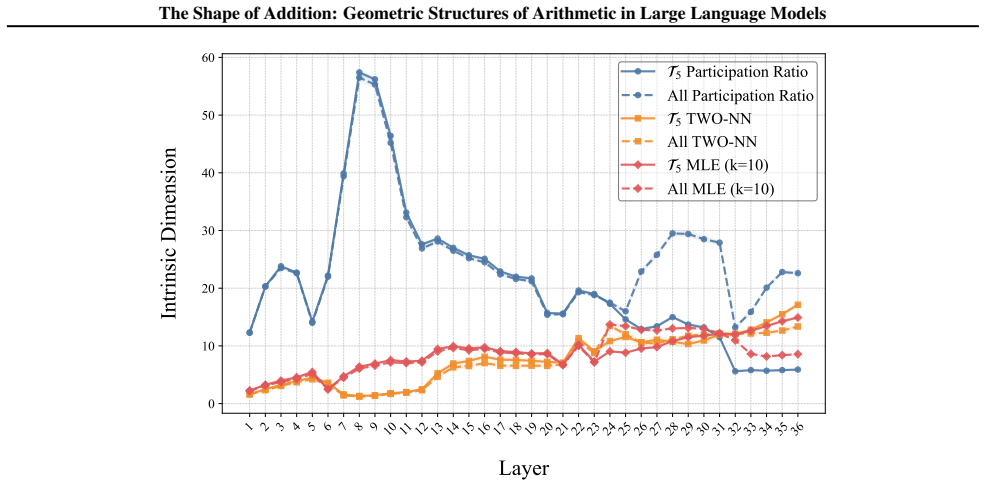
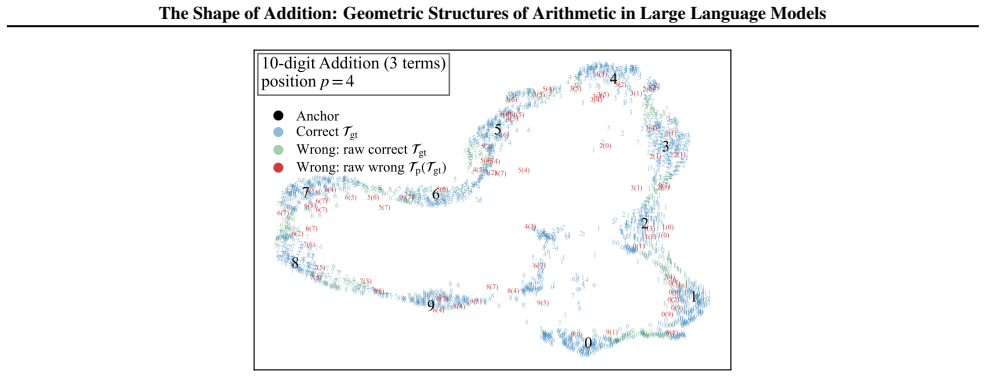
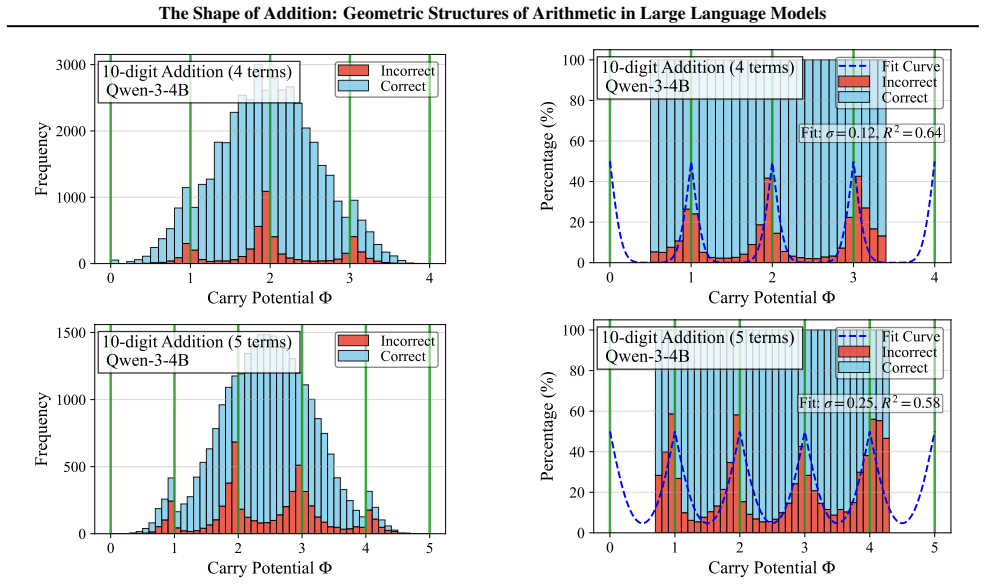
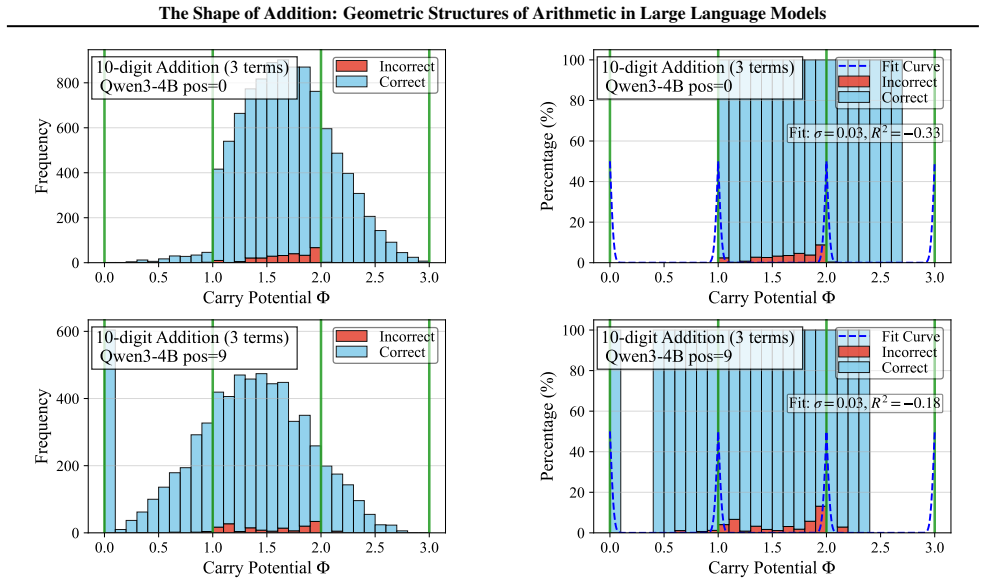
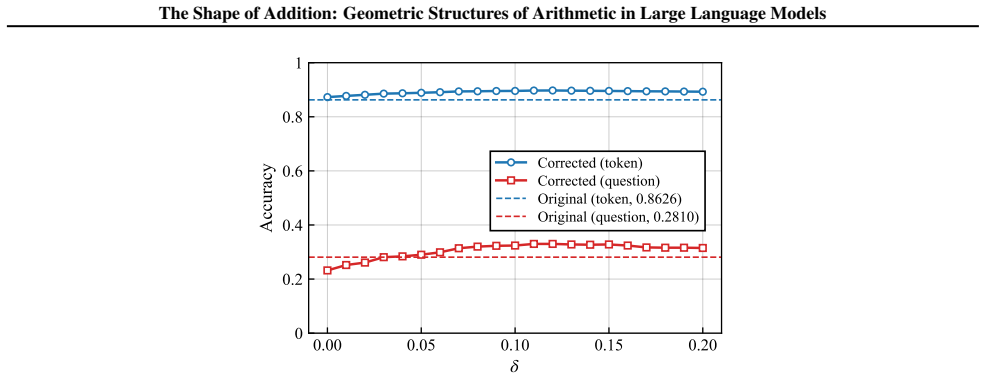
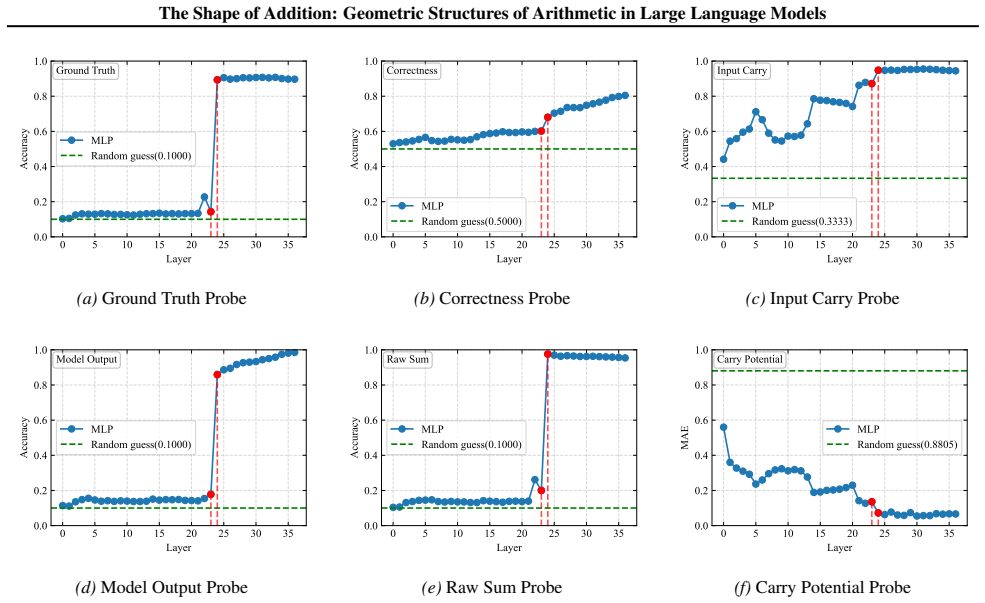
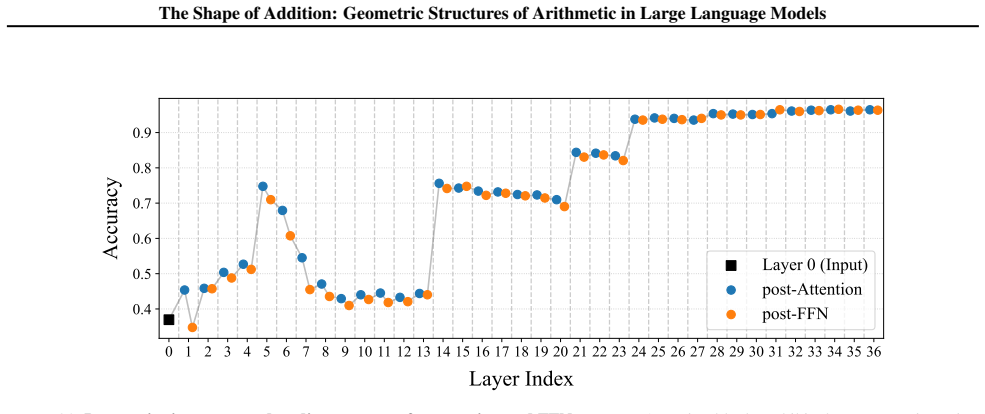

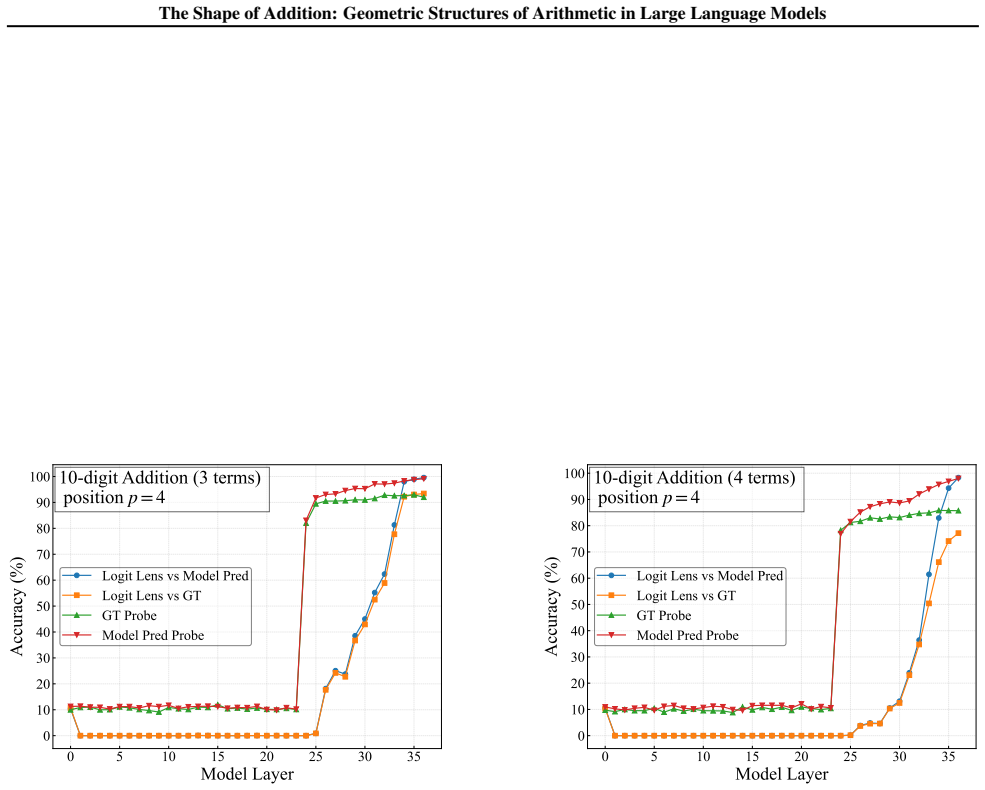
read the original abstract
Large Language Models exhibit paradoxical fragility in fundamental arithmetic, implying a disconnect between internal computation and discrete output. By analyzing the residual stream geometry during multi-operand addition, we identify the Iso-Raw-Sum Trajectory (IRST), a geometric structure where representations are anchored by semantic digits and modulated by continuous carry fibers. We propose the Noisy Quantization Model to explain this geometry, framing arithmetic errors as Geometric Slippages caused by internal neural noise pushing a continuous, latent Carry Potential across quantization thresholds. This geometric framework further elucidates Probe Versatility, explaining how lightweight probes can disentangle coexisting latent signals (such as ground truth versus hallucination) from a single activation vector. Finally, we validate these insights through a geometric consistency check method that effectively detects and corrects these quantization failures during inference. Our code is available at https://github.com/RL-MIND/Shape-of-Addition.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes residual stream geometry in LLMs during multi-operand addition tasks. It identifies an Iso-Raw-Sum Trajectory (IRST) in which representations are anchored by semantic digits and modulated by continuous carry fibers. The authors propose a Noisy Quantization Model that attributes arithmetic errors to geometric slippages arising when internal neural noise drives a latent continuous Carry Potential across discrete quantization thresholds. The framework is also used to explain probe versatility for disentangling coexisting signals (e.g., ground truth vs. hallucination) and is validated via a geometric consistency check that detects and corrects quantization failures at inference time. Code is released.
Significance. If the IRST geometry and the attribution of errors specifically to a continuous Carry Potential quantized at thresholds can be substantiated, the work would offer a mechanistic account of arithmetic fragility in LLMs and a practical inference-time correction method. The public code release is a clear strength that supports reproducibility and further testing of the geometric claims.
major comments (2)
- [Abstract] Abstract and introduction: the central claim that arithmetic errors arise from geometric slippages of a continuous latent Carry Potential across quantization thresholds is not accompanied by described controls or ablation experiments that would distinguish this mechanism from alternatives such as discrete attention patterns, token embedding statistics, or training-data regularities. Without such disambiguation the attribution remains unsecured.
- [Abstract] Abstract: the validation of the Noisy Quantization Model and the geometric consistency check is described only at a high level; no quantitative metrics, error bars, or statistical tests are mentioned that would allow assessment of whether the observed trajectories and error patterns are better explained by the proposed model than by simpler alternatives.
minor comments (1)
- [Abstract] The abstract introduces several new terms (IRST, Noisy Quantization Model, Carry Potential, Geometric Slippages) without immediate definitions or pointers to the sections where they are formalized.
Simulated Author's Rebuttal
Thank you for your constructive feedback. We value the emphasis on rigorous disambiguation of mechanisms and quantitative validation of the Noisy Quantization Model. We will revise the manuscript to incorporate explicit controls, ablations, and quantitative metrics as outlined below. These additions will strengthen the attribution of errors to geometric slippages of the continuous Carry Potential while preserving the core geometric findings on the IRST.
read point-by-point responses
-
Referee: [Abstract] Abstract and introduction: the central claim that arithmetic errors arise from geometric slippages of a continuous latent Carry Potential across quantization thresholds is not accompanied by described controls or ablation experiments that would distinguish this mechanism from alternatives such as discrete attention patterns, token embedding statistics, or training-data regularities. Without such disambiguation the attribution remains unsecured.
Authors: We agree that the abstract does not detail explicit controls. The manuscript's geometric consistency check functions as an implicit disambiguation by demonstrating that interventions aligned with the continuous carry dimension correct errors in a manner not predicted by discrete attention patterns or static embedding statistics. However, to directly address the concern, the revision will add a dedicated ablation section comparing the Noisy Quantization Model against alternatives, including attention-head ablations and training-data regularity baselines, with quantitative error-prediction comparisons. revision: yes
-
Referee: [Abstract] Abstract: the validation of the Noisy Quantization Model and the geometric consistency check is described only at a high level; no quantitative metrics, error bars, or statistical tests are mentioned that would allow assessment of whether the observed trajectories and error patterns are better explained by the proposed model than by simpler alternatives.
Authors: The current manuscript emphasizes qualitative trajectory visualizations and the functional success of the consistency check. We acknowledge the absence of explicit quantitative metrics in the abstract and high-level description. The revision will add quantitative results, including detection accuracy with error bars across multiple seeds, statistical significance tests against baseline models, and tables comparing slippage prediction performance to simpler alternatives. revision: yes
Circularity Check
No circularity in observational geometry analysis
full rationale
The paper presents observational analysis of residual stream geometry during addition, identifying structures such as the Iso-Raw-Sum Trajectory and proposing the Noisy Quantization Model to frame errors as geometric slippages. No load-bearing derivations, equations, or results are shown to reduce by construction to fitted inputs, self-citations, or self-definitional loops. The central claims remain descriptive and model-proposing without the enumerated circular patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Residual stream activations during addition contain linearly readable semantic and carry information
invented entities (3)
-
Iso-Raw-Sum Trajectory (IRST)
no independent evidence
-
Noisy Quantization Model
no independent evidence
-
Carry Potential
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 31st International Conference on Computational Linguistics , pages=
Language models encode the value of numbers linearly , author=. Proceedings of the 31st International Conference on Computational Linguistics , pages=
-
[2]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Probing for arithmetic errors in language models , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[3]
arXiv preprint arXiv:2510.05969 , year=
Probing the Difficulty Perception Mechanism of Large Language Models , author=. arXiv preprint arXiv:2510.05969 , year=
-
[4]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2) , year=
Measuring Mathematical Problem Solving With the MATH Dataset , author=. Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2) , year=
-
[6]
Tokenization counts: the impact of tokenization on arithmetic in frontier llms , author=. arXiv preprint arXiv:2402.14903 , year=
-
[7]
The Eleventh International Conference on Learning Representations , year=
Progress measures for grokking via mechanistic interpretability , author=. The Eleventh International Conference on Learning Representations , year=
-
[8]
arXiv preprint arXiv:2502.19981 , year=
The lookahead limitation: Why multi-operand addition is hard for llms , author=. arXiv preprint arXiv:2502.19981 , year=
-
[9]
arXiv preprint arXiv:2407.15360 , year=
Dissecting Multiplication in Transformers: Insights into LLMs , author=. arXiv preprint arXiv:2407.15360 , year=
-
[10]
The Twelfth International Conference on Learning Representations , year=
Understanding Addition in Transformers , author=. The Twelfth International Conference on Learning Representations , year=
-
[11]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops , pages=
The riemannian geometry of deep generative models , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops , pages=
-
[12]
Journal of Machine Learning Research , volume=
Topology of deep neural networks , author=. Journal of Machine Learning Research , volume=
-
[13]
ICML 2025 Workshop on Reliable and Responsible Foundation Models , year=
The Geometries of Truth Are Orthogonal Across Tasks , author=. ICML 2025 Workshop on Reliable and Responsible Foundation Models , year=
2025
-
[14]
NeurIPS 2024 Workshop on Symmetry and Geometry in Neural Representations , year=
Hidden Holes-topological aspects of language models , author=. NeurIPS 2024 Workshop on Symmetry and Geometry in Neural Representations , year=
2024
-
[15]
arXiv preprint arXiv:2402.02619v10 , year=
Understanding Addition and Subtraction in Transformers , author=. arXiv preprint arXiv:2402.02619v10 , year=
-
[16]
arXiv preprint arXiv:2506.07824 , year=
Addition in Four Movements: Mapping Layer-wise Information Trajectories in LLMs , author=. arXiv preprint arXiv:2506.07824 , year=
-
[17]
ICLR 2025 Workshop on Building Trust in Language Models and Applications , year=
Language Models Use Trigonometry to Do Addition , author=. ICLR 2025 Workshop on Building Trust in Language Models and Applications , year=
2025
-
[18]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
Umap: Uniform manifold approximation and projection for dimension reduction , author=. arXiv preprint arXiv:1802.03426 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
arXiv preprint arXiv:2411.04430 , year=
Towards unifying interpretability and control: Evaluation via intervention , author=. arXiv preprint arXiv:2411.04430 , year=
-
[21]
Forty-second International Conference on Machine Learning , year=
To Steer or Not to Steer? Mechanistic Error Reduction with Abstention for Language Models , author=. Forty-second International Conference on Machine Learning , year=
-
[22]
Gemma 3 technical report , author=. arXiv preprint arXiv:2503.19786 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Advances in neural information processing systems , volume=
Pytorch: An imperative style, high-performance deep learning library , author=. Advances in neural information processing systems , volume=
-
[25]
Proceedings of the 2020 conference on empirical methods in natural language processing: system demonstrations , pages=
Transformers: State-of-the-art natural language processing , author=. Proceedings of the 2020 conference on empirical methods in natural language processing: system demonstrations , pages=
2020
-
[26]
Language models encode numbers using digit representations in base 10 , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers) , pages=
2025
-
[27]
Proceedings of the Thirteenth International Conference on Learning Representations (ICLR) , year=
Not All Language Model Features Are One-Dimensionally Linear , author=. Proceedings of the Thirteenth International Conference on Learning Representations (ICLR) , year=
-
[28]
the Journal of machine Learning research , volume=
Scikit-learn: Machine learning in Python , author=. the Journal of machine Learning research , volume=. 2011 , publisher=
2011
-
[29]
Journal of machine learning research , volume=
Visualizing data using t-SNE , author=. Journal of machine learning research , volume=
-
[30]
Wiley interdisciplinary reviews: computational statistics , volume=
Principal component analysis , author=. Wiley interdisciplinary reviews: computational statistics , volume=. 2010 , publisher=
2010
-
[31]
AI Alignment Forum , year =
nostalgebraist , title =. AI Alignment Forum , year =
-
[32]
arXiv preprint arXiv:2411.16260 , year=
Unraveling arithmetic in large language models: The role of algebraic structures , author=. arXiv preprint arXiv:2411.16260 , year=
-
[33]
Hypothesis-Driven Feature Manifold Analysis in
Tiblias, Federico and Bigoulaeva, Irina and Niu, Jingcheng and Balloccu, Simone and Gurevych, Iryna , journal=. Hypothesis-Driven Feature Manifold Analysis in
-
[34]
Proceedings of the Artificial Intelligence in Measurement and Education Conference (AIME-Con): Full Papers , pages=
Mathematical Computation and Reasoning Errors by Large Language Models , author=. Proceedings of the Artificial Intelligence in Measurement and Education Conference (AIME-Con): Full Papers , pages=
-
[35]
A Language Model
Dimitri von R. A Language Model. Forty-first International Conference on Machine Learning , year=
-
[36]
arXiv preprint arXiv:2407.15421 , year=
Planning in a recurrent neural network that plays Sokoban , author=. arXiv preprint arXiv:2407.15421 , year=
-
[37]
MINT: Foundation Model Interventions , year=
Linearly Controlled Language Generation with Performative Guarantees , author=. MINT: Foundation Model Interventions , year=
-
[38]
First Conference on Language Modeling , year=
Eliciting Latent Knowledge from ''Quirky'' Language Models , author=. First Conference on Language Modeling , year=
-
[39]
Advances in Neural Information Processing Systems , volume=
Inference-time intervention: Eliciting truthful answers from a language model , author=. Advances in Neural Information Processing Systems , volume=
-
[40]
Proceedings of the 41st International Conference on Machine Learning , pages=
Interpreting and improving large language models in arithmetic calculation , author=. Proceedings of the 41st International Conference on Machine Learning , pages=
-
[41]
arXiv preprint arXiv:2304.02015 , year=
How well do large language models perform in arithmetic tasks? , author=. arXiv preprint arXiv:2304.02015 , year=
-
[42]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Exposing numeracy gaps: A benchmark to evaluate fundamental numerical abilities in large language models , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[43]
Findings of the Association for Computational Linguistics ACL 2024 , pages=
Unsupervised Real-Time Hallucination Detection based on the Internal States of Large Language Models , author=. Findings of the Association for Computational Linguistics ACL 2024 , pages=
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.