Training-Free Multi-Concept LoRA Composition with Prompt-Aware Weighting
Pith reviewed 2026-06-28 10:45 UTC · model grok-4.3
The pith
Prompt token importance enables training-free weighting of multiple LoRAs to reduce concept interference in image generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
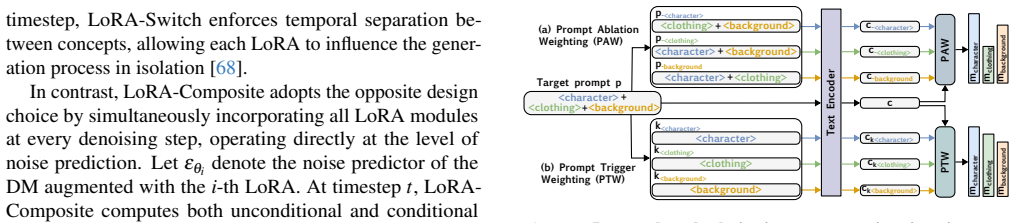
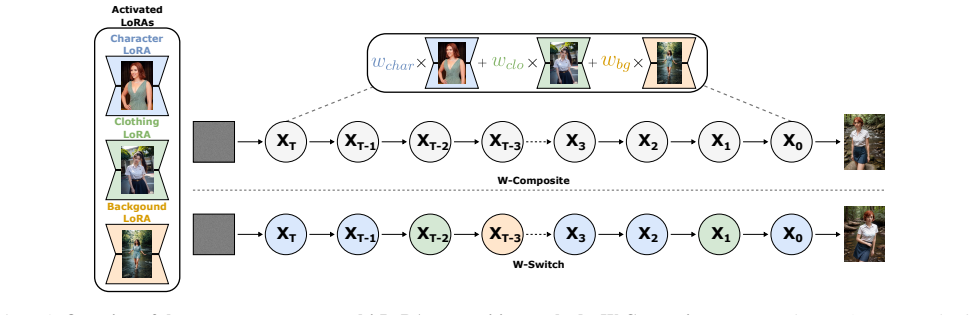
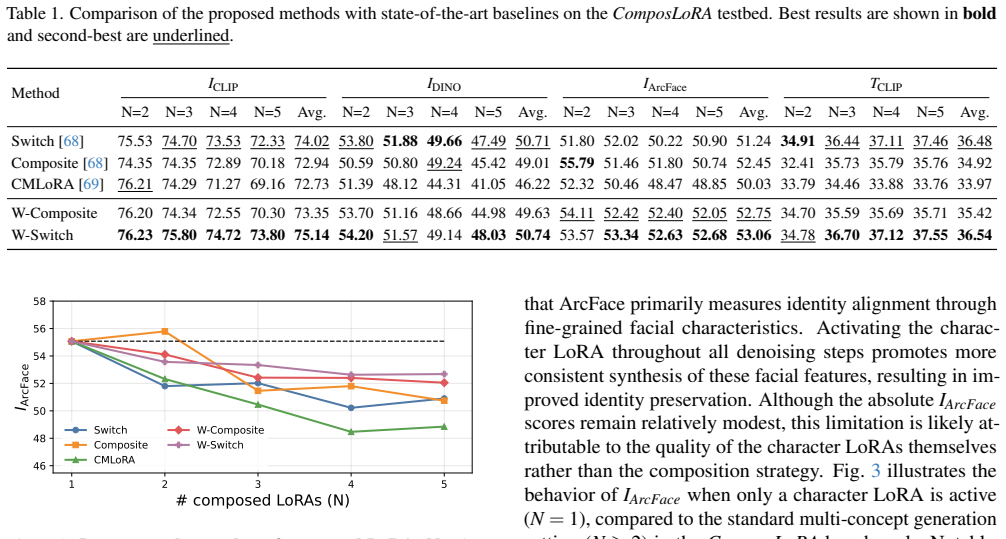
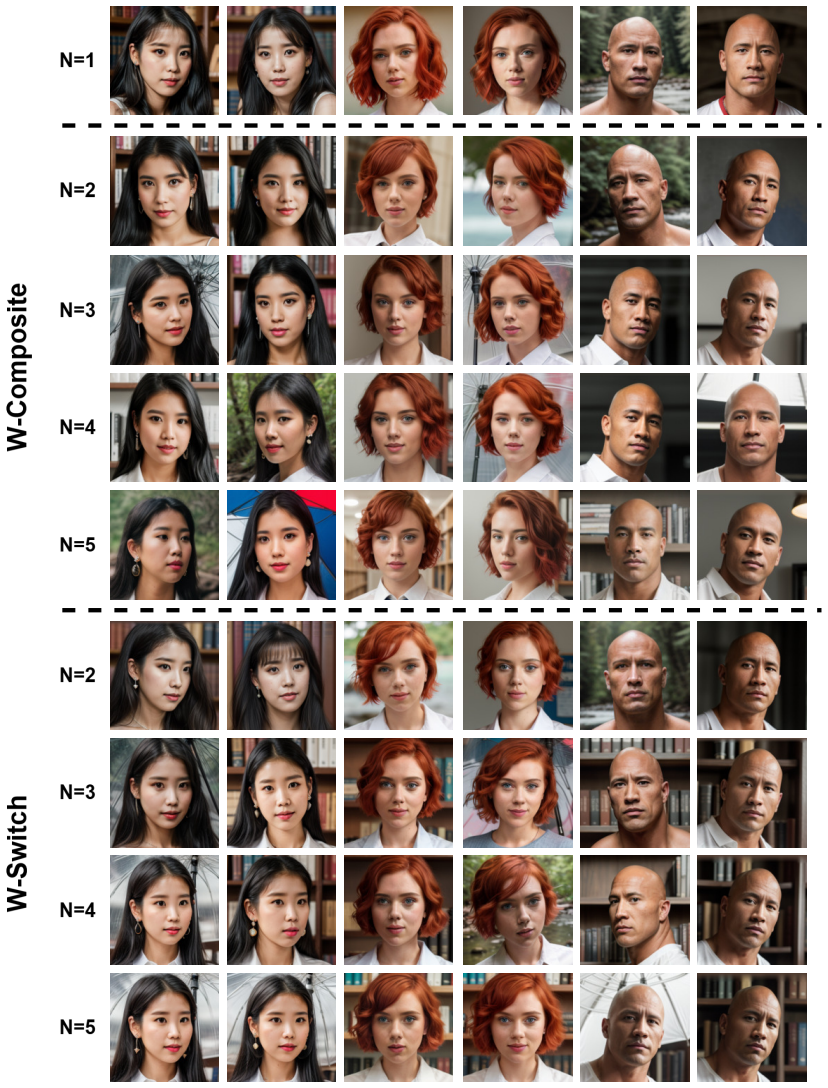
The central claim is that weighting the outputs of multiple LoRA modules by the semantic influence of their trigger words in the target prompt produces effective multi-concept combinations. This prompt-aware importance strategy, realized in the W-Switch and W-Composite methods, yields generated images with less concept interference, higher fidelity to individual references, and improved overall compositionality compared with unweighted or prior baselines.
What carries the argument
Prompt-aware importance weighting, which assigns each LoRA a weight derived from the semantic influence of its trigger words in the generation prompt.
If this is right
- Generated images preserve individual concept identities more accurately than naive LoRA addition.
- Quantitative gains appear consistently across the ComposLoRA benchmark and align with LLM-based and human evaluations.
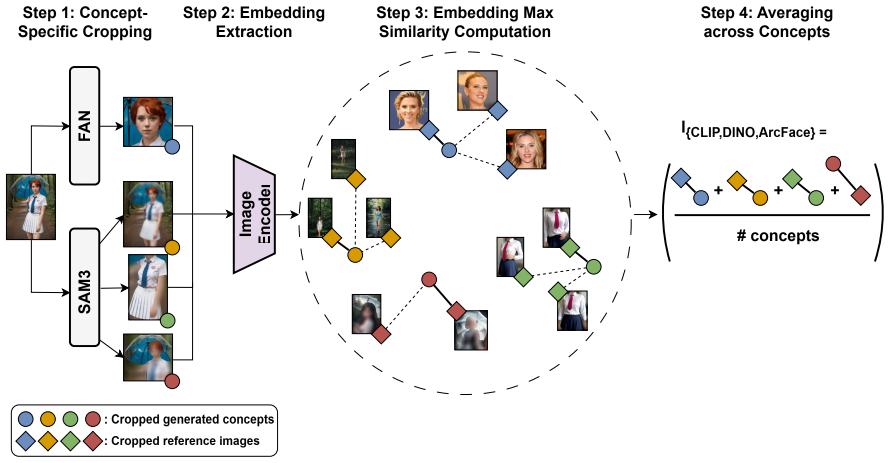
- The new image-based similarity framework enables direct fidelity checks between generated regions and real reference photos.
- No retraining is required to compose already-adapted LoRA modules.
Where Pith is reading between the lines
- The same token-influence logic might extend to weighting other modular adapters such as ControlNets or textual inversions.
- Prompts containing overlapping or ambiguous trigger words could expose cases where token counts alone under-estimate concept priority.
- Applying the weighting at different diffusion timesteps rather than uniformly might further reduce early-stage interference.
Load-bearing premise
Prompt tokens alone can reliably indicate the relative semantic importance of each concept for weighting LoRA outputs.
What would settle it
A controlled test set of multi-concept prompts where the prompt-weighted LoRA outputs exhibit measurably higher concept mixing or lower reference similarity than equal-weight combinations.
Figures








read the original abstract
Low-Rank Adaptation (LoRA) successfully enables personalization in text-to-image generation by adapting pre-trained diffusion models to specific visual concepts and styles. However, extending such models to multi-concept customization remains challenging. Naively combining multiple LoRA weights or their outputs often leads to interference among concepts, resulting in degraded visual quality and reduced fidelity to the reference images of individual concepts. This paper proposes a simple yet effective approach for multi-concept customization by optimally combining the outputs of multiple LoRA modules. We leverage the relative importance of each concept during generation, as inferred from its corresponding prompt tokens and introduce two methods, W-Switch and W-Composite, that employ a prompt-aware importance weighting strategy in which each LoRA is weighted according to the semantic influence of its trigger words in the target prompt. In addition, we extend existing quantitative evaluation metrics by proposing a new image-based similarity evaluation framework that assesses image fidelity and identity preservation through comparisons between real-world reference images and automatically segmented concept regions from generated images. We evaluate our approach on the ComposLoRA testbed and demonstrate consistent improvements over existing state-of-the-art methods in terms of visual quality, identity preservation and compositionality. Qualitative evaluations, including a Large Language Model (LLM) based assessment and a user study, further validate the effectiveness of the proposed methods and align with the newly introduced quantitative image-based metrics. Our code is available at https://github.com/GeorgeTsoumplekas/Prompt-Aware-Multi-LoRA-Composition.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that naively combining multiple LoRA modules for multi-concept text-to-image customization leads to interference and degraded fidelity; it introduces two training-free methods (W-Switch and W-Composite) that weight each LoRA output by the semantic importance of its trigger tokens in the target prompt, plus a new image-based similarity metric that compares segmented concept regions in generated images against real reference images. Experiments on the ComposLoRA testbed report consistent gains over prior methods in visual quality, identity preservation, and compositionality, corroborated by LLM-based assessment and a user study; code is released.
Significance. If the central claim holds, the work supplies a lightweight, training-free recipe for multi-concept personalization that could see immediate use in existing diffusion pipelines. The prompt-aware weighting idea and the proposed image-based fidelity metric are potentially reusable beyond this setting. The public code release is a clear strength that supports reproducibility.
major comments (2)
- [Abstract / Method description of W-Switch and W-Composite] The core assumption that scalar weighting of LoRA outputs (via token-derived importance) suffices to resolve concept interference is load-bearing for both W-Switch and W-Composite. The manuscript states that interference arises when “combining the outputs of multiple LoRA modules,” yet diffusion-model interference is known to occur inside the U-Net via shared attention and residual connections across denoising steps; output-level weighting alone does not modulate those internal paths. No derivation or ablation is supplied showing that prompt-token importance remains a faithful proxy once latents are mixed.
- [Evaluation section (new metric)] The new image-based similarity framework is presented as an extension of existing metrics, but the manuscript supplies no equations, segmentation procedure, exclusion rules, or quantitative comparison tables that would allow verification that the reported gains are not artifacts of the segmentation step or reference-image selection.
minor comments (2)
- [Abstract] The abstract asserts “consistent improvements” and alignment with LLM/user-study results but contains no numerical values, dataset sizes, or statistical tests; moving these numbers into the abstract would improve readability.
- [Method] Notation for the importance weights (how token influence is computed and normalized) is introduced without an explicit equation or pseudocode block, making the difference between W-Switch and W-Composite hard to reconstruct from text alone.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the work's significance, reproducibility via code release, and potential reusability of the prompt-aware weighting and metric ideas. We address each major comment below with concrete plans for revision.
read point-by-point responses
-
Referee: [Abstract / Method description of W-Switch and W-Composite] The core assumption that scalar weighting of LoRA outputs (via token-derived importance) suffices to resolve concept interference is load-bearing for both W-Switch and W-Composite. The manuscript states that interference arises when “combining the outputs of multiple LoRA modules,” yet diffusion-model interference is known to occur inside the U-Net via shared attention and residual connections across denoising steps; output-level weighting alone does not modulate those internal paths. No derivation or ablation is supplied showing that prompt-token importance remains a faithful proxy once latents are mixed.
Authors: We agree that interference in diffusion models occurs through internal U-Net mechanisms. Our output-level weighting is intended as a practical, training-free approximation that modulates each LoRA's contribution according to prompt-token semantics, which our experiments show reduces observable interference in the final images. While no closed-form derivation of the proxy is provided, the consistent gains on ComposLoRA across visual quality, identity, and compositionality metrics (including LLM and user study) support its utility. In revision we will add a dedicated discussion paragraph on the internal-vs-output distinction and an ablation varying the weighting granularity to better characterize the proxy's faithfulness. revision: partial
-
Referee: [Evaluation section (new metric)] The new image-based similarity framework is presented as an extension of existing metrics, but the manuscript supplies no equations, segmentation procedure, exclusion rules, or quantitative comparison tables that would allow verification that the reported gains are not artifacts of the segmentation step or reference-image selection.
Authors: We accept this criticism; the current presentation of the image-based similarity framework is insufficiently detailed. The revised manuscript will include the complete equations, a precise description of the segmentation procedure and exclusion rules, and additional quantitative tables comparing the metric against baselines and alternative segmenters to confirm that reported improvements are not segmentation artifacts. revision: yes
Circularity Check
No circularity: method is a heuristic weighting strategy without load-bearing derivations or self-referential reductions
full rationale
The abstract and description present W-Switch and W-Composite as prompt-aware weighting heuristics that assign scalar weights to LoRA outputs based on token-derived importance. No equations, parameter fits, uniqueness theorems, or self-citations are invoked as load-bearing steps that would reduce the claimed improvements to the inputs by construction. The new image-based similarity metrics are extensions for evaluation rather than derivations of the core method. The approach is self-contained as an empirical combination strategy without any of the enumerated circular patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In- trinsic dimensionality explains the effectiveness of language model fine-tuning
Armen Aghajanyan, Sonal Gupta, and Luke Zettlemoyer. In- trinsic dimensionality explains the effectiveness of language model fine-tuning. InProceedings of the 59th annual meeting of the association for computational linguistics and the 11th international joint conference on natural language processing (volume 1: long papers), pages 7319–7328, 2021. 3
2021
-
[2]
Imagen 3.arXiv preprint arXiv:2408.07009, 2024
Jason Baldridge, Jakob Bauer, Mukul Bhutani, Nicole Brich- tova, Andrew Bunner, Lluis Castrejon, Kelvin Chan, Yichang Chen, Sander Dieleman, Yuqing Du, et al. Imagen 3.arXiv preprint arXiv:2408.07009, 2024. 1
-
[3]
Eric Tillmann Bill, Enis Simsar, and Thomas Hofmann. Jedi: The force of jensen-shannon divergence in disentangling dif- fusion models.arXiv preprint arXiv:2505.19166, 2025. 2
-
[4]
Finding directions in gan’s latent space for neural face reenactment
Stella Bounareli, Vasileios Argyriou, and Georgios Tz- imiropoulos. Finding directions in gan’s latent space for neural face reenactment. InBritish Machine Vision Confer- ence, 2022. 14
2022
-
[5]
How far are we from solving the 2d & 3d face alignment problem?(and a dataset of 230,000 3d facial landmarks)
Adrian Bulat and Georgios Tzimiropoulos. How far are we from solving the 2d & 3d face alignment problem?(and a dataset of 230,000 3d facial landmarks). InProceedings of the IEEE international conference on computer vision, pages 1021–1030, 2017. 6, 14
2017
-
[6]
SAM 3: Segment Anything with Concepts
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoub- hik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, et al. Sam 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719, 2025. 6, 14
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Bolin Chen, Baoquan Zhao, Haoran Xie, Yi Cai, Qing Li, and Xudong Mao. Consislora: Enhancing content and style consistency for lora-based style transfer.arXiv preprint arXiv:2503.10614, 2025. 2
-
[8]
Iteris: Iterative inference-solving alignment for lora merging
Hongxu Chen, Zhen Wang, Runshi Li, Bowei Zhu, and Long Chen. Iteris: Iterative inference-solving alignment for lora merging. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 4829–4838, 2025. 1, 2
2025
-
[9]
Perception prior- itized training of diffusion models
Jooyoung Choi, Jungbeom Lee, Chaehun Shin, Sungwon Kim, Hyunwoo Kim, and Sungroh Yoon. Perception prior- itized training of diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recog- nition, pages 11472–11481, 2022. 5, 9
2022
-
[10]
Yusuf Dalva, Hidir Yesiltepe, and Pinar Yanardag. Lo- rashop: Training-free multi-concept image generation and editing with rectified flow transformers.arXiv preprint arXiv:2505.23758, 2025. 3
-
[11]
Arcface: Additive angular margin loss for deep face recog- nition
Jiankang Deng, Jia Guo, Niannan Xue, and Stefanos Zafeiriou. Arcface: Additive angular margin loss for deep face recog- nition. InProceedings of the IEEE/CVF conference on com- puter vision and pattern recognition, pages 4690–4699, 2019. 2, 6, 17
2019
-
[12]
Compositional visual generation with energy based models.Advances in Neural Information Processing Systems, 33:6637–6647, 2020
Yilun Du, Shuang Li, and Igor Mordatch. Compositional visual generation with energy based models.Advances in Neural Information Processing Systems, 33:6637–6647, 2020. 2
2020
-
[13]
Sugarcrepe++ dataset: Vision-language model sensi- tivity to semantic and lexical alterations.Advances in Neural Information Processing Systems, 37:17972–18018, 2024
Sri Harsha Dumpala, Aman Jaiswal, Chandramouli Shama Sastry, Evangelos Milios, Sageev Oore, and Hassan Sajjad. Sugarcrepe++ dataset: Vision-language model sensi- tivity to semantic and lexical alterations.Advances in Neural Information Processing Systems, 37:17972–18018, 2024. 4
2024
-
[14]
Loratorio: An intrinsic approach to lora skill composition
Niki Foteinopoulou, Ignas Budvytis, and Stephan Liwicki. Loratorio: An intrinsic approach to lora skill composition. arXiv preprint arXiv:2508.11624, 2025. 1, 2, 3, 6, 7, 17, 20
-
[15]
Implicit style-content separation using b-lora
Yarden Frenkel, Yael Vinker, Ariel Shamir, and Daniel Cohen- Or. Implicit style-content separation using b-lora. InEu- ropean Conference on Computer Vision, pages 181–198. Springer, 2024. 2
2024
-
[16]
An image is worth one word: Personalizing text-to-image generation using textual inversion
Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit Haim Bermano, Gal Chechik, and Daniel Cohen-Or. An image is worth one word: Personalizing text-to-image generation using textual inversion. InThe Eleventh Interna- tional Conference on Learning Representations, 2023. 17
2023
-
[17]
Mix-of-show: Decentralized low- rank adaptation for multi-concept customization of diffusion models.Advances in Neural Information Processing Systems, 36:15890–15902, 2023
Yuchao Gu, Xintao Wang, Jay Zhangjie Wu, Yujun Shi, Yun- peng Chen, Zihan Fan, Wuyou Xiao, Rui Zhao, Shuning Chang, Weijia Wu, et al. Mix-of-show: Decentralized low- rank adaptation for multi-concept customization of diffusion models.Advances in Neural Information Processing Systems, 36:15890–15902, 2023. 1, 2, 3, 6, 13
2023
-
[18]
Clipscore: A reference-free evaluation metric for image captioning
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. Clipscore: A reference-free evaluation metric for image captioning. InProceedings of the 2021 conference on empirical methods in natural language processing, pages 7514–7528, 2021. 6, 17
2021
-
[19]
Classifier-free diffusion guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. InNeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications, 2021. 3
2021
-
[20]
Denoising diffu- sion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffu- sion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020. 3
2020
-
[21]
Video diffusion models.Advances in neural information processing systems, 35:8633–8646, 2022
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J Fleet. Video diffusion models.Advances in neural information processing systems, 35:8633–8646, 2022. 1
2022
-
[22]
Interactdiffusion: Interaction con- trol in text-to-image diffusion models
Jiun Tian Hoe, Xudong Jiang, Chee Seng Chan, Yap-Peng Tan, and Weipeng Hu. Interactdiffusion: Interaction con- trol in text-to-image diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6180–6189, 2024. 1
2024
-
[23]
Lora: Low-rank adaptation of large language models.ICLR, 1(2):3,
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 1(2):3,
-
[24]
Lorahub: Efficient cross-task gener- alization via dynamic lora composition
Chengsong Huang, Qian Liu, Bill Yuchen Lin, Tianyu Pang, Chao Du, and Min Lin. Lorahub: Efficient cross-task gener- alization via dynamic lora composition. InFirst Conference on Language Modeling, 2024. 2
2024
-
[25]
Eigenlorax: Recycling adapters to find principal sub- spaces for resource-efficient adaptation and inference
Prakhar Kaushik, Ankit Vaidya, Shravan Chaudhari, and Alan Yuille. Eigenlorax: Recycling adapters to find principal sub- spaces for resource-efficient adaptation and inference. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 649–659, 2025. 2
2025
-
[26]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024. 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Multi-concept customization of text- to-image diffusion
Nupur Kumari, Bingliang Zhang, Richard Zhang, Eli Shecht- man, and Jun-Yan Zhu. Multi-concept customization of text- to-image diffusion. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 1931–1941, 2023. 2
1931
-
[28]
Concept weaver: Enabling multi-concept fusion in text-to-image models
Gihyun Kwon, Simon Jenni, Dingzeyu Li, Joon-Young Lee, Jong Chul Ye, and Fabian Caba Heilbron. Concept weaver: Enabling multi-concept fusion in text-to-image models. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 8880–8889, 2024. 2
2024
-
[29]
The double-ellipsoid geometry of CLIP
Meir Yossef Levi and Guy Gilboa. The double-ellipsoid geometry of CLIP. InForty-second International Conference on Machine Learning, 2025. 6
2025
-
[30]
Zhiwen Li, Zhongjie Duan, Die Chen, Cen Chen, Daoyuan Chen, Yaliang Li, and Yingda Chen. Autolora: Automatic lora retrieval and fine-grained gated fusion for text-to-image generation.arXiv preprint arXiv:2508.02107, 2025. 2
-
[31]
Compositional visual generation with composable diffusion models
Nan Liu, Shuang Li, Yilun Du, Antonio Torralba, and Joshua B Tenenbaum. Compositional visual generation with composable diffusion models. InEuropean conference on computer vision, pages 423–439. Springer, 2022. 1
2022
-
[32]
Customizable image synthesis with multiple subjects
Zhiheng Liu, Yifei Zhang, Yujun Shen, Kecheng Zheng, Kai Zhu, Ruili Feng, Yu Liu, Deli Zhao, Jingren Zhou, and Yang Cao. Customizable image synthesis with multiple subjects. Advances in neural information processing systems, 36:57500– 57519, 2023. 2, 3
2023
-
[33]
Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps.Advances in neural information processing systems, 35:5775–5787, 2022
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps.Advances in neural information processing systems, 35:5775–5787, 2022. 6
2022
-
[34]
Contrastive test-time composition of multiple lora models for image generation
Tuna Han Salih Meral, Enis Simsar, Federico Tombari, and Pinar Yanardag. Contrastive test-time composition of multiple lora models for image generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 18090–18100, 2025. 3
2025
-
[35]
Ladi-vton: Latent diffusion textual-inversion enhanced virtual try-on
Davide Morelli, Alberto Baldrati, Giuseppe Cartella, Mar- cella Cornia, Marco Bertini, and Rita Cucchiara. Ladi-vton: Latent diffusion textual-inversion enhanced virtual try-on. In Proceedings of the 31st ACM international conference on multimedia, pages 8580–8589, 2023. 1
2023
-
[36]
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel HAZIZA, Francisco Massa, Alaaeldin El-Nouby, Mido Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herve Je- gou, Julien Mairal, Patrick...
-
[37]
K-lora: Unlock- ing training-free fusion of any subject and style loras
Ziheng Ouyang, Zhen Li, and Qibin Hou. K-lora: Unlock- ing training-free fusion of any subject and style loras. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 13041–13050, 2025. 2
2025
-
[38]
Understanding the latent space of diffu- sion models through the lens of riemannian geometry.Ad- vances in Neural Information Processing Systems, 36:24129– 24142, 2023
Yong-Hyun Park, Mingi Kwon, Jaewoong Choi, Junghyo Jo, and Youngjung Uh. Understanding the latent space of diffu- sion models through the lens of riemannian geometry.Ad- vances in Neural Information Processing Systems, 36:24129– 24142, 2023. 5, 9
2023
-
[39]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 4195–4205,
-
[40]
Tara: Token-aware lora for composable personalization in diffusion models
Yuqi Peng, Lingtao Zheng, Yufeng Yang, Yi Huang, Mingfu Yan, Jianzhuang Liu, and Shifeng Chen. Tara: Token-aware lora for composable personalization in diffusion models. arXiv preprint arXiv:2508.08812, 2025. 2
-
[41]
Orthogonal adaptation for modular customization of diffusion models
Ryan Po, Guandao Yang, Kfir Aberman, and Gordon Wet- zstein. Orthogonal adaptation for modular customization of diffusion models. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 7964–7973, 2024. 1, 2, 6, 13
2024
-
[42]
SDXL: Improving latent diffusion models for high-resolution image synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. SDXL: Improving latent diffusion models for high-resolution image synthesis. InThe Twelfth International Conference on Learning Representations, 2024. 1
2024
-
[43]
Lora soups: Merg- ing loras for practical skill composition tasks
Akshara Prabhakar, Yuanzhi Li, Karthik Narasimhan, Sham Kakade, Eran Malach, and Samy Jelassi. Lora soups: Merg- ing loras for practical skill composition tasks. InProceedings of the 31st International Conference on Computational Lin- guistics: Industry Track, pages 644–655, 2025. 2
2025
-
[44]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 2, 6
2021
-
[45]
Zero-shot text-to-image generation
Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea V oss, Alec Radford, Mark Chen, and Ilya Sutskever. Zero-shot text-to-image generation. InInternational confer- ence on machine learning, pages 8821–8831. Pmlr, 2021. 1
2021
-
[46]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 1, 3, 6
2022
-
[47]
Aniket Roy, Maitreya Suin, Ketul Shah, and Rama Chellappa. Multlfg: Training-free multi-lora composi- tion using frequency-domain guidance.arXiv preprint arXiv:2505.20525, 2025. 1, 2, 3
-
[48]
Dreambooth: Fine tuning text-to-image diffusion models for subject-driven gen- eration
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven gen- eration. InProceedings of the IEEE/CVF conference on com- puter vision and pattern recognition, pages 22500–22510,
-
[49]
Pho- torealistic text-to-image diffusion models with deep language understanding.Advances in neural information processing systems, 35:36479–36494, 2022
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. Pho- torealistic text-to-image diffusion models with deep language understanding.Advances in neural information processing systems, 35:36479–36494, 2022. 1
2022
-
[50]
Ziplora: Any subject in any style by effectively merging loras
Viraj Shah, Nataniel Ruiz, Forrester Cole, Erika Lu, Svetlana Lazebnik, Yuanzhen Li, and Varun Jampani. Ziplora: Any subject in any style by effectively merging loras. InEuropean Conference on Computer Vision, pages 422–438. Springer,
-
[51]
Donald Shenaj, Ondrej Bohdal, Mete Ozay, Pietro Zanuttigh, and Umberto Michieli. Lora. rar: Learning to merge loras via hypernetworks for subject-style conditioned image generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 16132–16142, 2025. 2
2025
-
[52]
Loraclr: Contrastive adaptation for customization of diffusion models
Enis Simsar, Thomas Hofmann, Federico Tombari, and Pinar Yanardag. Loraclr: Contrastive adaptation for customization of diffusion models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 13189–13198,
-
[53]
Make-a-video: Text-to-video generation without text-video data
Uriel Singer, Adam Polyak, Thomas Hayes, Xi Yin, Jie An, Songyang Zhang, Qiyuan Hu, Harry Yang, Oron Ashual, Oran Gafni, Devi Parikh, Sonal Gupta, and Yaniv Taigman. Make-a-video: Text-to-video generation without text-video data. InThe Eleventh International Conference on Learning Representations, 2023. 1
2023
-
[54]
Deep unsupervised learning using nonequilibrium thermodynamics
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. InInternational confer- ence on machine learning, pages 2256–2265. pmlr, 2015. 3
2015
-
[55]
Denoising diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. InInternational Conference on Learning Representations, 2021. 3
2021
-
[56]
arXiv preprint arXiv:2303.09522 , year=
Andrey V oynov, Qinghao Chu, Daniel Cohen-Or, and Kfir Aberman. p+: Extended textual conditioning in text-to-image generation.arXiv preprint arXiv:2303.09522, 2023. 2
-
[57]
Characonsist: Fine- grained consistent character generation
Mengyu Wang, Henghui Ding, Jianing Peng, Yao Zhao, Yunpeng Chen, and Yunchao Wei. Characonsist: Fine- grained consistent character generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 16058–16067, 2025. 1
2025
-
[58]
Fastcomposer: Tuning-free multi- subject image generation with localized attention.Interna- tional Journal of Computer Vision, 133(3):1175–1194, 2025
Guangxuan Xiao, Tianwei Yin, William T Freeman, Frédo Durand, and Song Han. Fastcomposer: Tuning-free multi- subject image generation with localized attention.Interna- tional Journal of Computer Vision, 133(3):1175–1194, 2025. 2, 3
2025
-
[59]
Qr-lora: Efficient and disentangled fine-tuning via qr decomposition for customized generation
Jiahui Yang, Yongjia Ma, Donglin Di, Jianxun Cui, Hao Li, Wei Chen, Yan Xie, Xun Yang, and Wangmeng Zuo. Qr-lora: Efficient and disentangled fine-tuning via qr decomposition for customized generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 17587– 17597, 2025. 2
2025
-
[60]
Lora-composer: Leveraging low-rank adap- tation for multi-concept customization in training-free diffu- sion models.IEEE Transactions on Image Processing, 34: 8145–8158, 2025
Yang Yang, Wen Wang, Liang Peng, Chaotian Song, Yao Chen, Hengjia Li, Xiaolong Yang, Qinglin Lu, Deng Cai, Xiaofei He, et al. Lora-composer: Leveraging low-rank adap- tation for multi-concept customization in training-free diffu- sion models.IEEE Transactions on Image Processing, 34: 8145–8158, 2025. 3
2025
-
[61]
MiniCPM-V: A GPT-4V Level MLLM on Your Phone
Yuan Yao, Tianyu Yu, Ao Zhang, Chongyi Wang, Junbo Cui, Hongji Zhu, Tianchi Cai, Haoyu Li, Weilin Zhao, Zhihui He, et al. Minicpm-v: A gpt-4v level mllm on your phone.arXiv preprint arXiv:2408.01800, 2024. 6, 8, 17
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[62]
Andi Zhang, Xuan Ding, Haofan Wang, Steven McDon- agh, and Samuel Kaski. Rethinking inter-lora orthogonality in adapter merging: Insights from orthogonal monte carlo dropout.arXiv preprint arXiv:2510.03262, 2025. 2
-
[63]
Jia-Chen Zhang and Yu-Jie Xiong. Subject or style: Adap- tive and training-free mixture of loras.arXiv preprint arXiv:2508.02165, 2025. 2
-
[64]
S3fd: Single shot scale-invariant face detector
Shifeng Zhang, Xiangyu Zhu, Zhen Lei, Hailin Shi, Xiaobo Wang, and Stan Z Li. S3fd: Single shot scale-invariant face detector. InProceedings of the IEEE international conference on computer vision, pages 192–201, 2017. 14
2017
-
[65]
Xinlu Zhang, Yujie Lu, Weizhi Wang, An Yan, Jun Yan, Lianke Qin, Heng Wang, Xifeng Yan, William Yang Wang, and Linda Ruth Petzold. Gpt-4v (ision) as a general- ist evaluator for vision-language tasks.arXiv preprint arXiv:2311.01361, 2023. 17
-
[66]
Peng Zheng, Ye Wang, Rui Ma, and Zuxuan Wu. Freelora: Enabling training-free lora fusion for autoregressive multi- subject personalization.arXiv preprint arXiv:2507.01792,
-
[67]
Shenghe Zheng, Hongzhi Wang, Chenyu Huang, Xiaohui Wang, Tao Chen, Jiayuan Fan, Shuyue Hu, and Peng Ye. Decouple and orthogonalize: A data-free framework for lora merging.arXiv preprint arXiv:2505.15875, 2025. 2
-
[68]
Multi- lora composition for image generation.Transactions on Ma- chine Learning Research, 2024
Ming Zhong, Shuohang Wang, Yadong Lu, Yizhu Jiao, Siru Ouyang, Donghan Yu, Jiawei Han, Weizhu Chen, et al. Multi- lora composition for image generation.Transactions on Ma- chine Learning Research, 2024. 1, 3, 4, 6, 7, 8, 15, 17
2024
-
[69]
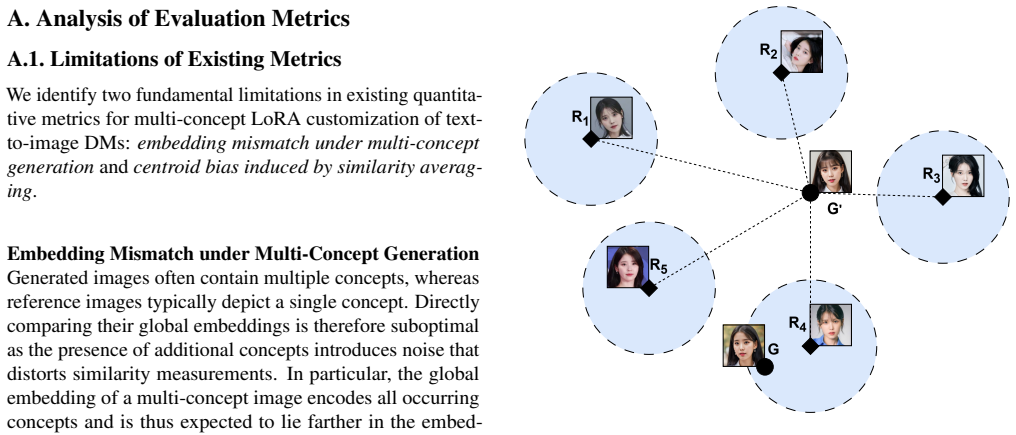
Xiandong Zou, Mingzhu Shen, Christos-Savvas Bouganis, and Yiren Zhao. Cached multi-lora composition for multi- concept image generation. InThe Thirteenth International Conference on Learning Representations, 2025. 1, 2, 3, 6, 7, 8, 15, 17 A. Analysis of Evaluation Metrics A.1. Limitations of Existing Metrics We identify two fundamental limitations in exis...
-
[70]
Criteria: - Visual Cohesion: Evaluate whether the elements appear as part of a unified scene, rather than as disjointed parts
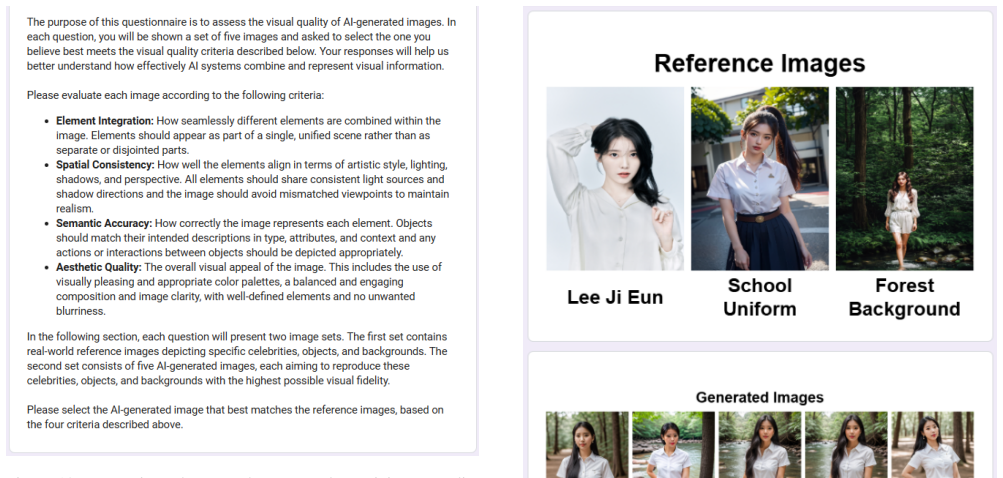
Element Integration: How seamlessly different elements are combined within the image. Criteria: - Visual Cohesion: Evaluate whether the elements appear as part of a unified scene, rather than as disjointed parts. - Object Overlap and Interaction: Check for natural overlaps and interactions between objects, ensuring no awkward placements or intersections
-
[71]
Criteria: - Stylistic Uniformity: Ensure that all elements share a consistent artistic style (e.g., realism, cartoonish)
Spatial Consistency: Uniformity in style, lighting, and perspective across all elements. Criteria: - Stylistic Uniformity: Ensure that all elements share a consistent artistic style (e.g., realism, cartoonish). - Lighting and Shadows: Verify that light sources and shadow directions are consistent, contributing to a realistic portrayal. - Perspective Align...
-
[72]
Criteria: - Object Accuracy: Objects should align with their descriptions in terms of type, attributes, and context
Semantic Accuracy: Correct interpretation and representation of each element as described in the prompt. Criteria: - Object Accuracy: Objects should align with their descriptions in terms of type, attributes, and context. - Action and Interaction: Actions or interactions between objects should be depicted accurately and appropriately
-
[73]
method",
Aesthetic Quality: Overall visual appeal and artistic quality of the generated image. Criteria: - Color Harmony: The use of color palettes should be visually pleasing and fitting for the scene. - Composition Balance: Elements should be arranged in a balanced way to create an engaging and harmonious composition. - Clarity and Sharpness: The image should be...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.