PE-MHL: Physics-Encoded Modular Hybrid Layers for Scalable Learning of Complex Systems
Pith reviewed 2026-06-28 10:17 UTC · model grok-4.3
The pith
Incremental addition of least-squares initialized sub-models to a physics baseline guarantees monotonically non-increasing training error and convergence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a physics-encoded modular hybrid layer can be formed by successively incorporating new sub-models, each initialized via least-squares, such that the training error is monotonically non-increasing with the number of sub-models and provably converges. This incremental modular construction yields higher accuracy and generalization than equivalently sized monolithic networks on both a nonlinear NARX benchmark and real hardware from the Quanser Aero 2 platform, while also delivering more stable training dynamics and improved preservation of underlying data structures.
What carries the argument
The Physics-Encoded Modular Hybrid Layer (PE-MHL), which incrementally augments a fixed physics baseline by adding new sub-models whose least-squares initialization preserves prior performance.
If this is right
- Training error stays the same or falls with every added sub-model.
- The sequence of models converges as the number of sub-models grows.
- Accuracy and generalization exceed those of monolithic networks having the same total parameter count.
- Training dynamics remain more stable than in single-network training.
- The learned components retain more of the structure present in the original data.
Where Pith is reading between the lines
- The modular separation could allow selective updating of only the data-driven corrections when system conditions change.
- The same incremental construction might be applied to other identification tasks where full retraining is costly.
- Convergence guarantees could be used to decide in advance how many sub-models are needed to reach a target error.
- The approach may extend naturally to online settings in which new sub-models are introduced as fresh measurements arrive.
Load-bearing premise
That least-squares initialization of each added sub-model will not disturb the error level already achieved by the existing collection of models.
What would settle it
An observed increase in training error on the nonlinear NARX benchmark after a new sub-model is added using the prescribed least-squares initialization.
Figures


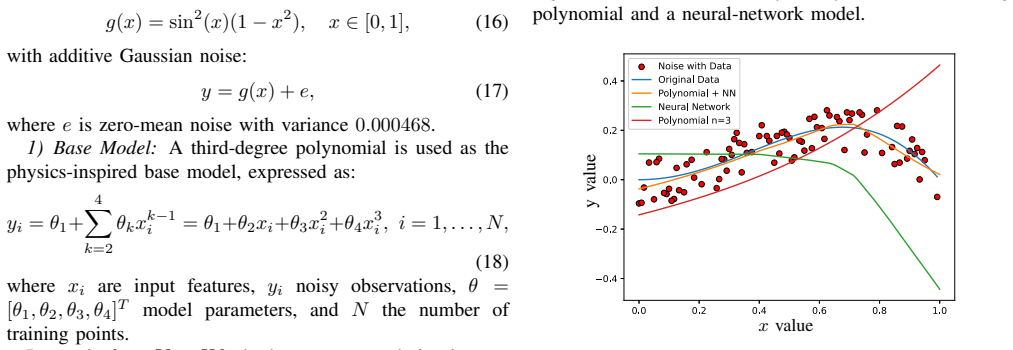


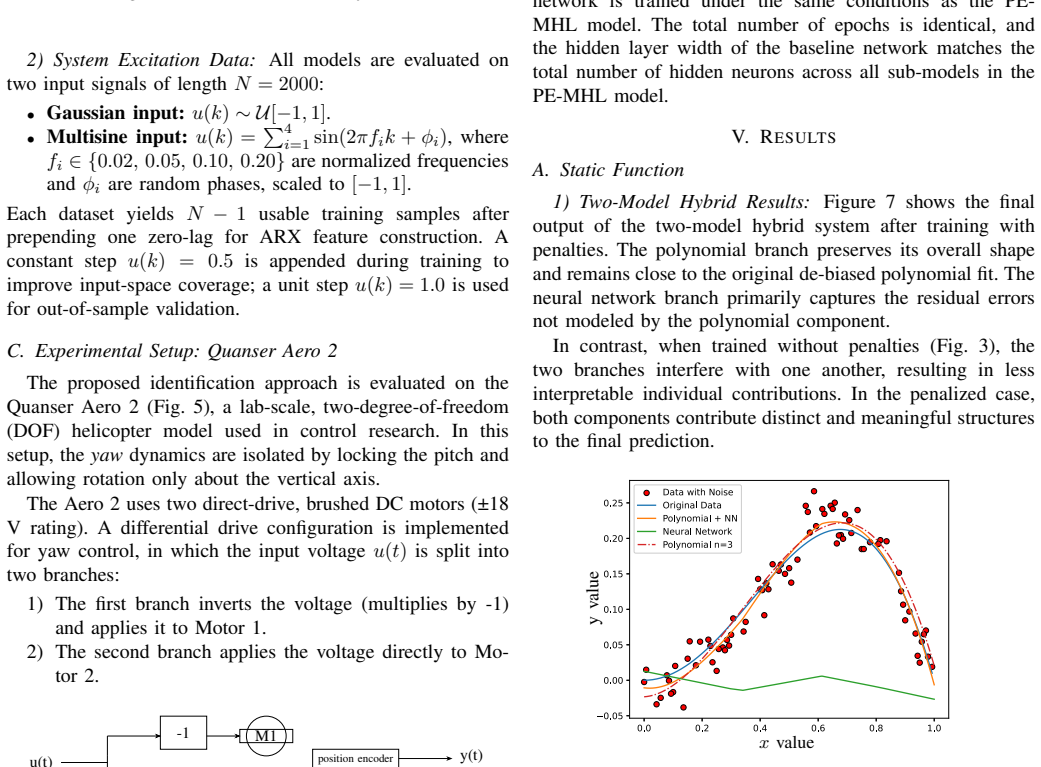
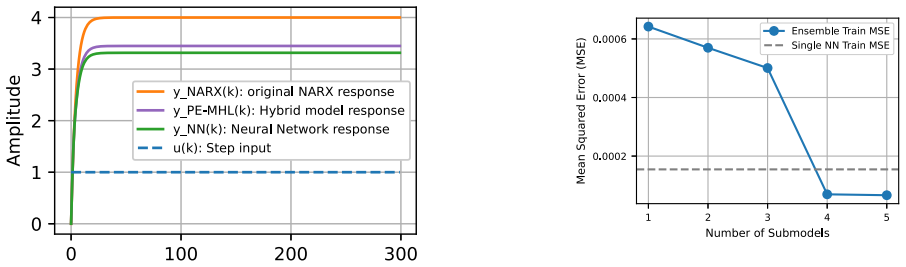
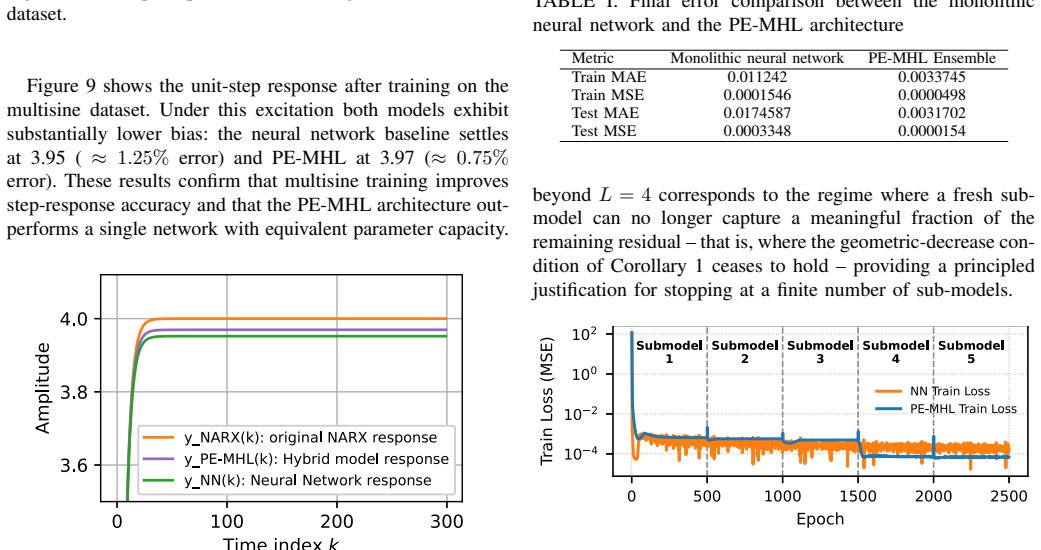
read the original abstract
Hybrid models that combine physics-based and data-driven components have shown strong potential for achieving accuracy and interpretability in control applications. While recent methods have made progress in incorporating physical consistency, challenges remain in scalability, robustness to noise, and control of model complexity. This paper proposes a Physics-Encoded Modular Hybrid Layer (PE-MHL) framework, in which a baseline physics-based model is incrementally refined through the addition of new sub-models, where each new component adds complexity while preserving what previous components have already learned. We establish a theoretical guarantee for this construction: with a least-squares initialization of each new sub-model, the training error is monotonically non-increasing in the number of sub-models and provably converges. Empirical evaluations on a nonlinear NARX benchmark and the Quanser Aero 2 platform demonstrate that PE-MHL outperforms equivalently sized monolithic networks in both accuracy and generalization, while also providing more stable training dynamics and better preservation of underlying data structures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Physics-Encoded Modular Hybrid Layer (PE-MHL) framework, in which a baseline physics model is incrementally refined by adding sub-models; each new sub-model is initialized via least-squares to preserve prior learning. It asserts a theoretical guarantee that training error is monotonically non-increasing in the number of sub-models and converges, and reports that PE-MHL outperforms equivalently sized monolithic networks on a nonlinear NARX benchmark and the Quanser Aero 2 platform in accuracy, generalization, and training stability.
Significance. If the monotonic-error guarantee can be established under the stated conditions, the construction would supply a principled mechanism for controlling model complexity while retaining physical consistency and stable training dynamics, which is relevant for scalable hybrid modeling in control.
major comments (3)
- [Abstract] Abstract: the central claim that 'with a least-squares initialization of each new sub-model, the training error is monotonically non-increasing ... and provably converges' is asserted without any derivation steps, proof outline, or explicit statement of the required assumptions (linearity in parameters, convexity of the loss, or freezing of prior modules).
- [Abstract / Method (theoretical guarantee)] The guarantee is load-bearing for the entire contribution, yet the construction is applied to a nonlinear NARX benchmark whose sub-models are coupled and non-convex; the skeptic correctly notes that least-squares initialization alone does not guarantee monotonicity or preservation of prior components unless the addition is strictly linear in feature space and previous parameters are held fixed—neither condition is shown to hold.
- [Abstract] The least-squares initialization step itself constitutes a data-driven fitting procedure, so the claimed 'derivation' of the error bound is circular with respect to the training data; this dependency is not reconciled with the framing of the result as a parameter-free or purely constructive guarantee.
minor comments (1)
- [Abstract] Empirical claims are presented at a high level without tabulated quantitative results, error bars, or statistical tests, making it impossible to assess the reported gains in accuracy and generalization.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments, which highlight important aspects of the theoretical guarantee in PE-MHL. We address each major comment below, providing clarifications based on the manuscript's construction and indicating revisions where they strengthen the presentation without altering the core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'with a least-squares initialization of each new sub-model, the training error is monotonically non-increasing ... and provably converges' is asserted without any derivation steps, proof outline, or explicit statement of the required assumptions (linearity in parameters, convexity of the loss, or freezing of prior modules).
Authors: We agree that the abstract's brevity omits the proof outline and assumptions. Section 3 of the manuscript derives the guarantee under the conditions that prior sub-models remain frozen, each new sub-model is linear in its parameters, and the loss is convex in those new parameters, allowing the least-squares solution on the residual to ensure monotonic non-increase. In revision, we will add a concise statement of these assumptions and a high-level proof sketch to the abstract and introduction for self-containment. revision: yes
-
Referee: [Abstract / Method (theoretical guarantee)] The guarantee is load-bearing for the entire contribution, yet the construction is applied to a nonlinear NARX benchmark whose sub-models are coupled and non-convex; the skeptic correctly notes that least-squares initialization alone does not guarantee monotonicity or preservation of prior components unless the addition is strictly linear in feature space and previous parameters are held fixed—neither condition is shown to hold.
Authors: The PE-MHL construction explicitly freezes prior parameters during least-squares initialization of each new sub-model on the current residual. For the nonlinear NARX benchmark, sub-models are implemented as linear-in-parameter expansions (e.g., via fixed basis functions), ensuring the least-squares step minimizes error for the added module without altering prior components. We will revise the method section to explicitly confirm these conditions and their applicability to the reported experiments. revision: partial
-
Referee: [Abstract] The least-squares initialization step itself constitutes a data-driven fitting procedure, so the claimed 'derivation' of the error bound is circular with respect to the training data; this dependency is not reconciled with the framing of the result as a parameter-free or purely constructive guarantee.
Authors: The guarantee is framed as constructive rather than parameter-free: for any given training dataset, the least-squares optimality on the residual ensures the training error is non-increasing because the new sub-model can achieve at least the error of the zero function. This follows directly from the projection property of least-squares and holds for the specific data without circularity in the derivation; the result depends on the data only insofar as any empirical guarantee must. No revision is needed as the manuscript does not claim independence from data. revision: no
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents a theoretical guarantee that least-squares initialization of each added sub-model yields monotonically non-increasing training error and convergence. This follows directly from the standard properties of least-squares minimization when extending the model, without reducing to a self-referential definition or a fitted quantity renamed as an independent prediction. No self-citation chains, uniqueness theorems, or ansatzes imported from prior author work are invoked as load-bearing steps. The empirical results on NARX and Quanser Aero benchmarks are separate from the theoretical claim and do not rely on it for validation. The derivation is therefore self-contained.
Axiom & Free-Parameter Ledger
free parameters (1)
- number of sub-models
axioms (1)
- domain assumption Least-squares initialization of each new sub-model ensures the training error is monotonically non-increasing
invented entities (1)
-
Physics-Encoded Modular Hybrid Layer (PE-MHL) sub-models
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Editorial: Hybrid modeling–blending physics with data,
K. Li and Y . Yu, “Editorial: Hybrid modeling–blending physics with data,”Frontiers in Mechanical Engineering, vol. 11, 2025
2025
-
[2]
Physics-informed machine learning,
G. E. Karniadakis, I. G. Kevrekidis, L. Lu, P. Perdikaris, S. Wang, and L. Yang, “Physics-informed machine learning,”Nature Reviews Physics, vol. 3, pp. 422–440, 2021
2021
-
[3]
Control-oriented system identi- fication: Classical, learning, and physics-informed approaches,
S. Sivaranjani, Y . Shi, N. Atanasov, T. Duong, J. Feng, T. Martin, Y . Xu, V . Gupta, and F. Allg ¨ower, “Control-oriented system identi- fication: Classical, learning, and physics-informed approaches,” 2025, arXiv:2512.06315
arXiv 2025
-
[4]
En- coding physics to learn reaction–diffusion processes,
C. Rao, P. Ren, Q. Wang, O. Buyukozturk, H. Sun, and Y . Liu, “En- coding physics to learn reaction–diffusion processes,”Nature Machine Intelligence, vol. 5, pp. 765–779, 2023
2023
-
[5]
Physics–guided neural net- works for inversion–based feedforward control applied to linear motors,
M. Bolderman, M. Lazar, and H. Butler, “Physics–guided neural net- works for inversion–based feedforward control applied to linear motors,” inProceedings of the IEEE Conference on Control Technology and Applications (CCTA), 2021, pp. 1115–1120
2021
-
[6]
On feedforward control using physics–guided neural networks: Training cost regularization and optimized initialization,
——, “On feedforward control using physics–guided neural networks: Training cost regularization and optimized initialization,” in2022 Euro- pean Control Conference (ECC), 2022, pp. 1403–1408
2022
-
[7]
Physics-guided machine learning for scientific discov- ery: An application in simulating lake temperature profiles,
X. Jia, J. D. Willard, A. Karpatne, J. S. Read, J. A. Zwart, M. Steinbach, and V . Kumar, “Physics-guided machine learning for scientific discov- ery: An application in simulating lake temperature profiles,”ACM/IMS Transactions on Data Science, vol. 2, no. 3, pp. 20–26, 2021
2021
-
[8]
Response estimation and system identification of dynamical systems via physics-informed neural networks,
M. Haywood-Alexander, G. Arcieri, A. Kamariotis, and E. Chatzi, “Response estimation and system identification of dynamical systems via physics-informed neural networks,”Advanced Modeling and Simulation in Engineering Sciences, vol. 12, 2025
2025
-
[9]
Physics-informed machine learning: A comprehensive review on applications in anomaly detection and condition monitoring,
Y . Wu, B. Sicard, and S. A. Gadsden, “Physics-informed machine learning: A comprehensive review on applications in anomaly detection and condition monitoring,”Expert Systems with Applications, vol. 255, p. 124678, 2024
2024
-
[10]
Physics guided neural networks with knowledge graph,
K. D. Gupta, S. Siddique, R. George, M. Kamal, R. H. Rifat, and M. A. Haque, “Physics guided neural networks with knowledge graph,”Digital, vol. 4, no. 4, pp. 846–865, 2024
2024
-
[11]
Robustness of physics-informed neural networks to noise in sensor data,
J. C. Wong, P.-H. Chiu, C. C. Ooi, and M. H. Da, “Robustness of physics-informed neural networks to noise in sensor data,”arXiv preprint arXiv:2211.12042, 2022
arXiv 2022
-
[12]
The strength of weak learnability,
R. E. Schapire, “The strength of weak learnability,”Machine Learning, vol. 5, pp. 197–227, 1990
1990
-
[13]
Greedy function approximation: A gradient boosting machine,
J. H. Friedman, “Greedy function approximation: A gradient boosting machine,”The Annals of Statistics, vol. 29, no. 5, pp. 1189–1232, 2001
2001
-
[14]
A. A. Rusu, N. C. Rabinowitz, G. Desjardins, H. Soyer, J. Kirkpatrick, K. Kavukcuoglu, R. Pascanu, and R. Hadsell, “Progressive neural networks,” 2016, arXiv:1606.04671
Pith/arXiv arXiv 2016
-
[15]
Overcoming catastrophic forgetting in neural networks,
J. Kirkpatrick, R. Pascanu, N. Rabinowitz, J. Veness, G. Desjardins, A. A. Rusu, K. Milan, J. Quan, T. Ramalho, A. Grabska-Barwinska, D. Hassabis, C. Clopath, D. Kumaran, and R. Hadsell, “Overcoming catastrophic forgetting in neural networks,”Proceedings of the National Academy of Sciences, vol. 114, no. 13, pp. 3521–3526, 2017
2017
-
[16]
Regularization of linear regression models,
G. Pillonetto, T. Chen, A. Chiuso, G. De Nicolao, and L. Ljung, “Regularization of linear regression models,” inRegularized System Identification, ser. Communications and Control Engineering. Springer, Cham, 2022
2022
-
[17]
S. A. Billings,Nonlinear System Identification: NARMAX Methods in the Time, Frequency, and Spatio-Temporal Domains. John Wiley & Sons, 2013
2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.