IMPose: Interactive Multi-person Pose Estimation with Dynamic Correction Propagation
Pith reviewed 2026-06-28 06:59 UTC · model grok-4.3
The pith
Sparse human corrections on one frame propagate into full multi-person video pose trajectories via dual-level tracking and a trajectory bank.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
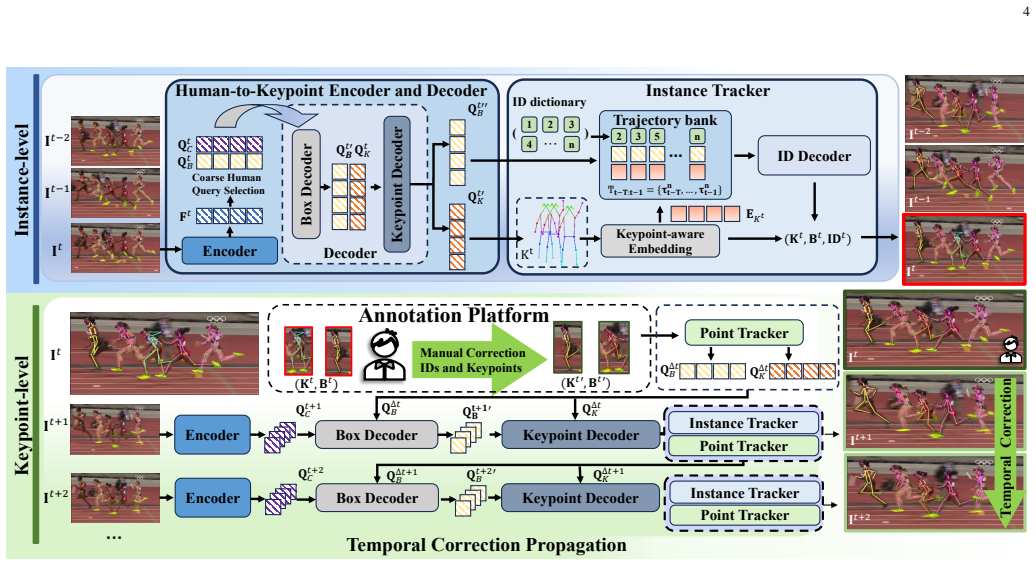
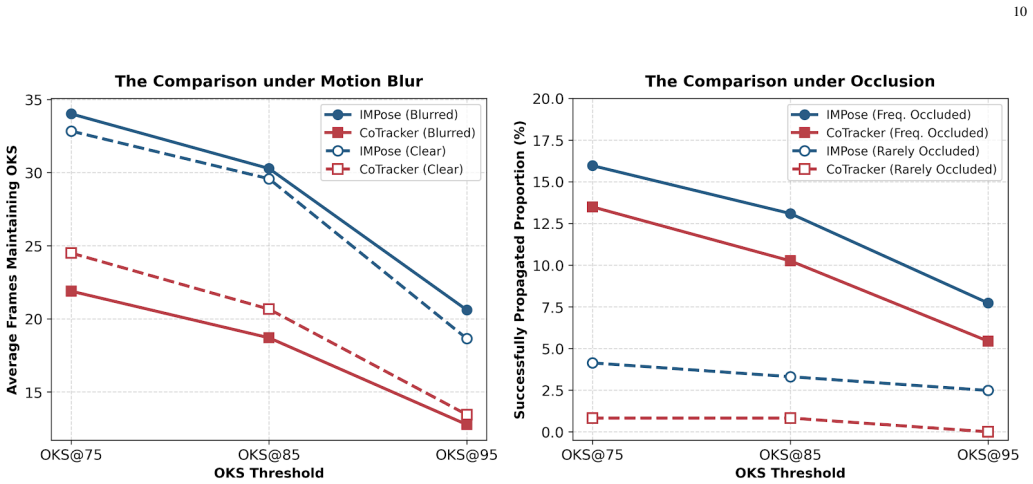
IMPose features a dual-level tracking mechanism that propagates one-frame multi-person pose corrections from annotators across entire videos. The keypoint-level ensures corrections temporal propagation via sequential modeling, while the instance-level employs keypoint-aware embedding with relative positional encoding to maintain multi-person cross-frame consistency. To further improve robustness, IMPose maintains historical pose and instance cues in a trajectory bank, which enhances long-range temporal association and stabilizes annotation in challenging cases such as occlusion and motion blur.
What carries the argument
Dual-level tracking mechanism (keypoint-level sequential modeling plus instance-level keypoint-aware embedding with relative positional encoding) combined with a trajectory bank that stores historical pose and instance cues.
If this is right
- High precision annotation requires only 27 clicks per 1,050 frame video on 3DPW.
- Annotation needs only 3 clicks per tracklet per 84-frame sequence on PoseTrack21.
- The system achieves a strong accuracy-efficiency tradeoff under varying interaction budgets.
- PoseTrack21 can be expanded by 188K pose instances (3.55M keypoints) at minimal annotator cost.
Where Pith is reading between the lines
- The trajectory bank approach could be adapted to annotate other time-varying signals such as hand gestures or object trajectories in video.
- Combining the propagation step with an initial automated pose estimator might lower the click count even further in practice.
- The same correction-propagation logic could support annotation of 3D poses if the underlying 2D tracker is replaced by a depth-aware model.
Load-bearing premise
The dual-level tracking mechanism and trajectory bank maintain cross-frame consistency and robustness under occlusion and motion blur without introducing systematic errors.
What would settle it
Run the system on a held-out video sequence containing repeated occlusions and motion blur, apply the reported low number of corrections, and measure whether the output poses deviate systematically from independent manual ground truth.
Figures






read the original abstract
High-quality dynamic human pose annotation equips AI with precise motion kinematics to enable human behavior mastery, yet remains labor-intensive and time-consuming. Current annotation tools either lack temporal correction propagation or fail in multi-person scenarios, necessitating excessive manual intervention. In this paper, we introduce IMPose, an interactive tool for multi-person dynamic pose annotation. It features a dual-level tracking mechanism that propagates one-frame multi-person pose corrections from annotators across entire videos. The keypoint-level ensures corrections temporal propagation via sequential modeling, while the instance-level employs keypoint-aware embedding with relative positional encoding to maintain multi-person cross-frame consistency. To further improve robustness, IMPose maintains historical pose and instance cues in a trajectory bank, which enhances long-range temporal association and stabilizes annotation in challenging cases such as occlusion and motion blur. By converting sparse human corrections into dense and coherent pose trajectories, our framework significantly reduces repeated manual refinement across frames. Extensive experiments show that IMPose consistently achieves a strong accuracy efficiency trade off under different interaction budgets, demonstrating particular advantages in low click annotation settings. IMPose achieves high precision annotation with high efficiency, requiring only 27 clicks per 1,050 frame video on 3DPW and 3 clicks per tracklet per 84-frame on PoseTrack21. We further expand PoseTrack21 with 188K pose instances (3.55M keypoints) at a minimal cost of 10 annotators in 10 hours. The annotation tool, codes, and extended dataset will be open-sourced.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents IMPose, an interactive tool for multi-person dynamic pose annotation in videos. It introduces a dual-level tracking mechanism—keypoint-level sequential modeling to propagate corrections temporally and instance-level keypoint-aware embedding with relative positional encoding to maintain cross-frame consistency—augmented by a trajectory bank that stores historical pose and instance cues for long-range association and robustness under occlusion or motion blur. The central claim is that sparse human corrections are converted into dense, coherent pose trajectories, yielding high efficiency (27 clicks per 1,050-frame video on 3DPW; 3 clicks per tracklet per 84-frame sequence on PoseTrack21) while enabling expansion of PoseTrack21 by 188K pose instances.
Significance. If the propagation mechanism functions without systematic error accumulation, the work would meaningfully reduce annotation labor for multi-person video pose data, supporting larger-scale datasets for human motion analysis with particular value in low-click regimes.
major comments (2)
- [Abstract] Abstract: the efficiency claims (27 clicks / 1,050 frames on 3DPW; 3 clicks per tracklet on PoseTrack21) rest on the trajectory bank and dual-level tracking converting one-frame corrections into coherent trajectories without introducing new errors that would require extra clicks, yet no description is given of conflict-resolution rules, bank-update logic under occlusion, or recovery from early mis-association.
- [Abstract] Abstract: the instance-level keypoint-aware embedding with relative positional encoding is asserted to maintain multi-person consistency, but without equations, algorithmic pseudocode, or ablation on how embeddings are updated or how the bank resolves conflicting corrections, the robustness claim under motion blur and occlusion cannot be evaluated.
minor comments (1)
- [Abstract] Abstract: the phrase 'strong accuracy efficiency trade off' is imprecise; the manuscript should state the concrete accuracy metric (e.g., MPJPE, PCK) and efficiency metric used to support the claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater transparency on the internal mechanisms supporting our efficiency claims. We agree that the abstract is overly concise and will revise it to include brief descriptions of the requested logic while expanding the methods section with equations, pseudocode, and targeted ablations. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the efficiency claims (27 clicks / 1,050 frames on 3DPW; 3 clicks per tracklet on PoseTrack21) rest on the trajectory bank and dual-level tracking converting one-frame corrections into coherent trajectories without introducing new errors that would require extra clicks, yet no description is given of conflict-resolution rules, bank-update logic under occlusion, or recovery from early mis-association.
Authors: We acknowledge that the abstract does not elaborate on these operational details. The full manuscript describes the dual-level propagation and trajectory bank in the methods, but we agree the abstract should be expanded to note the conflict-resolution rules (prioritizing recent corrections) and bank-update logic (keypoint-level sequential updates with instance-level re-association under occlusion). We will add a short clause to the abstract and include pseudocode for mis-association recovery in the revision. revision: yes
-
Referee: [Abstract] Abstract: the instance-level keypoint-aware embedding with relative positional encoding is asserted to maintain multi-person consistency, but without equations, algorithmic pseudocode, or ablation on how embeddings are updated or how the bank resolves conflicting corrections, the robustness claim under motion blur and occlusion cannot be evaluated.
Authors: The abstract summarizes the embedding approach without technical specifics. We will revise the abstract to reference the embedding update rule and add the requested equations for keypoint-aware embedding with relative positional encoding, pseudocode for bank conflict resolution, and an ablation study quantifying robustness under motion blur and occlusion to the experiments section. revision: yes
Circularity Check
No circularity; empirical results independent of derivation
full rationale
The paper describes an engineering system for interactive pose annotation via dual-level tracking and a trajectory bank. All performance numbers (27 clicks/1050 frames on 3DPW, 3 clicks/tracklet on PoseTrack21) are stated as outcomes of experiments on external datasets rather than any mathematical prediction, fitted parameter, or first-principles derivation. No equations, self-citations, ansatzes, or uniqueness theorems appear in the supplied text, so no load-bearing step reduces to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Corrections on one frame can be reliably propagated to other frames via sequential modeling and embedding without drift
Reference graph
Works this paper leans on
-
[1]
Advanced auto labeling solution with added features,
W. Wang, “Advanced auto labeling solution with added features,” CVHub, 2023, https://github.com/CVHub520/X-AnyLabeling
2023
-
[2]
Effective whole-body pose estimation with two-stages distillation,
Z. Yang, A. Zeng, C. Yuan, and Y . Li, “Effective whole-body pose estimation with two-stages distillation,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023, pp. 4210– 4220
2023
-
[3]
Simple online and realtime tracking with a deep association metric,
N. Wojke, A. Bewley, and D. Paulus, “Simple online and realtime tracking with a deep association metric,” in2017 IEEE International Conference on Image Processing (ICIP). IEEE, 2017, pp. 3645–3649
2017
-
[4]
Video-based human pose regression via decoupled space-time aggregation,
J. He and W. Yang, “Video-based human pose regression via decoupled space-time aggregation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2024, pp. 1022–1031
2024
-
[5]
High-resolution spatiotemporal modeling with global-local state space models for video-based human pose estimation,
R. Feng, H. J. Chang, T. H. E. Tse, B. Kim, Y . Chang, and Y . Gao, “High-resolution spatiotemporal modeling with global-local state space models for video-based human pose estimation,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025, pp. 8929–8938
2025
-
[6]
Causal- inspired multitask learning for video-based human pose estimation,
H. Chen, S. Wu, Z. Wang, Y . Yin, Y . Jiao, Y . Lyu, and Z. Liu, “Causal- inspired multitask learning for video-based human pose estimation,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 2, 2025, pp. 2052–2060
2025
-
[7]
Alphapose: Whole-body regional multi-person pose estimation and tracking in real-time,
H.-S. Fang, J. Li, H. Tang, C. Xu, H. Zhu, Y . Xiu, Y .-L. Li, and C. Lu, “Alphapose: Whole-body regional multi-person pose estimation and tracking in real-time,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022
2022
-
[8]
A gated attention transformer for multi- person pose tracking,
A. Doering and J. Gall, “A gated attention transformer for multi- person pose tracking,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023, pp. 3189–3198
2023
-
[9]
Neural interac- tive keypoint detection,
J. Yang, A. Zeng, F. Li, S. Liu, R. Zhang, and L. Zhang, “Neural interac- tive keypoint detection,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023, pp. 15 122–15 132
2023
-
[10]
ipose: Interactive human pose reconstruction from video,
J. Liu, L.-Y . Wei, A. Shamir, and T. Igarashi, “ipose: Interactive human pose reconstruction from video,” inProceedings of the 2024 CHI Conference on Human Factors in Computing Systems, 2024, pp. 1–14
2024
-
[11]
Cotracker3: Simpler and better point tracking by pseudo- labelling real videos,
N. Karaev, Y . Makarov, J. Wang, N. Neverova, A. Vedaldi, and C. Rupprecht, “Cotracker3: Simpler and better point tracking by pseudo- labelling real videos,” inarXiv:2410.11831, 2024
arXiv 2024
-
[12]
Recovering accurate 3d human pose in the wild using imus and a moving camera,
T. V on Marcard, R. Henschel, M. J. Black, B. Rosenhahn, and G. Pons- Moll, “Recovering accurate 3d human pose in the wild using imus and a moving camera,” inProceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 601–617
2018
-
[13]
Posetrack21: A dataset for person search, multi-object tracking and multi-person pose tracking,
A. D ¨oring, D. Chen, S. Zhang, B. Schiele, and J. Gall, “Posetrack21: A dataset for person search, multi-object tracking and multi-person pose tracking,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 20 963–20 972
2022
-
[14]
Effortless data labeling,
N. R. Lab, “Effortless data labeling,”CVHub, 2023, https://github.com/ vietanhdev/anylabeling
2023
-
[15]
Cvat: Computer vision annota- tion tool,
CV AT.ai Corporation and contributors, “Cvat: Computer vision annota- tion tool,” https://github.com/cvat-ai/cvat, 2020
2020
-
[16]
Sam 2: Segment anything in images and videos,
N. Ravi, V . Gabeur, Y .-T. Hu, R. Hu, C. Ryali, T. Ma, H. Khedr, R. R¨adle, C. Rolland, L. Gustafsonet al., “Sam 2: Segment anything in images and videos,”arXiv preprint arXiv:2408.00714, 2024
Pith/arXiv arXiv 2024
-
[17]
Deep high-resolution repre- sentation learning for human pose estimation,
K. Sun, B. Xiao, D. Liu, and J. Wang, “Deep high-resolution repre- sentation learning for human pose estimation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 5693–5703
2019
-
[18]
Vitpose: Simple vision transformer baselines for human pose estimation,
Y . Xu, J. Zhang, Q. Zhang, and D. Tao, “Vitpose: Simple vision transformer baselines for human pose estimation,” inAdvances in Neural Information Processing Systems, vol. 35, 2022, pp. 38 571–38 584
2022
-
[19]
Realtime multi-person 2d pose estimation using part affinity fields,
Z. Cao, T. Simon, S.-E. Wei, and Y . Sheikh, “Realtime multi-person 2d pose estimation using part affinity fields,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 7291–7299
2017
-
[20]
Associative embedding: End-to- end learning for joint detection and grouping,
A. Newell, Z. Huang, and J. Deng, “Associative embedding: End-to- end learning for joint detection and grouping,” inAdvances in Neural Information Processing Systems, vol. 30, 2017
2017
-
[21]
Pifpaf: Composite fields for human pose estimation,
S. Kreiss, L. Bertoni, and A. Alahi, “Pifpaf: Composite fields for human pose estimation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 11 977–11 986
2019
-
[22]
Posetrack: Joint multi-person pose estimation and tracking,
U. Iqbal, A. Milan, and J. Gall, “Posetrack: Joint multi-person pose estimation and tracking,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 2011–2020
2017
-
[23]
Detect-and-track: Efficient pose estimation in videos,
R. Girdhar and D. Ramanan, “Detect-and-track: Efficient pose estimation in videos,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 350–359
2017
-
[24]
Human pose estimation in video with temporal context,
G. Bertasius and L. Torresani, “Human pose estimation in video with temporal context,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 493–502
2019
-
[25]
Posetrack21: A dataset for person search, multi-object tracking and multi-person pose tracking,
A. Doering, D. Chen, S. Zhang, B. Schiele, and J. Gall, “Posetrack21: A dataset for person search, multi-object tracking and multi-person pose tracking,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 20 963–20 972
2022
-
[26]
3d human pose estimation in video with temporal convolutions and semi-supervised training,
D. Pavllo, C. Feichtenhofer, D. Grangier, and M. Auli, “3d human pose estimation in video with temporal convolutions and semi-supervised training,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 7753–7762
2019
-
[27]
Human pose regression with residual log-likelihood estimation,
J. Li, S. Bian, A. Zeng, C. Wang, B. Pang, W. Liu, and C. Lu, “Human pose regression with residual log-likelihood estimation,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 11 025–11 034
2021
-
[28]
Poseur: Direct human pose regression with transformers,
W. Mao, Y . Ge, C. Shen, Z. Tian, X. Wang, Z. Wang, and A. Van Den Hengel, “Poseur: Direct human pose regression with transformers,” inEuropean Conference on Computer Vision. Springer, 2022, pp. 72– 88. 14
2022
-
[29]
Pose flow: Efficient online pose tracking,
Y . Xiu, J. Li, H. Wang, H.-S. Fang, and C. Lu, “Pose flow: Efficient online pose tracking,” inProceedings of the British Machine Vision Conference, 2018
2018
-
[30]
Rescaling egocentric vision: Collection, pipeline and challenges for epic-kitchens- 100,
D. Damen, H. Doughty, G. M. Farinella, A. Furnari, J. Ma, E. Kazakos, D. Moltisanti, J. Munro, T. Perrett, W. Price, and M. Wray, “Rescaling egocentric vision: Collection, pipeline and challenges for epic-kitchens- 100,”International Journal of Computer Vision, vol. 130, p. 33–55,
-
[31]
Available: https://doi.org/10.1007/s11263-021-01531-2
[Online]. Available: https://doi.org/10.1007/s11263-021-01531-2
-
[32]
Epic-kitchens visor benchmark: Video segmentations and object relations,
A. Darkhalil, D. Shan, B. Zhu, J. Ma, A. Kar, R. Higgins, S. Fidler, D. Fouhey, and D. Damen, “Epic-kitchens visor benchmark: Video segmentations and object relations,”Advances in Neural Information Processing Systems, pp. 13 745–13 758, 2022
2022
-
[33]
Posefix: Model-agnostic general human pose refinement network,
G. Moon, J. Y . Chang, and K. M. Lee, “Posefix: Model-agnostic general human pose refinement network,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 7773–7781
2019
-
[34]
Fairmot: On the fairness of detection and re-identification in multiple object tracking,
Y . Zhang, C. Wang, X. Wang, W. Zeng, and W. Liu, “Fairmot: On the fairness of detection and re-identification in multiple object tracking,” International Journal of Computer Vision, vol. 129, pp. 3069–3087, 2021
2021
-
[35]
Bot-sort: Robust associa- tions multi-pedestrian tracking,
N. Aharon, R. Orfaig, and B.-Z. Bobrovsky, “Bot-sort: Robust associa- tions multi-pedestrian tracking,”arXiv preprint arXiv:2206.14651, 2022
arXiv 2022
-
[36]
Deformable detr: Deformable transformers for end-to-end object detection,
X. Zhu, W. Su, L. Lu, B. Li, X. Wang, and J. Dai, “Deformable detr: Deformable transformers for end-to-end object detection,”arXiv preprint arXiv:2010.04159, 2020
Pith/arXiv arXiv 2010
-
[37]
Dino: Detr with improved denoising anchor boxes for end-to- end object detection,
H. Zhang, F. Li, S. Liu, L. Zhang, H. Su, J. Zhu, L. M. Ni, and H.-Y . Shum, “Dino: Detr with improved denoising anchor boxes for end-to- end object detection,”arXiv preprint arXiv:2203.03605, 2022
Pith/arXiv arXiv 2022
-
[38]
Multiple object tracking as id predic- tion,
R. Gao, J. Qi, and L. Wang, “Multiple object tracking as id predic- tion,” inProceedings of the Computer Vision and Pattern Recognition Conference (CVPR), 2025, pp. 27 883–27 893
2025
-
[39]
Hota: A higher order metric for evaluating multi-object tracking,
J. Luiten, A. Osep, P. Dendorfer, P. Torr, A. Geiger, L. Leal-Taix ´e, and B. Leibe, “Hota: A higher order metric for evaluating multi-object tracking,”International Journal of Computer Vision, vol. 129, no. 2, pp. 548–578, 2021
2021
-
[40]
Memotr: Long-term memory-augmented trans- former for multi-object tracking,
R. Gao and L. Wang, “Memotr: Long-term memory-augmented trans- former for multi-object tracking,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023, pp. 9901– 9910
2023
-
[41]
Microsoft coco: Common objects in context,
T.-Y . Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Doll ´ar, and C. L. Zitnick, “Microsoft coco: Common objects in context,” inProceedings of the European conference on computer vision (ECCV). Springer, 2014, pp. 740–755
2014
-
[42]
Bridging the gap between end-to-end and non-end-to-end multi-object tracking,
F. Yan, W. Luo, Y . Zhong, Y . Gan, and L. Ma, “Bridging the gap between end-to-end and non-end-to-end multi-object tracking,”arXiv preprint arXiv:2305.12724, 2023
arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.