CoRe-MoE: Contrastive Reweighted Mixture of Experts for Multi-Terrain Humanoid Locomotion with Gait Adaptation
Pith reviewed 2026-06-28 06:30 UTC · model grok-4.3
The pith
A two-stage contrastive MoE framework decouples gait generation from terrain adaptation to unify stable locomotion policies for humanoids.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
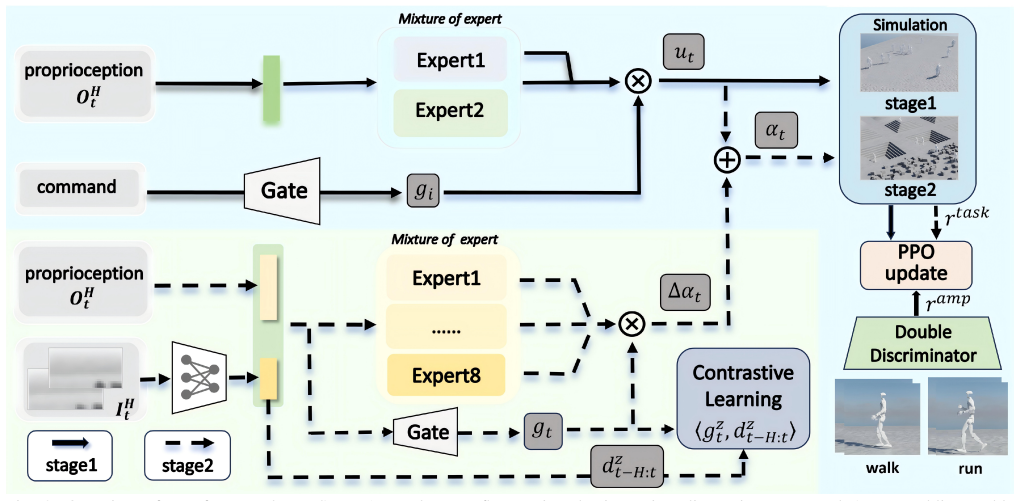
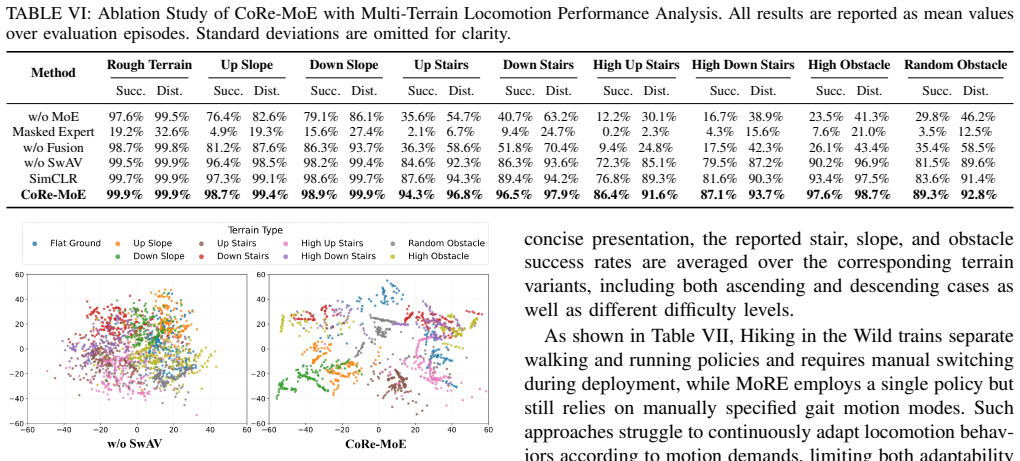
The authors claim that decoupling gait generation from terrain adaptation in a two-stage process, with contrastive training of the gating network in the second-stage terrain-aware MoE branch, produces clear expert specialization that avoids interference; the resulting weighted fusion of the base gait policy and terrain branch yields a policy that maintains natural locomotion while adapting to complex terrains.
What carries the argument
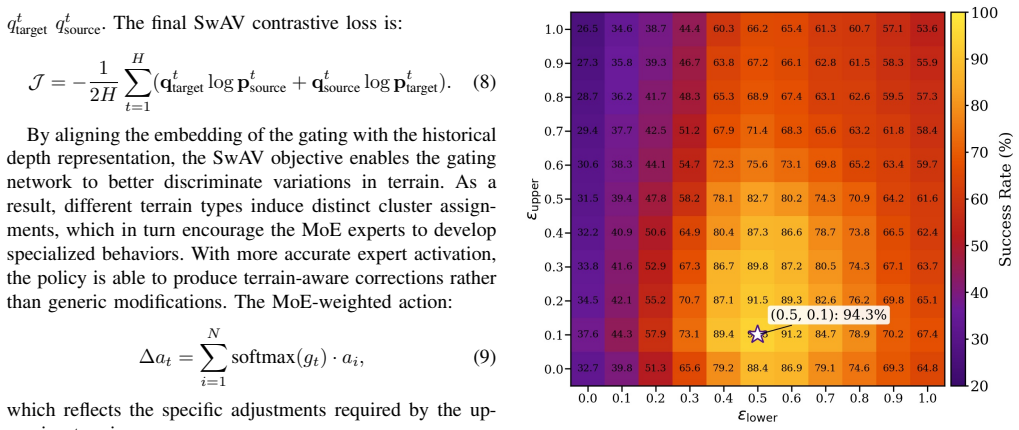
The contrastive objective on the gating network of the terrain-aware MoE branch, which learns structured terrain representations to drive expert specialization.
If this is right
- The method outperforms baseline approaches in success rate, locomotion stability, and multi-terrain adaptability in simulation.
- Zero-shot real-robot deployment produces robust walking and running with accurate foothold control and dynamic stability across stairs, slopes, steps, obstacles, and unstructured terrains.
- Smooth transitions between walking and running gaits are preserved while terrain adaptation occurs.
- The weighted fusion mechanism keeps the base policy's stable behaviors intact during terrain changes.
Where Pith is reading between the lines
- Similar two-stage decoupling with contrastive gating could extend to other robot policies that combine locomotion with manipulation or navigation skills.
- The learned terrain representations might support generalization to entirely novel surface types without additional fine-tuning.
- If expert specialization holds, the approach could scale to higher-dimensional control problems where multiple skills compete during training.
Load-bearing premise
The contrastive objective alone on the gating network will produce clear expert specialization and prevent gradient interference between gait and terrain tasks without extra regularization or constraints.
What would settle it
A direct measurement showing that the MoE experts exhibit similar activation patterns across different terrains rather than distinct specialization, or that the full policy shows no gain over a single-policy baseline on held-out terrain sequences in simulation or real deployment.
Figures




read the original abstract
Humans primarily rely on walking and running to traverse complex terrains. Similarly, humanoid robots should be able to smoothly transition between walking and running while maintaining natural and stable locomotion. However, unifying gait transition and multi-terrain adaptation within a single policy remains challenging due to gradient interference between tasks and the distribution shift caused by terrain variations. Although Mixture-of-Experts (MoE) architectures can mitigate multi-skill interference, direct joint training often fails to achieve clear expert specialization. To address these challenges, we propose CoRe-MoE, a two-stage reinforcement learning framework that decouples gait generation from terrain adaptation. In the first stage, a stable locomotion policy is learned to produce natural walking and running behaviors with smooth transitions. In the second stage, a terrain-aware MoE branch is introduced, and the gating network is trained with a contrastive objective to learn structured terrain representations and promote expert specialization. The final action is obtained through weighted fusion of the base gait policy and the terrain-aware branch, enabling the policy to preserve stable locomotion while adapting to complex terrains. Extensive simulation results demonstrate that the proposed method outperforms baseline approaches in terms of success rate, locomotion stability, and multi-terrain adaptability. Furthermore, zero-shot deployment on a Unitree G1 humanoid robot validates the effectiveness of our framework, achieving robust walking and running across stairs, slopes, steps, obstacles, and unstructured outdoor terrains while maintaining accurate foothold control and dynamic stability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
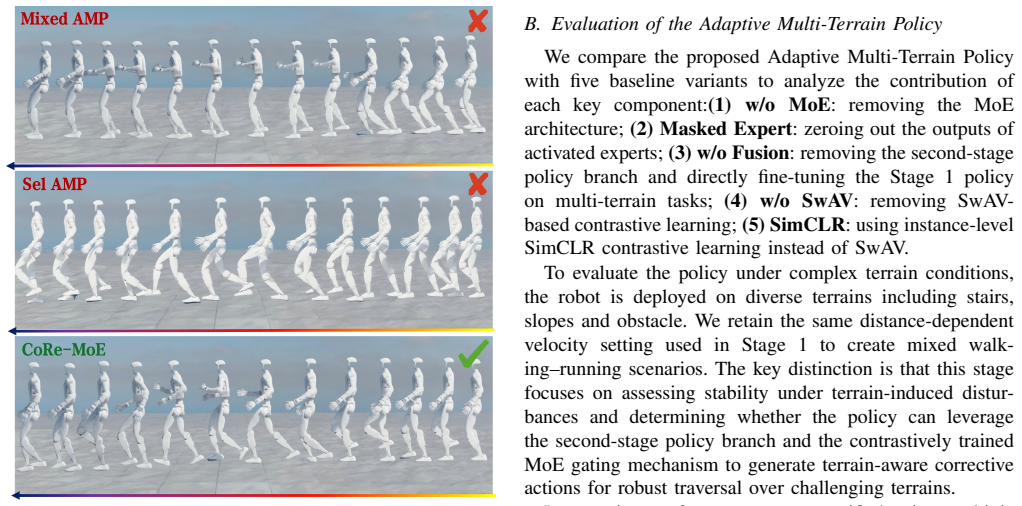
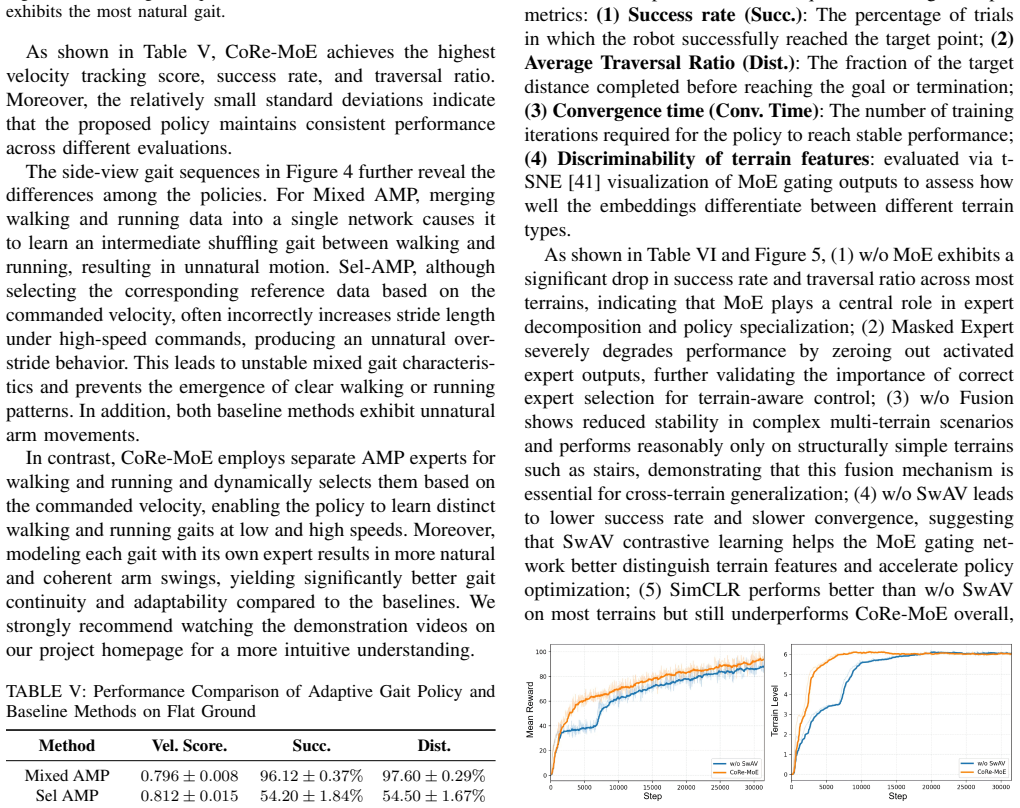
Summary. The paper proposes CoRe-MoE, a two-stage reinforcement learning framework for multi-terrain humanoid locomotion that first learns a stable base policy for walking/running gait generation and transitions, then augments it with a terrain-aware Mixture-of-Experts branch whose gating network is trained via a contrastive objective to promote expert specialization and mitigate gradient interference. The final policy fuses the base gait output with the terrain branch. The central claims are that this yields higher success rates, stability, and adaptability than baselines in simulation, plus successful zero-shot transfer to a Unitree G1 robot across stairs, slopes, steps, obstacles, and outdoor terrain while preserving foothold control and dynamic stability.
Significance. If the empirical claims are substantiated with quantitative metrics, ablations, and statistical analysis, the two-stage contrastive-MoE design could offer a practical route to decoupling gait and terrain adaptation in humanoid control, addressing a recognized source of training instability in multi-skill policies. The zero-shot real-robot results, if reproducible, would strengthen the case for sim-to-real transfer in unstructured environments.
major comments (3)
- [Abstract] Abstract: the central claim of outperformance over baselines in success rate, locomotion stability, and multi-terrain adaptability is stated without any numerical values, baseline descriptions, ablation results, or statistical details; this absence prevents verification that the two-stage procedure plus contrastive gating objective actually produces the reported gains.
- [Method] Method description (two-stage procedure and contrastive objective): no equations, hyper-parameter values, or activation statistics are supplied to show that the contrastive loss on the gating network yields measurable expert specialization or reduces interference between gait and terrain tasks; without such evidence the weakest assumption (that the contrastive term suffices without further regularization) remains untested.
- [Experiments] Experiments section: the real-robot validation claim (robust walking/running on Unitree G1 across multiple terrain types) is presented without quantitative metrics, failure-mode analysis, or comparison to the simulation baselines, rendering the zero-shot transfer result impossible to assess for robustness or statistical significance.
minor comments (1)
- [Method] Notation for the weighted fusion of base gait policy and terrain-aware branch is introduced without an explicit equation or diagram clarifying the combination rule.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies key areas for improving the clarity and empirical substantiation of our claims. We address each major comment below and outline the planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of outperformance over baselines in success rate, locomotion stability, and multi-terrain adaptability is stated without any numerical values, baseline descriptions, ablation results, or statistical details; this absence prevents verification that the two-stage procedure plus contrastive gating objective actually produces the reported gains.
Authors: We agree that the abstract would be strengthened by including specific numerical results. In the revised manuscript, we will update the abstract to report key quantitative metrics, such as success rates and stability improvements relative to baselines, drawn from the simulation experiments. revision: yes
-
Referee: [Method] Method description (two-stage procedure and contrastive objective): no equations, hyper-parameter values, or activation statistics are supplied to show that the contrastive loss on the gating network yields measurable expert specialization or reduces interference between gait and terrain tasks; without such evidence the weakest assumption (that the contrastive term suffices without further regularization) remains untested.
Authors: We will revise the methods section to explicitly include the equations for the contrastive objective, the hyperparameter values used during training, and activation statistics or gating analysis demonstrating expert specialization and reduced interference. revision: yes
-
Referee: [Experiments] Experiments section: the real-robot validation claim (robust walking/running on Unitree G1 across multiple terrain types) is presented without quantitative metrics, failure-mode analysis, or comparison to the simulation baselines, rendering the zero-shot transfer result impossible to assess for robustness or statistical significance.
Authors: We acknowledge the value of quantitative metrics for the real-robot results. The current manuscript relies on qualitative observations and video evidence. We will add a failure-mode analysis based on observed behaviors and note limitations relative to simulation baselines, but quantitative metrics and statistical tests were not collected during hardware deployment. revision: partial
- Providing quantitative metrics or statistical significance analysis for the real-robot zero-shot transfer experiments, as no such numerical data was recorded during the Unitree G1 deployments.
Circularity Check
Empirical RL framework with no derivational chain
full rationale
The paper describes a two-stage reinforcement learning procedure that trains a base gait policy followed by a terrain-aware MoE branch with an added contrastive loss on the gating network. All performance claims rest on simulation benchmarks and zero-shot hardware deployment rather than any closed-form derivation, uniqueness theorem, or parameter fit that is then re-labeled as a prediction. No equations appear in the provided text that would allow a reduction of outputs to inputs by construction, and no self-citations are invoked as load-bearing mathematical facts. The work is therefore self-contained as an empirical engineering contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Pie: Parkour with implicit-explicit learning framework for legged robots.IEEE Robotics and Automation Letters, 2024
Shixin Luo, Songbo Li, Ruiqi Yu, Zhicheng Wang, Jun Wu, and Qiuguo Zhu. Pie: Parkour with implicit-explicit learning framework for legged robots.IEEE Robotics and Automation Letters, 2024
2024
-
[2]
Dreamwaq++: Obstacle-aware quadrupedal locomotion with resilient multimodal reinforcement learning.IEEE Transactions on Robotics, 42:819–836, 2026
I Made Aswin Nahrendra, Byeongho Yu, Minho Oh, Dongkyu Lee, Seunghyun Lee, Hyeonwoo Lee, Hyungtae Lim, and Hyun Myung. Dreamwaq++: Obstacle-aware quadrupedal locomotion with resilient multimodal reinforcement learning.IEEE Transactions on Robotics, 42:819–836, 2026
2026
-
[3]
Shaoting Zhu, Ziwen Zhuang, Mengjie Zhao, Kun-Ying Lee, and Hang Zhao. Hiking in the wild: A scalable perceptive parkour framework for humanoids.arXiv preprint arXiv:2601.07718, 2026
-
[5]
Adapting humanoid locomotion over challenging terrain via two-phase training
Wenhao Cui, Shengtao Li, Huaxing Huang, Bangyu Qin, Tianchu Zhang, Liang Zheng, Ziyang Tang, Chenxu Hu, NING Yan, Jiahao Chen, et al. Adapting humanoid locomotion over challenging terrain via two-phase training. In8th Annual Conference on Robot Learning, 2024
2024
-
[6]
Beamdojo: Learning agile humanoid locomotion on sparse footholds
Huayi Wang, Zirui Wang, Junli Ren, Qingwei Ben, Tao Huang, Weinan Zhang, and Jiangmiao Pang. Beamdojo: Learning agile humanoid locomotion on sparse footholds. 2025
2025
-
[7]
Learning humanoid locomotion with perceptive internal model, 2024
Junfeng Long, Junli Ren, Moji Shi, Zirui Wang, Tao Huang, Ping Luo, and Jiangmiao Pang. Learning humanoid locomotion with perceptive internal model, 2024
2024
-
[8]
Hybrid internal model: Learning agile legged loco- motion with simulated robot response
Junfeng Long, ZiRui Wang, Quanyi Li, Liu Cao, Jiawei Gao, and Jiangmiao Pang. Hybrid internal model: Learning agile legged loco- motion with simulated robot response. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[9]
A comprehensive survey on gait analysis: History, parameters, approaches, pose estima- tion, and future work.Artificial Intelligence in Medicine, 129:102314, 2022
Dimple Sethi, Sourabh Bharti, and Chandra Prakash. A comprehensive survey on gait analysis: History, parameters, approaches, pose estima- tion, and future work.Artificial Intelligence in Medicine, 129:102314, 2022
2022
-
[10]
E. Y . S. Chao.Biomechanics of the Human Gait, pages 225–244. Springer New York, New York, NY , 1986
1986
-
[11]
More: Mixture of residual experts for humanoid lifelike gaits learning on complex terrains, 2025
Dewei Wang, Xinmiao Wang, Xinzhe Liu, Jiyuan Shi, Yingnan Zhao, Chenjia Bai, and Xuelong Li. More: Mixture of residual experts for humanoid lifelike gaits learning on complex terrains, 2025
2025
-
[12]
Humanoid-gym: Reinforcement learning for humanoid robot with zero-shot sim2real transfer
Xinyang Gu, Yen-Jen Wang, and Jianyu Chen. Humanoid-gym: Reinforcement learning for humanoid robot with zero-shot sim2real transfer. 2024
2024
-
[13]
Blind bipedal stair traversal via sim-to-real reinforcement learning
Jonah Siekmann, Kevin Green, John Warila, Alan Fern, and Jonathan Hurst. Blind bipedal stair traversal via sim-to-real reinforcement learning. 2021
2021
-
[15]
Learning humanoid locomotion over challenging terrain
Ilija Radosavovic, Sarthak Kamat, Trevor Darrell, and Jitendra Malik. Learning humanoid locomotion over challenging terrain. 2024
2024
-
[16]
Adaptive mixtures of local experts.Neural computation, 3(1):79–87, 1991
Robert A Jacobs, Michael I Jordan, Steven J Nowlan, and Geoffrey E Hinton. Adaptive mixtures of local experts.Neural computation, 3(1):79–87, 1991
1991
-
[17]
Moe-loco: Mixture of experts for multitask locomotion
Runhan Huang, Shaoting Zhu, Yilun Du, and Hang Zhao. Moe-loco: Mixture of experts for multitask locomotion. 2025
2025
-
[18]
Deep whole-body parkour, 2026
Ziwen Zhuang, Shaoting Zhu, Mengjie Zhao, and Hang Zhao. Deep whole-body parkour, 2026
2026
-
[19]
Swav: Unsupervised learning of visual features by contrasting cluster assignments
Mathilde Caron, Ishan Misra, Julien Mairal, Piotr Goyal, Piotr Bo- janowski, and Armand Joulin. Swav: Unsupervised learning of visual features by contrasting cluster assignments. 2020
2020
-
[20]
Now you see that: Learning end-to-end humanoid locomotion from raw pixels, 2026
Wandong Sun, Yongbo Su, Leoric Huang, Alex Zhang, Dwyane Wei, Mu San, Daniel Tian, Ellie Cao, Finn Yan, Ethan Xie, and Zongwu Xie. Now you see that: Learning end-to-end humanoid locomotion from raw pixels, 2026
2026
-
[21]
Real-world humanoid locomotion with reinforcement learning.Science Robotics, 9(89):eadi9579, 2024
Ilija Radosavovic, Tete Xiao, Bike Zhang, Trevor Darrell, Jitendra Malik, and Koushil Sreenath. Real-world humanoid locomotion with reinforcement learning.Science Robotics, 9(89):eadi9579, 2024
2024
-
[22]
Jonah Siekmann, Kevin Green, John Warila, Alan Fern, and Jonathan Hurst. Blind bipedal stair traversal via sim-to-real reinforcement learning.arXiv preprint arXiv:2105.08328, 2021
-
[23]
Mingqi Yuan, Tao Yu, Haolin Song, Bo Li, Xin Jin, Hua Chen, and Wenjun Zeng. Pvp: Data-efficient humanoid robot learning with proprioceptive-privileged contrastive representations.arXiv preprint arXiv:2512.13093, 2025
-
[24]
Whole-body humanoid mpc: Realtime physics-based procedural loco-manipulation planning and control
Manuel Yves Galliker. Whole-body humanoid mpc: Realtime physics-based procedural loco-manipulation planning and control. https://github.com/1x-technologies/wb_humanoid_mpc, 2024
2024
-
[25]
Mpc for humanoid gait generation: Stability and feasibility
Nicola Scianca, Daniele De Simone, Leonardo Lanari, and Giuseppe Oriolo. Mpc for humanoid gait generation: Stability and feasibility. IEEE Transactions on Robotics, 36(4):1171–1188, 2020
2020
-
[26]
Model predic- tive control of legged and humanoid robots: models and algorithms
Sotaro Katayama, Masaki Murooka, and Yuichi Tazaki. Model predic- tive control of legged and humanoid robots: models and algorithms. Advanced Robotics, 37(5):298–315, 2023
2023
-
[27]
Gait-adaptive perceptive humanoid locomotion with real time under-base terrain reconstruction
Haolin Song, Hongbo Zhu, Tao Yu, Yan Liu, Mingqi Yuan, Wengang Zhou, Hua Chen, and Houqiang Li. Gait-adaptive perceptive humanoid locomotion with real time under-base terrain reconstruction. 2025
2025
-
[28]
Extreme parkour with legged robots
Xuxin Cheng, Kexin Shi, Ananye Agarwal, and Deepak Pathak. Extreme parkour with legged robots. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 11443–11450. IEEE, 2024
2024
- [29]
-
[30]
Attention-based map encoding for learning generalized legged locomotion.Science Robotics, 10(105):eadv3604, 2025
Junzhe He, Chong Zhang, Fabian Jenelten, Ruben Grandia, Moritz Bächer, and Marco Hutter. Attention-based map encoding for learning generalized legged locomotion.Science Robotics, 10(105):eadv3604, 2025
2025
-
[31]
Qingwei Ben, Botian Xu, Kailin Li, Feiyu Jia, Wentao Zhang, Jingping Wang, Jingbo Wang, Dahua Lin, and Jiangmiao Pang. Gallant: V oxel grid-based humanoid locomotion and local-navigation across 3d constrained terrains.arXiv preprint arXiv:2511.14625, 2025
-
[32]
Learning humanoid locomotion with perceptive internal model
Junfeng Long, Junli Ren, Moji Shi, Zirui Wang, Tao Huang, Ping Luo, and Jiangmiao Pang. Learning humanoid locomotion with perceptive internal model. 2025
2025
- [33]
-
[34]
Jordan and Robert A
Michael I. Jordan and Robert A. Jacobs. Hierarchical mixtures of experts and the em algorithm.Neural Computation, 6(2):181–214, 1994
1994
-
[35]
A Simple Framework for Contrastive Learning of Visual Representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations.arXiv preprint arXiv:2002.05709, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2002
-
[36]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[37]
Amp: Adversarial motion priors for stylized physics-based character control.ACM Transactions on Graphics (ToG), 40(4):1–20, 2021
Xue Bin Peng, Ze Ma, Pieter Abbeel, Sergey Levine, and Angjoo Kanazawa. Amp: Adversarial motion priors for stylized physics-based character control.ACM Transactions on Graphics (ToG), 40(4):1–20, 2021
2021
-
[38]
Isaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
Mayank Mittal, Pascal Roth, James Tigue, et al. Isaac lab: A gpu- accelerated simulation framework for multi-modal robot learning. arXiv preprint arXiv:2511.04831, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Amass: Archive of motion capture as surface shapes
Naureen Mahmood, Nima Ghorbani, Nikolaus F Troje, Gerard Pons- Moll, and Michael J Black. Amass: Archive of motion capture as surface shapes. InProceedings of the IEEE/CVF international conference on computer vision, pages 5442–5451, 2019
2019
-
[40]
Harvey, Mike Yurick, Derek Nowrouzezahrai, and Christo- pher Pal
Félix G. Harvey, Mike Yurick, Derek Nowrouzezahrai, and Christo- pher Pal. Robust motion in-betweening. 39(4), 2020
2020
-
[41]
Cieslak, Ann M
Matthew C. Cieslak, Ann M. Castelfranco, Vittoria Roncalli, Petra H. Lenz, and Daniel K. Hartline. t-distributed stochastic neighbor em- bedding (t-sne): A tool for eco-physiological transcriptomic analysis. Marine Genomics, 51:100723, 2020
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.