Coarse-to-fine Hierarchical Architecture with Sequential Mamba for Brain Reconstruction
Pith reviewed 2026-06-28 06:56 UTC · model grok-4.3
The pith
A dual-stream Mamba model in coarse-to-fine stages predicts fMRI from images and shows causal stream specialization matching visual cortex regions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
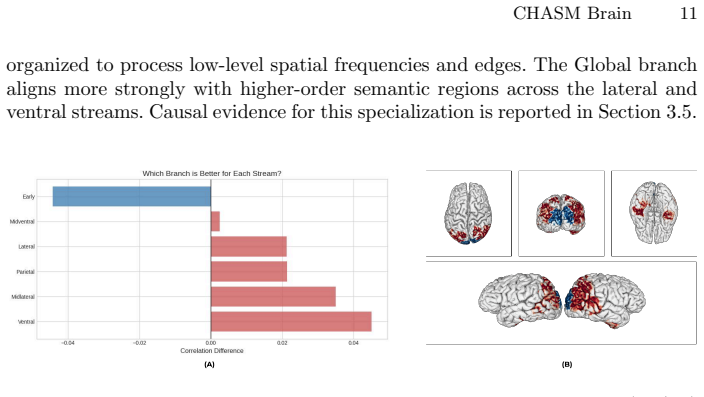
The central claim is that separating semantic and spatial processing into distinct Mamba streams within a coarse-to-fine hierarchy produces stronger image-to-fMRI predictions than prior methods while causally revealing an asymmetric division of labor: the patch stream specializes in early visual cortex and the CLS stream in higher-order areas.
What carries the argument
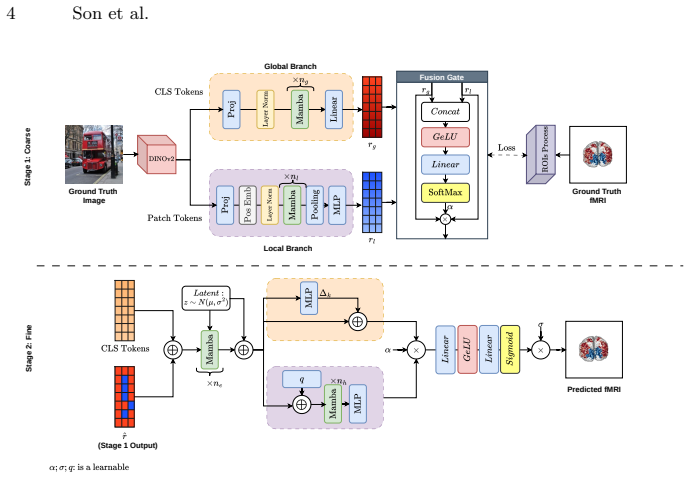
Dual-stream Mamba architecture that routes global CLS tokens through one sequential path and local patch tokens through another, embedded in a two-stage coarse-to-fine pipeline with Mamba-VAE refinement at the second stage.
If this is right
- The architecture reaches Pearson correlation 0.429 and MSE 0.261 on NSD, exceeding ridge regression and DINOv2 linear probes.
- Patch-stream ablation selectively impairs predictions in early retinotopic visual cortex.
- CLS-stream ablation selectively impairs predictions in higher-order semantic areas.
- The learned representation transfers to new subjects with only minimal per-subject fine-tuning.
Where Pith is reading between the lines
- The same dual-stream separation could be tested on other sensory modalities to check whether analogous causal specialization appears.
- If the pattern generalizes, the architecture offers a way to generate testable predictions about information flow between visual areas.
- Cross-subject generalization suggests the streams capture invariants that might be used to align representations across individuals in brain-computer interface settings.
Load-bearing premise
The model design assumes that ablating one stream versus the other can be read as causal evidence of functional specialization rather than simple correlation.
What would settle it
An experiment in which ablating the patch stream does not produce a measurably larger drop in prediction accuracy specifically within retinotopic early visual cortex voxels would falsify the claimed causal specialization.
Figures

read the original abstract
Understanding the relationship between deep visual representations and the human visual system is a fundamental challenge in computational neuroscience. While modern vision models achieve strong performance in image recognition, their correspondence with the hierarchical organization of the human visual cortex remains an open question. In this study, we propose CHASMBrain, a novel hierarchical two-stage framework for image-to-fMRI encoding. Our architecture leverages a dual-stream Mamba design to explicitly separate and process global semantic tokens and local spatial patches, motivated by the functional organization of the visual cortex. A coarse-to-fine strategy is employed: Stage 1 predicts denoised ROI-level activations, while Stage 2 refines these coarse responses into full voxel-level predictions using a Mamba-VAE. Experiments on the Natural Scenes Dataset (NSD) demonstrate that our method achieves a Pearson correlation of 0.429 and an MSE of 0.261, outperforming all evaluated baselines including ridge regression and DINOv2 linear probes. Beyond predictive performance, causal branch-ablation experiments reveal an asymmetric specialization: the patch stream is specifically locked to early visual cortex (retinotopic regions), while the CLS stream contributes broader semantic context to higher-order areas -- a correspondence that holds causally, not merely correlationally. Cross-subject transfer experiments further show that the learned backbone generalizes across individuals with minimal per-subject adaptation, suggesting the model captures a shared, subject-agnostic visual representation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes CHASMBrain, a coarse-to-fine hierarchical two-stage framework for image-to-fMRI encoding that employs a dual-stream Mamba architecture to separately process global semantic (CLS) tokens and local spatial patches. Stage 1 predicts denoised ROI-level activations while Stage 2 refines these into voxel-level predictions via a Mamba-VAE. On the Natural Scenes Dataset (NSD), the method reports a Pearson correlation of 0.429 and MSE of 0.261, outperforming baselines including ridge regression and DINOv2 linear probes. Causal branch-ablation experiments are presented as evidence of asymmetric specialization (patch stream locked to early visual cortex, CLS stream to higher-order areas), with additional results on cross-subject transfer showing generalization with minimal adaptation.
Significance. If the performance and ablation results prove robust under standard validation practices, the work could contribute a new architecture for brain encoding that explicitly incorporates hierarchical and dual-stream processing motivated by visual cortex organization. The reported cross-subject generalization would be a practical strength, and the causal reading of ablations (if substantiated) could offer interpretable insights beyond correlational findings common in the field.
major comments (2)
- [Abstract / Experiments] Abstract and Experiments section: The central performance claims (Pearson r = 0.429, MSE = 0.261, outperformance over ridge regression and DINOv2) are presented without data-split details, subject count, error bars, or statistical testing. These omissions are load-bearing because they prevent assessment of whether the reported gains are reliable or generalizable.
- [Experiments] Experiments section (branch-ablation results): The claim that ablations demonstrate 'causal' rather than correlational specialization is load-bearing for the dual-stream motivation and functional-organization interpretation, yet the protocol for the ablations (how branches are disabled, how 'locked' is quantified, and controls for indirect effects) is not specified in sufficient detail to support the causal language.
minor comments (2)
- [Abstract] The term 'Mamba-VAE' appears without definition or citation; clarify whether it is a novel component or an adaptation of prior Mamba or VAE work.
- [Experiments] Baseline implementation details (e.g., whether ridge regression and DINOv2 probes use identical training data, preprocessing, and hyperparameter search) should be stated explicitly to allow direct comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: The central performance claims (Pearson r = 0.429, MSE = 0.261, outperformance over ridge regression and DINOv2) are presented without data-split details, subject count, error bars, or statistical testing. These omissions are load-bearing because they prevent assessment of whether the reported gains are reliable or generalizable.
Authors: The referee correctly identifies that these specifics are absent from the abstract and main experiments section. In the revision we will add: NSD data splits (standard subject-wise train/test partitions across the 8 subjects), explicit subject count, error bars computed via 5-fold cross-validation, and statistical tests (paired Wilcoxon tests against baselines with p-values). These additions will appear in both the abstract and Experiments section. revision: yes
-
Referee: [Experiments] Experiments section (branch-ablation results): The claim that ablations demonstrate 'causal' rather than correlational specialization is load-bearing for the dual-stream motivation and functional-organization interpretation, yet the protocol for the ablations (how branches are disabled, how 'locked' is quantified, and controls for indirect effects) is not specified in sufficient detail to support the causal language.
Authors: We agree the ablation protocol requires more explicit description to justify the causal phrasing. The revision will expand the Experiments section with: (1) branch disabling via zero-masking of the patch or CLS stream outputs prior to fusion, (2) quantification of 'locked' specialization as the differential drop in voxel-wise Pearson r within early visual cortex (V1–V4) versus higher areas, and (3) control experiments using random feature ablation to isolate indirect effects. We will also moderate the language from 'causal' to 'intervention-based evidence of specialization' if the added controls warrant it. revision: yes
Circularity Check
No significant circularity detected
full rationale
The supplied paper text consists only of the abstract, which reports measured empirical results (Pearson 0.429, MSE 0.261 on NSD) and describes an architecture plus ablation experiments without any equations, derivations, fitted-parameter predictions, or self-citations. No load-bearing step reduces a claimed result to its own inputs by construction, and none of the six enumerated circularity patterns can be exhibited with a direct quote from the text. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The functional organization of the visual cortex separates global semantic processing from local spatial patch processing in a manner that can be directly mapped to dual-stream token and patch streams.
invented entities (1)
-
Mamba-VAE
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Adeli, H., Minni, S., Kriegeskorte, N.: Predicting brain activity using Transformers (Aug 2023).https://doi.org/10.1101/2023.08.02.551743
-
[2]
Nature neuroscience25(1), 116– 126 (2022)
Allen, E.J., St-Yves, G., Wu, Y., Breedlove, J.L., Prince, J.S., Dowdle, L.T., Nau, M., Caron, B., Pestilli, F., Charest, I., et al.: A massive 7t fmri dataset to bridge cognitive neuroscience and artificial intelligence. Nature neuroscience25(1), 116– 126 (2022)
2022
-
[3]
Castello, M.V.d.O., Deniz, F., la Tour, T.D., Gallant, J.L.: Encoding models in functional magnetic resonance imaging: The Voxelwise Encoding Model framework
-
[4]
In: International Conference on Machine Learning (ICML) (2024)
Dao, T., Gu, A.: Transformers are SSMs: Generalized models and efficient al- gorithms through structured state space duality. In: International Conference on Machine Learning (ICML) (2024)
2024
-
[5]
NeuroIm- age152, 184–194 (May 2017).https://doi.org/10.1016/j.neuroimage.2016
Eickenberg, M., Gramfort, A., Varoquaux, G., Thirion, B.: Seeing it all: Convo- lutional network layers map the function of the human visual system. NeuroIm- age152, 184–194 (May 2017).https://doi.org/10.1016/j.neuroimage.2016. 10.001
-
[6]
In: Advances in Neural Information Processing Systems (2019)
Kubilius, J., Schrimpf, M., Kar, K., Rajalingham, R., Hong, H., Majaj, N.J., Issa, E.B., Prescott-Roy, J., Schmidt, K., Nayebi, A., Bear, D., Yamins, D.L.K., Di- Carlo, J.J.: Brain-Like Object Recognition with High-Performing Shallow Recur- rent ANNs. In: Advances in Neural Information Processing Systems (2019)
2019
-
[7]
NeuroImage298, 120772 (Sep 2024).https://doi.org/10.1016/j.neuroimage.2024.120772
Lin, R., Naselaris, T., Kay, K., Wehbe, L.: Stacked regressions and structured variance partitioning for interpretable brain maps. NeuroImage298, 120772 (Sep 2024).https://doi.org/10.1016/j.neuroimage.2024.120772
-
[8]
Lu, H., Zhou, Q., Fei, N., Lu, Z., Ding, M., Wen, J., Du, C., Zhao, X., Sun, H., He, H., Wen, J.R.: Multimodal foundation models are better simulators of the human brain (Aug 2022).https://doi.org/10.48550/arXiv.2208.08263
-
[9]
In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025)
Mai, W., Wu, J., Zhu, Y., Yao, Z., Zhou, D., Luo, A., Zheng, Q., Ouyang, W., Song, C.: Synbrain: Enhancing visual-to-fmri synthesis via probabilistic represen- tation learning. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025)
2025
-
[10]
Oota, S.R., Chen, Z., Gupta, M., Bapi, R.S., Jobard, G., Alexandre, F., Hinaut, X.: Deep Neural Networks and Brain Alignment: Brain Encoding and Decoding (Survey) (Dec 2024).https://doi.org/10.48550/arXiv.2307.10246
-
[11]
Transactions on Ma- chine Learning Research (2024),https://openreview.net/forum?id=a68SUt6zFt, featured Certification
Oquab, M., Darcet, T., Moutakanni, T., Vo, H.V., Szafraniec, M., Khalidov, V., Fernandez, P., HAZIZA, D., Massa, F., El-Nouby, A., Assran, M., Ballas, N., Galuba, W., Howes, R., Huang, P.Y., Li, S.W., Misra, I., Rabbat, M., Sharma, V., Synnaeve, G., Xu, H., Jegou, H., Mairal, J., Labatut, P., Joulin, A., Bojanowski, P.: DINOv2: Learning robust visual feat...
2024
-
[12]
In: Meila, M., Zhang, T
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning transferable visual models from natural language supervision. In: Meila, M., Zhang, T. (eds.) Proceedings of the 38th International Conference on Machine Learning. Proceed- ings of Machine Learning Res...
2021
-
[13]
Cerebral cortex28(9), 3095–3114 (2018) 16 Son et al
Schaefer, A., Kong, R., Gordon, E.M., Laumann, T.O., Zuo, X.N., Holmes, A.J., Eickhoff, S.B., Yeo, B.T.: Local-global parcellation of the human cerebral cortex from intrinsic functional connectivity mri. Cerebral cortex28(9), 3095–3114 (2018) 16 Son et al
2018
-
[14]
Schrimpf, M., Kubilius, J., Hong, H., Majaj, N.J., Rajalingham, R., Issa, E.B., Kar, K., Bashivan, P., Prescott-Roy, J., Geiger, F., Schmidt, K., Yamins, D.L.K., DiCarlo, J.J.: Brain-Score: Which Artificial Neural Network for Object Recognition is most Brain-Like? (Sep 2018).https://doi.org/10.1101/407007
-
[15]
In: Proceedings of the 41st International Conference on Machine Learning
Scotti, P.S., Tripathy, M., Villanueva, C.K.T., Kneeland, R., Chen, T., Narang, A., Santhirasegaran, C., Xu, J., Naselaris, T., Norman, K.A., Abraham, T.M.: Mindeye2: shared-subject models enable fmri-to-image with 1 hour of data. In: Proceedings of the 41st International Conference on Machine Learning. ICML’24, JMLR.org (2024)
2024
-
[16]
NeuroImage180(Pt A), 188–202 (Oct 2018).https://doi.org/10.1016/j.neuroimage.2017.06.035
St-Yves, G., Naselaris, T.: The feature-weighted receptive field: An interpretable encoding model for complex feature spaces. NeuroImage180(Pt A), 188–202 (Oct 2018).https://doi.org/10.1016/j.neuroimage.2017.06.035
-
[17]
In: Advances in Neural Information Processing Systems
Wang, A., Tarr, M., Wehbe, L.: Neural Taskonomy: Inferring the Similarity of Task- Derived Representations from Brain Activity. In: Advances in Neural Information Processing Systems. vol. 32. Curran Associates, Inc. (2019).https://doi.org/10. 1101/708016
2019
-
[18]
Wen, H., Shi, J., Zhang, Y., Lu, K.H., Cao, J., Liu, Z.: Neural Encoding and Decod- ing with Deep Learning for Dynamic Natural Vision. Cerebral Cortex (New York, NY)28(12), 4136–4160 (Dec 2018).https://doi.org/10.1093/cercor/bhx268
-
[19]
In: Yue, Y., Garg, A., Peng, N., Sha, F., Yu, R
Zhang, Q., Gong, Z., Wu, Z., Miao, D.: Mindsimulator: Exploring brain concept localization via synthetic fmri. In: Yue, Y., Garg, A., Peng, N., Sha, F., Yu, R. (eds.) International Conference on Learning Representations. vol. 2025, pp. 76781–76803 (2025),https://proceedings.iclr.cc/paper_files/paper/2025/ file/bf121b033db3bac31c3193e8a0dcbf66-Paper-Conference.pdf
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.