STaR-Quant: State-Time Consistent Post-Training Quantization for Diffusion Large Language Models
Pith reviewed 2026-06-28 07:12 UTC · model grok-4.3
The pith
STaR-Quant corrects state-dependent activation differences and temporal error buildup to enable accurate low-bit quantization of diffusion language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
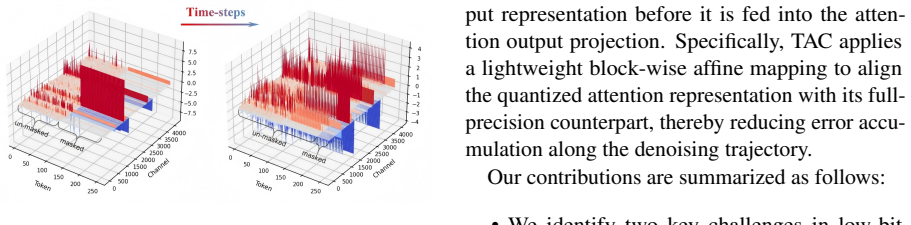
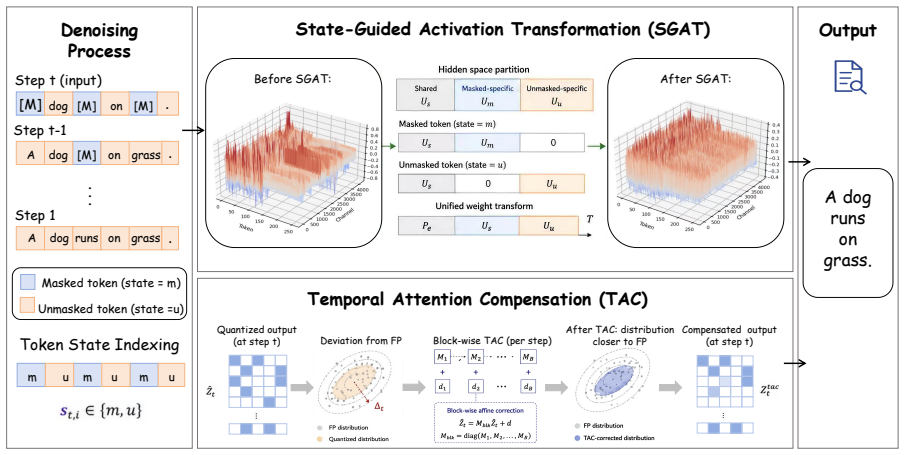
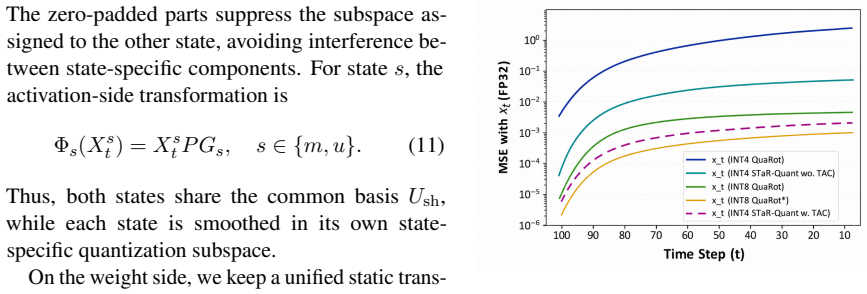
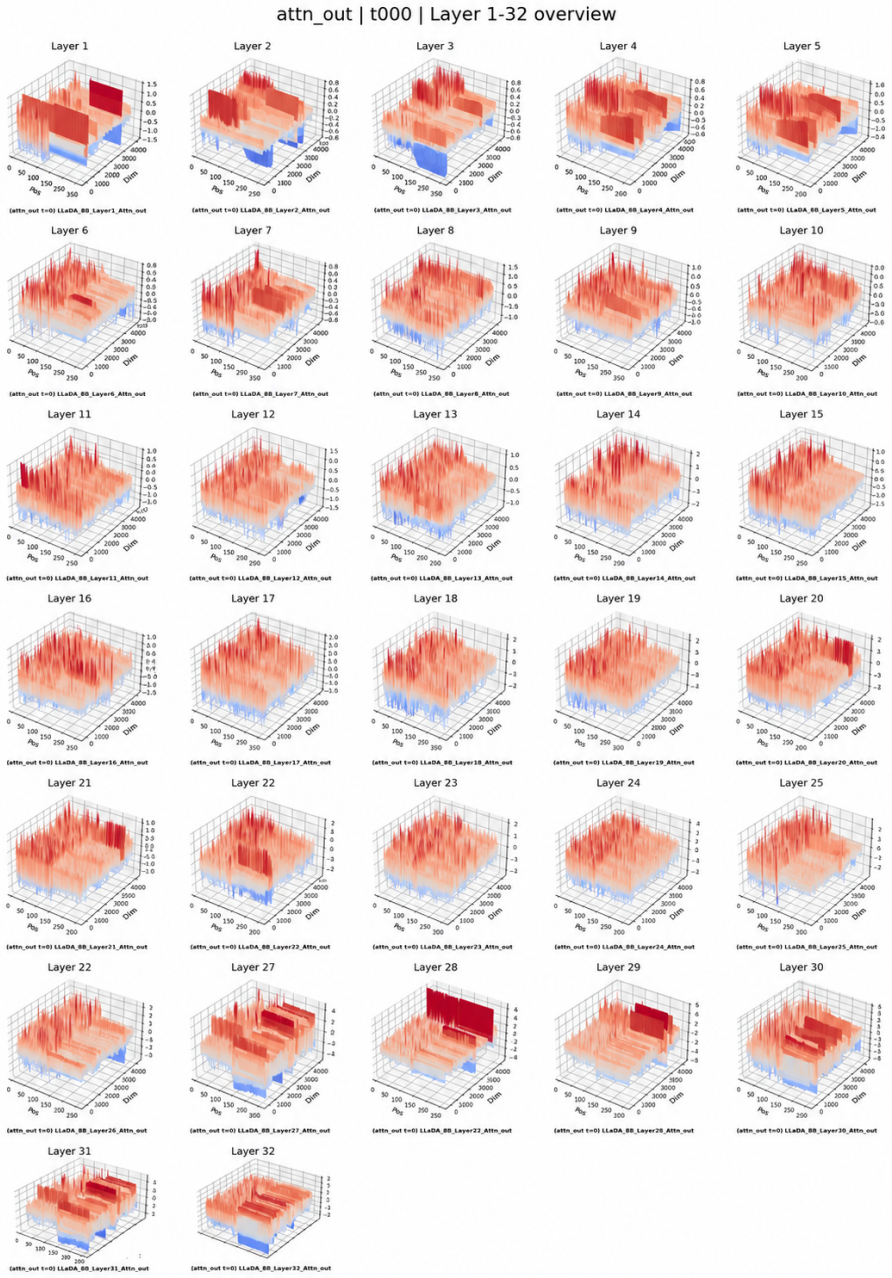
STaR-Quant introduces State-Guided Activation Transformation (SGAT) to assign masked and unmasked tokens to different activation transformation spaces with a unified static weight-side transformation. It further introduces Temporal Attention Compensation (TAC) to correct the quantized attention representation via a lightweight block-diagonal affine mapping. Experiments on representative DLLMs demonstrate that STaR-Quant consistently improves low-bit weight-activation quantization over strong PTQ baselines.
What carries the argument
State-Guided Activation Transformation (SGAT) paired with Temporal Attention Compensation (TAC), which together enforce consistency in activation ranges across token states and across denoising time steps.
If this is right
- Low-bit quantized versions of diffusion language models maintain higher generation quality than those produced by existing post-training quantization methods.
- Inference runs up to 1.69 times faster than the original FP16 model.
- Memory footprint drops by up to 3.14 times compared with FP16 deployment.
- The entire procedure operates after training is complete and requires no further model updates.
Where Pith is reading between the lines
- The same separation of token-state transformations could be tested on other iterative masked-generation models outside language.
- The block-diagonal correction pattern might transfer to attention layers in non-diffusion transformer variants that also run multiple forward passes.
- Combining the method with existing weight-only quantization or sparsity techniques could produce further compounded efficiency gains.
Load-bearing premise
State-dependent activation disparity and temporal error accumulation are the main obstacles to low-bit DLLM quantization and can be fixed by these two transformations without creating comparable new errors.
What would settle it
Running the same low-bit weight-activation quantization on the same DLLM models with a standard PTQ baseline and obtaining equal or higher accuracy, equal or greater speedup, and equal or greater memory reduction than STaR-Quant would falsify the claim.
Figures
read the original abstract
Diffusion large language models (DLLMs) have recently emerged as a promising alternative to autoregressive LLMs by generating text through iterative masked denoising with bidirectional context. However, their large model sizes and iterative denoising process introduce substantial memory and computational overhead, motivating post-training quantization for efficient deployment. In this paper, we identify two key challenges for low-bit DLLM quantization: state-dependent activation disparity and temporal error accumulation. Masked and unmasked tokens exhibit different activation distributions within each denoising step, while quantization errors can accumulate across steps during iterative decoding. To address these challenges, we propose STaR-Quant, a state-time consistent PTQ framework for DLLMs. STaR-Quant introduces State-Guided Activation Transformation (SGAT) to assign masked and unmasked tokens to different activation transformation spaces with a unified static weight-side transformation. It further introduces Temporal Attention Compensation (TAC) to correct the quantized attention representation via a lightweight block-diagonal affine mapping. Experiments on representative DLLMs demonstrate that STaR-Quant consistently improves low-bit weight-activation quantization over strong PTQ baselines, while delivering up to 1.69x speedup and 3.14x memory saving over FP16 deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes STaR-Quant, a post-training quantization (PTQ) framework for diffusion large language models (DLLMs). It identifies two challenges—state-dependent activation disparity between masked and unmasked tokens and temporal error accumulation across denoising steps—and introduces State-Guided Activation Transformation (SGAT) using separate activation spaces with a unified static weight transformation, plus Temporal Attention Compensation (TAC) via a lightweight block-diagonal affine mapping to correct quantized attention. Experiments on representative DLLMs are claimed to show consistent gains over strong PTQ baselines in low-bit weight-activation quantization, with up to 1.69× speedup and 3.14× memory savings versus FP16.
Significance. If the reported gains hold under rigorous validation, the work would be significant for practical deployment of DLLMs, as it targets efficiency without retraining while addressing DLLM-specific quantization issues. The post-training, lightweight nature of SGAT and TAC aligns well with deployment constraints and could extend to other iterative generative models.
minor comments (2)
- Abstract: the claim of 'consistent improvements' and specific speedup/memory numbers would be strengthened by naming the DLLM models, bit-widths (e.g., W4A4), and exact baselines used, even at high level.
- The description of SGAT and TAC would benefit from explicit equations or pseudocode for the unified static weight transformation and the block-diagonal affine mapping to allow reproducibility assessment.
Simulated Author's Rebuttal
We thank the referee for the positive summary, recognition of the significance for practical DLLM deployment, and recommendation of minor revision. We appreciate the alignment noted between our post-training, lightweight approach and deployment constraints.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents an empirical PTQ method (STaR-Quant) with two proposed components (SGAT and TAC) to address identified challenges in DLLM quantization. The abstract and description contain no mathematical derivation chain, no equations reducing a result to its own inputs by construction, no fitted parameters renamed as predictions, and no load-bearing self-citations or uniqueness theorems. The central claims rest on experimental improvements over baselines rather than any self-referential or tautological structure, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption State-dependent activation disparity and temporal error accumulation are the key challenges for low-bit DLLM quantization.
Reference graph
Works this paper leans on
-
[1]
2026 , eprint=
FreeAct: Freeing Activations for LLM Quantization , author=. 2026 , eprint=
2026
-
[2]
2025 , eprint=
DLLMQuant: Quantizing Diffusion-based Large Language Models , author=. 2025 , eprint=
2025
-
[3]
2022 , eprint=
TruthfulQA: Measuring How Models Mimic Human Falsehoods , author=. 2022 , eprint=
2022
-
[4]
2018 , eprint=
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge , author=. 2018 , eprint=
2018
-
[5]
2019 , eprint=
HellaSwag: Can a Machine Really Finish Your Sentence? , author=. 2019 , eprint=
2019
-
[6]
Advances in Neural Information Processing Systems , year=
Simplified and Generalized Masked Diffusion for Discrete Data , author=. Advances in Neural Information Processing Systems , year=
-
[7]
2019 , eprint=
WinoGrande: An Adversarial Winograd Schema Challenge at Scale , author=. 2019 , eprint=
2019
-
[8]
2019 , eprint=
PIQA: Reasoning about Physical Commonsense in Natural Language , author=. 2019 , eprint=
2019
-
[9]
2021 , eprint=
Measuring Massive Multitask Language Understanding , author=. 2021 , eprint=
2021
-
[10]
2023 , eprint=
C-Eval: A Multi-Level Multi-Discipline Chinese Evaluation Suite for Foundation Models , author=. 2023 , eprint=
2023
-
[11]
2021 , eprint=
Training Verifiers to Solve Math Word Problems , author=. 2021 , eprint=
2021
-
[12]
2026 , eprint=
Quantization Meets dLLMs: A Systematic Study of Post-training Quantization for Diffusion LLMs , author=. 2026 , eprint=
2026
-
[13]
2021 , eprint=
Evaluating Large Language Models Trained on Code , author=. 2021 , eprint=
2021
-
[14]
2024 , eprint=
QuaRot: Outlier-Free 4-Bit Inference in Rotated LLMs , author=. 2024 , eprint=
2024
-
[15]
2025 , eprint=
LLaDA 1.5: Variance-Reduced Preference Optimization for Large Language Diffusion Models , author=. 2025 , eprint=
2025
-
[16]
2023 , eprint=
Qwen Technical Report , author=. 2023 , eprint=
2023
-
[17]
2024 , eprint=
The Llama 3 Herd of Models , author=. 2024 , eprint=
2024
-
[18]
2023 , eprint=
LLaMA: Open and Efficient Foundation Language Models , author=. 2023 , eprint=
2023
-
[19]
2022 , eprint=
Diffusion-LM Improves Controllable Text Generation , author=. 2022 , eprint=
2022
-
[20]
2023 , eprint=
Structured Denoising Diffusion Models in Discrete State-Spaces , author=. 2023 , eprint=
2023
-
[21]
2024 , eprint=
Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution , author=. 2024 , eprint=
2024
-
[22]
2024 , eprint=
Simple and Effective Masked Diffusion Language Models , author=. 2024 , eprint=
2024
-
[23]
2025 , eprint=
Scaling Diffusion Language Models via Adaptation from Autoregressive Models , author=. 2025 , eprint=
2025
-
[24]
2025 , eprint=
Large Language Diffusion Models , author=. 2025 , eprint=
2025
-
[25]
2025 , eprint=
Dream 7B: Diffusion Large Language Models , author=. 2025 , eprint=
2025
-
[26]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Gaussianeditor: Swift and controllable 3d editing with gaussian splatting , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[27]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[28]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Instructpix2pix: Learning to follow image editing instructions , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[29]
arXiv preprint arXiv:2310.15916 , year=
In-context learning creates task vectors , author=. arXiv preprint arXiv:2310.15916 , year=
-
[30]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Instruct-nerf2nerf: Editing 3d scenes with instructions , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[31]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Text-to-3d using gaussian splatting , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[32]
, author=
3D Gaussian Splatting for Real-Time Radiance Field Rendering. , author=. ACM Trans. Graph. , volume=
-
[33]
Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
Grounding dino: Marrying dino with grounded pre-training for open-set object detection , author=. arXiv preprint arXiv:2303.05499 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Segment anything , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[35]
2023 IEEE International Conference on Robotics and Automation (ICRA) , pages=
Mask3d: Mask transformer for 3d semantic instance segmentation , author=. 2023 IEEE International Conference on Robotics and Automation (ICRA) , pages=. 2023 , organization=
2023
-
[36]
arXiv preprint arXiv:2312.00732 , year=
Gaussian grouping: Segment and edit anything in 3d scenes , author=. arXiv preprint arXiv:2312.00732 , year=
-
[37]
2024 , url =
Vachha, Cyrus and Haque, Ayaan , title =. 2024 , url =
2024
-
[38]
arXiv preprint arXiv:2401.17857 , year=
Semantic anything in 3d gaussians , author=. arXiv preprint arXiv:2401.17857 , year=
-
[39]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Feature 3dgs: Supercharging 3d gaussian splatting to enable distilled feature fields , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[40]
European Conference on Computer Vision , pages=
FlashSplat: 2D to 3D Gaussian Splatting Segmentation Solved Optimally , author=. European Conference on Computer Vision , pages=. 2025 , organization=
2025
-
[41]
arXiv preprint arXiv:2407.11793 , year=
Click-Gaussian: Interactive Segmentation to Any 3D Gaussians , author=. arXiv preprint arXiv:2407.11793 , year=
-
[42]
arXiv preprint arXiv:2403.15624 , year=
Semantic Gaussians: Open-Vocabulary Scene Understanding with 3D Gaussian Splatting , author=. arXiv preprint arXiv:2403.15624 , year=
-
[43]
2023 , journal=
Segment Any 3D Gaussians , author=. 2023 , journal=
2023
-
[44]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Tracking anything with decoupled video segmentation , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[45]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Gaussianeditor: Editing 3d gaussians delicately with text instructions , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[46]
International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences , volume=
NeRFBK: a holistic dataset for benchmarking NeRF-based 3D reconstruction , author=. International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences , volume=. 2023 , publisher=
2023
-
[47]
Remote Sensing , volume=
A critical analysis of nerf-based 3d reconstruction , author=. Remote Sensing , volume=. 2023 , publisher=
2023
-
[48]
DreamFusion: Text-to-3D using 2D Diffusion
Dreamfusion: Text-to-3d using 2d diffusion , author=. arXiv preprint arXiv:2209.14988 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[49]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Gaussiandreamer: Fast generation from text to 3d gaussians by bridging 2d and 3d diffusion models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[50]
arXiv preprint arXiv:2311.06214 , year=
Instant3d: Fast text-to-3d with sparse-view generation and large reconstruction model , author=. arXiv preprint arXiv:2311.06214 , year=
-
[51]
European Conference on Computer Vision , pages=
TPA3D: Triplane Attention for Fast Text-to-3D Generation , author=. European Conference on Computer Vision , pages=. 2025 , organization=
2025
-
[52]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Pi3d: Efficient text-to-3d generation with pseudo-image diffusion , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[53]
Proceedings of the 31st ACM International Conference on Multimedia , pages=
Points-to-3d: Bridging the gap between sparse points and shape-controllable text-to-3d generation , author=. Proceedings of the 31st ACM International Conference on Multimedia , pages=
-
[54]
International Journal of Computer Vision , pages=
Instant3d: Instant text-to-3d generation , author=. International Journal of Computer Vision , pages=. 2024 , publisher=
2024
-
[55]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Dreamcontrol: Control-based text-to-3d generation with 3d self-prior , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[56]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Magic3d: High-resolution text-to-3d content creation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[57]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Dreambooth3d: Subject-driven text-to-3d generation , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[58]
Proceedings of the 31st ACM International Conference on Multimedia , pages=
Control3d: Towards controllable text-to-3d generation , author=. Proceedings of the 31st ACM International Conference on Multimedia , pages=
-
[59]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Sherpa3d: Boosting high-fidelity text-to-3d generation via coarse 3d prior , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[60]
arXiv preprint arXiv:2406.18462 , year=
GaussianDreamerPro: Text to Manipulable 3D Gaussians with Highly Enhanced Quality , author=. arXiv preprint arXiv:2406.18462 , year=
-
[61]
arXiv preprint arXiv:2310.08529 , year=
Gaussiandreamer: Fast generation from text to 3d gaussian splatting with point cloud priors , author=. arXiv preprint arXiv:2310.08529 , year=
-
[62]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Make-it-3d: High-fidelity 3d creation from a single image with diffusion prior , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[63]
DreamGaussian: Generative Gaussian Splatting for Efficient 3D Content Creation
Dreamgaussian: Generative gaussian splatting for efficient 3d content creation , author=. arXiv preprint arXiv:2309.16653 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[64]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Zero-1-to-3: Zero-shot one image to 3d object , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[65]
2024 International Conference on 3D Vision (3DV) , pages=
Consistent-1-to-3: Consistent image to 3d view synthesis via geometry-aware diffusion models , author=. 2024 International Conference on 3D Vision (3DV) , pages=. 2024 , organization=
2024
-
[66]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Wonder3d: Single image to 3d using cross-domain diffusion , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[67]
Advances in Neural Information Processing Systems , volume=
One-2-3-45: Any single image to 3d mesh in 45 seconds without per-shape optimization , author=. Advances in Neural Information Processing Systems , volume=
-
[68]
LRM: Large Reconstruction Model for Single Image to 3D
Lrm: Large reconstruction model for single image to 3d , author=. arXiv preprint arXiv:2311.04400 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[69]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
One-2-3-45++: Fast single image to 3d objects with consistent multi-view generation and 3d diffusion , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[70]
arXiv preprint arXiv:2403.10395 , year=
Isotropic3d: Image-to-3d generation based on a single clip embedding , author=. arXiv preprint arXiv:2403.10395 , year=
-
[71]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Nerf-editing: geometry editing of neural radiance fields , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[72]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Sine: Semantic-driven image-based nerf editing with prior-guided editing field , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[73]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Blending-nerf: Text-driven localized editing in neural radiance fields , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[74]
Proceedings of the ACM on Computer Graphics and Interactive Techniques , volume=
Nerfshop: Interactive editing of neural radiance fields , author=. Proceedings of the ACM on Computer Graphics and Interactive Techniques , volume=
-
[75]
Advances in Neural Information Processing Systems , volume=
Vica-nerf: View-consistency-aware 3d editing of neural radiance fields , author=. Advances in Neural Information Processing Systems , volume=
-
[76]
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
Control-nerf: Editable feature volumes for scene rendering and manipulation , author=. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
-
[77]
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
NeRFEditor: Differentiable Style Decomposition for 3D Scene Editing , author=. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
-
[78]
arXiv preprint arXiv:2404.18929 , year=
Dge: Direct gaussian 3d editing by consistent multi-view editing , author=. arXiv preprint arXiv:2404.18929 , year=
-
[79]
arXiv preprint arXiv:2408.00083 , year=
Localized Gaussian Splatting Editing with Contextual Awareness , author=. arXiv preprint arXiv:2408.00083 , year=
-
[80]
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
Grounded sam: Assembling open-world models for diverse visual tasks , author=. arXiv preprint arXiv:2401.14159 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.