DAR: Deontic Reasoning with Agentic Harnesses
Pith reviewed 2026-06-28 05:53 UTC · model grok-4.3
The pith
Agentic harnesses let LLMs query statutes on demand and improve deontic reasoning on some tasks but not uniformly.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
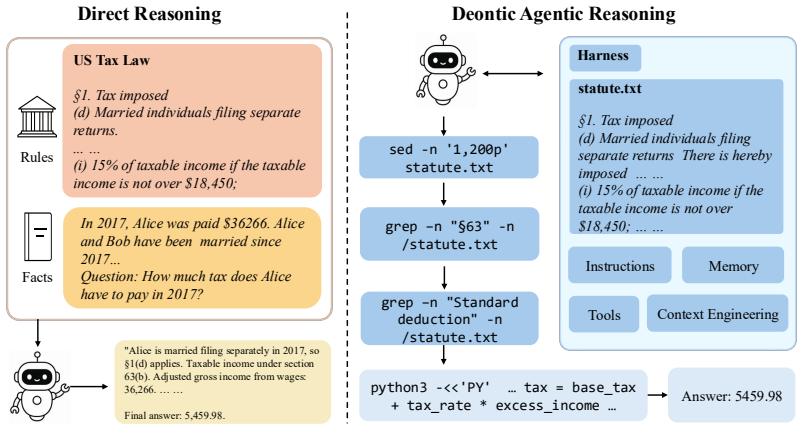
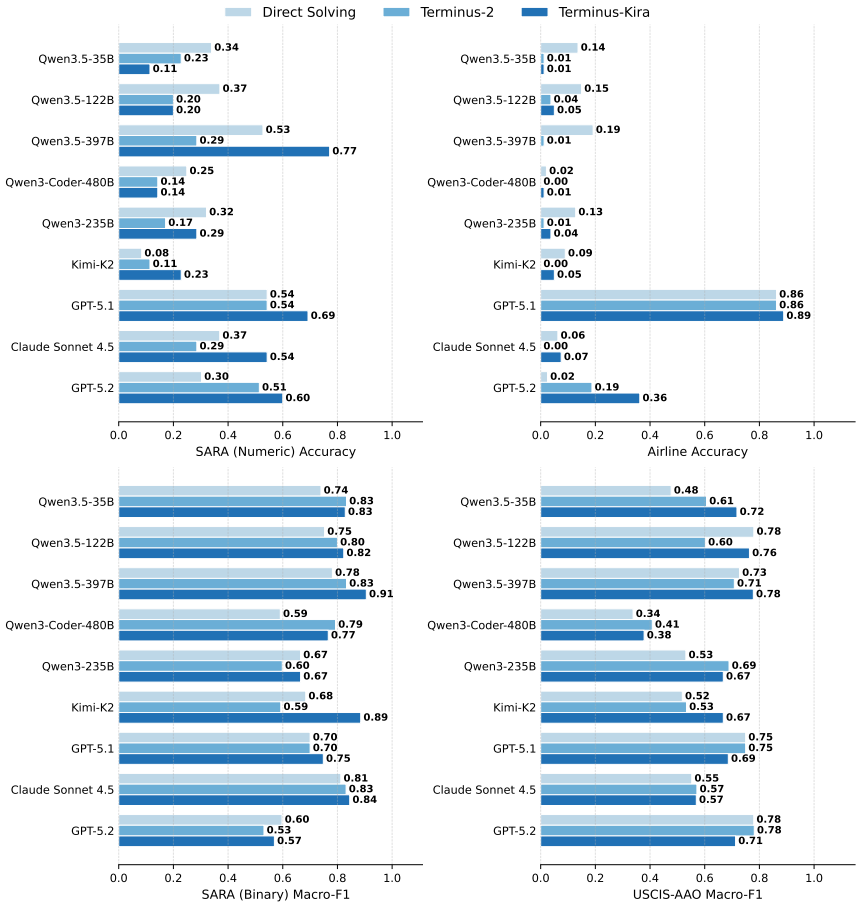
Deontic Agentic Reasoning (DAR) is an agentic reasoning setup in which the model interacts with the statutes on demand. Across multiple harnesses on hard subsets of DeonticBench, agentic harnesses can push the frontier on deontic reasoning tasks, but improvements are not uniform: weaker models often degrade on numerical tasks while consuming far more tokens.
What carries the argument
Deontic Agentic Reasoning (DAR), an agentic reasoning setup in which the model interacts with the statutes on demand to locate and apply relevant rules.
If this is right
- Agentic interaction expands the set of deontic problems LLMs can solve when rule sets are long and cross-referenced.
- Performance differences between models become more pronounced under agentic harnesses than under standard prompting.
- Numerical deontic subtasks remain especially sensitive to model scale when using on-demand rule access.
- Token budgets increase substantially with agentic methods, creating a cost-performance trade-off.
Where Pith is reading between the lines
- The same on-demand interaction pattern could be applied to other domains that rely on large, cross-referenced rule collections such as regulatory compliance or contract interpretation.
- Token-efficiency optimizations or hybrid retrieval-plus-agent designs might reduce the cost penalty observed for weaker models.
- If the interaction harness is made more structured, the gap between strong and weak models on numerical tasks might narrow.
Load-bearing premise
Allowing the model to interact with the statutes on demand enables it to locate and apply the correct rules more effectively than standard prompting without introducing new errors or excessive costs.
What would settle it
If DAR versions of the same models produce lower accuracy than direct-prompt baselines on the same DeonticBench subsets, especially on numerical tasks, the claim that agentic harnesses push the frontier would not hold.
Figures

read the original abstract
Deontic reasoning is the task of answering questions by applying explicit rules and policies to case-specific facts, for example computing tax liability under a statute or determining the outcome of an immigration appeal. A key technical challenge for LLM-based deontic reasoning is that the relevant ruleset can be long and cross-referenced, so models may still fail to locate the rules needed for a particular reasoning step. We introduce Deontic Agentic Reasoning (DAR), an agentic reasoning setup in which the model interacts with the statutes on demand. We evaluate DAR under multiple harnesses on hard subsets of DeonticBench. Across these settings, we find that agentic harnesses can push the frontier on deontic reasoning tasks, but improvements are not uniform: weaker models often degrade on numerical tasks while consuming far more tokens.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Deontic Agentic Reasoning (DAR), an agentic reasoning setup in which the model interacts with the statutes on demand to address the challenge of locating relevant rules in long, cross-referenced rulesets for tasks such as tax liability or immigration appeals. It evaluates DAR under multiple harnesses on hard subsets of DeonticBench and reports that agentic harnesses can push the frontier on deontic reasoning tasks, but improvements are not uniform: weaker models often degrade on numerical tasks while consuming far more tokens.
Significance. If the empirical results hold after proper validation, the work could be significant for advancing LLM-based deontic reasoning by demonstrating the value (and limitations) of dynamic, on-demand interaction with rule sets rather than static prompting. The non-uniformity finding across model strengths and the token-cost observation would be useful for practitioners deploying such systems in legal or policy domains. The paper is purely empirical with no equations, derivations, or fitted parameters.
major comments (1)
- Abstract: The abstract states high-level findings without experimental details, baselines, error bars, statistical tests, or data descriptions, so it is impossible to determine whether the reported results actually support the claim that agentic harnesses push the frontier on deontic reasoning tasks.
Simulated Author's Rebuttal
We thank the referee for their review. We address the single major comment below and will revise the manuscript accordingly where appropriate.
read point-by-point responses
-
Referee: Abstract: The abstract states high-level findings without experimental details, baselines, error bars, statistical tests, or data descriptions, so it is impossible to determine whether the reported results actually support the claim that agentic harnesses push the frontier on deontic reasoning tasks.
Authors: We agree that the abstract, in its current form, is high-level and does not include the requested specifics. While abstracts are conventionally concise, we will revise it to incorporate brief references to the evaluated models, the hard subsets of DeonticBench, and the nature of the observed improvements (including the non-uniformity across model strengths). Full experimental details, baselines, token costs, and any statistical analyses remain in Sections 4 and 5 of the paper. This change will make the abstract more self-contained without exceeding typical length constraints. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper is a purely empirical study introducing an agentic harness (DAR) for deontic reasoning and reporting performance on DeonticBench subsets. It contains no equations, derivations, fitted parameters, or claimed first-principles results. All load-bearing claims are experimental outcomes rather than reductions to self-defined inputs or self-citation chains, making the work self-contained against external benchmarks with no circular steps present.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
and Li, Zhening and Khattab, Omar , title =
Zhang, Alex L. and Li, Zhening and Khattab, Omar , title =. 2026 , month = apr, day =
2026
-
[9]
2025 , month = nov, day =
Young, Justin , title =. 2025 , month = nov, day =
2025
-
[10]
DeonticBench: A Benchmark for Reasoning over Rules
DeonticBench: A Benchmark for Reasoning over Rules , author=. arXiv preprint arXiv:2604.04443 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
2025 , eprint=
Kimi K2: Open Agentic Intelligence , author=. 2025 , eprint=
2025
-
[12]
Qwen3-Coder-Next Technical Report
Qwen3-Coder-Next Technical Report , author=. arXiv preprint arXiv:2603.00729 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
2026 , url=
Terminus-KIRA: Boosting Frontier Model Performance on Terminal-Bench with Minimal Harness , author=. 2026 , url=
2026
-
[14]
Is Grep All You Need? How Agent Harnesses Reshape Agentic Search
Is Grep All You Need? How Agent Harnesses Reshape Agentic Search , author=. arXiv preprint arXiv:2605.15184 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Beyond Semantic Similarity: Rethinking Retrieval for Agentic Search via Direct Corpus Interaction
Beyond Semantic Similarity: Rethinking Retrieval for Agentic Search via Direct Corpus Interaction , author=. arXiv preprint arXiv:2605.05242 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
2026 , publisher=
Agent Harness for Large Language Model Agents: A Survey , author=. 2026 , publisher=
2026
-
[17]
ReFlect: An Effective Harness System for Complex Long-Horizon LLM Reasoning
ReFlect: An Effective Harness System for Complex Long-Horizon LLM Reasoning , author=. arXiv preprint arXiv:2605.05737 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
2026 , month = feb, day =
Lopopolo, Ryan , title =. 2026 , month = feb, day =
2026
-
[19]
Meta-Harness: End-to-End Optimization of Model Harnesses
Meta-harness: End-to-end optimization of model harnesses , author=. arXiv preprint arXiv:2603.28052 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Language Models and Logic Programs for Trustworthy Tax Reasoning , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[21]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (
Ruiwen Zhou and Wenyue Hua and Liangming Pan and Sitao Cheng and Xiaobao Wu and En Yu and William Yang Wang , title=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (
-
[22]
2026 , eprint=
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces , author=. 2026 , eprint=
2026
-
[23]
Openai gpt-5 system card , author=. arXiv preprint arXiv:2601.03267 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Introducing Claude Sonnet 4.5 , howpublished =
-
[25]
Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
Efficient Memory Management for Large Language Model Serving with PagedAttention , author=. Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
-
[26]
Qwen3 Technical Report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Connecting Symbolic Statutory Reasoning with Legal Information Extraction
Holzenberger, Nils and Van Durme, Benjamin. Connecting Symbolic Statutory Reasoning with Legal Information Extraction. Proceedings of the Natural Legal Language Processing Workshop 2023. 2023. doi:10.18653/v1/2023.nllp-1.12
-
[28]
Recursive language models , author=. arXiv preprint arXiv:2512.24601 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
The Twelfth International Conference on Learning Representations , year=
DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines , author=. The Twelfth International Conference on Learning Representations , year=
-
[30]
arXiv preprint arXiv:2510.05592 , year=
In-the-flow agentic system optimization for effective planning and tool use , author=. arXiv preprint arXiv:2510.05592 , year=
-
[31]
arXiv preprint arXiv:2603.20278 , year=
Openresearcher: A fully open pipeline for long-horizon deep research trajectory synthesis , author=. arXiv preprint arXiv:2603.20278 , year=
-
[32]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Search-r1: Training llms to reason and leverage search engines with reinforcement learning , author=. arXiv preprint arXiv:2503.09516 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Folio: Natural language reasoning with first-order logic , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[34]
arXiv preprint arXiv:2501.14851 , year=
Justlogic: A comprehensive benchmark for evaluating deductive reasoning in large language models , author=. arXiv preprint arXiv:2501.14851 , year=
-
[35]
2026 , eprint=
CL-bench: A Benchmark for Context Learning , author=. 2026 , eprint=
2026
-
[36]
Proceedings of the Natural Legal Language Processing Workshop 2024 , pages=
Gaps or hallucinations? scrutinizing machine-generated legal analysis for fine-grained text evaluations , author=. Proceedings of the Natural Legal Language Processing Workshop 2024 , pages=
2024
-
[37]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , pages=
Is that your final answer? test-time scaling improves selective question answering , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , pages=
-
[38]
Conformal Thinking: Risk Control for Reasoning on a Compute Budget
Conformal Thinking: Risk Control for Reasoning on a Compute Budget , author=. arXiv preprint arXiv:2602.03814 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.