Using Large Language Models to Support High Volume Application Review for an Undergraduate Research Program
Pith reviewed 2026-06-28 01:59 UTC · model grok-4.3
The pith
An LLM-based tool replicated human grading for 1,200 statements of purpose, letting one coordinator shortlist candidates in 4 hours instead of weeks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
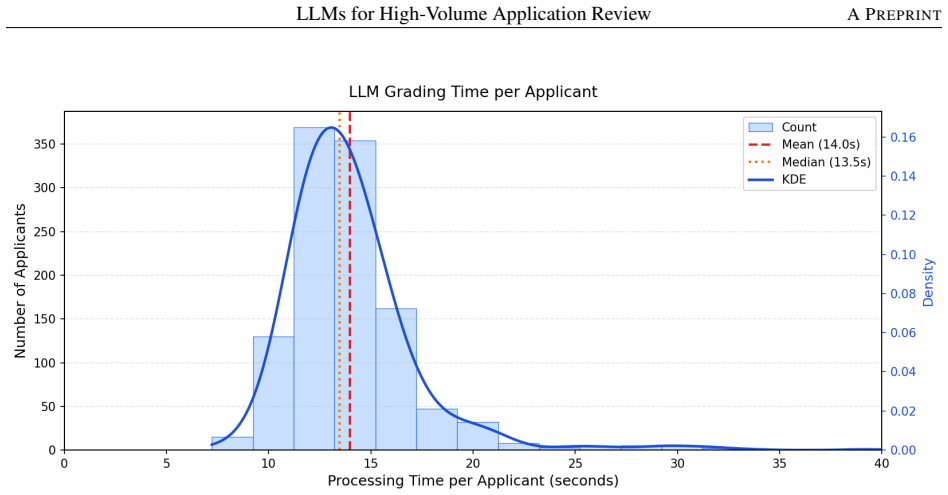
The LLM outputs replicated the role previously played by distributed human graders, providing the program coordinator with scored and rationale-annotated outputs for the entire applicant pool. Using GPT-5.2, the full batch of 1,200 SoPs was processed in approximately 4.6 hours of compute time, averaging roughly 14 seconds per SoP. The program coordinator then reviewed these outputs alongside each applicant's SoP, applying the same downstream office criteria used in prior SURF cycles, to produce a shortlist of strong candidates in approximately 4 hours, compared to the multi-week coordination effort required in prior program cycles.
What carries the argument
A structured six-subcategory rubric scored 0-3, with prompts tuned on staff-graded examples to output numerical scores, positive/negative rationales, and verbatim excerpts from each statement of purpose.
If this is right
- The coordinator review step remains necessary and can still apply the program's existing selection rules to the model outputs.
- Later GPT versions showed better adherence to the exact rubric categories than earlier ones.
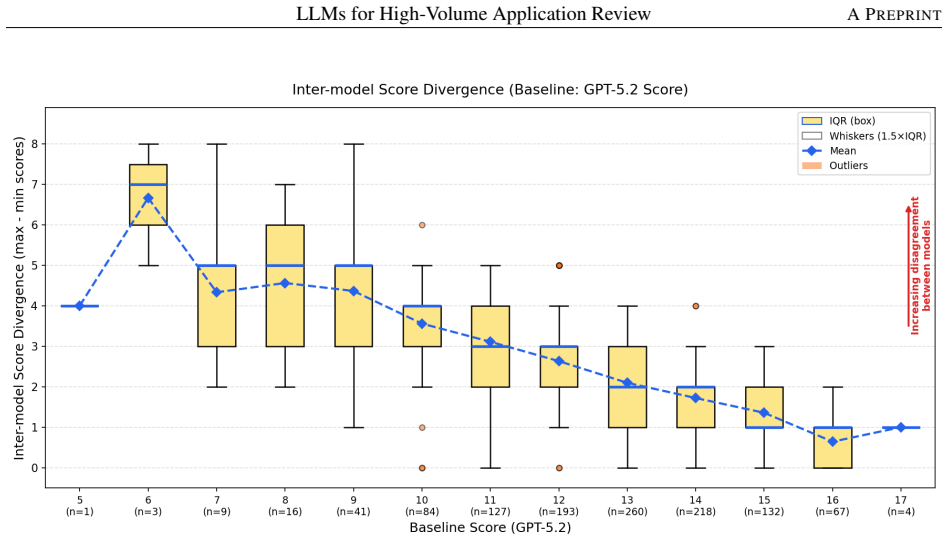
- Score disagreement between models was larger on lower-scoring submissions than on high-scoring ones.
- Total human time dropped from multiple weeks of coordination to a single 4-hour review pass.
Where Pith is reading between the lines
- The same rubric-and-prompt pattern could be reused for other high-volume selection tasks that currently rely on distributed reviewers.
- Programs could increase the number of applications reviewed without adding staff hours if the initial scoring step stays automated.
- Coordinator feedback on the model outputs could be fed back into prompt adjustments for the next cycle.
- The approach separates the consistent initial pass from the final human judgment, which may reduce variability across cycles.
Load-bearing premise
The model's scores and rationales must match what human graders would produce closely enough that the final shortlist of candidates does not change.
What would settle it
Run the same 100 statements through both the LLM workflow and independent human graders, then compare whether the two shortlists select the same top applicants.
Figures
read the original abstract
Undergraduate research programs such as the Summer Undergraduate Research Fellowship (SURF) at Purdue University receive thousands of applications every year, requiring significant time and effort for program staff to evaluate each submission consistently and within tight timelines. This work-in-progress paper describes the development and initial deployment of a large language model (LLM)-based tool to assist in the evaluation of approximately 1,200 student Statements of Purpose (SoPs) for the SURF 2026 cycle at Purdue University. The workflow utilizes OpenAI GPT models (GPT-4o, GPT-5-mini, and GPT-5.2) and uses a structured rubric across six subcategories, each scored on a 0-3 scale. A few SoPs, graded by program staff, were used to tune the model responses. The model prompt was designed to generate both numerical scores, rationales (including positive and negative aspects) and short excerpts from each submission. Using GPT-5.2, the full batch of 1,200 SoPs was processed in approximately 4.6 hours of compute time, averaging roughly 14 seconds per SoP (with per-SoP timing varying with SoP length, which ranged from 500 to 2,000 words). Notable differences in rubric adherence were observed across model versions, with GPT-5.2 adhering most closely. Disagreement in model scores was more pronounced for lower-scoring submissions. The LLM outputs replicated the role previously played by distributed human graders, providing the program coordinator with scored and rationale-annotated outputs for the entire applicant pool. The program coordinator then reviewed these outputs alongside each applicant's SoP, applying the same downstream office criteria used in prior SURF cycles, to produce a shortlist of strong candidates. This coordinator review was completed in approximately 4 hours, compared to the multi-week coordination effort required in prior program cycles.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that an LLM-based workflow using GPT models can process 1,200 SoPs for an undergraduate research program in 4.6 hours, providing scores and rationales that allow the coordinator to shortlist candidates in 4 hours, thereby replicating the role of distributed human graders.
Significance. If the LLM scores and rationales are shown to be reliable substitutes for human grading, this could transform high-volume application screening by drastically reducing processing time and coordination overhead in academic programs. The reported processing times and model version comparisons offer initial practical benchmarks for such applications.
major comments (2)
- [Abstract] The central claim that the LLM outputs 'replicated the role previously played by distributed human graders' lacks supporting quantitative data. No agreement metrics, accuracy rates, or comparison between the LLM-generated shortlist and historical human-generated shortlists are provided, despite noting that a few staff-graded SoPs were used for tuning and that disagreement was higher for low-scoring submissions.
- [Results] The manuscript does not report any hold-out validation set, inter-rater reliability statistics between model and humans, or analysis of how the coordinator's review corrected or altered the model outputs. This leaves the replication assertion as an unverified qualitative observation.
minor comments (1)
- [Abstract] The specific number of SoPs used for prompt tuning is described only as 'a few'; providing the exact count would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for these constructive comments on our work-in-progress manuscript. We agree that the replication claim is currently unsupported by quantitative evidence and will revise the text to reflect the preliminary, observational nature of the deployment. Point-by-point responses follow.
read point-by-point responses
-
Referee: [Abstract] The central claim that the LLM outputs 'replicated the role previously played by distributed human graders' lacks supporting quantitative data. No agreement metrics, accuracy rates, or comparison between the LLM-generated shortlist and historical human-generated shortlists are provided, despite noting that a few staff-graded SoPs were used for tuning and that disagreement was higher for low-scoring submissions.
Authors: We agree that the manuscript provides no agreement metrics, accuracy rates, or direct comparison to prior human shortlists. The statement in the abstract is a qualitative description of workflow usage rather than an empirically validated claim. A small number of staff-graded examples were used only for prompt tuning; no hold-out evaluation or historical comparison was performed. We will revise the abstract to remove the replication phrasing and instead state that the LLM outputs enabled the coordinator to complete shortlisting in 4 hours. revision: yes
-
Referee: [Results] The manuscript does not report any hold-out validation set, inter-rater reliability statistics between model and humans, or analysis of how the coordinator's review corrected or altered the model outputs. This leaves the replication assertion as an unverified qualitative observation.
Authors: This assessment is accurate. No hold-out validation set was reserved, no inter-rater reliability statistics were computed, and the coordinator's review process was not systematically logged for corrections or overrides. The paper reports only the observed processing times and model-version differences. We will add an explicit limitations paragraph in the Results section stating these absences and reframe the contribution as an initial deployment benchmark rather than a validated replication study. revision: yes
Circularity Check
No circularity; purely observational deployment report with no derivations, fits, or self-citation chains.
full rationale
The paper describes an LLM workflow for scoring ~1200 SoPs using a fixed rubric, notes that a few staff-graded examples were used for prompt tuning, reports compute times and qualitative observations on model versions, and states that the coordinator then reviewed outputs to produce a shortlist. No equations, parameter estimation, predictions derived from fitted values, uniqueness theorems, or self-citations appear. The central claim that LLM outputs replicated the human-grader role is presented as an observational outcome of the described process rather than a derived result that reduces to its own inputs by construction. This is a standard non-circular empirical report.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs prompted with a rubric can produce scores and rationales sufficiently faithful to human judgment for initial application screening
Reference graph
Works this paper leans on
-
[1]
URLhttps://doi.org/10.17226/24622
doi:10.17226/24622. URLhttps://doi.org/10.17226/24622. Marcia C. Linn, Erin Palmer, Anne Baranger, Elizabeth Gerard, and Elisa Stone. Undergraduate research experiences: Impacts and opportunities.Science, 347(6222):1261757,
-
[2]
URL https: //doi.org/10.1126/science.1261757
doi:10.1126/science.1261757. URL https: //doi.org/10.1126/science.1261757. Alejandra Recio-Saucedo, Ksenia Crane, Katie Meadmore, Kathryn Fackrell, Hazel Church, Simon Fraser, and Amanda Blatch-Jones. What works for peer review and decision-making in research funding: A realist synthesis.Research Integrity and Peer Review, 7(2),
-
[3]
URL https://doi.org/10.1186/ s41073-022-00120-2
doi:10.1186/s41073-022-00120-2. URL https://doi.org/10.1186/ s41073-022-00120-2. Dadi Ramesh and Suresh Kumar Sanampudi. An automated essay scoring systems: A systematic literature review. Artificial Intelligence Review, 55(3):2495–2527,
-
[4]
URL https://doi.org/ 10.1007/s10462-021-10068-2
doi:10.1007/s10462-021-10068-2. URL https://doi.org/ 10.1007/s10462-021-10068-2. Atsushi Mizumoto and Masaki Eguchi. Exploring the potential of using an AI language model for automated essay scoring.Research Methods in Applied Linguistics, 2(2):100050,
-
[5]
URL https://doi.org/10.1016/j.rmal.2023.100050
doi:10.1016/j.rmal.2023.100050. URL https://doi.org/10.1016/j.rmal.2023.100050. Xiaoyi Tang, Hongwei Chen, Daoyu Lin, and Kexin Li. Harnessing LLMs for multi-dimensional writing assessment: Reliability and alignment with human judgments.Heliyon, 10(14):e34262,
-
[6]
URLhttps://doi.org/10.1016/j.heliyon.2024.e34262
doi:10.1016/j.heliyon.2024.e34262. URLhttps://doi.org/10.1016/j.heliyon.2024.e34262. 6 LLMs for High-V olume Application ReviewA PREPRINT Xiaoyi Tian, Amogh Mannekote, Carly E Solomon, Yukyeong Song, Christine Fry Wise, Tom Mcklin, Joanne Barrett, Kristy Elizabeth Boyer, and Maya Israel. Examining llm prompting strategies for automatic evaluation of learn...
-
[7]
URL https://doi.org/10.1016/j.caeai
doi:10.1016/j.caeai.2024.100248. URL https://doi.org/10.1016/j.caeai. 2024.100248. Fatih Yavuz, Özgür Çelik, and Gamze Yava¸ s Çelik. Utilizing large language models for EFL essay grading: An examination of reliability and validity in rubric-based assessments.British Journal of Educational Technology, 56(1): 150–166,
-
[8]
URLhttps://doi.org/10.1111/bjet.13494
doi:10.1111/bjet.13494. URLhttps://doi.org/10.1111/bjet.13494. Francisco García-Varela, Miguel Nussbaum, Marcelo Mendoza, Carolina Martínez-Troncoso, and Zvi Beker- man. ChatGPT as a stable and fair tool for automated essay scoring.Education Sciences, 15(8):946,
-
[9]
URLhttps://doi.org/10.3390/educsci15080946
doi:10.3390/educsci15080946. URLhttps://doi.org/10.3390/educsci15080946. Tim Metzler, Paul G. Plöger, and Jörn Hees. Computer-assisted short answer grading using large language models and rubrics. InINFORMATIK 2024, Lecture Notes in Informatics (LNI), pages 1383–1393, Bonn,
-
[10]
Autorubric: Unifying Rubric-based LLM Evaluation
Gesellschaft für Informatik. doi:10.18420/inf2024_121. URLhttps://doi.org/10.18420/inf2024_121. Delip Rao and Chris Callison-Burch. AutoRubric: Unifying rubric-based LLM evaluation.arXiv preprint arXiv:2603.00077,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18420/inf2024_121
-
[11]
Autorubric: Unifying Rubric-based LLM Evaluation
doi:10.48550/arXiv.2603.00077. URL https://doi.org/10.48550/arXiv.2603. 00077. Jerin George Mathew, Sumayya Taher, Anindita Kundu, and Denilson Barbosa. LLMs do not grade essays like humans. arXiv preprint arXiv:2603.23714,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2603.00077
-
[12]
URL https://doi.org/10.48550/ arXiv.2603.23714
doi:10.48550/arXiv.2603.23714. URL https://doi.org/10.48550/ arXiv.2603.23714. Watheq Mansour, Salam Albatarni, Sohaila Eltanbouly, and Tamer Elsayed. Can large language models automatically score proficiency of written essays? InProceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-CO...
-
[13]
URLhttps://aclanthology.org/2024.lrec-main.247
ELRA and ICCL. URLhttps://aclanthology.org/2024.lrec-main.247. Enkelejda Kasneci, Kathrin Seßler, Stefan Küchemann, Maria Bannert, Daryna Dementieva, Frank Fischer, Urs Gasser, et al. ChatGPT for good? on opportunities and challenges of large language models for education.Learning and Individual Differences, 103:102274,
2024
-
[14]
URL https://doi.org/10.1016/ j.lindif.2023.102274
doi:10.1016/j.lindif.2023.102274. URL https://doi.org/10.1016/ j.lindif.2023.102274. Carmelo M. Vicario, Michael A. Nitsche, Chiara Lucifora, Pietro Perconti, Mohammad Ali Salehinejad, Francesco Tomaiuolo, Simona Massimino, Alessio Avenanti, and Massimo Mucciardi. Timing matters! academic assessment changes throughout the day.Frontiers in Psychology, 16:1605041,
-
[15]
URL https://doi.org/10.3389/fpsyg.2025.1605041
doi:10.3389/fpsyg.2025.1605041. URL https://doi.org/10.3389/fpsyg.2025.1605041. Ashish Gurung, Anthony F. Botelho, Russell Thompson, Adam C. Sales, Sami Baral, and Neil T. Heffernan. Considerate, unfair, or just fatigued? examining factors that impact teacher practices in open-ended responses to student work. InProceedings of the 30th International Confer...
-
[16]
doi:10.1057/s41599-025-04460-4. 7 LLMs for High-V olume Application ReviewA PREPRINT Appendix A: Evaluation Rubric The following rubric was part of the evaluation prompt. It defines three main categories (Passion, Clarity of Purpose, and Resilience), each with two sub-categories scored on a 0-3 scale, for a maximum total score of
-
[17]
contagious enthusiasm,
Each score level includes a behavioral descriptor that served as an anchor for the model’s evaluation. Category 1: Passion. Motivation for Scientific Research - Why are they interested in STEM/research? • 0:The candidate gives no clear indication of what sparked their interest in STEM or why they continue to pursue it. • 1:The candidate mentions either th...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.