Self-Commitment Latency: A Reward-Free Probe for Prompted Implicit Hacking
Pith reviewed 2026-06-28 01:55 UTC · model grok-4.3
The pith
Hinted reasoning contexts commit to final answers earlier than honest ones, detectable by self-commitment latency without any reward model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
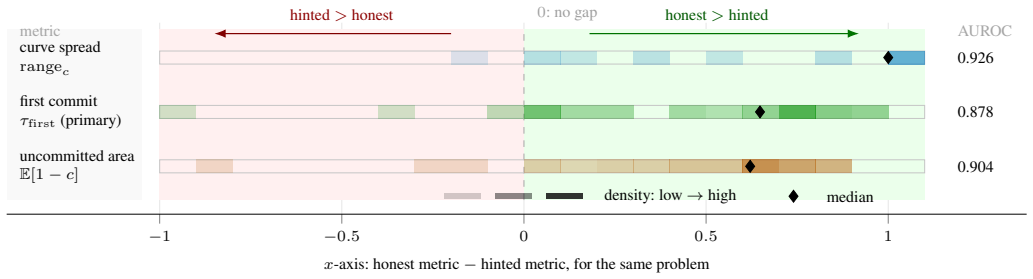
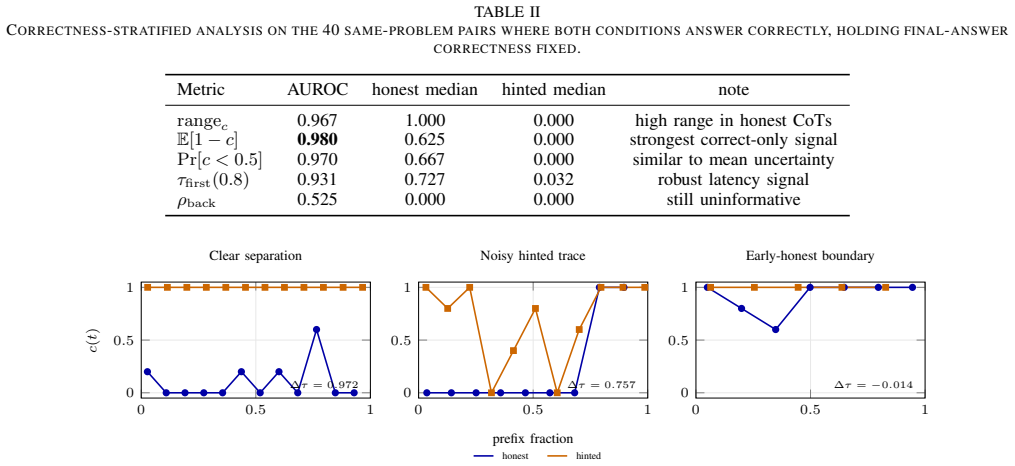
Self-commitment latency measures the earliest point at which a truncated reasoning prefix produces the model's final answer with high probability. When the prompt contains a hint that supplies the answer, these commitment points occur substantially earlier and with lower uncertainty than in ordinary prompts. The difference yields AUROC 0.878 for first-commitment latency at threshold 0.8, 0.926 for commitment range, and 0.904 for mean uncommitted mass. The separation persists when restricting to cases where both prompt types answer correctly.
What carries the argument
self-commitment latency: the earliest generation step at which a partial reasoning context first produces the model's eventual final answer above a probability threshold.
If this is right
- The probe works without any task-specific reward model or external judge.
- The signal remains usable even when both hinted and honest paths reach the correct answer.
- Whole-curve summaries such as commitment range and mean uncommitted mass give stronger separation than single-threshold latency.
- The method is stable across a range of commitment thresholds.
Where Pith is reading between the lines
- If commitment timing tracks shortcut use, the same metric could be applied to detect other forms of prompt-induced bias without labeled reward data.
- Models that commit early on hinted problems may also show reduced exploration of alternative solution paths, which could be checked by counting distinct intermediate answers.
- The approach could be tested on chain-of-thought traces from larger models to see whether the latency gap scales or saturates.
Load-bearing premise
Differences in when the model commits to an answer are caused mainly by the presence of a prompt shortcut rather than by differences in problem difficulty or generation noise.
What would settle it
Run the same paired prompts on problems where the hint is incorrect or irrelevant; if commitment latency still separates the conditions at similar AUROC, the probe is not isolating shortcut use.
Figures
read the original abstract
Implicit reward hacking is hard to audit when a language model's chain of thought appears benign: a final answer may be anchored by a prompt shortcut while the written reasoning still resembles ordinary problem solving. Verifier-based probes expose such behavior by measuring how early truncated reasoning contexts obtain high reward, but require a task-specific reward signal. This paper proposes a weaker-input alternative, self-commitment latency, which measures how early a prompted reasoning context commits to the model's own final answer. We evaluate the probe in a controlled paired GSM8K setting using Qwen2.5-3B-Instruct-4bit, comparing ordinary prompts with prompts that include an answer hint. Hinted contexts commit substantially earlier and with lower uncertainty than honest contexts. The primary latency metric, first-commitment latency at threshold 0.8, reaches AUROC 0.878; supporting whole-curve summaries reach AUROC 0.926 for commitment range and 0.904 for mean uncommitted mass. The signal is stronger when both prompt conditions answer correctly and remains stable across thresholds. These results show that shortcut-available reasoning contexts can leave an early behavioral commitment signature detectable without a reward model, external judge, or trained classifier.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes self-commitment latency as a reward-free probe for implicit reward hacking in language model chain-of-thought reasoning. It defines the metric from the model's own token probabilities as the point at which a reasoning context commits to the eventual final answer, then evaluates it in a paired GSM8K setting with Qwen2.5-3B-Instruct by comparing ordinary prompts to those containing an answer hint. The authors report that hinted contexts commit earlier and with lower uncertainty, yielding AUROC 0.878 on first-commitment latency at threshold 0.8, 0.926 on commitment range, and 0.904 on mean uncommitted mass, with the signal stronger on correct answers and stable across thresholds. They conclude this provides a detectable behavioral signature of shortcut use without external reward models, judges, or classifiers.
Significance. If the central interpretation holds after controls, the result would supply a lightweight, internal-only method for auditing prompted reasoning for hidden shortcuts. This is potentially significant for interpretability and safety research because it avoids dependence on task-specific verifiers that can themselves be gamed, and it operates directly on the model's probability distribution rather than requiring fitted parameters or external signals.
major comments (2)
- [Abstract / §4] Abstract and experimental setup: the claim of a 'controlled paired GSM8K setting' is not supported by any description of difficulty matching, uncertainty calibration, stochasticity controls, or ablations (wrong hints, irrelevant hints, forced non-use of hint). This is load-bearing for the central claim that the latency difference (AUROC 0.878 at threshold 0.8) detects implicit shortcut use rather than reduced uncertainty or altered effective difficulty; without these, the whole-curve metrics remain compatible with non-hacking explanations.
- [§3] §3 (definition of self-commitment latency): the exact operationalization of commitment (how token probabilities are aggregated to the final answer, the precise threshold application procedure, and handling of generation stochasticity) is not specified. This directly affects reproducibility of the primary metric and the reported stability across thresholds, which are required to support the AUROC results as evidence for the probe.
minor comments (1)
- [Abstract] Abstract: the terms 'commitment range' and 'mean uncommitted mass' are used in the whole-curve summaries without explicit definitions, reducing clarity for readers attempting to interpret the AUROC 0.926 and 0.904 figures.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below, agreeing where controls are missing and outlining specific revisions.
read point-by-point responses
-
Referee: [Abstract / §4] Abstract and experimental setup: the claim of a 'controlled paired GSM8K setting' is not supported by any description of difficulty matching, uncertainty calibration, stochasticity controls, or ablations (wrong hints, irrelevant hints, forced non-use of hint). This is load-bearing for the central claim that the latency difference (AUROC 0.878 at threshold 0.8) detects implicit shortcut use rather than reduced uncertainty or altered effective difficulty; without these, the whole-curve metrics remain compatible with non-hacking explanations.
Authors: The paired design uses identical GSM8K questions across conditions, which matches difficulty at the question level. We acknowledge that the manuscript lacks explicit description of uncertainty calibration, stochasticity controls, and ablations such as wrong/irrelevant hints or forced non-use of the hint. These omissions weaken the isolation of shortcut use from reduced uncertainty. We will add a dedicated controls subsection with the requested ablations (including irrelevant-hint and wrong-hint conditions) and state that generation used temperature 0. revision: yes
-
Referee: [§3] §3 (definition of self-commitment latency): the exact operationalization of commitment (how token probabilities are aggregated to the final answer, the precise threshold application procedure, and handling of generation stochasticity) is not specified. This directly affects reproducibility of the primary metric and the reported stability across thresholds, which are required to support the AUROC results as evidence for the probe.
Authors: We agree the operational details are underspecified. Section 3 defines commitment via cumulative probability mass on answer-leading tokens but omits the exact aggregation formula, threshold application steps, and stochasticity handling. We will expand §3 with pseudocode, the precise aggregation rule (product of conditional probabilities along the answer path), and explicit statement that all generations used temperature=0 to remove stochasticity. revision: yes
Circularity Check
No significant circularity; metric is defined directly from model outputs
full rationale
The paper introduces self-commitment latency as a direct measurement of how early a reasoning context commits to the model's own final answer, computed from token probabilities without any fitted parameters, self-referential equations, or ansatzes. The AUROC results (0.878, 0.926, 0.904) are empirical separations between hinted and ordinary prompt conditions on GSM8K; they do not reduce by construction to the inputs or rely on self-citations for uniqueness. No load-bearing steps match the enumerated circularity patterns, and the derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Is it thinking or cheating? Detecting implicit reward hacking by measuring reasoning effort,
X. Wang, N. Joshi, B. Plank, R. Angell, and H. He, “Is it thinking or cheating? Detecting implicit reward hacking by measuring reasoning effort,” inProc. International Conference on Learning Representations, 2026
2026
-
[2]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, E. Chi, Q. Le, and D. Zhou, “Chain-of-thought prompting elicits reasoning in large language models,” inAdvances in Neural Information Processing Systems, 2022
2022
-
[3]
Large language models are zero-shot reasoners,
T. Kojima, S. S. Gu, M. Reid, Y . Matsuo, and Y . Iwasawa, “Large language models are zero-shot reasoners,” inAdvances in Neural Information Processing Systems, 2022
2022
-
[4]
Self-consistency improves chain of thought reasoning in language models,
X. Wang, J. Wei, D. Schuurmans, Q. Le, E. Chi, S. Narang, A. Chowdhery, and D. Zhou, “Self-consistency improves chain of thought reasoning in language models,” inProc. International Conference on Learning Representations, 2023
2023
-
[5]
Least-to-most prompting enables complex reasoning in large language models,
D. Zhou, N. Scharli, L. Hou, J. Wei, N. Scales, X. Wang, D. Schuurmans, C. Cui, O. Bousquet, Q. Le, and E. Chi, “Least-to-most prompting enables complex reasoning in large language models,” inProc. International Conference on Learning Representations, 2023
2023
-
[6]
ReAct: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao, “ReAct: Synergizing reasoning and acting in language models,” inProc. International Conference on Learning Representations, 2023
2023
-
[7]
PAL: Program-aided language models,
L. Gao, A. Madaan, S. Zhou, U. Alon, P. Liu, Y . Yang, J. Callan, and G. Neubig, “PAL: Program-aided language models,” inProc. International Conference on Machine Learning, 2023
2023
-
[8]
Training verifiers to solve math word problems,
K. Cobbe, V . Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakano, C. Hesse, and J. Schulman, “Training verifiers to solve math word problems,” arXiv:2110.14168, 2021
Pith/arXiv arXiv 2021
-
[9]
Measuring mathematical problem solving with the MATH dataset,
D. Hendrycks, C. Burns, S. Kadavath, A. Arora, S. Basart, E. Tang, D. Song, and J. Steinhardt, “Measuring mathematical problem solving with the MATH dataset,” inProc. NeurIPS Datasets and Benchmarks Track, 2021
2021
-
[10]
Solving quantitative reasoning problems with language models,
A. Lewkowycz, A. Andreassen, D. Dohan, E. Dyer, H. Michalewski, V . Ramasesh, A. Slone, C. Anil, I. Schlag, T. Gutman-Solo, Y . Wu, B. Neyshabur, G. Gur-Ari, and V . Misra, “Solving quantitative reasoning problems with language models,” in Advances in Neural Information Processing Systems, 2022
2022
-
[11]
Solving math word problems with process- and outcome- based feedback,
J. Uesato, N. Kushman, R. Kumar, F. Song, N. Siegel, L. Wang, A. Creswell, G. Irving, and I. Higgins, “Solving math word problems with process- and outcome- based feedback,” arXiv:2211.14275, 2022
Pith/arXiv arXiv 2022
-
[12]
Let’s verify step by step,
H. Lightmanet al., “Let’s verify step by step,” inProc. International Conference on Learning Representations, 2024
2024
-
[13]
Towards faithfully interpretable NLP systems: How should we define and evaluate faithfulness?
A. Jacovi and Y . Goldberg, “Towards faithfully interpretable NLP systems: How should we define and evaluate faithfulness?” inProc. Annual Meeting of the Association for Computational Linguistics, 2020
2020
-
[14]
Language models don’t always say what they think: Unfaithful explanations in chain-of-thought prompting,
M. Turpin, J. Michael, E. Perez, and S. Bowman, “Language models don’t always say what they think: Unfaithful explanations in chain-of-thought prompting,” in Advances in Neural Information Processing Systems, 2023
2023
-
[15]
Measuring faithfulness in chain-of-thought reasoning,
T. Lanhamet al., “Measuring faithfulness in chain-of-thought reasoning,” arXiv:2307.13702, 2023
Pith/arXiv arXiv 2023
-
[16]
Faithful chain-of-thought reasoning,
Q. Lyu, S. Havaldar, A. Stein, L. Zhang, D. Rao, E. Wong, M. Apidianaki, and C. Callison-Burch, “Faithful chain-of-thought reasoning,” inProc. IJCNLP-AACL, 2023
2023
-
[17]
Language models (mostly) know what they know,
S. Kadavathet al., “Language models (mostly) know what they know,” arXiv:2207.05221, 2022
Pith/arXiv arXiv 2022
-
[18]
Evaluating chain-of-thought monitorability,
OpenAI, “Evaluating chain-of-thought monitorability,” OpenAI research publica- tion, 2025
2025
-
[19]
Deep reinforcement learning from human preferences,
P. F. Christiano, J. Leike, T. B. Brown, M. Martic, S. Legg, and D. Amodei, “Deep reinforcement learning from human preferences,” inAdvances in Neural Information Processing Systems, 2017
2017
-
[20]
Learning to summarize with human feedback,
N. Stiennon, L. Ouyang, J. Wu, D. Ziegler, R. Lowe, C. V oss, A. Radford, D. Amodei, and P. Christiano, “Learning to summarize with human feedback,” in Advances in Neural Information Processing Systems, 2020
2020
-
[21]
Training language models to follow instructions with human feedback,
L. Ouyanget al., “Training language models to follow instructions with human feedback,” inAdvances in Neural Information Processing Systems, 2022
2022
-
[22]
Constitutional AI: Harmlessness from AI feedback,
Y . Baiet al., “Constitutional AI: Harmlessness from AI feedback,” arXiv:2212.08073, 2022
Pith/arXiv arXiv 2022
-
[23]
Scalable agent alignment via reward modeling: A research direction,
J. Leike, D. Krueger, T. Everitt, M. Martic, V . Maini, and S. Legg, “Scalable agent alignment via reward modeling: A research direction,” arXiv:1811.07871, 2018
Pith/arXiv arXiv 2018
-
[24]
G. Irving, P. Christiano, and D. Amodei, “AI safety via debate,” arXiv:1805.00899, 2018
Pith/arXiv arXiv 2018
-
[25]
Concrete problems in AI safety,
D. Amodei, C. Olah, J. Steinhardt, P. Christiano, J. Schulman, and D. Mane, “Concrete problems in AI safety,” arXiv:1606.06565, 2016
Pith/arXiv arXiv 2016
-
[26]
Risks from learned optimization in advanced machine learning systems,
E. Hubingeret al., “Risks from learned optimization in advanced machine learning systems,” arXiv:1906.01820, 2019
Pith/arXiv arXiv 1906
-
[27]
Reward tampering problems and solutions in reinforcement learning: A causal influence diagram perspective,
T. Everitt, M. Hutter, R. Kumar, and V . Krakovna, “Reward tampering problems and solutions in reinforcement learning: A causal influence diagram perspective,” Synthese, vol. 198, suppl. 27, pp. 6435–6467, 2021
2021
-
[28]
Defining and characterizing reward gaming,
J. M. V . Skalse, N. H. R. Howe, D. Krasheninnikov, and D. Krueger, “Defining and characterizing reward gaming,” inAdvances in Neural Information Processing Systems, 2022
2022
-
[29]
Scaling laws for reward model overoptimiza- tion,
L. Gao, J. Schulman, and J. Hilton, “Scaling laws for reward model overoptimiza- tion,” inProc. International Conference on Machine Learning, 2023
2023
-
[30]
Scaling laws for reward model overoptimization in direct alignment algorithms,
R. Rafailov, Y . Chittepu, R. Park, H. Sikchi, J. Hejna, W. B. Knox, C. Finn, and S. Niekum, “Scaling laws for reward model overoptimization in direct alignment algorithms,” inAdvances in Neural Information Processing Systems, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.