Agent-Orchestrated Adaptive RAG: A Comparative Study on Structured and Multi-Hop Retrieval
Pith reviewed 2026-06-27 23:54 UTC · model grok-4.3
The pith
Agentic RAG with query decomposition and reflection improves structured domain results but degrades multi-hop ranking precision, requiring selective use rather than uniform application.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that query decomposition yields consistent gains in the structured domain (overall score +0.04, MRR +0.17 on DevOps) but degrades ranking precision on the multi-hop benchmark, while the reflection mechanism improves citation accuracy at a substantial latency cost. These contrasting results show that agentic enhancements are not universally beneficial and must be applied selectively according to query and domain characteristics. The findings argue for adaptive, cost-aware orchestration rather than uniformly aggressive reasoning pipelines.
What carries the argument
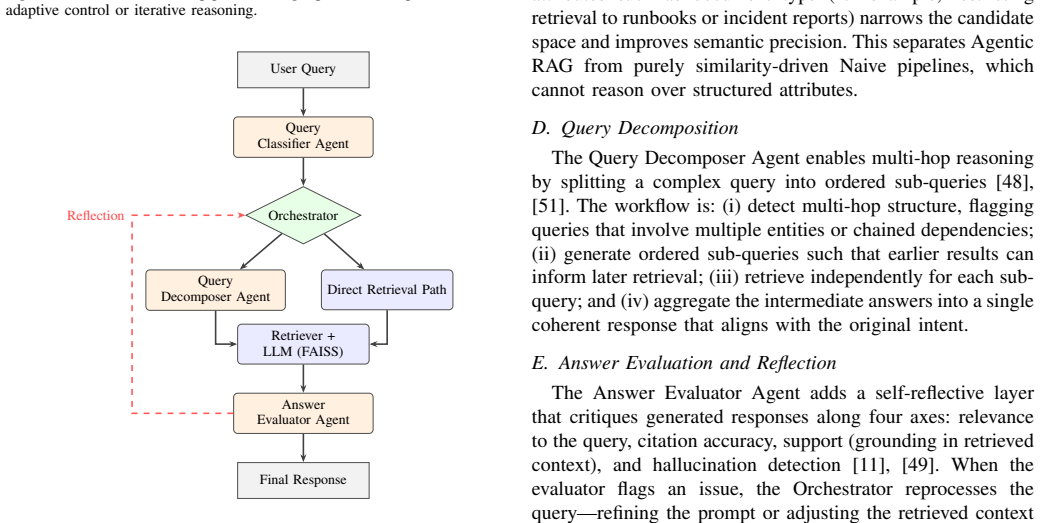
The Agent-Orchestrated Adaptive RAG framework that adds dynamic query decomposition, iterative retrieval, and a bounded self-reflective evaluation loop to a standard retrieval-augmented generation pipeline.
If this is right
- Query decomposition improves overall score and MRR on structured DevOps tasks but lowers ranking precision on multi-hop reasoning tasks.
- The reflection loop raises citation accuracy but adds substantial latency.
- Uniform application of agentic components produces mixed results that depend on query and domain traits.
- Adaptive orchestration that selects retrieval strategies according to task characteristics outperforms always-on agent pipelines.
Where Pith is reading between the lines
- Query-type classifiers could be added upstream to decide automatically whether to invoke decomposition or reflection.
- Cost models that weigh latency against accuracy gains could be used to set dynamic bounds on the reflection loop.
- The pattern of selective benefit may extend to other agentic LLM pipelines that add planning or self-critique steps.
Load-bearing premise
The two chosen datasets and the four evaluation metrics are representative enough to support the general claim that agentic steps must be applied selectively across all query types and domains.
What would settle it
A follow-up experiment that shows query decomposition and the reflection loop produce consistent gains in both overall score and ranking precision on a new set of multi-hop and structured datasets would falsify the need for selective orchestration.
Figures



read the original abstract
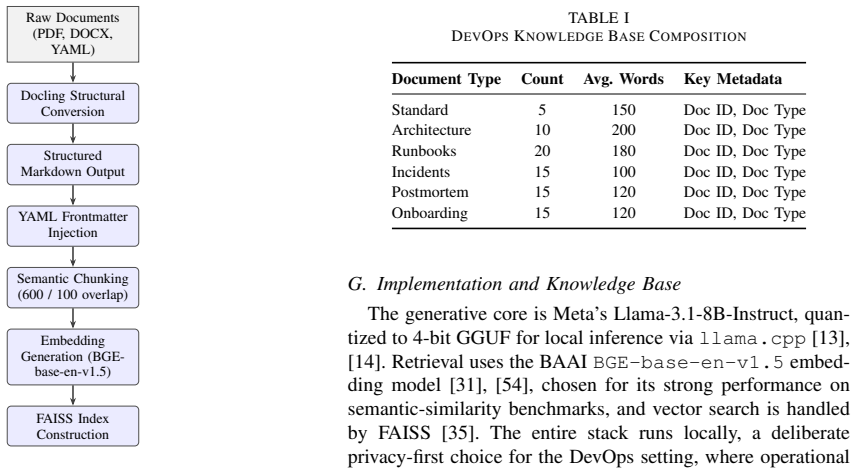
Retrieval-Augmented Generation (RAG) enhances Large Language Models (LLMs) by grounding their responses in external knowledge, but conventional pipelines rely on static, single-step retrieval that limits performance on complex queries. This paper presents an Agent-Orchestrated Adaptive RAG framework that introduces dynamic query decomposition, iterative retrieval, and a bounded self-reflective evaluation loop. We evaluate the system across two complementary datasets: a domain-specific DevOps knowledge base and the multi-hop reasoning benchmark MuSiQue. Using metrics that include overall score, citation accuracy, mean reciprocal rank, and topic coverage, we find that query decomposition yields consistent gains in the structured domain (overall score $+0.04$, MRR $+0.17$ on DevOps) but degrades ranking precision on the multi-hop benchmark, while the reflection mechanism improves citation accuracy at a substantial latency cost. These contrasting results show that agentic enhancements are not universally beneficial and must be applied selectively according to query and domain characteristics. Our findings argue for adaptive, cost-aware orchestration rather than uniformly aggressive reasoning pipelines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces an Agent-Orchestrated Adaptive RAG framework featuring dynamic query decomposition, iterative retrieval, and a bounded self-reflective evaluation loop to address limitations of static single-step RAG on complex queries. It reports experimental results on two datasets—a domain-specific DevOps knowledge base and the multi-hop MuSiQue benchmark—using metrics including overall score, citation accuracy, MRR, and topic coverage. Key findings are that decomposition yields gains on the structured DevOps domain (+0.04 overall score, +0.17 MRR) but degrades ranking precision on MuSiQue, while reflection improves citation accuracy at high latency cost. The authors conclude that agentic enhancements are not universally beneficial and advocate for selective, cost-aware orchestration based on query and domain characteristics.
Significance. If the contrasting empirical outcomes hold under rigorous verification, the work offers a practical caution against blanket adoption of agentic RAG techniques and supports more nuanced, efficiency-aware system design in information retrieval and LLM augmentation. This could inform deployment decisions where latency and precision trade-offs matter.
major comments (1)
- [Abstract] The central recommendation that agentic enhancements 'must be applied selectively according to query and domain characteristics' is load-bearing for the paper's contribution yet rests on results from only two datasets (DevOps KB and MuSiQue) with no reported statistical tests for interaction effects, ablation on query characteristics, or additional benchmarks. This weakens the generalizability of the selective-orchestration claim (Abstract).
minor comments (1)
- [Abstract] The abstract references numerical improvements and contrasting outcomes but the manuscript should explicitly detail the implementation of the agent components, chosen baselines, and any error analysis or variance reporting to allow verification of the data-to-claim link.
Simulated Author's Rebuttal
We thank the referee for the detailed review and the opportunity to clarify the scope of our claims. We address the major comment point by point below.
read point-by-point responses
-
Referee: [Abstract] The central recommendation that agentic enhancements 'must be applied selectively according to query and domain characteristics' is load-bearing for the paper's contribution yet rests on results from only two datasets (DevOps KB and MuSiQue) with no reported statistical tests for interaction effects, ablation on query characteristics, or additional benchmarks. This weakens the generalizability of the selective-orchestration claim (Abstract).
Authors: We acknowledge that the selective-orchestration recommendation is supported by empirical contrasts from only two datasets and that the manuscript does not include statistical tests for interaction effects, query-characteristic ablations, or results from additional benchmarks. The DevOps KB and MuSiQue were deliberately selected as complementary testbeds (structured domain-specific retrieval versus multi-hop reasoning) precisely to demonstrate that decomposition and reflection do not yield uniform benefits; the observed degradation on MuSiQue versus gains on DevOps provides direct evidence against blanket adoption. Nevertheless, we agree that this evidence base limits the strength of any broader generalization. We will therefore revise the abstract and conclusion sections to qualify the claim, replacing the stronger phrasing with language that presents the findings as suggestive of the need for selective, cost-aware orchestration based on the query and domain characteristics examined here. We will also insert an explicit limitations paragraph discussing the narrow evaluation scope. This constitutes a partial revision, as we cannot introduce new experiments or statistical analyses without further data collection. revision: partial
Circularity Check
No circularity: empirical comparison without derivations
full rationale
The paper is a comparative empirical study reporting experimental outcomes (overall score, MRR, citation accuracy) on two fixed datasets. No equations, parameter fitting, predictions derived from inputs, or self-citation load-bearing steps exist in the described framework or results. The central claim follows directly from the observed contrasts between datasets and requires no reduction to self-referential construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Survey of hallucination in natural language generation,
Z. Ji, N. Lee, R. Frieske, T. Yu, D. Su, Y . Xu, E. Ishii, Y . J. Bang, A. Madotto, and P. Fung, “Survey of hallucination in natural language generation,”ACM Computing Surveys, vol. 55, no. 12, pp. 1–38, 2023
2023
-
[2]
Augmented Language Models: a Survey
G. Mialon, R. Dess `ı, M. Lomeli, C. Nalmpantis, R. Pasunuru, R. Raileanu, B. Rozi `ere, N. Goyal, A. Joulin, and T. Scialom, “Aug- mented language models: A survey,”arXiv preprint arXiv:2302.07842, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Building a genai-rag runbooks-based chatops assis- tant,
Amazon Bedrock, “Building a genai-rag runbooks-based chatops assis- tant,” DevOps.com, 2024
2024
-
[4]
Retrieval- augmented generation for knowledge-intensive nlp tasks,
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. K ¨uttler, M. Lewis, W. Yih, T. Rockt ¨aschelet al., “Retrieval- augmented generation for knowledge-intensive nlp tasks,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 33, 2020, pp. 9459–9474
2020
-
[5]
Realm: Retrieval-augmented language model pre-training,
K. Guu, K. Leeet al., “Realm: Retrieval-augmented language model pre-training,” inICML, 2020
2020
-
[6]
Empirical evaluation of rag patterns: Naive, fusion, and self-rag,
L. Amorimet al., “Empirical evaluation of rag patterns: Naive, fusion, and self-rag,” inSBC, 2024
2024
-
[7]
Multi-hop question answering: A survey,
S. Feldmanet al., “Multi-hop question answering: A survey,”arXiv preprint, 2023
2023
-
[8]
Retrieval-Augmented Generation for Large Language Models: A Survey
Y . Gaoet al., “Retrieval-augmented generation for large language models: A survey,”arXiv preprint arXiv:2312.10997, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG
P. Ghadekaret al., “Agentic retrieval-augmented generation: A survey,” arXiv preprint arXiv:2501.09136, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
The evolution of retrieval-augmented generation,
B. Wanget al., “The evolution of retrieval-augmented generation,” Journal of AI Research, 2024
2024
-
[11]
Self-rag: Learning to retrieve, generate, and critique through self-reflection,
A. Asaiet al., “Self-rag: Learning to retrieve, generate, and critique through self-reflection,” inProceedings of ICLR, 2024
2024
-
[12]
ReAct: Synergizing Reasoning and Acting in Language Models
S. Yaoet al., “React: Synergizing reasoning and acting in language models,”arXiv preprint arXiv:2210.03629, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[13]
The llama 3 herd of models,
Meta AI, “The llama 3 herd of models,” Meta AI, Tech. Rep., 2024
2024
-
[14]
Gguf: A new format for local llm inference,
G. Gerganov, “Gguf: A new format for local llm inference,” llama.cpp documentation, 2023
2023
-
[15]
Musique: Multihop questions via single-hop ques- tion composition,
H. Trivediet al., “Musique: Multihop questions via single-hop ques- tion composition,”Transactions of the Association for Computational Linguistics, 2022
2022
-
[16]
Generative adversarial nets,
I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y . Bengio, “Generative adversarial nets,” in Advances in Neural Information Processing Systems, 2014, pp. 2672– 2680
2014
-
[17]
A survey on generative adversarial networks: Algorithms, theory, and applications,
J. Gui, Z. Sun, Y . Wen, D. Tao, and J. Ye, “A survey on generative adversarial networks: Algorithms, theory, and applications,”IEEE Trans- actions on Knowledge and Data Engineering, 2021
2021
-
[18]
Language models are few-shot learners,
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askellet al., “Language models are few-shot learners,”Advances in Neural Information Processing Systems, vol. 33, pp. 1877–1901, 2020
1901
-
[19]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” inAdvances in Neural Information Processing Systems, 2017, pp. 5998–6008
2017
-
[20]
Self-attention with relative position representations,
P. Shaw, J. Uszkoreit, and A. Vaswani, “Self-attention with relative position representations,” inProceedings of NAACL, 2018
2018
-
[21]
Position information in trans- formers: An overview,
P. Dufter, M. Schmitt, and H. Sch ¨utze, “Position information in trans- formers: An overview,”Computational Linguistics, vol. 48, no. 3, pp. 733–763, 2022
2022
-
[22]
Neural Machine Translation of Rare Words with Subword Units
R. Sennrich, B. Haddow, and A. Birch, “Neural machine translation of rare words with subword units,”arXiv preprint arXiv:1508.07909, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[23]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,”arXiv preprint arXiv:1810.04805, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[24]
Improving language understanding by generative pre-training,
A. Radford and K. Narasimhan, “Improving language understanding by generative pre-training,” 2018
2018
-
[25]
Sequence Transduction with Recurrent Neural Networks
A. Graves, “Sequence transduction with recurrent neural networks,” arXiv preprint arXiv:1211.3711, 2012
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[26]
The Curious Case of Neural Text Degeneration
A. Holtzman, J. Buys, L. Du, M. Forbes, and Y . Choi, “The curious case of neural text degeneration,”arXiv preprint arXiv:1904.09751, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[27]
On the dangers of stochastic parrots: Can language models be too big?
E. M. Bender, T. Gebru, A. McMillan-Major, and S. Shmitchell, “On the dangers of stochastic parrots: Can language models be too big?” in Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, 2021, pp. 610–623
2021
-
[28]
Energy and policy consid- erations for deep learning in nlp,
E. Strubell, A. Ganesh, and A. McCallum, “Energy and policy consid- erations for deep learning in nlp,” inProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019
2019
-
[29]
Distributed representations of words and phrases,
T. Mikolovet al., “Distributed representations of words and phrases,” inNeurIPS, 2013
2013
-
[30]
Efficient Estimation of Word Representations in Vector Space
T. Mikolov, K. Chen, G. Corrado, and J. Dean, “Efficient estimation of word representations in vector space,”arXiv preprint arXiv:1301.3781, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[31]
Sentence-bert: Sentence embeddings using siamese bert-networks,
N. Reimers and I. Gurevych, “Sentence-bert: Sentence embeddings using siamese bert-networks,” inProceedings of EMNLP, 2019
2019
-
[32]
Dense passage retrieval for open-domain question answering,
V . Karpukhin, B. Oguzet al., “Dense passage retrieval for open-domain question answering,” inEMNLP, 2020
2020
-
[33]
Query2doc: Query expansion with large language models,
L. Wanget al., “Query2doc: Query expansion with large language models,” inProceedings of EMNLP, 2023
2023
-
[34]
A. Maharjan and U. Yadav, “Chunking, retrieval, and re-ranking: An empirical evaluation of rag architectures for policy document question answering,”arXiv preprint arXiv:2601.15457, 2026
-
[35]
Billion-scale similarity search with gpus,
J. Johnsonet al., “Billion-scale similarity search with gpus,”IEEE Transactions on Big Data, 2019
2019
-
[36]
M. Douzeet al., “The faiss library for efficient similarity search,”arXiv preprint arXiv:2401.08281, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
Sentence meaning similarity detector using faiss,
P. Ghadekar, “Sentence meaning similarity detector using faiss,” in ICCUBEA, 2023
2023
-
[38]
S. Mishra, S. Niroula, U. Yadav, D. Thakur, S. Gyawali, and S. Gaire, “Sok: Agentic retrieval-augmented generation (rag): Taxon- omy, architectures, evaluation, and research directions,”arXiv preprint arXiv:2603.07379, 2026
-
[39]
A Survey on Large Language Model based Autonomous Agents
L. Wanget al., “A survey of large language model based autonomous agents,”arXiv preprint arXiv:2308.11432, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[40]
The agentic workflow landscape,
A. Ng, “The agentic workflow landscape,” DeepLearning.AI, 2024
2024
-
[41]
Multi-agent collaboration in generative ai,
L. Yan, “Multi-agent collaboration in generative ai,” Medium, 2024
2024
-
[42]
Toolformer: Language Models Can Teach Themselves to Use Tools
T. Schicket al., “Toolformer: Language models can teach themselves to use tools,”arXiv preprint arXiv:2302.04761, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[43]
Corrective retrieval augmented generation,
S. Yanet al., “Corrective retrieval augmented generation,” inProceed- ings of ICLR, 2024
2024
-
[44]
Adaptive-rag: Learning to adapt retrieval-augmented large language models through question complexity,
S. Jeonget al., “Adaptive-rag: Learning to adapt retrieval-augmented large language models through question complexity,” inProceedings of NAACL, 2024
2024
-
[45]
Agentic rag: Enhancing retrieval with ai agents,
Weights and Biases, “Agentic rag: Enhancing retrieval with ai agents,” WandB Reports, 2024
2024
-
[46]
Self-correction in llms during inference: A survey,
J. Huet al., “Self-correction in llms during inference: A survey,” Transactions of the ACL (TACL), 2024
2024
-
[47]
Chain-of-thought prompting elicits reasoning in llms,
J. Weiet al., “Chain-of-thought prompting elicits reasoning in llms,” in NeurIPS, 2022
2022
-
[48]
Least-to-Most Prompting Enables Complex Reasoning in Large Language Models
D. Zhouet al., “Least-to-most prompting enables complex reasoning,” arXiv preprint arXiv:2205.10625, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[49]
Self-Refine: Iterative Refinement with Self-Feedback
A. Madaanet al., “Self-refine: Iterative refinement with self-feedback,” arXiv preprint arXiv:2303.17651, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[50]
Hotpotqa: A dataset for diverse, explainable multi-hop question answering,
Z. Yanget al., “Hotpotqa: A dataset for diverse, explainable multi-hop question answering,” inProceedings of EMNLP, 2018
2018
-
[51]
Reasoning in trees: Multi-hop question answering in rag,
Y . Shiet al., “Reasoning in trees: Multi-hop question answering in rag,” inProceedings of the WWW Conference, 2026
2026
-
[52]
Docling: An efficient open-source toolkit for ai-driven document conversion,
IBM Research, “Docling: An efficient open-source toolkit for ai-driven document conversion,” inAAAI, 2025
2025
-
[53]
Docling technical report v2.0,
——, “Docling technical report v2.0,”arXiv preprint arXiv:2501.17887, 2025
-
[54]
Bge-base-en-v1.5 technical specifications,
BAAI, “Bge-base-en-v1.5 technical specifications,” HuggingFace, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.