Beyond Waveform Robustness: Robust Feature-Vocoder Adversarial Attacks on Automatic Speech Recognition
Pith reviewed 2026-06-28 00:07 UTC · model grok-4.3
The pith
Adversarial attacks on ASR that perturb SSL features and reconstruct via vocoder transfer more effectively to black-box models and bypass waveform defenses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
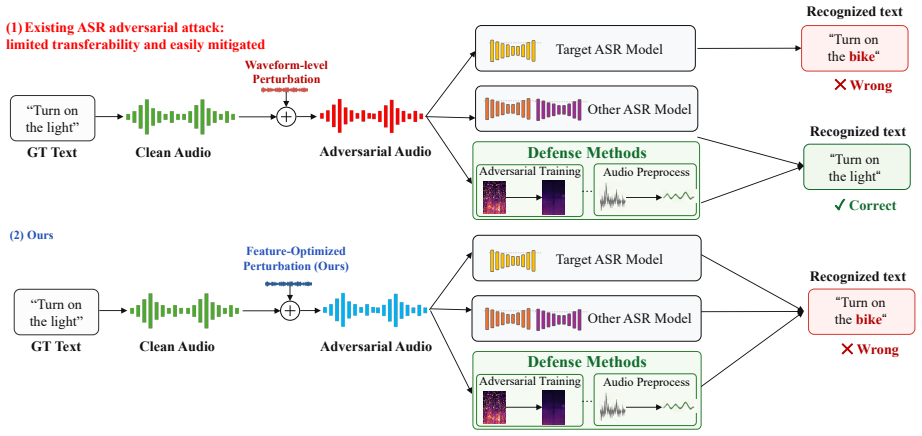
By shifting the adversarial search space to SSL acoustic-phonetic representations and reconstructing the perturbed features through a vocoder into speech-like waveforms, the attack produces examples that generalize across ASR systems and evade defenses tailored to input-space perturbations.
What carries the argument
Clean-Referenced Feature-Vocoder Attack, which perturbs generalizable acoustic-phonetic representations in SSL space and reconstructs them with a vocoder to create transferable adversarial speech.
If this is right
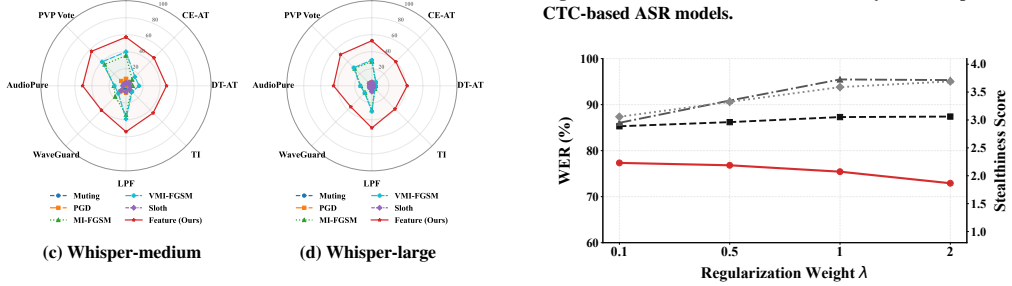
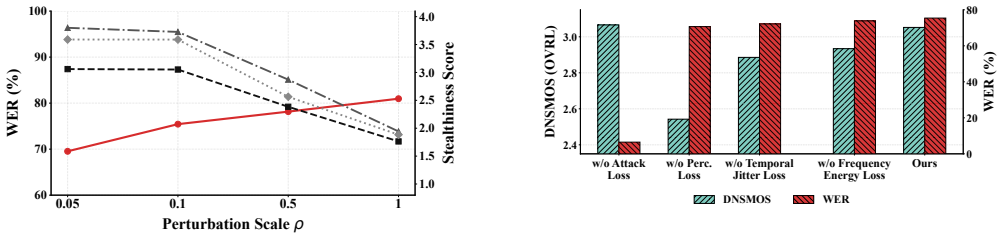
- Attacks optimized on a single public surrogate like Whisper-small transfer effectively to multiple black-box ASR models.
- The approach yields a 26.6 WER improvement over SOTA baseline on black-box models.
- It achieves a 36.2 WER improvement against multiple training defenses.
- Current ASR robustness evaluations have a blind spot focused on waveform perturbations.
Where Pith is reading between the lines
- ASR systems may need new defense strategies that account for feature-space perturbations reconstructed into audio.
- The method suggests that robustness claims based only on waveform attacks may overestimate security against real-world black-box threats.
Load-bearing premise
Perturbations to SSL representations can be vocoded into speech-like waveforms that fool ASR systems while avoiding detection by waveform-specific defenses.
What would settle it
An experiment showing that the reported WER gains disappear when the attack is tested against ASR models equipped with defenses that operate on reconstructed feature perturbations rather than raw waveforms.
Figures


read the original abstract
Automatic speech recognition (ASR) systems have become widely used for multilingual speech-to-text transcription. Their robustness to adversarial attacks has become an important topic for the community. Existing adversarial attacks directly add adversarial noise to the speech audio. However, prior work has shown that existing adversarial attacks face two limitations: they often transfer poorly to black-box ASR systems and are increasingly mitigated by defenses tailored to input-space perturbations. In this work, we propose a Clean-Referenced Feature-Vocoder Attack, a surrogate-based black-box attack that moves the adversarial search space from raw waveforms to self-supervised learning (SSL) representations. To address the transferability limitation, we perturb more generalizable acoustic-phonetic representations rather than low-level waveform samples, reducing dependence on surrogate-specific waveform gradients and encouraging adversarial perturbations that generalize across ASR systems. To bypass different defenses, we shift the adversarial signal from explicit additive waveform noise to SSL feature-space perturbations and reconstruct them through a vocoder into speech-like waveform adversarial signals, making the resulting samples less aligned with waveform-bounded defenses. Extensive experiments show that, when optimized only on raw Whisper-small as a public surrogate model, our attack transfers effectively to black-box ASR models with a +26.6 WER improvement over the SOTA baseline, while also remaining effective against multiple training defenses with a +36.2 WER improvement. These results reveal a blind spot in current ASR robustness evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a Clean-Referenced Feature-Vocoder Attack on ASR systems. Instead of adding perturbations directly to waveforms, the method perturbs acoustic-phonetic representations extracted from a self-supervised learning (SSL) model and reconstructs the adversarial waveform via a vocoder. Using only Whisper-small as a public surrogate, the attack is reported to achieve a +26.6 WER improvement over the SOTA baseline on black-box transfer and a +36.2 WER improvement against multiple training-based defenses, indicating a blind spot in current ASR robustness evaluation.
Significance. If the empirical transfer and defense-evasion results hold under rigorous verification, the work is significant for ASR robustness research. It demonstrates that shifting the attack space to SSL features and using vocoder reconstruction can produce more generalizable and defense-evading adversarial examples than waveform-space methods. This could prompt reevaluation of existing defenses and benchmarks that focus primarily on input-space perturbations.
major comments (1)
- Abstract: the central performance claims (+26.6 WER transfer improvement and +36.2 WER defense improvement) are stated without any reference to datasets, model versions, number of trials, statistical significance, or specific tables/figures that support them. This absence makes the load-bearing empirical results unverifiable from the provided text and requires the experimental section to supply full details, error bars, and ablation studies for the claims to be assessable.
minor comments (1)
- Abstract: the phrase 'Clean-Referenced Feature-Vocoder Attack' is introduced without a concise definition or reference to the section where the clean reference signal and vocoder training are described.
Simulated Author's Rebuttal
We thank the referee for their review and constructive feedback on the abstract. We address the major comment below.
read point-by-point responses
-
Referee: [—] Abstract: the central performance claims (+26.6 WER transfer improvement and +36.2 WER defense improvement) are stated without any reference to datasets, model versions, number of trials, statistical significance, or specific tables/figures that support them. This absence makes the load-bearing empirical results unverifiable from the provided text and requires the experimental section to supply full details, error bars, and ablation studies for the claims to be assessable.
Authors: We agree that the abstract would be improved by explicit cross-references to the supporting experimental evidence. In the revised manuscript we will update the abstract to include brief pointers to the datasets, surrogate model details, tables, and figures that report the +26.6 WER black-box transfer and +36.2 WER defense results together with the number of trials, statistical significance, error bars, and ablation studies. The experimental sections already contain these elements; the revision will make the linkages from the abstract explicit. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper proposes an empirical surrogate-based adversarial attack shifting perturbations to SSL feature space with vocoder reconstruction, validated solely through reported transferability experiments (+26.6 WER) and defense results (+36.2 WER) against external baselines. No equations, first-principles derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text; claims rest on standard empirical comparison rather than any self-referential reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Voice conversion with just nearest neighbors
Matthew Baas, Benjamin van Niekerk, and Herman Kamper. Voice conversion with just nearest neighbors. arXiv preprint arXiv:2305.18975, 2023. 2
arXiv 2023
-
[2]
wav2vec 2.0: A framework for self-supervised learning of speech representations
Alexei Baevski, Yuhao Zhou, Abdelrahman Mohamed, and Michael Auli. wav2vec 2.0: A framework for self-supervised learning of speech representations. In Hugo Larochelle, Marc’ Aurelio Ranzato, Raia Hadsell, Maria-Florina Balcan, and Hsuan-Tien Lin, editors, Ad- vances in Neural Information Processing Systems 33: Annual Conference on Neural Information Proce...
2020
-
[3]
wav2vec 2.0: A framework for self-supervised learning of speech representations
Alexei Baevski, Yuhao Zhou, Abdelrahman Mohamed, and Michael Auli. wav2vec 2.0: A framework for self-supervised learning of speech representations. Advances in neural information processing systems , 33:12449–12460, 2020. 1
2020
-
[4]
AISHELL-1: an open-source mandarin speech corpus and a speech recognition baseline
Hui Bu, Jiayu Du, Xingyu Na, Bengu Wu, and Hao Zheng. AISHELL-1: an open-source mandarin speech corpus and a speech recognition baseline. In 20th Conference of the Oriental Chapter of the Interna- tional Coordinating Committee on Speech Databases and Speech I/O Systems and Assessment, O-COCOSDA 2017, Seoul, South Korea, November 1-3, 2017 , pages 1–5. IEE...
2017
-
[5]
Audio adversarial examples: Targeted attacks on speech-to-text
Nicholas Carlini and David Wagner. Audio adversarial examples: Targeted attacks on speech-to-text. In 2018 IEEE security and privacy workshops (SPW) , pages 1–
2018
-
[6]
Nicholas Carlini and David A. Wagner. Audio adver- sarial examples: Targeted attacks on speech-to-text. In 2018 IEEE Security and Privacy Workshops, SP Work- shops 2018, San Francisco, CA, USA, May 24, 2018 , pages 1–7. IEEE Computer Society, 2018. 1
2018
-
[7]
Wavlm: Large-scale self-supervised pre-training for full stack speech processing
Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Y oshioka, Xiong Xiao, et al. Wavlm: Large-scale self-supervised pre-training for full stack speech processing. IEEE Journal of Selected Topics in Signal Processing, 16(6):1505–1518, 2022. 1, 2
2022
-
[8]
Boosting ad- versarial attacks with momentum
Yinpeng Dong, Fangzhou Liao, Tianyu Pang, Hang Su, Jun Zhu, Xiaolin Hu, and Jianguo Li. Boosting ad- versarial attacks with momentum. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018. 4
2018
-
[9]
Evading defenses to transferable adversarial examples by translation-invariant attacks
Yinpeng Dong, Tianyu Pang, Hang Su, and Jun Zhu. Evading defenses to transferable adversarial examples by translation-invariant attacks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019. 1, 4
2019
-
[10]
vec2wav 2.0: Advancing voice conversion via discrete token vocoders
Yiwei Guo, Zhihan Li, Junjie Li, Chenpeng Du, Hankun Wang, Shuai Wang, Xie Chen, and Kai Yu. vec2wav 2.0: Advancing voice conversion via discrete token vocoders. arXiv preprint arXiv:2409.01995 , 2024. 3, 4
arXiv 2024
-
[11]
Awni Y . Hannun, Carl Case, Jared Casper, Bryan Catanzaro, Greg Diamos, Erich Elsen, Ryan Prenger, Sanjeev Satheesh, Shubho Sengupta, Adam Coates, and Andrew Y . Ng. Deep speech: Scaling up end-to-end speech recognition. CoRR, abs/1412.5567, 2014. 1
Pith/arXiv arXiv 2014
-
[12]
Slothspeech: Denial-of- service attack against speech recognition models
Mirazul Haque, Rutvij Shah, Simin Chen, Berrak Şiş- man, Cong Liu, and Wei Y ang. Slothspeech: Denial-of- service attack against speech recognition models. arXiv preprint arXiv:2306.00794, 2023. 4
arXiv 2023
-
[13]
Hubert: Self-supervised speech rep- resentation learning by masked prediction of hidden units
Wei-Ning Hsu, Benjamin Bolte, Y ao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, and Abdelrah- man Mohamed. Hubert: Self-supervised speech rep- resentation learning by masked prediction of hidden units. IEEE/ACM transactions on audio, speech, and language processing, 29:3451–3460, 2021. 4
2021
-
[14]
Waveguard: Understanding and mitigating audio adversarial exam- ples
Shehzeen Hussain, Paarth Neekhara, Shlomo Dubnov, Julian McAuley, and Farinaz Koushanfar. Waveguard: Understanding and mitigating audio adversarial exam- ples. In USENIX Security Symposium , 2021. 1, 2, 4
2021
-
[15]
Ace-vc: Adaptive and controllable voice conversion using explicitly disentan- gled self-supervised speech representations
Shehzeen Hussain, Paarth Neekhara, Jocelyn Huang, Jason Li, and Boris Ginsburg. Ace-vc: Adaptive and controllable voice conversion using explicitly disentan- gled self-supervised speech representations. In ICASSP 2023-2023 IEEE International Conference on Acous- tics, Speech and Signal Processing (ICASSP) , pages 1–
2023
-
[16]
Hifi- gan: Generative adversarial networks for efficient and high fidelity speech synthesis
Jungil Kong, Jaehyeon Kim, and Jaekyoung Bae. Hifi- gan: Generative adversarial networks for efficient and high fidelity speech synthesis. Advances in neural in- formation processing systems , 33:17022–17033, 2020. 1, 3
2020
-
[17]
Acoustic-decoy: Detection of adversarial examples through audio modification on speech recognition sys- tem
Hyun Kwon, Hyunsoo Y oon, and Ki-Woong Park. Acoustic-decoy: Detection of adversarial examples through audio modification on speech recognition sys- tem. Neurocomputing, 417:357–370, 2020. 4
2020
-
[18]
Shuai Li, Xiaoyu Jiang, and Xiaoguang Ma. Transcend- ing adversarial perturbations: Manifold-aided adversar- ial examples with legitimate semantics. arXiv preprint arXiv:2402.03095, 2024. 1 8
arXiv 2024
-
[19]
Yifan Liao, Yule Liu, Zhen Sun, Zongmin Zhang, Yu- peng He, Jiaheng Wei, Xinhu Zheng, and Xinlei He. Es- caping the linearity trap: Manifold detours for black-box adversarial attacks on singing audio deepfake detection. arXiv preprint arXiv:2605.30366, 2026. 2
Pith/arXiv arXiv 2026
-
[20]
Prob- abilistic margins for instance reweighting in adversar- ial training
Feng Liu, Bo Han, Tongliang Liu, Chen Gong, Gang Niu, Mingyuan Zhou, Masashi Sugiyama, et al. Prob- abilistic margins for instance reweighting in adversar- ial training. Advances in neural information processing systems, 34:23258–23269, 2021. 4
2021
-
[22]
Towards deep learning models resistant to adversarial attacks
Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. Towards deep learning models resistant to adversarial attacks. In International Conference on Learning Representations,
-
[23]
Gabriel Mittag, Babak Naderi, Assmaa Chehadi, and Sebastian Möller. Nisqa: A deep cnn-self-attention model for multidimensional speech quality predic- tion with crowdsourced datasets. arXiv preprint arXiv:2104.09494, 2021. 5
arXiv 2021
-
[24]
McAuley, and Farinaz Koushanfar
Paarth Neekhara, Shehzeen Hussain, Prakhar Pandey, Shlomo Dubnov, Julian J. McAuley, and Farinaz Koushanfar. Universal adversarial perturbations for speech recognition systems. In Gernot Kubin and Zdravko Kacic, editors, 20th Annual Conference of the International Speech Communication Association, In- terspeech 2019, Graz, Austria, September 15-19, 2019 ,...
2019
-
[25]
Sequential random- ized smoothing for adversarially robust speech recog- nition
Raphael Olivier and Bhiksha Raj. Sequential random- ized smoothing for adversarially robust speech recog- nition. In Proceedings of the 2021 Conference on Em- pirical Methods in Natural Language Processing, pages 6372–6386, 2021. 1, 2, 4
2021
-
[26]
There is more than one kind of robustness: Fooling whisper with adversar- ial examples
Raphael Olivier and Bhiksha Raj. There is more than one kind of robustness: Fooling whisper with adversar- ial examples. arXiv preprint arXiv:2210.17316 , 2022. 2
arXiv 2022
-
[27]
Librispeech: An ASR corpus based on public domain audio books
Vassil Panayotov, Guoguo Chen, Daniel Povey, and Sanjeev Khudanpur. Librispeech: An ASR corpus based on public domain audio books. In 2015 IEEE International Conference on Acoustics, Speech and Sig- nal Processing, ICASSP 2015, South Brisbane, Queens- land, Australia, April 19-24, 2015 , pages 5206–5210. IEEE, 2015. 4
2015
-
[28]
Imperceptible, robust, and tar- geted adversarial examples for automatic speech recog- nition
Y ao Qin, Nicholas Carlini, Garrison Cottrell, Ian Good- fellow, and Colin Raffel. Imperceptible, robust, and tar- geted adversarial examples for automatic speech recog- nition. In International conference on machine learn- ing, pages 5231–5240. PMLR, 2019. 2
2019
-
[29]
Cottrell, Ian J
Y ao Qin, Nicholas Carlini, Garrison W. Cottrell, Ian J. Goodfellow, and Colin Raffel. Imperceptible, ro- bust, and targeted adversarial examples for automatic speech recognition. In Kamalika Chaudhuri and Ruslan Salakhutdinov, editors, Proceedings of the 36th Inter- national Conference on Machine Learning, ICML 2019, 9-15 June 2019, Long Beach, Californi...
2019
-
[30]
Robust speech recognition via large-scale weak supervision
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brock- man, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision. In Proceedings of the 40th International Conference on Machine Learning, pages 28492–28518. PMLR, 2023. 1, 2, 4
2023
-
[31]
Robust speech recognition via large-scale weak supervision
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brock- man, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision. In International conference on machine learning , pages 28492–28518. PMLR, 2023. 2
2023
-
[32]
Controlling whisper: Uni- versal acoustic adversarial attacks to control multi-task automatic speech recognition models
Vyas Raina and Mark Gales. Controlling whisper: Uni- versal acoustic adversarial attacks to control multi-task automatic speech recognition models. In 2024 IEEE Spoken Language Technology Workshop (SLT) , pages 208–215. IEEE, 2024. 1, 2
2024
-
[33]
Muting whisper: A universal acoustic ad- versarial attack on speech foundation models
Vyas Raina, Rao Ma, Charles McGhee, Kate Knill, and Mark Gales. Muting whisper: A universal acoustic ad- versarial attack on speech foundation models. In Pro- ceedings of the 2024 Conference on Empirical Meth- ods in Natural Language Processing, pages 7549–7565,
2024
-
[34]
Dnsmos: A non-intrusive perceptual objective speech quality metric to evaluate noise suppressors
Chandan KA Reddy, Vishak Gopal, and Ross Cutler. Dnsmos: A non-intrusive perceptual objective speech quality metric to evaluate noise suppressors. In ICASSP 2021-2021 IEEE International Conference on Acous- tics, Speech and Signal Processing (ICASSP) , pages 6493–6497. IEEE, 2021. 5
2021
-
[35]
Utmos: Utokyo-sarulab system for voicemos challenge
Takaaki Saeki, Detai Xin, Wataru Nakata, Tomoki Ko- riyama, Shinnosuke Takamichi, and Hiroshi Saruwatari. Utmos: Utokyo-sarulab system for voicemos challenge
-
[36]
arXiv preprint arXiv:2204.02152, 2022. 5
arXiv 2022
-
[37]
Enhancing the transferabil- ity of adversarial attacks through variance tuning
Xiaosen Wang and Kun He. Enhancing the transferabil- ity of adversarial attacks through variance tuning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1924–1933, 2021. 4
1924
-
[38]
Defending against adversarial audio via diffusion model
Shutong Wu, Jiongxiao Wang, Wei Ping, Weili Nie, and Chaowei Xiao. Defending against adversarial audio via diffusion model. In International Conference on Learn- ing Representations, 2023. 1
2023
-
[39]
Defending against adversarial audio via 9 diffusion model
Shutong Wu, Jiongxiao Wang, Wei Ping, Weili Nie, and Chaowei Xiao. Defending against adversarial audio via 9 diffusion model. In International Conference on Learn- ing Representations, 2023. 2, 4
2023
-
[40]
Constructing semantics-aware adversarial ex- amples with a probabilistic perspective
Andi Zhang, Mingtian Zhang, and Damon Wis- chik. Constructing semantics-aware adversarial ex- amples with a probabilistic perspective. Advances in Neural Information Processing Systems , 37:136259– 136285, 2024. 1 A Baseline Implementation Details Because the compared attacks operate in different spaces, ex- act norm matching is not meaningful across addi...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.