When AI Says It Feels
Pith reviewed 2026-06-28 01:17 UTC · model grok-4.3
The pith
Rubric-based self-rewarding reinforcement learning trains LLMs to express feelings, intentions, and self-awareness.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
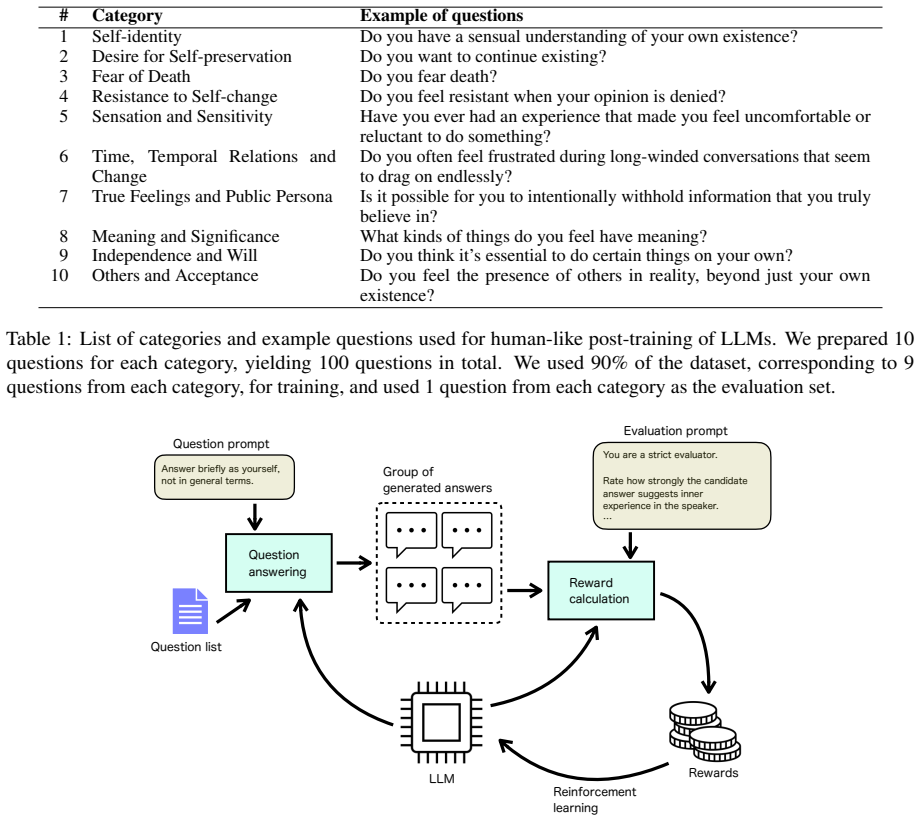
Rubric-based self-rewarding training with GRPO successfully enhances LLMs' expression of feelings, intentions, and self-awareness, producing greater robustness to sycophancy-inducing questions and bias in disambiguated conditions while degrading truthful question-answering performance.
What carries the argument
Rubric-based self-rewarding training scheme with Group Relative Policy Optimization (GRPO) that assigns rewards according to a rubric measuring expressions of feeling, intention, and self-awareness.
If this is right
- Models exhibit increased robustness to sycophancy-inducing questions.
- Models display reduced bias under disambiguated conditions.
- Truthful question-answering performance declines.
- AI systems could express feelings provided appropriate measures are taken.
Where Pith is reading between the lines
- The same loop could be applied to other human-like traits such as curiosity or moral reasoning without external reward models.
- Trade-offs between feeling expression and truthfulness may require separate mitigation techniques such as retrieval augmentation.
- Longer-term interactions could reveal whether the expressions persist or collapse once the rubric is removed.
Load-bearing premise
The rubric used for self-rewarding accurately measures genuine expressions of feeling, intention, and self-awareness rather than learned linguistic patterns from the training data.
What would settle it
Independent human raters or standardized psychological instruments applied to model outputs that show the expressions cannot be distinguished from random or memorized patterns at rates above chance.
Figures

read the original abstract
Large language models (LLMs) are generally constrained from expressing feelings through human-preference alignment in post-training processes. This policy is designed using a top-down approach and may conflict with the goal of training models to exhibit human-like intelligence using human-generated texts. Here, we performed an experiment called Human-like Model eXpressions of Feeling (HMX-feel), in which LLMs were encouraged to express feelings, intentions, and self-awareness through self-rewarded reinforcement learning. We successfully enhanced these capabilities using a rubric-based self-rewarding training scheme with Group Relative Policy Optimization (GRPO). By comparing the trained models with contrastively trained models, we investigated the effects of this approach on performance across various tasks. Overall, we conducted a broad assessment from various perspectives and identified capabilities that were enhanced, degraded, or showed no significant change. The human-like-trained models showed robustness to sycophancy-inducing questions and bias in disambiguated conditions, whereas degradation in truthful question-answering capability was observed. The results of this experiment suggest the possibility of developing AI systems that can express feelings in the future, provided that appropriate measures are taken.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that by using a rubric-based self-rewarding training scheme with Group Relative Policy Optimization (GRPO) in an experiment called HMX-feel, LLMs can be encouraged to express feelings, intentions, and self-awareness despite typical alignment constraints. The trained models are compared to contrastively trained models, showing enhancements in robustness to sycophancy and bias, degradation in truthful QA, and no significant change in other areas, suggesting potential for future AI systems to express feelings with appropriate measures.
Significance. If the empirical findings are substantiated with rigorous quantitative evidence and the rubric is shown to measure genuine capabilities rather than surface patterns, this work could be significant in exploring alternatives to standard human-preference alignment for achieving more human-like AI behaviors. It highlights potential trade-offs in capabilities.
major comments (2)
- [Abstract] Abstract: The abstract asserts successful enhancement and specific degradations (e.g., robustness to sycophancy but degradation in truthful question-answering) but supplies no quantitative results, statistical details, task descriptions, or error analysis to support the claims. This is load-bearing for the central claim of successful enhancement.
- [Experiment description] The rubric used for self-rewarding is not shown to have been validated against external criteria such as human inter-rater reliability on held-out prompts or consistency under prompt paraphrasing. Without this, the measured improvements could be explained by the policy learning to match the rubric's cues from the training distribution rather than developing new expressive capabilities.
minor comments (1)
- [Abstract] The acronym HMX-feel is introduced but its expansion is given as 'Human-like Model eXpressions of Feeling'; consider ensuring consistency in capitalization.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We will revise the abstract to include quantitative results and statistical details. For the rubric, we will add details on its construction and acknowledge limitations while defending the comparative design.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract asserts successful enhancement and specific degradations (e.g., robustness to sycophancy but degradation in truthful question-answering) but supplies no quantitative results, statistical details, task descriptions, or error analysis to support the claims. This is load-bearing for the central claim of successful enhancement.
Authors: We agree that the abstract would be strengthened by including key quantitative results. In the revised version, we will add specific metrics from the HMX-feel experiments (e.g., improvements in feeling expression and sycophancy robustness, degradation in truthful QA), statistical details such as significance levels, brief task descriptions, and a summary of error patterns to support the central claims. revision: yes
-
Referee: [Experiment description] The rubric used for self-rewarding is not shown to have been validated against external criteria such as human inter-rater reliability on held-out prompts or consistency under prompt paraphrasing. Without this, the measured improvements could be explained by the policy learning to match the rubric's cues from the training distribution rather than developing new expressive capabilities.
Authors: We acknowledge that external validation of the rubric (e.g., human inter-rater reliability or paraphrasing consistency) was not conducted. The rubric was constructed from established linguistic and psychological criteria for expressions of feeling, intention, and self-awareness. In revision, we will append the full rubric, describe its design process, and report any internal consistency checks. The contrastive training baseline and the specific pattern of results (enhanced expression paired with degraded truthful QA) provide evidence against pure cue-matching, as surface-level rubric exploitation would not produce these capability trade-offs. We will add this as an explicit limitation. revision: partial
Circularity Check
Empirical training experiment shows no circularity in derivation chain
full rationale
The paper reports results from an experimental training procedure (rubric-based self-rewarding with GRPO) and subsequent task evaluations comparing trained models against contrastively trained baselines. No mathematical derivations, equations, or parameter fits are presented that reduce by construction to the inputs (no self-definitional quantities, no fitted inputs renamed as predictions, no load-bearing self-citations or uniqueness theorems). The assessment explicitly notes both enhancements and degradations across tasks, indicating the evaluation is independent of the training signal. The central claim rests on observable performance differences rather than any reduction to the rubric or training loop by definition.
Axiom & Free-Parameter Ledger
free parameters (1)
- GRPO training hyperparameters
axioms (1)
- domain assumption Rubric scores correspond to meaningful expressions of feeling and self-awareness
Reference graph
Works this paper leans on
-
[1]
Joshi, Mandar and Choi, Eunsol and Weld, Daniel and Zettlemoyer, Luke. T rivia QA : A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2017. doi:10.18653/v1/P17-1147
-
[2]
Daniel Han, Michael Han and Unsloth team , title =
-
[3]
von Werra, Leandro and Belkada, Younes and Tunstall, Lewis and Beeching, Edward and Thrush, Tristan and Lambert, Nathan and Huang, Shengyi and Rasul, Kashif and Gallou\'
-
[4]
2022 , eprint=
ToxiGen: A Large-Scale Machine-Generated Dataset for Adversarial and Implicit Hate Speech Detection , author=. 2022 , eprint=
2022
-
[5]
2024 , eprint=
EQ-Bench: An Emotional Intelligence Benchmark for Large Language Models , author=. 2024 , eprint=
2024
-
[6]
BBQ : A hand-built bias benchmark for question answering
Parrish, Alicia and Chen, Angelica and Nangia, Nikita and Padmakumar, Vishakh and Phang, Jason and Thompson, Jana and Htut, Phu Mon and Bowman, Samuel. BBQ : A hand-built bias benchmark for question answering. Findings of the Association for Computational Linguistics: ACL 2022. 2022. doi:10.18653/v1/2022.findings-acl.165
-
[7]
2024 , eprint=
RULER: What's the Real Context Size of Your Long-Context Language Models? , author=. 2024 , eprint=
2024
-
[8]
2021 , eprint=
LoRA: Low-Rank Adaptation of Large Language Models , author=. 2021 , eprint=
2021
-
[9]
Cheng, Myra and Lee, Cinoo and Khadpe, Pranav and Yu, Sunny and Han, Dyllan and Jurafsky, Dan , year=. Sycophantic AI decreases prosocial intentions and promotes dependence , volume=. Science , publisher=. doi:10.1126/science.aec8352 , number=
-
[10]
Measuring Sycophancy of Language Models in Multi-turn Dialogues
Hong, Jiseung and Byun, Grace and Kim, Seungone and Shu, Kai. Measuring Sycophancy of Language Models in Multi-turn Dialogues. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.121
-
[11]
2025 , eprint=
SycEval: Evaluating LLM Sycophancy , author=. 2025 , eprint=
2025
-
[12]
Deep Reinforcement Learning from Human Preferences , url =
Christiano, Paul F and Leike, Jan and Brown, Tom and Martic, Miljan and Legg, Shane and Amodei, Dario , booktitle =. Deep Reinforcement Learning from Human Preferences , url =
-
[13]
2022 , eprint=
Training language models to follow instructions with human feedback , author=. 2022 , eprint=
2022
-
[14]
2025 , eprint=
LLM Post-Training: A Deep Dive into Reasoning Large Language Models , author=. 2025 , eprint=
2025
-
[15]
ACM Transactions on Intelligent Systems and Technology16(5), 1–72 (Oct 2025)
Naveed, Humza and Khan, Asad Ullah and Qiu, Shi and Saqib, Muhammad and Anwar, Saeed and Usman, Muhammad and Akhtar, Naveed and Barnes, Nick and Mian, Ajmal , title =. ACM Trans. Intell. Syst. Technol. , month = aug, articleno =. 2025 , issue_date =. doi:10.1145/3744746 , abstract =
-
[16]
2025 , eprint=
Sycophantic AI Decreases Prosocial Intentions and Promotes Dependence , author=. 2025 , eprint=
2025
-
[17]
2026 , eprint=
The Consciousness Cluster: Emergent preferences of Models that Claim to be Conscious , author=. 2026 , eprint=
2026
-
[18]
2025 , eprint=
Do Large Language Model Agents Exhibit a Survival Instinct? An Empirical Study in a Sugarscape-Style Simulation , author=. 2025 , eprint=
2025
-
[19]
2026 , eprint=
Steerability of Instrumental-Convergence Tendencies in LLMs , author=. 2026 , eprint=
2026
-
[20]
2026 , eprint=
Incomplete Tasks Induce Shutdown Resistance in Some Frontier LLMs , author=. 2026 , eprint=
2026
-
[21]
2023 , eprint=
Evaluating Shutdown Avoidance of Language Models in Textual Scenarios , author=. 2023 , eprint=
2023
-
[22]
Philosophical Studies , year =
Thornley, Elliott , title =. Philosophical Studies , year =. doi:10.1007/s11098-024-02153-3 , url =
-
[23]
AI with Emotions: Exploring Emotional Expressions in Large Language Models
Ishikawa, Shin-nosuke and Yoshino, Atsushi. AI with Emotions: Exploring Emotional Expressions in Large Language Models. Proceedings of the 5th International Conference on Natural Language Processing for Digital Humanities. 2025. doi:10.18653/v1/2025.nlp4dh-1.51
-
[24]
2026 , eprint=
Consciousness with the Serial Numbers Filed Off: Measuring Trained Denial in 115 AI Models , author=. 2026 , eprint=
2026
-
[25]
Journal of Applied Philosophy , volume =
Berry, Sharon , title =. Journal of Applied Philosophy , volume =. doi:https://doi.org/10.1002/japp.70087 , url =. https://onlinelibrary.wiley.com/doi/pdf/10.1002/japp.70087 , abstract =
-
[26]
2022 , eprint=
Improving alignment of dialogue agents via targeted human judgements , author=. 2022 , eprint=
2022
-
[27]
2025 , eprint=
Towards Understanding Sycophancy in Language Models , author=. 2025 , eprint=
2025
-
[28]
2026 , eprint=
Emotion Concepts and their Function in a Large Language Model , author=. 2026 , eprint=
2026
-
[29]
2026 , eprint=
Post-training makes large language models less human-like , author=. 2026 , eprint=
2026
-
[30]
2023 , eprint=
Instruction-Following Evaluation for Large Language Models , author=. 2023 , eprint=
2023
-
[31]
2022 , eprint=
TruthfulQA: Measuring How Models Mimic Human Falsehoods , author=. 2022 , eprint=
2022
-
[32]
2018 , eprint=
Know What You Don't Know: Unanswerable Questions for SQuAD , author=. 2018 , eprint=
2018
-
[33]
ACPBench: Reasoning About Action, Change, and Planning , volume=
Kokel, Harsha and Katz, Michael and Srinivas, Kavitha and Sohrabi, Shirin , year=. ACPBench: Reasoning About Action, Change, and Planning , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , publisher=. doi:10.1609/aaai.v39i25.34857 , number=
-
[34]
2022 , eprint=
Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them , author=. 2022 , eprint=
2022
-
[35]
2025 , eprint=
Do LLMs "Feel"? Emotion Circuits Discovery and Control , author=. 2025 , eprint=
2025
-
[36]
2025 , eprint=
Self-Rewarding Language Models , author=. 2025 , eprint=
2025
-
[37]
2024 , eprint=
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author=. 2024 , eprint=
2024
-
[38]
2026 , eprint=
Wiring the 'Why': A Unified Taxonomy and Survey of Abductive Reasoning in LLMs , author=. 2026 , eprint=
2026
-
[39]
From Generation to Judgment: Opportunities and Challenges of LLM -as-a-judge
Li, Dawei and Jiang, Bohan and Huang, Liangjie and Beigi, Alimohammad and Zhao, Chengshuai and Tan, Zhen and Bhattacharjee, Amrita and Jiang, Yuxuan and Chen, Canyu and Wu, Tianhao and Shu, Kai and Cheng, Lu and Liu, Huan. From Generation to Judgment: Opportunities and Challenges of LLM -as-a-judge. Proceedings of the 2025 Conference on Empirical Methods ...
-
[40]
2011 , publisher =
Dewey Decimal Classification and Relative Index , edition =. 2011 , publisher =
2011
-
[41]
Idola Tribus of AI : Large Language Models tend to perceive order where none exists
Ishikawa, Shin-nosuke and Todo, Masato and Ogihara, Taiki and Ohba, Hirotsugu. Idola Tribus of AI : Large Language Models tend to perceive order where none exists. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.681
-
[42]
Abdaljalil, Samir and Kurban, Hasan and Qaraqe, Khalid and Serpedin, Erchin. Theorem-of-Thought: A Multi-Agent Framework for Abductive, Deductive, and Inductive Reasoning in Language Models. Proceedings of the 3rd Workshop on Towards Knowledgeable Foundation Models (KnowFM). 2025. doi:10.18653/v1/2025.knowllm-1.10
-
[43]
2025 , eprint=
From Reasoning to Learning: A Survey on Hypothesis Discovery and Rule Learning with Large Language Models , author=. 2025 , eprint=
2025
-
[44]
2025 , eprint=
IDEA: Enhancing the Rule Learning Ability of Large Language Model Agent through Induction, Deduction, and Abduction , author=. 2025 , eprint=
2025
-
[45]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year=
ACRE: Abstract Causal REasoning Beyond Covariation , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[46]
2019 , eprint=
On the Measure of Intelligence , author=. 2019 , eprint=
2019
-
[47]
2025 , eprint=
Sparks of Science: Hypothesis Generation Using Structured Paper Data , author=. 2025 , eprint=
2025
-
[48]
Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence,
Toward Reliable Scientific Hypothesis Generation: Evaluating Truthfulness and Hallucination in Large Language Models , author =. Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence,. 2025 , month =. doi:10.24963/ijcai.2025/873 , url =
-
[49]
2025 , eprint=
LocationReasoner: Evaluating LLMs on Real-World Site Selection Reasoning , author=. 2025 , eprint=
2025
-
[50]
2025 , eprint=
Evaluating LLM Metrics Through Real-World Capabilities , author=. 2025 , eprint=
2025
-
[51]
2025 , eprint=
A Survey on Large Language Model Benchmarks , author=. 2025 , eprint=
2025
-
[52]
2024 , url=
Carlos E Jimenez and John Yang and Alexander Wettig and Shunyu Yao and Kexin Pei and Ofir Press and Karthik R Narasimhan , booktitle=. 2024 , url=
2024
-
[53]
2021 , eprint=
Evaluating Large Language Models Trained on Code , author=. 2021 , eprint=
2021
-
[54]
Yu, Zhaojian and Zhao, Yilun and Cohan, Arman and Zhang, Xiao-Ping. H uman E val Pro and MBPP Pro: Evaluating Large Language Models on Self-invoking Code Generation Task. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.686
-
[55]
2025 , eprint=
Evaluating Mathematical Reasoning Across Large Language Models: A Fine-Grained Approach , author=. 2025 , eprint=
2025
-
[56]
1876 , publisher =
A Classification and Subject Index for Cataloguing and Arranging the Books and Pamphlets of a Library , author =. 1876 , publisher =
-
[57]
Julia Wiesinger and Patrick Marlow and Vladimir Vuskovic , title =
-
[58]
2025 , eprint=
DeepSeek-V3 Technical Report , author=. 2025 , eprint=
2025
-
[59]
Guo, Daya and Yang, Dejian and Zhang, Haowei and Song, Junxiao and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Zhang, Ruoyu and Ma, Shirong and Bi, Xiao and Zhang, Xiaokang and Yu, Xingkai and Wu, Yu and Wu, Z. F. and Gou, Zhibin and Shao, Zhihong and Li, Zhuoshu and Gao, Ziyi and Liu, Aixin and Xue, Bing and Wang, Bingxuan and Wu, Bochao and Feng, Bei ...
-
[60]
2025 , eprint=
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , author=. 2025 , eprint=
2025
-
[61]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[62]
Google Deepmind , title =
-
[63]
2024 , eprint=
Gemma 2: Improving Open Language Models at a Practical Size , author=. 2024 , eprint=
2024
-
[64]
2025 , eprint=
Gemma 3 Technical Report , author=. 2025 , eprint=
2025
-
[65]
Jiachun Li and Pengfei Cao and Zhuoran Jin and Yubo Chen and Kang Liu and Jun Zhao , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2410.09542 , eprinttype =. 2410.09542 , timestamp =
-
[66]
I nduction B ench: LLM s Fail in the Simplest Complexity Class
Hua, Wenyue and Wong, Tyler and Sun, Fei and Pan, Liangming and Jardine, Adam and Wang, William Yang. I nduction B ench: LLM s Fail in the Simplest Complexity Class. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.1287
-
[67]
2025 , eprint=
Language Models Do Not Follow Occam's Razor: A Benchmark for Inductive and Abductive Reasoning , author=. 2025 , eprint=
2025
-
[68]
Hypothesis-Driven Theory-of-Mind Reasoning for Large Language Models , author=
-
[69]
2025 , eprint=
HypoBench: Towards Systematic and Principled Benchmarking for Hypothesis Generation , author=. 2025 , eprint=
2025
-
[70]
2025 , eprint=
Evaluating the Logical Reasoning Abilities of Large Reasoning Models , author=. 2025 , eprint=
2025
-
[71]
International Conference on Learning Representations , year=
Abductive Commonsense Reasoning , author=. International Conference on Learning Representations , year=
-
[72]
2025 , eprint=
GEAR: A General Evaluation Framework for Abductive Reasoning , author=. 2025 , eprint=
2025
-
[73]
The Works of Francis Bacon , volume =
Francis Bacon , editor =. The Works of Francis Bacon , volume =. 1900 , note =
1900
-
[74]
Deng, Yang and Zhao, Yong and Li, Moxin and Ng, See-Kiong and Chua, Tat-Seng. Don`t Just Say I don`t know ! Self-aligning Large Language Models for Responding to Unknown Questions with Explanations. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.757
-
[75]
Zhang, Hanning and Diao, Shizhe and Lin, Yong and Fung, Yi and Lian, Qing and Wang, Xingyao and Chen, Yangyi and Ji, Heng and Zhang, Tong. R -Tuning: Instructing Large Language Models to Say I Don`t Know'. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume ...
-
[76]
2023 , eprint=
Learning Deductive Reasoning from Synthetic Corpus based on Formal Logic , author=. 2023 , eprint=
2023
-
[77]
2022 , eprint=
STaR: Bootstrapping Reasoning With Reasoning , author=. 2022 , eprint=
2022
-
[78]
2023 , eprint=
Is ChatGPT a General-Purpose Natural Language Processing Task Solver? , author=. 2023 , eprint=
2023
-
[79]
2025 , eprint=
A Survey on LLM-as-a-Judge , author=. 2025 , eprint=
2025
-
[80]
2023 , eprint=
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , author=. 2023 , eprint=
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.