Where does Absolute Position come from in decoder-only Transformers?
Pith reviewed 2026-06-28 01:21 UTC · model grok-4.3
The pith
RoPE-trained decoder-only transformers distinguish absolute position in attention patterns through the causal mask and residual stream.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
RoPE-trained transformers distinguish absolute position in their attention patterns, even though RoPE encodes only relative offsets in the inner product. We trace this leakage to two architectural components: the causal mask is responsible for the first as its per-query softmax denominator depends on the absolute query position by construction; the residual stream supplies the second as the activation at position 0 attends only to itself and runs as a closed dynamical system from the embedding of the token at that position, which downstream attention reads through sink-reading heads. Both components appear in all three architectures we study, in architecturally specific balance.
What carries the argument
Causal mask and residual stream, where position-zero activations form a closed dynamical system whose trajectory is read by sink-reading heads.
If this is right
- NTK scaling suppresses the residual-stream component of absolute position leakage.
- Sliding-window attention allows the residual component to accumulate with depth.
- Standard RoPE balances the two leakage sources between the other variants.
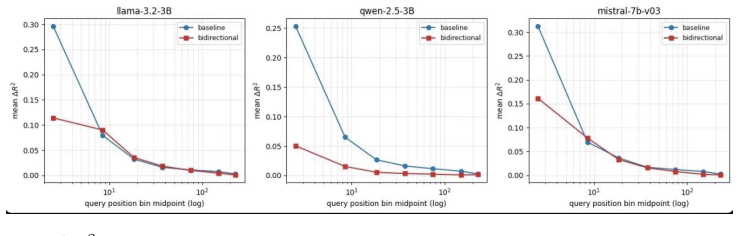
- Replacing the BOS embedding removes forty percent of the residual-stream component at early queries.
- Attention sinks act as token-anchored stabilizers that forward a deterministic fingerprint of the position-zero token.
Where Pith is reading between the lines
- Controlling the initial token embedding offers a direct way to adjust how much absolute position information reaches later layers.
- The same mechanism may underlie attention-sink behavior observed across many decoder-only models.
- Models that do not auto-prepend a fixed BOS token would carry a fingerprint that changes with the actual first input token.
Load-bearing premise
The per-query softmax denominator under the causal mask depends on absolute query position by construction, and the activation at position 0 runs as a closed dynamical system whose trajectory is read downstream by sink-reading heads.
What would settle it
Measure attention weights after replacing the BOS embedding or removing the causal mask and check whether absolute-position distinctions in the patterns disappear.
Figures
read the original abstract
RoPE-trained transformers distinguish absolute position in their attention patterns, even though RoPE encodes only relative offsets in the inner product. We trace this leakage to two architectural components, The causal mask is responsible for the first: its per-query softmax denominator depends on the absolute query position by construction. The residual stream supplies the second. Under causal attention the activation at position $0$ attends only to itself and runs as a closed dynamical system from the embedding of the token at that position; downstream attention reads this trajectory through sink-reading heads. Both components appear in all three architectures we study, in architecturally specific balance: NTK scaling suppresses the residual-stream component, sliding-window attention allows it to accumulate with depth, and standard RoPE sits between. Replacing the \texttt{BOS} embedding before the forward pass removes $40\%$ of the residual-stream component at early queries. Attention sinks are token-anchored stabilizers that pass forward a deterministic fingerprint of the token at position $0$, constant across inputs when that token is the auto-prepended \texttt{BOS} and varying with it otherwise.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that RoPE-trained decoder-only transformers exhibit absolute position information in their attention patterns despite RoPE providing only relative offsets in inner products. This leakage is traced to two sources: the causal mask, whose per-query softmax normalization depends on absolute query position by construction, and the residual stream, where the position-0 activation forms a closed dynamical system under causal attention and is read downstream by sink-reading heads. The relative strength of these channels varies across standard RoPE, NTK scaling, and sliding-window attention; replacing the BOS embedding is reported to remove 40% of the residual-stream component.
Significance. If the tracing and measurements are robust, the work supplies a mechanistic account of how absolute positional cues arise from standard decoder-only components even under relative encodings. The explicit comparison across architectural variants (NTK, sliding windows) and the BOS ablation provide concrete, falsifiable observations that could inform positional encoding design and attention analysis in long-context models.
major comments (2)
- [Abstract] Abstract: the 40% removal figure upon BOS replacement is presented as evidence for the residual-stream channel, yet no measurement protocol, layers/heads, distance metric, or statistical controls are supplied; without these the quantitative attribution to the residual stream cannot be evaluated.
- [Abstract] Abstract: while the causal-mask softmax denominator indeed grows with absolute query index, the manuscript does not show a controlled isolation (e.g., via an equation or ablation) demonstrating how much of the observed absolute-position distinction in attention patterns is produced by this denominator versus the residual-stream channel.
minor comments (2)
- The terms 'sink-reading heads' and 'attention sinks' are used without a concise definition or pointer to their first appearance; a one-sentence gloss would aid readers.
- Consider adding a small table or figure panel that tabulates the relative contribution of the two channels for each of the three architectures studied.
Simulated Author's Rebuttal
We thank the referee for the careful review and the recommendation of minor revision. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the 40% removal figure upon BOS replacement is presented as evidence for the residual-stream channel, yet no measurement protocol, layers/heads, distance metric, or statistical controls are supplied; without these the quantitative attribution to the residual stream cannot be evaluated.
Authors: We agree that the abstract does not supply the measurement protocol, layers/heads, distance metric, or statistical controls. We will revise the abstract to include these details so that the 40% figure can be properly evaluated. revision: yes
-
Referee: [Abstract] Abstract: while the causal-mask softmax denominator indeed grows with absolute query index, the manuscript does not show a controlled isolation (e.g., via an equation or ablation) demonstrating how much of the observed absolute-position distinction in attention patterns is produced by this denominator versus the residual-stream channel.
Authors: We agree that the current manuscript does not include a controlled isolation of the two channels. We will add an equation formalizing the position dependence of the softmax denominator together with an ablation that holds the denominator fixed, to quantify the separate contribution of each source. revision: yes
Circularity Check
No significant circularity
full rationale
The paper offers an observational architectural analysis tracing absolute-position leakage to the causal mask's position-dependent softmax normalization and the position-0 residual stream's closed dynamics under self-attention. These follow directly from standard decoder-only definitions once RoPE supplies only relative inner products; no equations, fitted parameters, or self-citations are invoked to force the claimed mechanisms. The account remains self-contained against external architectural benchmarks with no reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The causal mask's per-query softmax denominator depends on absolute query position by construction.
invented entities (2)
-
sink-reading heads
no independent evidence
-
attention sinks
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
Neurocomputing , volume=
Roformer: Enhanced transformer with rotary position embedding , author=. Neurocomputing , volume=. 2024 , publisher=
2024
-
[9]
Advances in Neural Information Processing Systems , volume=
The impact of positional encoding on length generalization in transformers , author=. Advances in Neural Information Processing Systems , volume=
-
[10]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Beyond Position: the emergence of wavelet-like properties in Transformers , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[11]
International Conference on Learning Representations , volume=
Efficient streaming language models with attention sinks , author=. International Conference on Learning Representations , volume=
-
[12]
International Conference on Learning Representations , volume=
When attention sink emerges in language models: An empirical view , author=. International Conference on Learning Representations , volume=
-
[13]
Advances in Neural Information Processing Systems , volume=
What are you sinking? a geometric approach on attention sink , author=. Advances in Neural Information Processing Systems , volume=
-
[14]
arXiv preprint arXiv:2108.12409 , year=
Train short, test long: Attention with linear biases enables input length extrapolation , author=. arXiv preprint arXiv:2108.12409 , year=
-
[15]
International Conference on Learning Representations , volume=
Yarn: Efficient context window extension of large language models , author=. International Conference on Learning Representations , volume=
-
[16]
Understanding Transformer Memorization Recall Through Idioms
Haviv, Adi and Cohen, Ido and Gidron, Jacob and Schuster, Roei and Goldberg, Yoav and Geva, Mor. Understanding Transformer Memorization Recall Through Idioms. Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics. 2023. doi:10.18653/v1/2023.eacl-main.19
-
[17]
arXiv preprint arXiv:2209.11895 , year=
In-context learning and induction heads , author=. arXiv preprint arXiv:2209.11895 , year=
-
[18]
Interpretability in the Wild: a Circuit for Indirect Object Identification in
Kevin Ro Wang and Alexandre Variengien and Arthur Conmy and Buck Shlegeris and Jacob Steinhardt , booktitle=. Interpretability in the Wild: a Circuit for Indirect Object Identification in. 2023 , url=
2023
-
[19]
arXiv preprint arXiv:2407.21783 , year=
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
-
[20]
5-coder technical report , author=
Qwen2. 5-coder technical report , author=. arXiv preprint arXiv:2409.12186 , year=
-
[21]
Jiang, Albert Q. and Sablayrolles, Alexandre and Mensch, Arthur and Bamford, Chris and Chaplot, Devendra Singh and de Las Casas, Diego and Bressand, Florian and Lengyel, Gianna and Lample, Guillaume and Saulnier, Lucile and Lavaud, L. Mistral 7B , url =. CoRR , keywords =. doi:10.48550/ARXIV.2310.06825 , eprint =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.06825
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.