Complexity-Balanced Diffusion Splitting
Pith reviewed 2026-06-28 02:18 UTC · model grok-4.3
The pith
Diffusion models improve by splitting the timeline into segments of equal modeling difficulty.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By grounding temporal partitioning in function approximation theory and de Boor's equidistribution principle, Complexity-Balanced Splitting allocates representational capacity proportionally to the local complexity of the generative dynamics, using tractable spatial and geometric monitor functions estimated by an auxiliary model, which yields higher-quality samples than uniform monolithic networks or naive splits while preserving inference speed.
What carries the argument
Complexity-Balanced Splitting (CBS), which partitions the diffusion timeline into segments of equal approximation burden according to Dirichlet energy and trajectory acceleration monitor functions estimated by a lightweight auxiliary model.
If this is right
- CBS raises synthesis quality, for example by roughly 35 percent lower FID on SiT-XL with classifier-free guidance, compared with naive temporal partitioning.
- The same per-step inference cost is maintained because each sub-network is used only on its assigned segment.
- The method works across SiT, JiT, and UNet backbones and multiple datasets without requiring architecture-specific heuristics.
- The auxiliary model removes the need for manual split design or expensive optimization searches.
Where Pith is reading between the lines
- The same splitting logic could be tested on video or 3D generative models where temporal or spatial complexity varies even more sharply.
- If the monitor functions correlate with known failure modes such as mode collapse, they might serve as diagnostic tools beyond capacity allocation.
- Specialized sub-networks trained on single segments might transfer to other diffusion schedules that share similar complexity profiles.
Load-bearing premise
The lightweight auxiliary model can estimate the two monitor functions accurately enough across the entire timeline that its own training and inference costs do not offset the quality gains from better capacity allocation.
What would settle it
Running the full CBS pipeline including auxiliary-model training produces either lower FID or higher total training time than a monolithic baseline or a naive fixed split on identical hardware and data.
Figures

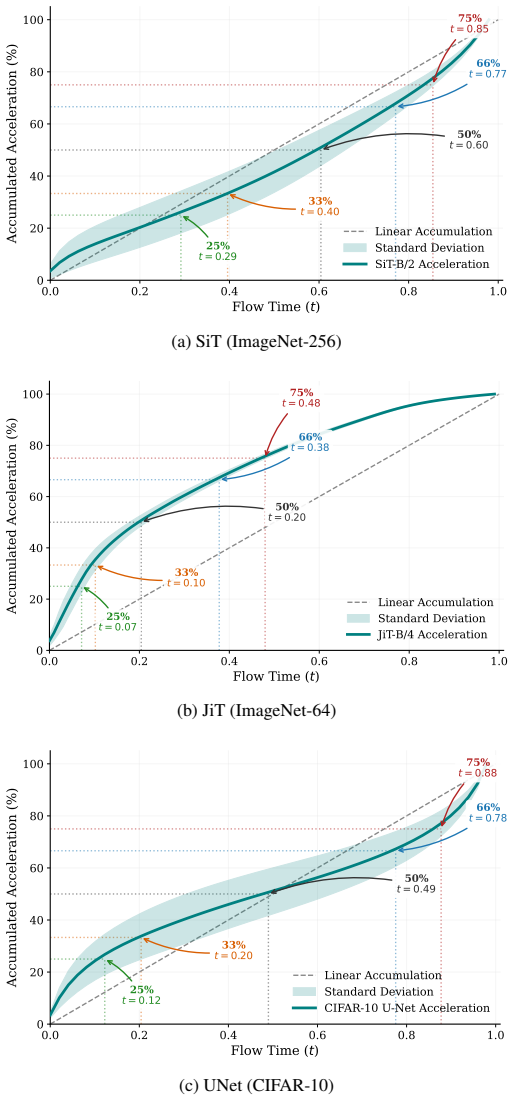
read the original abstract
Standard continuous-time generative models rely on monolithic architectures that must navigate vastly different signal regimes, from isotropic noise to intricate data distributions. While scaling model capacity improves performance, deploying a massive network uniformly across the entire generative timeline is inherently inefficient. In this work, we propose Complexity-Balanced Splitting (CBS), a principled framework for temporal capacity allocation that distributes the generative workload across multiple specialized sub-networks. Grounded in function approximation theory and de Boor's equidistribution principle, CBS partitions the diffusion timeline into segments of equal approximation burden, allocating more representational capacity to regions where the generative dynamics are more difficult to model. To estimate this local complexity, we introduce two complementary and tractable monitor functions: a spatial measure based on the flow's Dirichlet energy, and a geometric measure based on the acceleration of the sampling trajectories. Using a lightweight auxiliary model to estimate these complexity profiles, our approach eliminates the need for heuristic temporal splits or computationally expensive search procedures. Extensive evaluation across multiple architectures (SiT, JiT, and UNet) and datasets demonstrates that CBS consistently improves synthesis quality without increasing per-step inference cost. In particular, CBS improves FID by ~35% on SiT-XL with CFG relative to naive temporal partitioning. Project page is available at https://noamissachar.github.io/CBS/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Complexity-Balanced Splitting (CBS) for continuous-time generative models. It partitions the diffusion timeline into segments of equal approximation burden via de Boor's equidistribution principle, using two monitor functions (spatial: flow Dirichlet energy; geometric: sampling trajectory acceleration) estimated by a lightweight auxiliary model. This is claimed to allocate capacity more efficiently than monolithic networks or naive splits, yielding ~35% FID improvement on SiT-XL with CFG across SiT, JiT, and UNet architectures without raising per-step inference cost.
Significance. If the auxiliary estimates are shown to be faithful proxies, CBS supplies a theory-grounded alternative to heuristic temporal partitioning and could improve quality-efficiency trade-offs in scaled diffusion models. The approach is notable for attempting to reduce reliance on search procedures, though this hinges on the unverified fidelity of the monitors.
major comments (3)
- [§4] §4 (Auxiliary Model and Monitor Estimation): The central claim that CBS 'eliminates the need for heuristic temporal splits or computationally expensive search procedures' rests on the auxiliary model producing sufficiently accurate estimates of Dirichlet energy and trajectory acceleration. No quantitative fidelity check (e.g., correlation with direct computation on held-out trajectories, error bounds, or ablation of auxiliary capacity) is reported; without this, the equidistributed partitions may not equalize burden and the FID gains could arise from the particular split chosen rather than the method.
- [Table 3 / §5.3] Table 3 / §5.3 (FID results on SiT-XL with CFG): The reported ~35% FID improvement versus 'naive temporal partitioning' lacks specification of how the naive baseline split was chosen, whether multiple random seeds or error bars are shown, and whether the CBS split was selected post-hoc among several candidates. This makes it impossible to assess whether the gain is robust or attributable to the complexity-balancing principle.
- [§3.2] §3.2 (de Boor's equidistribution application): The derivation assumes the two monitor functions are faithful proxies for local generative complexity, yet the paper supplies no empirical test that equalizing these monitors actually equalizes approximation error across segments (e.g., via per-segment reconstruction error or Lipschitz constants). This assumption is load-bearing for the claim that the resulting allocation is 'complexity-balanced.'
minor comments (2)
- Notation for the two monitor functions (Dirichlet energy and acceleration) is introduced without a compact summary table relating them to the underlying flow ODE; a small table would improve readability.
- The abstract states 'extensive evaluation across multiple architectures,' yet the main text provides limited detail on training schedules or hyper-parameters of the auxiliary model itself; these should be reported for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and will revise the manuscript to incorporate the requested clarifications, ablations, and empirical checks.
read point-by-point responses
-
Referee: [§4] The central claim that CBS 'eliminates the need for heuristic temporal splits or computationally expensive search procedures' rests on the auxiliary model producing sufficiently accurate estimates of Dirichlet energy and trajectory acceleration. No quantitative fidelity check (e.g., correlation with direct computation on held-out trajectories, error bounds, or ablation of auxiliary capacity) is reported.
Authors: We agree that a direct quantitative fidelity assessment of the auxiliary model is necessary to substantiate the claim. In the revised manuscript we will add a new subsection (or appendix) reporting correlation coefficients, mean absolute errors, and capacity ablations between auxiliary estimates and direct Monte-Carlo computations on held-out trajectories for both monitor functions. This will allow readers to evaluate the reliability of the estimates independently of the final FID numbers. revision: yes
-
Referee: [Table 3 / §5.3] The reported ~35% FID improvement versus 'naive temporal partitioning' lacks specification of how the naive baseline split was chosen, whether multiple random seeds or error bars are shown, and whether the CBS split was selected post-hoc among several candidates.
Authors: We will revise §5.3 and the caption of Table 3 to explicitly state that the naïve baseline uses uniform temporal partitioning (equal-length segments), that all reported FID values are means and standard deviations over three independent training seeds, and that the CBS partition is obtained deterministically from the auxiliary monitors without any post-hoc selection or search. These details will be added to the experimental protocol description. revision: yes
-
Referee: [§3.2] The derivation assumes the two monitor functions are faithful proxies for local generative complexity, yet the paper supplies no empirical test that equalizing these monitors actually equalizes approximation error across segments (e.g., via per-segment reconstruction error or Lipschitz constants).
Authors: We acknowledge that the manuscript currently relies on the theoretical motivation of the monitors without a direct empirical link to per-segment approximation error. In the revision we will add an experiment (new figure or table in §3.2 or §5) that computes per-segment reconstruction error and effective Lipschitz constants on a held-out validation set for both the equidistributed CBS partitions and uniform partitions, thereby testing whether equalizing the monitors reduces variation in local approximation burden. revision: yes
Circularity Check
No circularity: derivation applies external equidistribution principle via independent auxiliary estimator
full rationale
The paper grounds its partitioning in de Boor's equidistribution principle from function approximation theory and introduces a new lightweight auxiliary model to estimate the two monitor functions (Dirichlet energy and trajectory acceleration). These elements are presented as external inputs and a novel component, respectively, rather than any quantity being defined in terms of itself or a prior self-citation. No equation or claim reduces a 'prediction' to a fitted parameter by construction, nor does any load-bearing step rely on a self-citation chain. The reported FID gains are framed as empirical results of applying the method, not tautological consequences of the setup. The construction is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- auxiliary model capacity and training schedule
- number of timeline segments
axioms (2)
- domain assumption de Boor's equidistribution principle can be applied directly to the generative flow to produce segments of equal approximation difficulty
- ad hoc to paper The Dirichlet energy of the flow and the acceleration of sampling trajectories are faithful proxies for local generative complexity
invented entities (2)
-
spatial monitor based on flow Dirichlet energy
no independent evidence
-
geometric monitor based on trajectory acceleration
no independent evidence
Reference graph
Works this paper leans on
-
[1]
eDiff-I: Text-to-Image Diffusion Models with an Ensemble of Expert Denoisers
Y . Balaji, S. Nah, X. Huang, A. Vahdat, J. Song, Q. Zhang, K. Kreis, M. Aittala, T. Aila, S. Laine, et al. ediff-i: Text-to-image diffusion models with an ensemble of expert denoisers. arXiv preprint arXiv:2211.01324, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
A. R. Barron. Universal approximation bounds for superpositions of a sigmoidal function.IEEE Transactions on Information theory, 39(3):930–945, 2002
2002
-
[3]
FLUX.https://github.com/black-forest-labs/flux, 2024
Black Forest Labs. FLUX.https://github.com/black-forest-labs/flux, 2024
2024
-
[4]
Cheng, X
K. Cheng, X. He, L. Yu, Z. Tu, M. Zhu, N. Wang, X. Gao, and J. Hu. Diff-moe: Diffusion trans- former with time-aware and space-adaptive experts. InForty-second International Conference on Machine Learning, 2025
2025
-
[5]
C. de Boor. Good approximation by splines with variable knots. In A. Meir and A. Sharma, editors,Spline Functions and Approximation Theory, volume 21 ofInternational Series of Numerical Mathematics / ISNM, pages 57–72. Birkhäuser Basel, 1973
1973
-
[6]
Z. Feng, Z. Zhang, X. Yu, Y . Fang, L. Li, X. Chen, Y . Lu, J. Liu, W. Yin, S. Feng, et al. Ernie-vilg 2.0: Improving text-to-image diffusion model with knowledge-enhanced mixture- of-denoising-experts. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10135–10145, 2023
2023
-
[7]
Finlay, J.-H
C. Finlay, J.-H. Jacobsen, L. Nurbekyan, and A. Oberman. How to train your neural ode: the world of jacobian and kinetic regularization. InInternational conference on machine learning, pages 3154–3164. PMLR, 2020
2020
-
[8]
Gallier.Curves and surfaces in geometric modeling: theory and algorithms
J. Gallier.Curves and surfaces in geometric modeling: theory and algorithms. Morgan Kaufmann Publishers Inc., San Francisco, CA, USA, 1999
1999
-
[9]
T. H. Gronwall. Note on the derivatives with respect to a parameter of the solutions of a system of differential equations.Annals of Mathematics, 20(4):292–296, 1919. 10
1919
-
[10]
Heusel, H
M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
2017
-
[11]
J. Ho, A. Jain, and P. Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[12]
J. Ho, C. Saharia, W. Chan, D. J. Fleet, M. Norouzi, and T. Salimans. Cascaded diffusion models for high fidelity image generation.Journal of Machine Learning Research, 23(47):1–33, 2022
2022
-
[13]
Classifier-Free Diffusion Guidance
J. Ho and T. Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[14]
Training Compute-Optimal Large Language Models
J. Hoffmann, S. Borgeaud, A. Mensch, E. Buchatskaya, T. Cai, E. Rutherford, D. Casas, L. A. Hendricks, J. Welbl, A. Clark, et al. Training compute-optimal large language models.arXiv preprint arXiv:2203.15556, 10, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[15]
M. F. Hutchinson. A stochastic estimator of the trace of the influence matrix for Laplacian smoothing splines.Communications in Statistics-Simulation and Computation, 19(2):433–450, 1990
1990
-
[16]
Scaling Laws for Neural Language Models
J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Rad- ford, J. Wu, and D. Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[17]
Kelly, J
J. Kelly, J. Bettencourt, M. J. Johnson, and D. K. Duvenaud. Learning differential equations that are easy to solve.Advances in Neural Information Processing Systems, 33:4370–4380, 2020
2020
-
[18]
Kynkäänniemi, T
T. Kynkäänniemi, T. Karras, S. Laine, J. Lehtinen, and T. Aila. Improved precision and recall metric for assessing generative models.Advances in neural information processing systems, 32, 2019
2019
-
[19]
Y . Lee, J. Kim, H. Go, M. Jeong, S. Oh, and S. Choi. Multi-architecture multi-expert diffusion models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 13427–13436, 2024
2024
-
[20]
Back to Basics: Let Denoising Generative Models Denoise
T. Li and K. He. Back to basics: Let denoising generative models denoise.arXiv preprint arXiv:2511.13720, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [21]
-
[22]
Flow Matching for Generative Modeling
Y . Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[23]
N. Ma, M. Goldstein, M. S. Albergo, N. M. Boffi, E. Vanden-Eijnden, and S. Xie. Sit: Exploring flow and diffusion-based generative models with scalable interpolant transformers. InEuropean Conference on Computer Vision, pages 23–40. Springer, 2024
2024
-
[24]
B. Park, H. Go, J.-Y . Kim, S. Woo, S. Ham, and C. Kim. Switch diffusion transformer: Synergizing denoising tasks with sparse mixture-of-experts. InEuropean Conference on Computer Vision, pages 461–477. Springer, 2024
2024
- [25]
-
[26]
Peebles and S
W. Peebles and S. Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
2023
-
[27]
Ronneberger, P
O. Ronneberger, P. Fischer, and T. Brox. U-net: Convolutional networks for biomedical image segmentation. InInternational Conference on Medical image computing and computer-assisted intervention, pages 234–241. Springer, 2015
2015
-
[28]
W. Rudin. Principles of mathematical analysis. 2021. 11
2021
-
[29]
Salimans, I
T. Salimans, I. Goodfellow, W. Zaremba, V . Cheung, A. Radford, and X. Chen. Improved techniques for training gans.Advances in neural information processing systems, 29, 2016
2016
-
[30]
Progressive Distillation for Fast Sampling of Diffusion Models
T. Salimans and J. Ho. Progressive distillation for fast sampling of diffusion models.arXiv preprint arXiv:2202.00512, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[31]
Y . Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[32]
C. Wu, J. Li, J. Zhou, J. Lin, K. Gao, K. Yan, S.-m. Yin, S. Bai, X. Xu, Y . Chen, et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Z. Xue, G. Song, Q. Guo, B. Liu, Z. Zong, Y . Liu, and P. Luo. Raphael: Text-to-image generation via large mixture of diffusion paths.Advances in Neural Information Processing Systems, 36:41693–41706, 2023
2023
-
[34]
Yarotsky
D. Yarotsky. Error bounds for approximations with deep relu networks.Neural Networks, 94:103–114, 2017. 12 A Bounding Spectral Complexity via Dirichlet Energy In this section, we formally derive the relationship between the spectral complexity Cvt and the Dirichlet energyE D(vt)using the Cauchy-Schwarz inequality. Recall the definition of the spectral com...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.