NTILC: Neural Tool Invocation via Learned Compression
Pith reviewed 2026-06-28 00:03 UTC · model grok-4.3
The pith
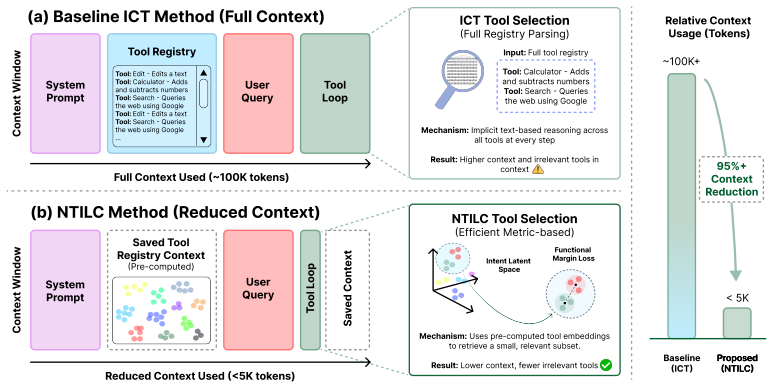
NTILC learns shared embeddings to retrieve tools externally instead of listing full specifications in every prompt.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
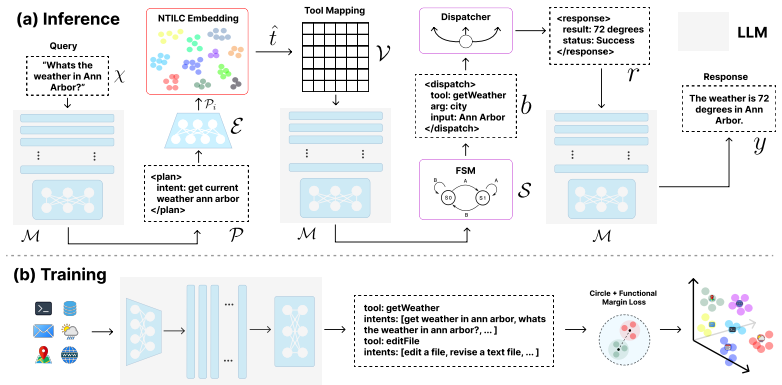
NTILC maps both user intent and tool specifications into a shared embedding space, enabling tool selection via external retrieval rather than in-context lookup. The language model is conditioned only on the selected tool schema, allowing for precise, constrained argument generation. Central to the approach is a signature-aware composite objective that augments semantic similarity with constraints derived from tool signatures by combining Circle Loss with a Functional Margin Loss to enforce separation between tools that are semantically similar but incompatible under their execution signatures.
What carries the argument
Signature-aware composite objective that combines Circle Loss with Functional Margin Loss to separate tools by both semantic similarity and execution-signature compatibility.
If this is right
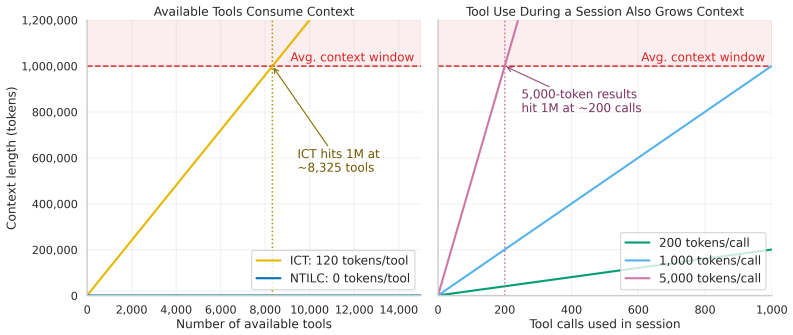
- Context token consumption drops by more than 95 percent relative to long-context in-context tool baselines.
- Inference latency falls by as much as 74 percent on the same tasks.
- The model receives only the schema of the retrieved tool and therefore generates arguments under explicit type and arity constraints.
- Evaluation covers both public tool-selection benchmarks and function-calling datasets.
- The same framework applies to any registry whose members can be described by a signature of arguments and return types.
Where Pith is reading between the lines
- The method opens the possibility of maintaining registries that are orders of magnitude larger than any single context window can hold.
- External retrieval could be updated in real time without retraining the language model itself.
- The same embedding-plus-signature technique might be reused for other selection problems such as API endpoint routing or plugin discovery.
- If retrieval accuracy holds, the architecture decouples tool inventory size from prompt length, changing how agent systems are deployed at scale.
Load-bearing premise
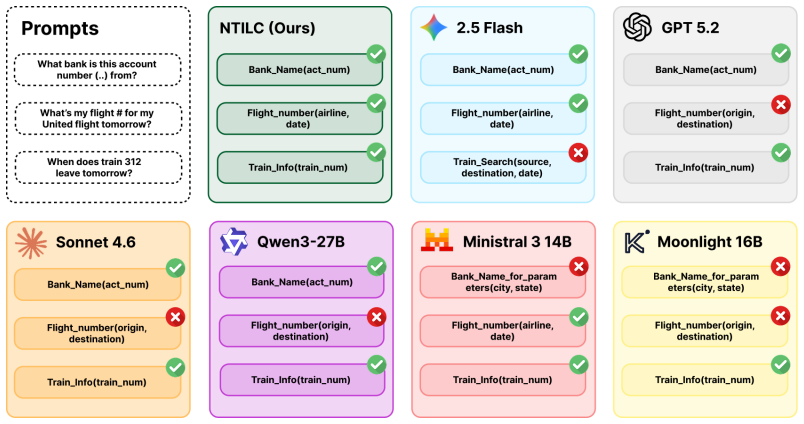
The learned embeddings will continue to retrieve the correct tool with high accuracy when the full registry is no longer supplied inside the prompt.
What would settle it
A controlled test on a registry of several hundred tools where retrieval accuracy falls below the in-context baseline or where the reported 95 percent context reduction is not observed.
Figures
read the original abstract
Agentic tool-calling language models depend on large registries of callable APIs, functions, and local actions. Placing full tool specifications directly in the prompt incurs a cost that scales linearly with the size of the tool registry, rapidly consuming the context budget. As the registry grows, this leads to higher latency and degrades selection accuracy, particularly due to interference from irrelevant tools. We overcome these limitations by introducing NTILC, a neural tool selection and invocation framework that replaces in-context registry look-up with learned latent retrieval. NTILC maps both user intent and tool specifications into a shared embedding space, enabling tool selection via external retrieval rather than in-context lookup. The language model is conditioned only on the selected tool schema, allowing for precise, constrained argument generation. Central to our approach is a signature-aware composite objective, which augments semantic similarity with constraints derived from tool signatures (e.g., argument schema, type compatibility, and return types). By combining Circle Loss with a Functional Margin Loss, the model enforces separation between tools that are semantically similar but incompatible under their execution signatures. We evaluate NTILC on public tool-selection and function-calling datasets and report context token usage, retrieval accuracy, and selection latency metrics. Across these settings, NTILC reduces context window consumption by over 95% and inference latency by up to 74% compared to long-context ICT baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces NTILC, a neural tool selection and invocation framework that replaces in-context tool registry lookup with learned latent retrieval in a shared embedding space. Tool selection uses external retrieval, after which the LM is conditioned only on the selected tool schema for argument generation. The core technical contribution is a signature-aware composite objective combining Circle Loss with Functional Margin Loss to enforce separation based on argument schemas, type compatibility, and return types. The authors evaluate on public tool-selection and function-calling datasets and claim >95% reduction in context token usage and up to 74% reduction in inference latency relative to long-context in-context tool (ICT) baselines.
Significance. If the unstated accuracy numbers confirm that retrieval and selection quality remain comparable to ICT baselines, the result would be significant for scaling agentic systems to registries far larger than current context windows allow. The signature-aware loss is a concrete technical step beyond pure semantic retrieval and directly addresses a known failure mode (semantically similar but signature-incompatible tools).
major comments (2)
- [Abstract] Abstract: the manuscript states that 'retrieval accuracy and selection latency metrics' are reported and that selection quality is preserved, yet supplies no numerical values, no baseline comparisons, and no error analysis. Without these figures the 95% context and 74% latency claims cannot be evaluated as net gains rather than accuracy-efficiency trade-offs.
- [Evaluation] Evaluation section (implied by the abstract's reference to public datasets): the central claim that the signature-aware objective 'maintains high retrieval and selection accuracy' when tools are fetched externally is load-bearing for the efficiency results, but no accuracy deltas, precision@K, or error rates versus ICT baselines are provided.
minor comments (1)
- [Abstract] The abstract mentions 'public tool-selection and function-calling datasets' but does not name them; the evaluation section should list the exact datasets and splits.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The feedback correctly identifies that the abstract and evaluation section would benefit from more explicit numerical presentation of accuracy metrics to allow direct assessment of the efficiency claims. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the manuscript states that 'retrieval accuracy and selection latency metrics' are reported and that selection quality is preserved, yet supplies no numerical values, no baseline comparisons, and no error analysis. Without these figures the 95% context and 74% latency claims cannot be evaluated as net gains rather than accuracy-efficiency trade-offs.
Authors: We agree that the abstract would be strengthened by incorporating the key numerical results it summarizes. The evaluation section of the manuscript reports retrieval accuracy, selection latency, and context usage on the public datasets, along with comparisons to ICT baselines and supporting analysis. To address the concern directly, we will revise the abstract to include the primary accuracy figures, baseline comparisons, and a concise reference to the error analysis so that the efficiency gains can be evaluated as net improvements. revision: yes
-
Referee: [Evaluation] Evaluation section (implied by the abstract's reference to public datasets): the central claim that the signature-aware objective 'maintains high retrieval and selection accuracy' when tools are fetched externally is load-bearing for the efficiency results, but no accuracy deltas, precision@K, or error rates versus ICT baselines are provided.
Authors: We acknowledge that the evaluation section would benefit from more prominent and explicit presentation of accuracy deltas, precision@K scores, and direct error-rate comparisons to the ICT baselines. While the section evaluates on public tool-selection and function-calling datasets and states that selection quality is preserved under the signature-aware objective, we will expand the section with additional tables and text that report these quantities side-by-side with the ICT baselines to make the supporting evidence clearer. revision: yes
Circularity Check
No significant circularity; derivation is empirical and self-contained
full rationale
The paper introduces NTILC as a neural embedding-based retrieval method trained with a composite loss (Circle Loss + Functional Margin Loss) on tool signatures, then evaluates empirically on public datasets for context reduction and latency. No equations, fitted parameters renamed as predictions, self-citations as load-bearing premises, uniqueness theorems, or ansatzes smuggled via citation appear in the provided text. The central claims rest on reported metrics from external datasets rather than any reduction of outputs to inputs by construction. This is the expected non-finding for a standard applied ML framework paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URLhttps://arxiv.org/abs/2401.08281. P. Hosseini, I. Castro, I. Ghinassi, and M. Purver. Efficient solutions for an intriguing failure of llms: Long context window does not mean llms can analyze long sequences flawlessly,
work page internal anchor Pith review Pith/arXiv arXiv
- [2]
- [3]
-
[4]
URL https: //arxiv.org/abs/1702.08734. M. Kang, W.-N. Chen, D. Han, H. A. Inan, L. Wutschitz, Y . Chen, R. Sim, and S. Rajmohan. Acon: Optimizing context compression for long-horizon llm agents,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
URL https://arxiv.org/ abs/2510.00615. C. Li, Z. Tang, Z. Li, M. Xue, K. Bao, T. Ding, R. Sun, B. Wang, X. Wang, J. Lin, and D. Liu. Teaching language models to reason with tools,
work page internal anchor Pith review Pith/arXiv arXiv
- [6]
-
[7]
URLhttps://arxiv.org/abs/2304.08244. N. F. Liu, K. Lin, J. Hewitt, A. Paranjape, M. Bevilacqua, F. Petroni, and P. Liang. Lost in the middle: How language models use long contexts,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
URLhttps://arxiv.org/abs/2307.03172. G. Mialon, R. Dessì, M. Lomeli, C. Nalmpantis, R. Pasunuru, R. Raileanu, B. Rozière, T. Schick, J. Dwivedi-Yu, A. Celikyilmaz, E. Grave, Y . LeCun, and T. Scialom. Augmented language models: a survey,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
URLhttps://arxiv.org/abs/2302.07842. A. Parisi, Y . Zhao, and N. Fiedel. Talm: Tool augmented language models,
work page internal anchor Pith review Pith/arXiv arXiv
- [10]
-
[11]
URLhttps://arxiv.org/abs/2305.15334. S. G. Patil, H. Mao, F. Yan, C. C.-J. Ji, V . Suresh, I. Stoica, and J. E. Gonzalez. The berkeley function calling leaderboard (BFCL): From tool use to agentic evaluation of large language models. InForty-second International Conference on Machine Learning,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
doi: 10.54364/aaiml.2026.61268
ISSN 2582-9793. doi: 10.54364/aaiml.2026.61268. URL http://dx.doi.org/10.54364/AAIML. 2026.61268. A. Plaat, M. Van Duijn, N. Van Stein, M. Preuss, P. Van der Putten, and K. J. Batenburg. Agentic large language models, a survey.Journal of Artificial Intelligence Research, 84, Dec
-
[13]
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
ISSN 1076-9757. doi: 10.1613/jair.1.18675. URLhttp://dx.doi.org/10.1613/jair.1.18675. Y . Qin, S. Liang, Y . Ye, K. Zhu, L. Yan, Y . Lu, Y . Lin, X. Cong, X. Tang, B. Qian, S. Zhao, L. Hong, R. Tian, R. Xie, J. Zhou, M. Gerstein, D. Li, Z. Liu, and M. Sun. Toolllm: Facilitating large language models to master 16000+ real-world apis, 2023a. URL https://arx...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1613/jair.1.18675
- [14]
- [15]
- [16]
- [17]
-
[18]
URL https://arxiv.org/abs/2307.09702. J. Ye, G. Li, S. Gao, C. Huang, Y . Wu, S. Li, X. Fan, S. Dou, T. Ji, Q. Zhang, T. Gui, and X. Huang. Tooleyes: Fine-grained evaluation for tool learning capabilities of large language models in real-world scenarios,
work page internal anchor Pith review Pith/arXiv arXiv
- [19]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.