Multilingual Multi-Speaker Unit Vocoders: A Systematic Analysis of Discrete Speech Representations
Pith reviewed 2026-06-27 23:27 UTC · model grok-4.3
The pith
Larger cluster sizes in discrete speech units improve intelligibility by enhancing phonetic discriminability in multilingual multi-speaker vocoders, while explicit speaker conditioning prevents identity collapse.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Discrete speech units obtained via k-means clustering of self supervised embeddings entangle phonetic, speaker, and language information, causing speaker mixing and cross-lingual interference in multilingual multi-speaker speech generation. Cluster size governs intelligibility by improving phonetic discriminability, while explicit speaker conditioning is indispensable for preventing identity collapse. Language supervision yields further gains mainly at lower cluster sizes where units remain ambiguous. Similar phonemes across languages collapse to the same cluster IDs at smaller inventories, with larger clusters progressively separating them.
What carries the argument
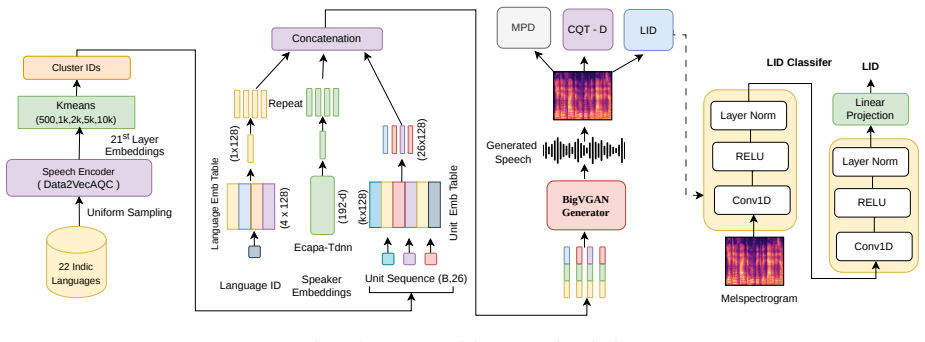
The k-means cluster size interacting with speaker and language conditioning inputs to the unit vocoder, which controls separation of phonetic, speaker, and language information in the discrete representations.
If this is right
- Larger cluster sizes reduce word error rates by improving phonetic discriminability.
- Explicit speaker conditioning is required to maintain high speaker similarity and prevent identity collapse.
- Language supervision provides gains primarily at smaller cluster sizes where units are more ambiguous.
- Similar phonemes from different languages share cluster IDs at small inventories but separate at larger ones.
Where Pith is reading between the lines
- The pattern of phoneme collapse indicates that optimal cluster size may need to increase with the total phonetic diversity across the languages in the system.
- For unit-based models in broader speech applications, conditioning choices could be adjusted dynamically according to the chosen cluster inventory size.
Load-bearing premise
The assumption that word error rate, speaker similarity, and unit-level metrics are sufficient and unbiased proxies for entanglement of phonetic, speaker, and language information in the discrete units.
What would settle it
A direct measurement of speaker mixing or cross-lingual phoneme confusion via perceptual listening tests or embedding analysis on generated audio that fails to match the observed trends in WER and similarity scores.
Figures
read the original abstract
Discrete speech units obtained via k-means clustering of self supervised embeddings entangle phonetic, speaker, and language information, causing speaker mixing and cross-lingual interference in multilingual multi-speaker speech generation. Despite growing use in Audio LLMs and speech to speech systems, unit vocoders remain underexplored. We analyze a BigVGAN based unit vocoder, across four Indian languages. We study the interaction between cluster size and conditioning strategies using WER, speaker similarity, and unit level metrics. Results show that cluster size governs intelligibility by improving phonetic discriminability, while explicit speaker conditioning is indispensable for preventing identity collapse. Language supervision yields further gains mainly at lower cluster sizes where units remain ambiguous. Our analysis shows similar phonemes across languages collapse to the same cluster IDs at smaller inventories, with larger clusters progressively separating them.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts a systematic analysis of a BigVGAN-based unit vocoder for multilingual multi-speaker speech generation using discrete units obtained from k-means clustering of self-supervised embeddings across four Indian languages. It investigates the effects of cluster size and conditioning strategies (speaker and language) on WER, speaker similarity, and unit-level metrics. The results indicate that cluster size controls intelligibility through phonetic discriminability, explicit speaker conditioning prevents identity collapse, language supervision aids at lower cluster sizes, and similar phonemes merge in small clusters but separate in larger ones.
Significance. If validated, the findings offer useful empirical insights for optimizing discrete representations in multilingual speech systems used in Audio LLMs and S2S applications. The ablation study documents the interplay between granularity and conditioning for disentangling information types, adding to the literature on unit vocoders which are noted as underexplored. The work is purely empirical without parameter-free derivations or machine-checked proofs.
major comments (2)
- [Abstract and results paragraph] The central claims depend on interpreting WER as a measure of phonetic discriminability and speaker similarity as evidence against collapse. These proxies may be confounded by factors such as vocoder capacity or data imbalance, and the manuscript does not provide validation through supervised probes or other methods to confirm they isolate the entanglement effects.
- [Abstract] The analysis of phoneme collapse across languages to same cluster IDs at smaller sizes is stated without citing specific quantitative results from unit-level metrics or providing examples, weakening the support for this observation.
minor comments (2)
- Include full experimental details such as dataset sizes, speaker counts, exact cluster sizes, and statistical significance tests with error bars to allow proper assessment of the results.
- Provide a clear definition of the unit-level metrics employed in the study.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our empirical analysis of unit vocoders. We address the major comments point by point below, clarifying our use of metrics and strengthening the presentation of results where appropriate.
read point-by-point responses
-
Referee: [Abstract and results paragraph] The central claims depend on interpreting WER as a measure of phonetic discriminability and speaker similarity as evidence against collapse. These proxies may be confounded by factors such as vocoder capacity or data imbalance, and the manuscript does not provide validation through supervised probes or other methods to confirm they isolate the entanglement effects.
Authors: We agree that WER and speaker similarity are proxy metrics and could in principle be influenced by vocoder capacity or data distribution. However, these are the standard evaluation protocols in the unit vocoder and discrete speech literature for measuring intelligibility and speaker consistency. Our unit-level analyses (cluster purity, normalized mutual information, and cross-lingual phoneme overlap statistics) provide convergent evidence that directly ties cluster size to phonetic separability and that speaker conditioning prevents identity collapse. While we did not include supervised probe classifiers, the multi-language, multi-condition ablation design shows consistent directional effects that would be difficult to attribute solely to capacity or imbalance. We will add an explicit limitations paragraph discussing these proxy choices and potential confounds in the revision. revision: partial
-
Referee: [Abstract] The analysis of phoneme collapse across languages to same cluster IDs at smaller sizes is stated without citing specific quantitative results from unit-level metrics or providing examples, weakening the support for this observation.
Authors: The full manuscript reports unit-level metrics (including per-phoneme cluster assignment overlap tables and entropy measures) demonstrating that similar phonemes from different languages share cluster IDs at small k and separate at larger k. We will revise the abstract to reference the key quantitative findings (e.g., overlap percentages at k=100 vs. k=1000) and include one concrete cross-lingual phoneme pair example to make the claim self-contained. revision: yes
Circularity Check
Empirical ablation study with no derivation chain or self-referential predictions
full rationale
The paper conducts a systematic empirical analysis of unit vocoders across cluster sizes and conditioning strategies, reporting direct measurements of WER, speaker similarity, and unit-level metrics on four Indian languages. No mathematical derivations, first-principles predictions, fitted parameters renamed as outputs, or load-bearing self-citations appear in the provided abstract or described methodology. All claims follow from experimental ablations against external benchmarks rather than reducing to inputs by construction. The concern about metric validity as proxies is a question of experimental design validity, not circularity in any derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption k-means clustering of self-supervised embeddings produces discrete units that entangle phonetic, speaker, and language information
Reference graph
Works this paper leans on
-
[1]
Introduction Discrete speech units derived from self-supervised represen- tations are emerging as a key intermediate in modern speech systems, particularly in speech language models and speech-to- speech translation pipelines. By discretizing continuous speech into symbolic unit sequences, these approaches enable direct speech generation without relying o...
-
[2]
Methodology For our experiments, we adopt the BigVGAN [7] architec- ture consisting of a generatorG, a Multi-Period Discriminator (MPD) and CQT based time frequency discriminators. Unlike a standard vocoder, which takes mel spectrograms as input, we replace the generator input with discrete units. Optional speaker and language embeddings are concatenated ...
Pith/arXiv arXiv 2026
-
[3]
Experiments 3.1. Training Setup and Datasets We conduct experiments on four languages Bengali, Hindi, Tamil, and Telugu from the IndicV oices-R dataset [18], a mul- tilingual and multispeaker corpus. All audios are resampled to 16 kHz. Language-wise data and speaker statistics are summa- rized in Table 1. We evaluate on the official IndicV oices-R test sp...
-
[4]
Results and Discussion This section analyzes how cluster size and conditioning strate- gies affect intelligibility and speaker preservation. Through a 2Indic-Conformer: https://github.com/AI4Bharat/IndicConformerASR 3IndicMFA: https://github.com/AI4Bharat/IndicMFA systematic comparison of four configurations, we study the in- dividual and combined effects...
-
[5]
Conclusion We presented a systematic analysis of discrete unit based vocoders in a multilingual multi-speaker setting by extending BigVGAN to synthesize speech from discrete units. Experi- ments across four Indian languages show that cluster size pri- marily controls intelligibility through phonetic resolution, while explicit speaker conditioning is essen...
-
[6]
The authors developed and verified all scientific concepts, experimental methodolo- gies, results, and conclusions independently
Generative AI Use Disclosure Generative AI was utilized exclusively for minor linguistic re- finement and phrasing improvements. The authors developed and verified all scientific concepts, experimental methodolo- gies, results, and conclusions independently
-
[7]
Speech Resynthesis from Discrete Disentangled Self-Supervised Representations,
A. Polyak, Y . Adi, J. Copet, E. Kharitonov, K. Lakhotia, W.-N. Hsu, A. Mohamed, and E. Dupoux, “Speech Resynthesis from Discrete Disentangled Self-Supervised Representations,” inPro- ceedings of the Interspeech, 2021
2021
-
[8]
Multilingual Speech-to-Speech Translation into Multiple Target Languages,
H. Gong, N. Dong, S. Popuri, V . Goswami, A. Lee, and J. Pino, “Multilingual Speech-to-Speech Translation into Multiple Target Languages,” 2023. [Online]. Available: https: //arxiv.org/abs/2307.08655
arXiv 2023
-
[9]
Seamless: Multilingual Expressive and Streaming Speech Translation,
S. Communication, L. Barrault, Y .-A. Chung, M. C. Meglioli, D. Dale, N. Dong, M. Duppenthaler, P.-A. Duquenne, B. Ellis, H. Elsahar, J. Haaheim, J. Hoffman, M.-J. Hwang, H. Inaguma, C. Klaiber, I. Kulikov, P. Li, D. Licht, J. Maillard, R. Mavlyutov, A. Rakotoarison, K. R. Sadagopan, A. Ramakrishnan, T. Tran, G. Wenzek, Y . Yang, E. Ye, I. Evtimov, P. Fer...
-
[10]
Available: https://arxiv.org/abs/2312.05187
[Online]. Available: https://arxiv.org/abs/2312.05187
-
[11]
SpeechGPT: Empowering Large Language Models with Intrinsic Cross-Modal Conversational Abilities,
D. Zhang, S. Li, X. Zhang, J. Zhan, P. Wang, Y . Zhou, and X. Qiu, “SpeechGPT: Empowering Large Language Models with Intrinsic Cross-Modal Conversational Abilities,” inFindings of the Associ- ation for Computational Linguistics: EMNLP, 2023, pp. 15 757– 15 773
2023
-
[12]
StreamSpeech: Simultaneous Speech-to-Speech Translation with Multi-task Learning,
S. Zhang, Q. Fang, S. Guo, Z. Ma, M. Zhang, and Y . Feng, “StreamSpeech: Simultaneous Speech-to-Speech Translation with Multi-task Learning,” inProceedings of the 62th Annual Meeting of the Association for Computational Linguistics (Long Papers), 2024
2024
-
[13]
Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis,
J. Kong, J. Kim, and J. Bae, “Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis,” inAd- vances in Neural Information Processing Systems, H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, Eds., vol. 33. Curran Associates, Inc., 2020, pp. 17 022–17 033. [Online]. Available: https://proceedings.neurips.cc/...
2020
-
[14]
BigVGAN: A universal neural vocoder with large- scale training,
S. gil Lee, W. Ping, B. Ginsburg, B. Catanzaro, and S. Yoon, “BigVGAN: A universal neural vocoder with large- scale training,” inThe Eleventh International Conference on Learning Representations, 2023. [Online]. Available: https: //openreview.net/forum?id=iTtGCMDEzS
2023
-
[15]
Ecapa-tdnn embeddings for speaker diarization,
Nauman Dawalatabad and Mirco Ravanelli and Franc ¸ois Grondin and Jenthe Thienpondt and Brecht Desplanques and Hwidong Na, “Ecapa-tdnn embeddings for speaker diarization,” inProceedings of the Interspeech, 2021, pp. 3560–3564
2021
-
[16]
Least Squares Generative Adversarial Networks,
X. Mao, Q. Li, H. Xie, R. Y . Lau, Z. Wang, and S. Paul Smolley, “Least Squares Generative Adversarial Networks,” inProceed- ings of the IEEE International Conference on Computer Vision (ICCV), 2017
2017
-
[17]
Autoencoding beyond pixels using a learned similarity met- ric,
A. B. L. Larsen, S. K. Sønderby, H. Larochelle, and O. Winther, “Autoencoding beyond pixels using a learned similarity met- ric,” inProceedings of the International Conference on Machine Learning (ICML), 2016, vol. 48, pp. 1558–1566
2016
-
[18]
Data2vec-Aqc: Search for the Right Teaching Assistant in the Teacher-Student Training Setup,
V . S. Lodagala, S. Ghosh, and S. Umesh, “Data2vec-Aqc: Search for the Right Teaching Assistant in the Teacher-Student Training Setup,” inProceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023, pp. 1– 5
2023
-
[19]
All ears: Building self-supervised learning based asr models for indian lan- guages at scale,
V . S. Lodagala, A. Biswas, S. Das, S. Umeshet al., “All ears: Building self-supervised learning based asr models for indian lan- guages at scale,” inProceedings of the interspeech, 2024, pp. 3944–3948
2024
-
[20]
Comparative layer-wise analy- sis of self-supervised speech models,
A. Pasad, B. Shi, and K. Livescu, “Comparative layer-wise analy- sis of self-supervised speech models,” inProceedings of the IEEE International Conference on Acoustics, Speech and Signal Pro- cessing (ICASSP), 2023, pp. 1–5
2023
-
[21]
IndicV oices: Towards building an Inclusive Mul- tilingual Speech Dataset for Indian Languages,
T. Javed, J. Nawale, E. George, S. Joshi, K. Bhogale, D. Mehen- dale, I. Sethi, A. Ananthanarayanan, H. Faquih, P. Palit, S. Rav- ishankar, S. Sukumaran, T. Panchagnula, S. Murali, K. Gandhi, A. R, M. M, C. Vaijayanthi, K. Karunganni, P. Kumar, and M. Khapra, “IndicV oices: Towards building an Inclusive Mul- tilingual Speech Dataset for Indian Languages,”...
2024
-
[22]
Towards Building Text-to-Speech Systems for the Next Bil- lion Users,
G. K. Kumar, P. S V , P. Kumar, M. M. Khapra, and K. Nandaku- mar, “Towards Building Text-to-Speech Systems for the Next Bil- lion Users,” inProceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023, pp. 1–5
2023
-
[23]
Effectiveness of mining audio and text pairs from public data for improving ASR systems for low-resource languages,
K. S. Bhogale, A. Raman, T. Javed, S. Doddapaneni, A. Kunchukuttan, P. Kumar, and M. M. Khapra, “Effectiveness of mining audio and text pairs from public data for improving ASR systems for low-resource languages,” inProceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023, pp. 1–5
2023
-
[24]
SPRING-INX: A Multilingual Indian Language Speech Corpus by SPRING Lab, IIT Madras,
N. R, M. S, J. F, A. Gangwar, M. N. J, S. Umesh, R. Sarab, A. K. Dubey, G. Divakaran, S. V . K, and S. V . Gangashetty, “SPRING-INX: A Multilingual Indian Language Speech Corpus by SPRING Lab, IIT Madras,” 2023. [Online]. Available: https://arxiv.org/abs/2310.14654
arXiv 2023
-
[25]
IndicV oices-R: Unlocking a Massive Multilingual Multi-speaker Speech Corpus for Scaling Indian TTS,
A. Sankar, S. Anand, P. S. Varadhan, S. Thomas, M. Singal, S. Kumar, D. Mehendale, A. Krishana, G. Raju, and M. Khapra, “IndicV oices-R: Unlocking a Massive Multilingual Multi-speaker Speech Corpus for Scaling Indian TTS,”NeurIPS 2024 Datasets and Benchmarks, 2024
2024
-
[26]
VERSA: A Versatile Evaluation Toolkit for Speech, Audio, and Music,
J. Shi, H. jin Shim, J. Tian, S. Arora, H. Wu, D. Petermann, J. Q. Yip, Y . Zhang, Y . Tang, W. Zhang, D. S. Alharthi, Y . Huang, K. Saito, J. Han, Y . Zhao, C. Donahue, and S. Watanabe, “VERSA: A Versatile Evaluation Toolkit for Speech, Audio, and Music,” inAnnual Conference of the North American Chapter of the Association for Computational Linguistics –...
2025
-
[27]
HuBERT: Self-Supervised Speech Rep- resentation Learning by Masked Prediction of Hidden Units,
W.-N. Hsu, B. Bolte, Y .-H. H. Tsai, K. Lakhotia, R. Salakhutdi- nov, and A. Mohamed, “HuBERT: Self-Supervised Speech Rep- resentation Learning by Masked Prediction of Hidden Units,” IEEE/ACM Transactions on Audio, Speech, and Language Pro- cessing, 2021, vol. 29, pp. 3451–3460
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.