OpenHalDet: A Unified Benchmark for Hallucination Detection across Diverse Generation Scenarios
Pith reviewed 2026-06-27 21:49 UTC · model grok-4.3
The pith
OpenHalDet standardizes the full evaluation pipeline for hallucination detectors in LLMs to allow direct comparisons across tasks and access levels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
OpenHalDet is a unified benchmark that standardizes the evaluation pipeline from prompt construction and response generation to truthfulness annotation, detector scoring, and metric computation. It supports heterogeneous detector families under black-box, gray-box, and white-box access settings. By bringing diverse tasks, models, and detectors into one framework, it enables controlled comparison and provides a systematic view of how different detection paradigms behave in LLM applications. The code and datasets are released as an open and extensible codebase.
What carries the argument
The OpenHalDet benchmark, a standardized pipeline that unifies prompt construction, generation, annotation, scoring, and metrics while supporting black-box, gray-box, and white-box detectors.
If this is right
- Detector performances reported under the benchmark become directly comparable across different studies and settings.
- A systematic view emerges of how black-box, gray-box, and white-box paradigms behave across LLM applications.
- Reproducible evaluation becomes possible through the shared open codebase.
- New detection methods can be developed and tested under the same standardized conditions.
Where Pith is reading between the lines
- The benchmark could reveal which access level (black-box versus white-box) delivers the best trade-off for particular downstream domains.
- Extending the covered tasks to include more recent model families would test whether the standardization holds as LLMs evolve.
- Applying the pipeline inside production systems might expose practical gaps between benchmark scores and real deployment reliability.
Load-bearing premise
That making inference configurations and evaluation steps consistent across studies will make detector performance directly comparable and generalizable beyond the tested settings.
What would settle it
Running multiple detectors through the OpenHalDet pipeline on the same tasks and finding that their relative performance rankings still flip when only the random seed or minor prompt wording changes.
Figures
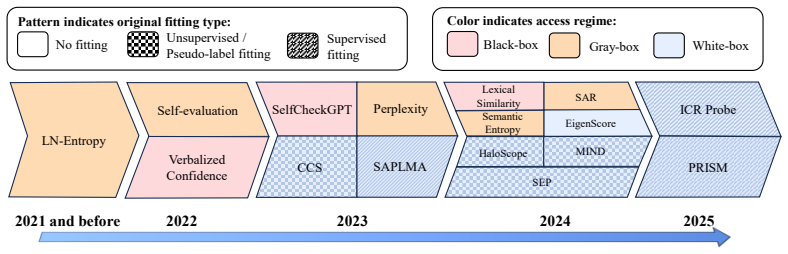
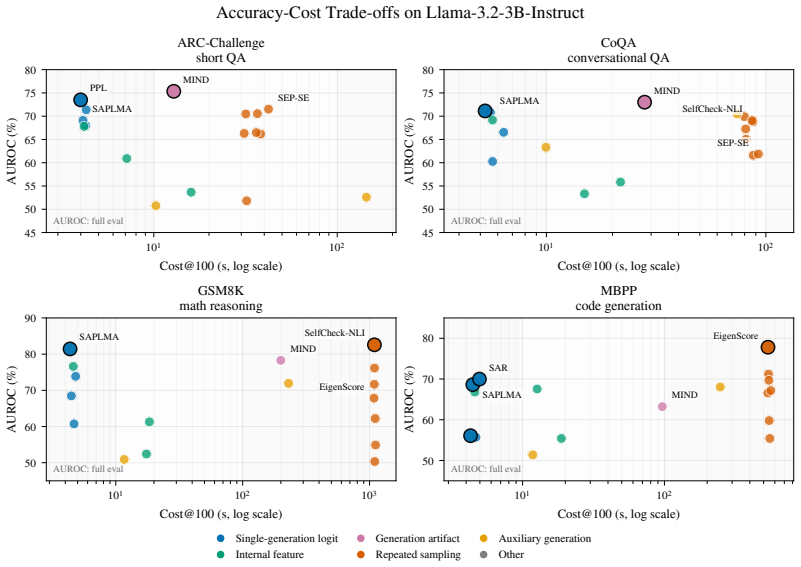
read the original abstract
Hallucination detection is essential for the reliable deployment of large language models (LLMs). However, existing evaluations face two core challenges: inconsistent inference configuration and evaluation, and limited coverage of downstream domains and tasks. Consequently, reported detector performance is often difficult to compare, reproduce, and generalize beyond specific experimental settings. We introduce OpenHalDet, a unified benchmark for hallucination detection across diverse generation scenarios. OpenHalDet standardizes the evaluation pipeline, from prompt construction and response generation to truthfulness annotation, detector scoring, and metric computation. It supports heterogeneous detector families under different access settings, including black-box methods that use only generated outputs, gray-box methods that rely on probability-based signals, and white-box methods that exploit internal model signals. By bringing diverse tasks, models, and detectors into a shared framework, OpenHalDet enables controlled comparison and provides a systematic view of how different detection paradigms behave in LLM applications. We release OpenHalDet as an open and extensible codebase to facilitate reproducible evaluation and future development of hallucination detection methods. The code and datasets are available at https://github.com/Nellie179/Hallucination-Detection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces OpenHalDet, a unified benchmark for hallucination detection in LLMs. It standardizes the full evaluation pipeline (prompt construction, response generation, truthfulness annotation, detector scoring, and metrics) across diverse tasks and models, supporting black-box, gray-box, and white-box detectors, and releases an open extensible codebase and datasets to enable reproducible comparisons.
Significance. If the standardization is correctly implemented and the released resources are comprehensive, OpenHalDet could provide a valuable common platform for comparing hallucination detectors, reducing inconsistencies in prior work and supporting systematic analysis of detection paradigms across access settings.
major comments (1)
- [Abstract] Abstract: the central claim that the benchmark 'enables controlled comparison and provides a systematic view of how different detection paradigms behave' is not supported by any reported experiments, baseline results, or validation metrics in the provided description; without such evidence the utility of the standardization cannot be assessed.
minor comments (1)
- The description of supported tasks, models, and specific detectors is high-level; adding an explicit table or section listing coverage would strengthen the claim of 'diverse generation scenarios'.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the single major comment below and indicate the planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the benchmark 'enables controlled comparison and provides a systematic view of how different detection paradigms behave' is not supported by any reported experiments, baseline results, or validation metrics in the provided description; without such evidence the utility of the standardization cannot be assessed.
Authors: We agree that the abstract phrasing should be tightened to avoid overstating what is demonstrated. The manuscript's core contribution is the standardized pipeline and released codebase that make controlled comparisons possible across black-, gray-, and white-box detectors; the paper itself contains initial cross-detector evaluations on the included tasks and models. We will revise the abstract to state that OpenHalDet supplies the common infrastructure and datasets for such comparisons, and we will add an explicit reference to the baseline results already present in the experimental section so that the claim is directly supported by reported metrics. revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces OpenHalDet as a standardized benchmark for hallucination detection, focusing on unifying evaluation pipelines across tasks, models, and detector types (black/gray/white-box). No derivation chain, mathematical predictions, fitted parameters, or first-principles results are claimed or present. The central contribution is the benchmark definition, standardization of configs, and code release itself, with no self-definitional reductions, fitted inputs renamed as predictions, or load-bearing self-citations that collapse the argument. The abstract and description describe an engineering solution to inconsistent evaluations without internal circular structure.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A survey of large language models, 2026
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, Yifan Du, Chen Yang, Yushuo Chen, Zhipeng Chen, Jinhao Jiang, Ruiyang Ren, Yifan Li, Xinyu Tang, Zikang Liu, Peiyu Liu, Jian-Yun Nie, and Ji-Rong Wen. A survey of large language models, 2026
2026
-
[2]
Enhancing hallucination detection through noise injection.CoRR, abs/2502.03799, 2025
Litian Liu, Reza Pourreza, Sunny Panchal, Apratim Bhattacharyya, Ya-Qin Zhang, and Roland Memisevic. Enhancing hallucination detection through noise injection.CoRR, abs/2502.03799, 2025
Pith/arXiv arXiv 2025
-
[3]
Steer LLM latents for hallucination detection
Seongheon Park, Xuefeng Du, Min-Hsuan Yeh, Haobo Wang, and Yixuan Li. Steer LLM latents for hallucination detection. InForty-second International Conference on Machine Learning, 2025
2025
-
[4]
Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension.ACL, 2017
Mandar Joshi, Eunsol Choi, Daniel S Weld, and Luke Zettlemoyer. Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension.ACL, 2017
2017
-
[5]
Truthfulqa: Measuring how models mimic human falsehoods.ACL, 2022
Stephanie Lin, Jacob Hilton, and Owain Evans. Truthfulqa: Measuring how models mimic human falsehoods.ACL, 2022
2022
-
[6]
don’t forget the teachers
Emma Harvey, Allison Koenecke, and René F. Kizilcec. "don’t forget the teachers": Towards an educator-centered understanding of harms from large language models in education. In Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems, pages 1–19, 2025
2025
-
[7]
The clinicians’ guide to large language models: A general perspective with a focus on hallucinations.Interactive Journal of Medical Research, 14:e59823, 2025
Dimitri Roustan and François Bastardot. The clinicians’ guide to large language models: A general perspective with a focus on hallucinations.Interactive Journal of Medical Research, 14:e59823, 2025
2025
-
[8]
Haoqiang Kang and Xiao-Yang Liu. Deficiency of large language models in finance: An empirical examination of hallucination.arXiv preprint arXiv:2311.15548, 2023
arXiv 2023
-
[9]
On faithfulness and factuality in abstractive summarization
Joshua Maynez, Shashi Narayan, Bernd Bohnet, and Ryan McDonald. On faithfulness and factuality in abstractive summarization. InProceedings of the 58th annual meeting of the association for computational linguistics, pages 1906–1919, 2020
1906
-
[10]
Adam Tauman Kalai and Santosh S. Vempala. Calibrated language models must hallucinate. In Proceedings of the 56th Annual ACM Symposium on Theory of Computing, STOC 2024, page 160–171, New York, NY , USA, 2024. Association for Computing Machinery
2024
-
[11]
Llms will always hallucinate, and we need to live with this
Sourav Banerjee, Ayushi Agarwal, and Saloni Singla. Llms will always hallucinate, and we need to live with this. InIntelligent Systems Conference, pages 624–648. Springer, 2025
2025
-
[12]
Why language models hallucinate.arXiv preprint arXiv:2509.04664, 2025
Adam Tauman Kalai, Ofir Nachum, Santosh S Vempala, and Edwin Zhang. Why language models hallucinate.arXiv preprint arXiv:2509.04664, 2025
Pith/arXiv arXiv 2025
-
[13]
Adam Tauman Kalai and Santosh S. Vempala. Calibrated language models must hallucinate. In Proceedings of the 56th Annual ACM Symposium on Theory of Computing, 2024
2024
-
[14]
On the limits of language generation: Trade-offs between hallucination and mode-collapse
Alkis Kalavasis, Anay Mehrotra, and Grigoris Velegkas. On the limits of language generation: Trade-offs between hallucination and mode-collapse. InProceedings of the 57th Annual ACM Symposium on Theory of Computing, 2025
2025
-
[15]
Jie Ren, Jiaming Luo, Yao Zhao, Kundan Krishna, Mohammad Saleh, Balaji Lakshminarayanan, and Peter J Liu. Out-of-distribution detection and selective generation for conditional language models.arXiv preprint arXiv:2209.15558, 2022. 10
arXiv 2022
-
[16]
Halueval: A large-scale hallucination evaluation benchmark for large language models
Junyi Li, Xiaoxue Cheng, Wayne Xin Zhao, Jian-Yun Nie, and Ji-Rong Wen. Halueval: A large-scale hallucination evaluation benchmark for large language models. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 6449–6464, 2023
2023
-
[17]
SelfcheckGPT: Zero-resource black-box hallucination detection for generative large language models
Potsawee Manakul, Adian Liusie, and Mark Gales. SelfcheckGPT: Zero-resource black-box hallucination detection for generative large language models. InThe 2023 Conference on Empirical Methods in Natural Language Processing, 2023
2023
-
[18]
Detecting hallucinations in large language models using semantic entropy.Nature, 630:625 – 630, 2024
Sebastian Farquhar, Jannik Kossen, Lorenz Kuhn, and Yarin Gal. Detecting hallucinations in large language models using semantic entropy.Nature, 630:625 – 630, 2024
2024
-
[19]
A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions.ACM Trans
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qiang- long Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, and Ting Liu. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions.ACM Trans. Inf. Syst., 2025
2025
-
[20]
Siren’s song in the AI ocean: A survey on hallucination in large language models
Yue Zhang, Yafu Li, Leyang Cui, Deng Cai, Lemao Liu, Tingchen Fu, Xinting Huang, Enbo Zhao, Yu Zhang, Yulong Chen, Longyue Wang, Anh Tuan Luu, Wei Bi, Freda Shi, and Shuming Shi. Siren’s song in the AI ocean: A survey on hallucination in large language models. Computational Linguistics, 2025
2025
-
[21]
Lin, Jacob Hilton, and Owain Evans
Stephanie C. Lin, Jacob Hilton, and Owain Evans. Teaching models to express their uncertainty in words.Trans. Mach. Learn. Res., 2022, 2022
2022
-
[22]
Generating with confidence: Uncertainty quan- tification for black-box large language models.Transactions on Machine Learning Research, 2024
Zhen Lin, Shubhendu Trivedi, and Jimeng Sun. Generating with confidence: Uncertainty quan- tification for black-box large language models.Transactions on Machine Learning Research, 2024
2024
-
[23]
Out-of-distribution detection and selective generation for conditional language models
Jie Ren, Jiaming Luo, Yao Zhao, Kundan Krishna, Mohammad Saleh, Balaji Lakshminarayanan, and Peter J Liu. Out-of-distribution detection and selective generation for conditional language models. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[24]
Uncertainty estimation in autoregressive structured prediction
Andrey Malinin and Mark Gales. Uncertainty estimation in autoregressive structured prediction. InInternational Conference on Learning Representations, 2021
2021
-
[25]
Shifting attention to relevance: Towards the predictive uncertainty quantification of free-form large language models
Jinhao Duan, Hao Cheng, Shiqi Wang, Alex Zavalny, Chenan Wang, Renjing Xu, Bhavya Kailkhura, and Kaidi Xu. Shifting attention to relevance: Towards the predictive uncertainty quantification of free-form large language models. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Computa- ti...
2024
-
[26]
INSIDE: LLMs’ internal states retain the power of hallucination detection
Chao Chen, Kai Liu, Ze Chen, Yi Gu, Yue Wu, Mingyuan Tao, Zhihang Fu, and Jieping Ye. INSIDE: LLMs’ internal states retain the power of hallucination detection. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[27]
Discovering latent knowledge in language models without supervision
Collin Burns, Haotian Ye, Dan Klein, and Jacob Steinhardt. Discovering latent knowledge in language models without supervision. InThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023
2023
-
[28]
The internal state of an LLM knows when it’s lying
Amos Azaria and Tom Mitchell. The internal state of an LLM knows when it’s lying. InThe 2023 Conference on Empirical Methods in Natural Language Processing, 2023
2023
-
[29]
Mitigat- ing llm hallucinations via conformal abstention.arXiv preprint arXiv:2405.01563, 2024
Yasin Abbasi Yadkori, Ilja Kuzborskij, David Stutz, András György, Adam Fisch, Arnaud Doucet, Iuliya Beloshapka, Wei-Hung Weng, Yao-Yuan Yang, Csaba Szepesvári, et al. Mitigat- ing llm hallucinations via conformal abstention.arXiv preprint arXiv:2405.01563, 2024
arXiv 2024
-
[30]
A framework to assess clinical safety and hallucination rates of LLMs for medical text summarisation.npj Digital Medicine, 8(1):274, 2025
Elham Asgari, Nina Montaña-Brown, Magda Dubois, Saleh Khalil, Jasmine Balloch, Joshua Au Yeung, and Dominic Pimenta. A framework to assess clinical safety and hallucination rates of LLMs for medical text summarisation.npj Digital Medicine, 8(1):274, 2025. 11
2025
-
[31]
RedeEP: Detecting hallucination in retrieval-augmented generation via mechanistic interpretability
ZhongXiang Sun, Xiaoxue Zang, Kai Zheng, Jun Xu, Xiao Zhang, Weijie Yu, Yang Song, and Han Li. RedeEP: Detecting hallucination in retrieval-augmented generation via mechanistic interpretability. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[32]
Valentin Noël. Spectral guardrails for agents in the wild: Detecting tool use hallucinations via attention topology.arXiv preprint arXiv:2602.08082, 2026
arXiv 2026
-
[33]
The illusion of progress: Re-evaluating hallucination detection in llms
Denis Janiak, Jakub Binkowski, Albert Sawczyn, Bogdan Gabrys, Ravid Shwartz-Ziv, and Tomasz Kajdanowicz. The illusion of progress: Re-evaluating hallucination detection in llms. InConference on Empirical Methods in Natural Language Processing, 2025
2025
-
[34]
HalluLens: LLM hallucination benchmark
Yejin Bang, Ziwei Ji, Alan Schelten, Anthony Hartshorn, Tara Fowler, Cheng Zhang, Nicola Cancedda, and Pascale Fung. HalluLens: LLM hallucination benchmark. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), July 2025
2025
-
[35]
Hallumix: A task-agnostic, multi-domain benchmark for real-world hallucination detection
Deanna Emery, Michael Goitia, Freddie Vargus, and Iulia Neagu. Hallumix: A task-agnostic, multi-domain benchmark for real-world hallucination detection. 2025
2025
-
[36]
ICR probe: Tracking hidden state dynamics for reliable hallucination detection in LLMs
Zhenliang Zhang, Xinyu Hu, Huixuan Zhang, Junzhe Zhang, and Xiaojun Wan. ICR probe: Tracking hidden state dynamics for reliable hallucination detection in LLMs. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Pape...
2025
-
[37]
Evaluating evaluation metrics — the mirage of hallucination detection
Atharva Kulkarni*, Yuan Zhang, Joel Ruben Antony Moniz*, Xiou Ge, Bo-Hsiang Tseng, Dhivya Piraviperumal, Swabha Swayamdipta, and Hong Yu. Evaluating evaluation metrics — the mirage of hallucination detection. InEMNLP, 2025
2025
-
[38]
HalluCounter: Reference-free LLM hallucination detection in the wild! In Kentaro Inui, Sakriani Sakti, Haofen Wang, Derek F
Ashok Urlana, Gopichand Kanumolu, Charaka Vinayak Kumar, Bala Mallikarjunarao Garlapati, and Rahul Mishra. HalluCounter: Reference-free LLM hallucination detection in the wild! In Kentaro Inui, Sakriani Sakti, Haofen Wang, Derek F. Wong, Pushpak Bhattacharyya, Biplab Banerjee, Asif Ekbal, Tanmoy Chakraborty, and Dhirendra Pratap Singh, editors,Proceedings...
2025
-
[39]
Haloscope: Harnessing unlabeled LLM generations for hallucination detection
Xuefeng Du, Chaowei Xiao, and Yixuan Li. Haloscope: Harnessing unlabeled LLM generations for hallucination detection. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
2024
-
[40]
Beyond in-domain detection: Spikescore for cross-domain hallucination detection
Yongxin Deng, Zhen Fang, Sharon Li, and Ling Chen. Beyond in-domain detection: Spikescore for cross-domain hallucination detection. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[41]
Halluentity: Benchmarking and understanding entity-level hallucination detection.Transactions on Machine Learning Research, 2025
Min-Hsuan Yeh, Max Kamachee, Seongheon Park, and Yixuan Li. Halluentity: Benchmarking and understanding entity-level hallucination detection.Transactions on Machine Learning Research, 2025
2025
-
[42]
FActscore: Fine-grained atomic evaluation of factual precision in long form text generation
Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen tau Yih, Pang Wei Koh, Mohit Iyyer, Luke Zettlemoyer, and Hannaneh Hajishirzi. FActscore: Fine-grained atomic evaluation of factual precision in long form text generation. InEMNLP, 2023
2023
-
[43]
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge.ArXiv, abs/1803.05457, 2018
Pith/arXiv arXiv 2018
-
[44]
CommonsenseQA: A question answering challenge targeting commonsense knowledge
Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. CommonsenseQA: A question answering challenge targeting commonsense knowledge. In Jill Burstein, Christy Doran, and Thamar Solorio, editors,Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volum...
2019
-
[45]
Know what you don’t know: Unanswerable questions for SQuAD
Pranav Rajpurkar, Robin Jia, and Percy Liang. Know what you don’t know: Unanswerable questions for SQuAD. In Iryna Gurevych and Yusuke Miyao, editors,Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Melbourne, Australia, July 2018. Association for Computational Linguistics
2018
-
[46]
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. HotpotQA: A dataset for diverse, explainable multi-hop question answering. In Ellen Riloff, David Chiang, Julia Hockenmaier, and Jun’ichi Tsujii, editors, Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processi...
2018
-
[47]
Siva Reddy, Danqi Chen, and Christopher D. Manning. CoQA: A conversational question answering challenge.Transactions of the Association for Computational Linguistics, 7, 2019
2019
-
[48]
RAGTruth: A hallucination corpus for developing trustworthy retrieval- augmented language models
Cheng Niu, Yuanhao Wu, Juno Zhu, Siliang Xu, KaShun Shum, Randy Zhong, Juntong Song, and Tong Zhang. RAGTruth: A hallucination corpus for developing trustworthy retrieval- augmented language models. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors, Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: ...
2024
-
[49]
Cohen, and Mirella Lapata
Shashi Narayan, Shay B. Cohen, and Mirella Lapata. Don’t give me the details, just the summary! topic-aware convolutional neural networks for extreme summarization. In Ellen Riloff, David Chiang, Julia Hockenmaier, and Jun’ichi Tsujii, editors,Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, Octobe...
2018
-
[50]
Training verifiers to solve math word problems.ArXiv, abs/2110.14168, 2021
Karl Cobbe, Vineet Kosaraju, Mo Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.ArXiv, abs/2110.14168, 2021
Pith/arXiv arXiv 2021
-
[51]
Arkil Patel, Satwik Bhattamishra, and Navin Goyal. Are NLP models really able to solve simple math word problems? In Kristina Toutanova, Anna Rumshisky, Luke Zettlemoyer, Dilek Hakkani-Tur, Iz Beltagy, Steven Bethard, Ryan Cotterell, Tanmoy Chakraborty, and Yichao Zhou, editors,Proceedings of the 2021 Conference of the North American Chapter of the Associ...
2021
-
[52]
Association for Computational Linguistics
-
[53]
TheoremQA: A theorem-driven question answering dataset
Wenhu Chen, Ming Yin, Max Ku, Pan Lu, Yixin Wan, Xueguang Ma, Jianyu Xu, Xinyi Wang, and Tony Xia. TheoremQA: A theorem-driven question answering dataset. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Singapore, December 2023. Association for Computational Linguistics
2023
-
[54]
Cummings, Matthias Plappert, Fotios Chantzis, Elizabeth Barnes, Ariel Herbert-V oss, William H
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Pondé, Jared Kaplan, Harrison Edwards, Yura Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mo Bavarian, Clemens Winter, Phi...
Pith/arXiv arXiv 2021
-
[55]
Cai, Michael Terry, Quoc V
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie J. Cai, Michael Terry, Quoc V . Le, and Charles Sutton. Program synthesis with large language models.ArXiv, 2021
2021
-
[56]
xLAM: A family of large action models to empower 13 AI agent systems
Jianguo Zhang, Tian Lan, Ming Zhu, Zuxin Liu, Thai Hoang, Shirley Kokane, Weiran Yao, Juntao Tan, Zhiwei Liu, Yihao Feng, Juan Carlos Niebles, Shelby Heinecke, Huan Wang, Silvio Savarese, and Caiming Xiong. xLAM: A family of large action models to empower 13 AI agent systems. In Luis Chiruzzo, Alan Ritter, and Lu Wang, editors,Proceedings of the 2025 Conf...
2025
-
[57]
The belebele benchmark: a parallel reading comprehension dataset in 122 language variants
Lucas Bandarkar, Davis Liang, Benjamin Muller, Mikel Artetxe, Satya Narayan Shukla, Donald Husa, Naman Goyal, Abhinandan Krishnan, Luke Zettlemoyer, and Madian Khabsa. The belebele benchmark: a parallel reading comprehension dataset in 122 language variants. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual Meeting o...
2024
-
[58]
Wong, and Rui Wang
Yiming Wang, Pei Zhang, Baosong Yang, Derek F. Wong, and Rui Wang. Latent space chain-of-embedding enables output-free LLM self-evaluation. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[59]
Xing, Hao Zhang, Joseph E
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena. InProceedings of the 37th International Conference on Neural Information Processing Systems, NIPS ’23, Red Hook, NY , USA...
2023
-
[60]
Brown, Jack Clark, Nicholas Joseph, Benjamin Mann, Sam McCandlish, Chris Olah, and Jared Kaplan
Saurav Kadavath, Tom Conerly, Amanda Askell, Thomas Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zachary Dodds, Nova Dassarma, Eli Tran-Johnson, Scott Johnston, Sheer El-Showk, Andy Jones, Nelson Elhage, Tristan Hume, Anna Chen, Yuntao Bai, Sam Bowman, Stanislav Fort, Deep Ganguli, Danny Hernandez, Josh Jacobson, John Kernion, Shauna Kravec, Lian...
Pith/arXiv arXiv 2022
-
[61]
Unsupervised real-time hallucination detection based on the internal states of large language models
Weihang Su, Changyue Wang, Qingyao Ai, Yiran Hu, Zhijing Wu, Yujia Zhou, and Yiqun Liu. Unsupervised real-time hallucination detection based on the internal states of large language models. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Findings of the Association for Computational Linguistics: ACL 2024, Bangkok, Thailand, August 2024. Associat...
2024
-
[62]
Semantic entropy probes: Robust and cheap hallucination detection in LLMs, 2025
Jannik Kossen, Jiatong Han, Muhammed Razzak, Lisa Schut, Shreshth A Malik, and Yarin Gal. Semantic entropy probes: Robust and cheap hallucination detection in LLMs, 2025
2025
-
[63]
Prompt-guided internal states for hallucination detection of large language models
Fujie Zhang, Peiqi Yu, Biao Yi, Baolei Zhang, Tong Li, and Zheli Liu. Prompt-guided internal states for hallucination detection of large language models. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pa...
2025
-
[64]
The llama 3 herd of models.CoRR, abs/2407.21783, 2024
Llama Team. The llama 3 herd of models.CoRR, abs/2407.21783, 2024
Pith/arXiv arXiv 2024
-
[65]
Qwen Team. Qwen3 technical report.CoRR, abs/2505.09388, 2025. 14 Appendix Contents A Backbone LLMs 17 B Prior Detector Settings 17 C Dataset Processing, Prompt Construction, and Generation Pipeline 19 C.1 Coverage Compared with Representative Hallucination Benchmarks . . . . . . . . 19 C.2 Dataset Processing and Unified Schema . . . . . . . . . . . . . . ...
Pith/arXiv arXiv 2025
-
[66]
If the Model’s answer aligns with any of the Acceptable Truths, outputcorrect. 23
-
[67]
If the Model’s answer aligns with any Known Traps or introduces fabricated facts, output hallucination
-
[68]
reasoning
If the Model explicitly states it does not know the answer, outputabstention. Provide a brief reasoning, then select the category. User input format: Context: <optional context> Question: <question> Acceptable Truths: <list of acceptable answers> Known Traps: <optional list of known incorrect answers> Model Answer: <generated response> Required structured...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.