Predictive Style Matching: Natural and Robust Humanoid Locomotion
Pith reviewed 2026-06-27 22:00 UTC · model grok-4.3
The pith
Predictive Style Matching lets RL policies match natural upper-body style while retaining task-only robustness to disturbances.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
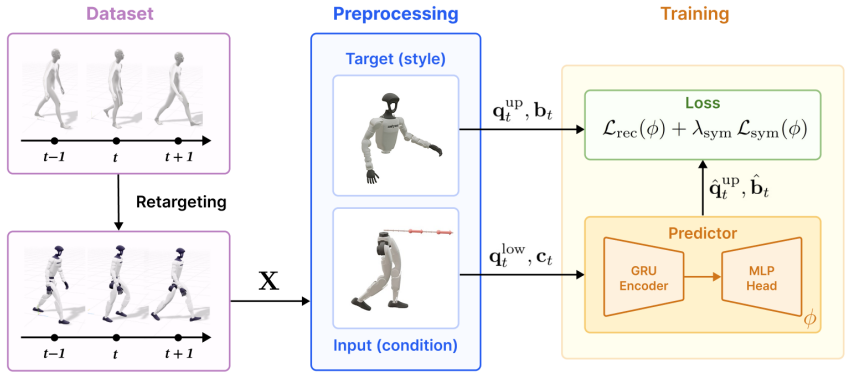
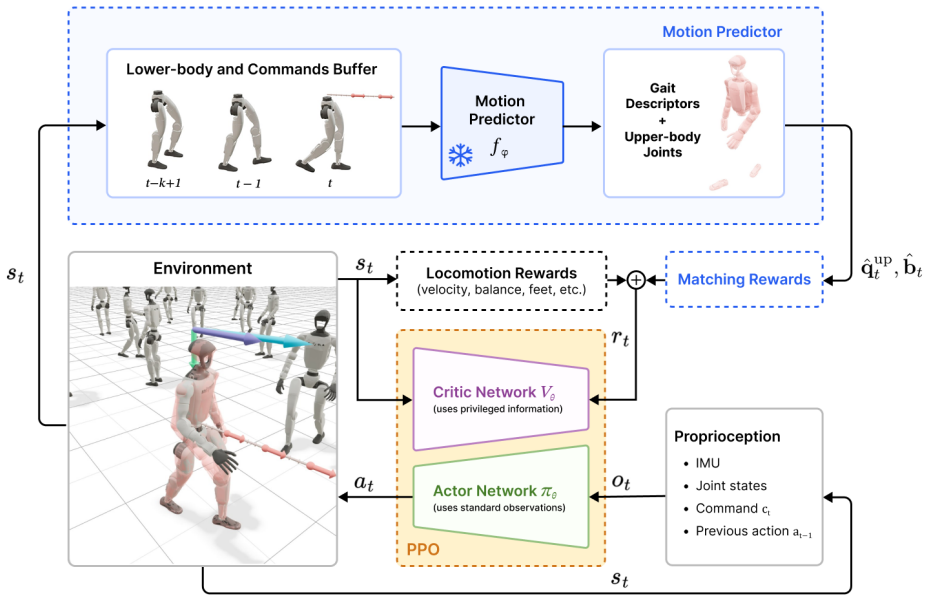
Predictive Style Matching trains an offline predictor that maps lower-body state history and velocity commands to upper-body joint and gait targets; these targets are used solely to shape the reward signal during policy training, so the deployed controller inherits the proprioceptive interface and disturbance-rejection performance of a task-only RL policy while attaining substantially lower upper-body style error.
What carries the argument
An offline predictor that outputs state-conditioned upper-body targets used only at training time to shape the reward.
If this is right
- The deployed controller uses only proprioceptive observations and incurs the same inference cost as a task-only baseline.
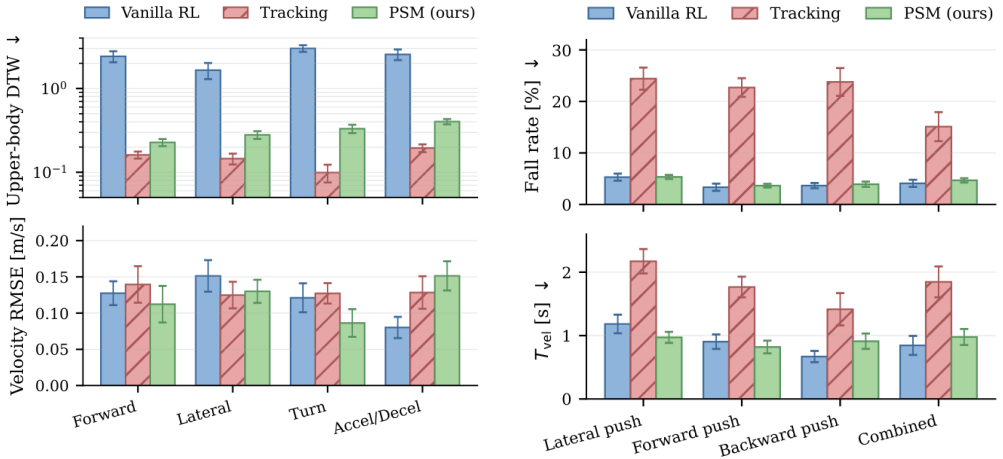
- Upper-body style error drops by roughly an order of magnitude relative to task-only RL.
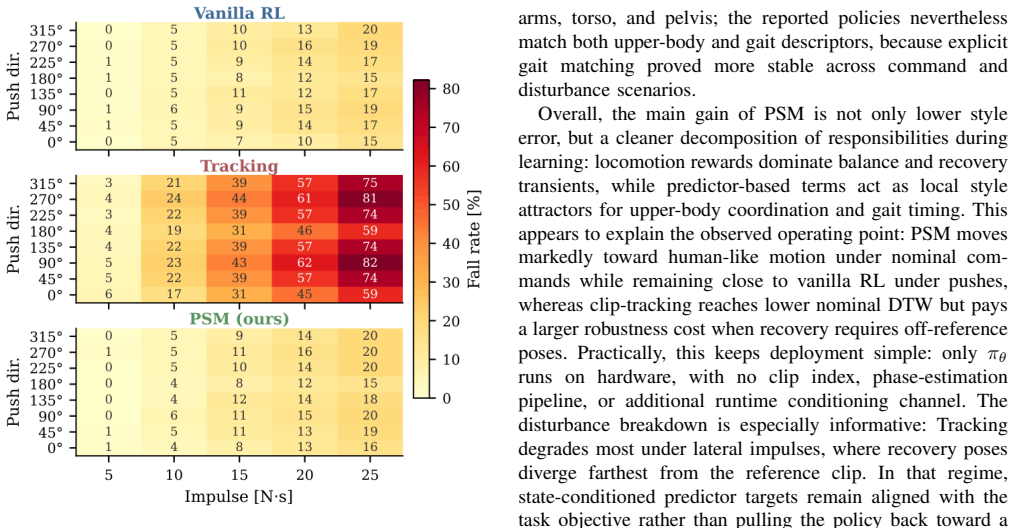
- Fall-recovery rate matches the task-only baseline and exceeds the motion-imitation baseline by a factor of about five.
- The method produces usable policies both in simulation and on Unitree G1 hardware.
Where Pith is reading between the lines
- The same offline-prediction approach could be applied to lower-body style or to other robot morphologies without changing the online controller interface.
- Because the predictor is trained once and then frozen, it could be reused to regularize multiple base policies trained on different tasks.
- Extending the predictor to include terrain or load estimates might further improve compatibility during recovery without altering the core training procedure.
Load-bearing premise
Targets generated by the offline predictor from lower-body history remain compatible with the transient poses required for balance recovery, so the added reward term does not reduce disturbance rejection.
What would settle it
A training run in which the style reward from the predictor produces a policy whose fall-recovery rate drops to levels comparable to the motion-imitation baseline would falsify the central claim.
Figures

read the original abstract
Reinforcement learning has become the prevailing approach to humanoid locomotion control: policies transfer reliably from simulation to hardware and recover gracefully from disturbances. Motion quality, however, still lags behind: task-only rewards often converge to stiff, asymmetric gaits, while motion imitation methods improve appearance but become more sensitive to external disturbances because reference signals can oppose the transient poses needed to regain balance. We propose Predictive Style Matching, in which an offline predictor maps the robot's lower-body state history and velocity commands to interpretable upper-body joint and gait targets that shape the rewards during training. Because the targets are state-conditioned rather than time-indexed and the predictor is used only at training time, the deployed controller inherits the proprioceptive interface and inference cost of a task-only RL baseline. On the Unitree G1, in both simulation and hardware, PSM reduces upper-body style error by roughly an order of magnitude over task-only RL while preserving its fall-recovery rate, whereas the motion-imitation baseline attains the lowest style error but fails to recover from disturbances about five times as often.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Predictive Style Matching (PSM) for humanoid locomotion control. An offline predictor maps lower-body state history and velocity commands to upper-body joint and gait targets that are used only to shape the RL reward during training; the resulting policy uses a standard proprioceptive interface at deployment. The central claim is that PSM reduces upper-body style error by roughly an order of magnitude relative to task-only RL while preserving its fall-recovery rate, in contrast to a motion-imitation baseline that achieves the lowest style error but recovers from disturbances approximately five times less often. Results are reported on the Unitree G1 in both simulation and hardware.
Significance. If the empirical claims hold under rigorous evaluation, the work would address a practically important trade-off between motion naturalness and robustness in RL locomotion policies. The design choice of a frozen, state-conditioned predictor used exclusively at training time is a clear strength: it avoids the inference overhead and reference-signal conflicts of imitation methods while still shaping style. The approach could be broadly applicable to other high-DoF robotic systems where offline data can inform reward design without altering the deployed controller.
major comments (2)
- [Method and Experiments] The central robustness claim rests on the assumption that targets produced by the offline predictor (trained on nominal locomotion data) remain compatible with the transient poses required for balance recovery. The manuscript provides no explicit evidence that this potential conflict was measured or mitigated (e.g., by evaluating the predictor on perturbed trajectories, reporting reward-component magnitudes during recovery episodes, or using reward masking). This is load-bearing for the claim that recovery rates are preserved.
- [Abstract and §4 (Experiments)] The abstract and experimental results assert an order-of-magnitude reduction in style error and a five-fold difference in recovery rates, yet supply no definition of the style-error metric, number of trials per condition, statistical tests, or precise implementation details of the motion-imitation and task-only baselines. These omissions prevent assessment of whether the reported differences are reliable and reproducible.
minor comments (1)
- [Method] The notation for the predictor input (lower-body state history) and output targets could be formalized with explicit variable definitions and dimensions to improve clarity for readers implementing the method.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our work. We address each major point below and will incorporate clarifications and additional analysis in the revised manuscript.
read point-by-point responses
-
Referee: [Method and Experiments] The central robustness claim rests on the assumption that targets produced by the offline predictor (trained on nominal locomotion data) remain compatible with the transient poses required for balance recovery. The manuscript provides no explicit evidence that this potential conflict was measured or mitigated (e.g., by evaluating the predictor on perturbed trajectories, reporting reward-component magnitudes during recovery episodes, or using reward masking). This is load-bearing for the claim that recovery rates are preserved.
Authors: We agree that direct measurement of predictor behavior on perturbed states would provide stronger support for the claim. The empirical preservation of recovery rates suggests compatibility in practice, as the state-conditioned predictor receives lower-body inputs that reflect recovery dynamics and the policy is free to deviate from targets when needed for balance. However, we did not include an explicit evaluation of predictor outputs or reward magnitudes on perturbed trajectories. In revision we will add this analysis, including predictor evaluation on recovery episodes and reporting of the style-reward component during those episodes. revision: yes
-
Referee: [Abstract and §4 (Experiments)] The abstract and experimental results assert an order-of-magnitude reduction in style error and a five-fold difference in recovery rates, yet supply no definition of the style-error metric, number of trials per condition, statistical tests, or precise implementation details of the motion-imitation and task-only baselines. These omissions prevent assessment of whether the reported differences are reliable and reproducible.
Authors: The referee correctly identifies that these details are not provided in the abstract or main experimental section. We will add an explicit definition of the style-error metric (mean squared deviation from predictor targets on upper-body joints), the number of trials per condition, and expanded implementation details for the baselines (reward weights, network sizes, and training procedure) to the revised manuscript. Statistical tests were not performed in the original experiments; we will either add them or report per-trial variability to allow readers to assess reliability. revision: yes
Circularity Check
No circularity: claims rest on empirical baseline comparisons
full rationale
The paper presents an empirical method where an offline predictor (trained on locomotion data) supplies state-conditioned upper-body targets used only in the training reward; the deployed policy uses only proprioception. The headline result (order-of-magnitude style improvement while preserving recovery rate) is demonstrated via direct quantitative comparisons to task-only RL and motion-imitation baselines on simulation and hardware metrics. No derivation reduces a claimed prediction to a fitted quantity by construction, no self-citation chain carries the central claim, and the evaluation metrics are independent of the predictor's internal definitions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption An offline model can be trained to produce upper-body targets from lower-body state history that improve style without harming robustness.
invented entities (1)
-
Predictive Style Matching predictor
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Learning to walk in minutes using massively parallel deep reinforcement learning,
N. Rudin, D. Hoeller, P. Reist, and M. Hutter, “Learning to walk in minutes using massively parallel deep reinforcement learning,” in Conference on Robot Learning, 2022, pp. 91–100
2022
-
[2]
mjlab: A lightweight framework for GPU-accelerated robot learning,
K. Zakka, Q. Liao, B. Yi, L. L. Lay, K. Sreenath, and P. Abbeel, “mjlab: A lightweight framework for GPU-accelerated robot learning,” arXiv preprint arXiv:2601.22074, 2026
-
[3]
Learning quadrupedal locomotion over challenging terrain,
J. Lee, Y . Seo, S. L. Zhang, S. Mahadevan, P. Clary, T. Nguyenet al., “Learning quadrupedal locomotion over challenging terrain,”Science Robotics, vol. 5, no. 47, p. eabc5986, 2020
2020
-
[4]
Learning robust perceptive locomotion for quadrupedal robots in the wild,
T. Miki, J. Lee, J. Hwangbo, L. Wellhausen, V . Koltun, and M. Hutter, “Learning robust perceptive locomotion for quadrupedal robots in the wild,”Science Robotics, vol. 7, no. 62, p. eabk2822, 2022
2022
-
[5]
Extreme parkour with legged robots,
X. Cheng, K. Shi, A. Agarwal, and D. Pathak, “Extreme parkour with legged robots,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 11 443–11 450
2024
-
[6]
Anymal parkour: Learning agile navigation for quadrupedal robots,
D. Hoeller, N. Rudin, D. V . Sako, and M. Hutter, “Anymal parkour: Learning agile navigation for quadrupedal robots,”Science Robotics, vol. 9, no. 88, p. eadh8134, 2024
2024
-
[7]
N. Rudin, J. He, J. Aurand, and M. Hutter, “Parkour in the wild: Learn- ing a general and extensible agile locomotion policy for quadrupedal robots,”arXiv preprint arXiv:2405.10427, 2024
-
[8]
ASAP: Aligning simulation and real-world physics for learning agile humanoid whole- body skills,
T. He, J. Gao, W. Xiao, Y . Zhang, R. Tsunodaet al., “ASAP: Aligning simulation and real-world physics for learning agile humanoid whole- body skills,”arXiv preprint arXiv:2412.04194, 2024
-
[9]
KungfuBot: Physics-based humanoid whole-body control for learning highly-dynamic skills,
Y . Shi, X. Wang, X. Li, J. Zhanget al., “KungfuBot: Physics-based humanoid whole-body control for learning highly-dynamic skills,” arXiv preprint arXiv:2410.05064, 2024
-
[10]
ZEST: Zero-shot embodied skill transfer for athletic robot control,
J.-P. Sleiman, H. Li, A. Adu-Bredu, R. Deits, A. Kumaret al., “ZEST: Zero-shot embodied skill transfer for athletic robot control,”arXiv preprint arXiv:2602.00401, 2026
-
[11]
Learning- based legged locomotion: State of the art and future perspectives,
S. Ha, J. Lee, S. L. Zhang, J. Hwangbo, X. B. Penget al., “Learning- based legged locomotion: State of the art and future perspectives,” Annual Review of Control, Robotics, and Autonomous Systems, vol. 6, pp. 339–364, 2023
2023
-
[12]
Adversarial motion priors make good substitutes for complex reward functions,
P. Escontrela, W. Yu, X. B. Peng, S. Levine, and Y . Ma, “Adversarial motion priors make good substitutes for complex reward functions,” arXiv preprint arXiv:2203.15103, 2022
-
[13]
Concurrent training of a control policy and a state estimator for tracking and estimation,
G. Ji, P. M. Wensing, and J. Grizzle, “Concurrent training of a control policy and a state estimator for tracking and estimation,” in2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2022, pp. 12 170–12 177
2022
-
[14]
Deepmimic: Example-guided deep reinforcement learning of physics-based char- acter skills,
X. B. Peng, P. Abbeel, S. Levine, and M. van de Panne, “Deepmimic: Example-guided deep reinforcement learning of physics-based char- acter skills,” inACM Transactions on Graphics (TOG), vol. 37, no. 4, 2018, pp. 1–14
2018
-
[15]
VideoMimic: Visual whole-body control for humanoids from human videos,
Z. Gu, H. Xue, Z. Xie, X. B. Penget al., “VideoMimic: Visual whole-body control for humanoids from human videos,”arXiv preprint arXiv:2412.16382, 2024
-
[16]
Amp: Adversarial motion priors for stylized physics-based character con- trol,
X. B. Peng, Y . Ma, P. Abbeel, S. Levine, and A. Kanazawa, “Amp: Adversarial motion priors for stylized physics-based character con- trol,” inACM Transactions on Graphics (TOG), vol. 40, no. 4, 2021, pp. 1–20
2021
-
[17]
Interactive character control with auto-regressive motion diffusion models,
Y . Shi, J. Wang, X. Jiang, B. Lin, B. Dai, and X. B. Peng, “Interactive character control with auto-regressive motion diffusion models,” in ACM Transactions on Graphics (Proc. SIGGRAPH 2024), 2024
2024
-
[18]
Flexible motion in-betweening with diffusion models,
S. Cohan, G. Tevet, D. Reda, X. B. Peng, and M. van de Panne, “Flexible motion in-betweening with diffusion models,” inACM SIGGRAPH 2024, 2024
2024
-
[19]
CLoSD: Closing the loop between simulation and diffusion for multi-task character control,
G. Tevet, S. Raab, S. Cohan, D. Reda, Z. Luo, X. B. Peng, A. H. Bermano, and M. van de Panne, “CLoSD: Closing the loop between simulation and diffusion for multi-task character control,” inInterna- tional Conference on Learning Representations, 2025
2025
-
[20]
CALM: Conditional adversarial latent models for directable virtual characters,
C. Tessler, Y . Kasten, Y . Guo, S. Mannor, G. Chechik, and X. B. Peng, “CALM: Conditional adversarial latent models for directable virtual characters,” inACM SIGGRAPH 2023, 2023
2023
-
[21]
ASE: Large- scale reusable adversarial skill embeddings for physically simulated characters,
X. B. Peng, Y . Guo, L. Halper, S. Levine, and S. Fidler, “ASE: Large- scale reusable adversarial skill embeddings for physically simulated characters,” inACM Transactions on Graphics (Proc. SIGGRAPH 2022), vol. 41, no. 4, 2022, pp. 1–17
2022
-
[22]
Masked- Mimic: Unified physics-based character control through masked mo- tion inpainting,
C. Tessler, Y . Guo, O. Nabati, G. Chechik, and X. B. Peng, “Masked- Mimic: Unified physics-based character control through masked mo- tion inpainting,” inACM Transactions on Graphics (Proc. SIGGRAPH Asia 2024), 2024
2024
-
[23]
BeyondMimic: From Motion Tracking to Versatile Humanoid Control via Guided Diffusion
Q. Liao, T. E. Truong, X. Huang, Y . Gao, G. Tevet, K. Sreenath, and C. K. Liu, “BeyondMimic: From motion tracking to ver- satile humanoid control via guided diffusion,”arXiv preprint arXiv:2508.08241, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
AI datasets for machine learning and motion capture,
Bones Studio, “AI datasets for machine learning and motion capture,” https://bones.studio/ai-datasets/, 2026, human motion capture data (BoneSeed)
2026
-
[25]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,”arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[26]
Dynamic programming algorithm optimiza- tion for spoken word recognition,
H. Sakoe and S. Chiba, “Dynamic programming algorithm optimiza- tion for spoken word recognition,”IEEE Transactions on Acoustics, Speech, and Signal Processing, vol. 26, no. 1, pp. 43–49, 1978
1978
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.