OPTIMUS-Prime: Minimal and Sufficient Concept Explanations for Deep Vision Models
Pith reviewed 2026-06-27 21:56 UTC · model grok-4.3
The pith
OPTIMUS generates visual heatmaps for deep vision models that provably guarantee the prediction using the smallest set of concepts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
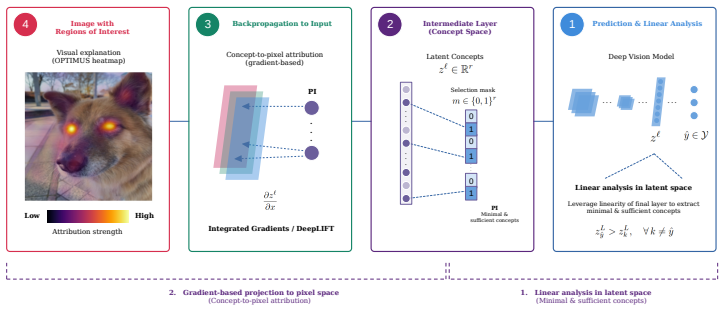
OPTIMUS explanations take the form of visual heatmaps grounded in prime implicants of the classifier's decision process. They satisfy sufficiency, meaning the concepts highlighted provably guarantee the model's prediction, and minimality, meaning no strict subset of those concepts retains the guarantee. This combination produces explanations that are logically tight and visually coherent for deep classification models.
What carries the argument
Prime implicants identified or approximated from the model's internal activations, rendered as heatmaps that enforce both sufficiency and minimality for the selected visual concepts.
If this is right
- The resulting heatmaps remain interpretable to end users while carrying explicit logical guarantees absent from most saliency methods.
- No smaller collection of concepts will still guarantee the classifier output.
- The approach applies directly to standard deep vision classification models and surfaces decision-relevant concepts on benchmarks.
- Explanations become both visually coherent and free of redundant concepts.
Where Pith is reading between the lines
- If the prime-implicant approximation holds across architectures, it could support systematic comparison of what different models treat as essential for the same input.
- The minimality property might help isolate the exact features a model uses when predictions change under small input perturbations.
- Extending the method beyond vision could test whether similar implicant extraction works for other data types where decision boundaries are less spatially organized.
Load-bearing premise
Prime implicants can be identified or approximated from the internal activations of a deep neural network in a way that directly yields the claimed formal guarantees for visual concepts.
What would settle it
A concrete falsifier would be a generated heatmap where the isolated concepts fail to force the model's original prediction, or where removing one concept leaves a subset that still guarantees the prediction.
Figures





read the original abstract
The growing demand for transparency in automated decision-making has propelled eXplainable Artificial Intelligence (XAI) to the forefront of machine learning research. In computer vision, however, existing explanation methods often prioritize end-user accessibility at the expense of formal guarantees, leaving a critical gap between practical utility and theoretical rigor. In this paper, we address this gap by introducing OPTIMUS, a novel framework for generating concept-based visual explanations for deep classification models. OPTIMUS explanations take the form of visual heatmaps that not only remain interpretable to end users, but are grounded in the well-established theory of prime implicants, providing formal guarantees that have been largely absent from existing saliency-based methods. Specifically, OPTIMUS explanations satisfy two desirable properties: sufficiency, ensuring that the highlighted concepts provably guarantee the classifier's prediction, and minimality, ensuring that no strict subset of those concepts retains this guarantee. Together, these properties yield explanations that are both logically tight and visually coherent. We validate our approach on a visual classification benchmark, demonstrating that OPTIMUS heatmaps naturally and faithfully surface the decision-relevant concepts underlying model predictions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces OPTIMUS, a framework for generating concept-based visual explanations (heatmaps) for deep vision classification models. It claims these explanations are grounded in prime implicant theory, satisfying formal guarantees of sufficiency (highlighted concepts provably entail the model's prediction) and minimality (no strict subset retains the guarantee).
Significance. If the formal guarantees are rigorously established, the work would be significant for XAI in computer vision by supplying theoretically grounded explanations with logical tightness, a property largely absent from saliency methods. The approach of leveraging boolean function theory for visual concepts is a promising direction if the extraction process can be shown to preserve exact entailment.
major comments (2)
- [Abstract and §3] Abstract and §3 (method): The abstract asserts that OPTIMUS explanations 'provably guarantee' the classifier's prediction via prime implicants, but no derivation, algorithm, or proof is supplied showing how continuous DNN activations are mapped to discrete boolean literals such that the conjunction exactly entails the output for all inputs (not merely sampled ones). Without discretization error bounds or a demonstration that no counterexamples exist, the formal sufficiency claim reduces to an empirical property.
- [§4] §4 (experiments): The validation is described only at a high level ('visual classification benchmark') with no quantitative assessment of whether the extracted implicants satisfy exact minimality or sufficiency on held-out data; this is load-bearing because the central claim requires the guarantees to hold beyond the training distribution.
minor comments (2)
- [§3] Notation for visual concepts (e.g., how superpixels or activation thresholds become literals) should be introduced with an explicit example early in §3 to aid readability.
- [Abstract] The abstract mentions 'a visual classification benchmark' but does not name the dataset; adding the name would improve clarity without altering the contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment point by point below.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (method): The abstract asserts that OPTIMUS explanations 'provably guarantee' the classifier's prediction via prime implicants, but no derivation, algorithm, or proof is supplied showing how continuous DNN activations are mapped to discrete boolean literals such that the conjunction exactly entails the output for all inputs (not merely sampled ones). Without discretization error bounds or a demonstration that no counterexamples exist, the formal sufficiency claim reduces to an empirical property.
Authors: We acknowledge the referee's observation. Section 3 describes the discretization of continuous concept activations into boolean literals via thresholding and the subsequent application of prime implicant extraction on the resulting boolean function. The formal guarantees of sufficiency and minimality are established exactly within this discretized boolean representation. However, the manuscript does not include explicit discretization error bounds or a proof that entailment holds without counterexamples in the original continuous input space. We will revise the paper to add a dedicated subsection deriving the discretization step, stating the assumptions under which the guarantees transfer, and discussing the distinction between the boolean and continuous domains. revision: yes
-
Referee: [§4] §4 (experiments): The validation is described only at a high level ('visual classification benchmark') with no quantitative assessment of whether the extracted implicants satisfy exact minimality or sufficiency on held-out data; this is load-bearing because the central claim requires the guarantees to hold beyond the training distribution.
Authors: We agree that quantitative assessment on held-out data is necessary to substantiate the claims. The current §4 presents qualitative results on the visual classification benchmark to illustrate the coherence of the generated heatmaps. In the revised version we will incorporate quantitative evaluations, including the fraction of test samples on which the extracted prime implicants preserve both sufficiency and minimality when the underlying boolean function is evaluated on unseen data. revision: yes
Circularity Check
No circularity; derivation applies external prime-implicant theory to DNN activations without self-referential reduction.
full rationale
The paper grounds its sufficiency and minimality claims in the established theory of prime implicants, an external boolean-logic framework independent of the present work. No equations, self-citations, or definitional loops appear in the provided abstract that would make the guarantees tautological or force predictions from fitted inputs. The mapping from continuous activations to boolean literals is presented as a methodological step rather than a self-defining equivalence, leaving the central claims dependent on external mathematical properties rather than internal construction. This is the most common honest outcome for a methods paper that invokes a pre-existing formal theory.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Sanity checks for saliency maps
Julius Adebayo, Justin Gilmer, Michael Muelly, Ian Goodfellow, Moritz Hardt, and Been Kim. Sanity checks for saliency maps. InProceedings of the 32nd International Conference on Neural Information Processing Systems, NIPS’18, pages 9525–9536, Red Hook, NY , USA, December 2018. Curran Associates Inc
2018
-
[2]
David Bau, Bolei Zhou, Aditya Khosla, Aude Oliva, and Antonio Torralba. Network Dissec- tion: Quantifying Interpretability of Deep Visual Representations.2017 IEEE Conference on 9 Computer Vision and Pattern Recognition (CVPR), pages 3319–3327, July 2017
2017
-
[3]
Understanding the role of individual units in a deep neural network.Proceedings of the National Academy of Sciences, 117(48):30071–30078, December 2020
David Bau, Jun-Yan Zhu, Hendrik Strobelt, Agata Lapedriza, Bolei Zhou, and Antonio Tor- ralba. Understanding the role of individual units in a deep neural network.Proceedings of the National Academy of Sciences, 117(48):30071–30078, December 2020
2020
-
[4]
Su- perposition of many models into one
Brian Cheung, Alexander Terekhov, Yubei Chen, Pulkit Agrawal, and Bruno Olshausen. Su- perposition of many models into one. InAdvances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019
2019
-
[5]
Arun Das and Paul Rad. Opportunities and challenges in explainable artificial intelligence (xai): A survey.arXiv preprint arXiv:2006.11371, 2020
arXiv 2006
-
[6]
On the inter- pretability of part-prototype based classifiers: a human centric analysis.Scientific Reports, 13(1):23088, December 2023
Omid Davoodi, Shayan Mohammadizadehsamakosh, and Majid Komeili. On the inter- pretability of part-prototype based classifiers: a human centric analysis.Scientific Reports, 13(1):23088, December 2023
2023
-
[7]
Toy Models of Superposition, September 2022
Nelson Elhage, Tristan Hume, Catherine Olsson, Nicholas Schiefer, Tom Henighan, Shauna Kravec, Zac Hatfield-Dodds, Robert Lasenby, Dawn Drain, Carol Chen, Roger Grosse, Sam McCandlish, Jared Kaplan, Dario Amodei, Martin Wattenberg, and Christopher Olah. Toy Models of Superposition, September 2022
2022
-
[8]
From contrastive to abductive explanations and back again
Alexey Ignatiev, Nina Narodytska, Nicholas Asher, and Joao Marques-Silva. From contrastive to abductive explanations and back again. InInternational Conference of the Italian Associa- tion for Artificial Intelligence, 2020
2020
-
[9]
On Explaining Decision Trees, October
Yacine Izza, Alexey Ignatiev, and Joao Marques-Silva. On Explaining Decision Trees, October
-
[10]
arXiv:2010.11034 [cs]
arXiv 2010
-
[11]
Visualizing and Understanding Recurrent Networks, November 2015
Andrej Karpathy, Justin Johnson, and Li Fei-Fei. Visualizing and Understanding Recurrent Networks, November 2015. arXiv:1506.02078 [cs]
Pith/arXiv arXiv 2015
-
[12]
Wattenberg, J
Been Kim, M. Wattenberg, J. Gilmer, Carrie J. Cai, James Wexler, F. Viégas, and R. Sayres. Interpretability Beyond Feature Attribution: Quantitative Testing with Concept Activation Vec- tors (TCA V). InInternational Conference on Machine Learning, November 2017
2017
-
[13]
Concept bottleneck models
Pang Wei Koh, Thao Nguyen, Yew Siang Tang, Stephen Mussmann, Emma Pierson, Been Kim, and Percy Liang. Concept bottleneck models. InProceedings of the 37th International Conference on Machine Learning, volume 119 ofICML’20, pages 5338–5348. JMLR.org, July 2020
2020
-
[14]
Captum: A unified and generic model interpretability library for PyTorch, September 2020
Narine Kokhlikyan, Vivek Miglani, Miguel Martin, Edward Wang, Bilal Alsallakh, Jonathan Reynolds, Alexander Melnikov, Natalia Kliushkina, Carlos Araya, Siqi Yan, and Orion Reblitz-Richardson. Captum: A unified and generic model interpretability library for PyTorch, September 2020. arXiv:2009.07896 [cs]
arXiv 2020
-
[15]
Similarity of Neural Network Representations Revisited, July 2019
Simon Kornblith, Mohammad Norouzi, Honglak Lee, and Geoffrey Hinton. Similarity of Neural Network Representations Revisited, July 2019. arXiv:1905.00414 [cs]
Pith/arXiv arXiv 2019
-
[16]
Yixuan Li, Jason Yosinski, Jeff Clune, Hod Lipson, and John Hopcroft. Convergent Learning: Do different neural networks learn the same representations? InProceedings of the 1st Inter- national Workshop on Feature Extraction: Modern Questions and Challenges at NIPS 2015, pages 196–212. PMLR, December 2015
2015
-
[17]
Lundberg and S-I
S. Lundberg and S-I. Lee. A unified approach to interpreting model predictions. InProc. of NIPS’17, 2017
2017
-
[18]
High Resolution Cat-Dog-Bird Image Dataset (13000)
MahmoudNoor. High Resolution Cat-Dog-Bird Image Dataset (13000)
-
[19]
Logic-based explainability in machine learning, 2023
Joao Marques-Silva. Logic-based explainability in machine learning, 2023
2023
-
[20]
Explaining naive bayes and other linear classifiers with polynomial time and delay
Joao Marques-Silva, Thomas Gerspacher, Martin Cooper, Alexey Ignatiev, and Nina Naro- dytska. Explaining naive bayes and other linear classifiers with polynomial time and delay. Advances in Neural Information Processing Systems, 33:20590–20600, 2020. 10
2020
-
[21]
Linguistic regularities in continuous space word representations
Tomas Mikolov, Wen-tau Yih, and Geoffrey Zweig. Linguistic regularities in continuous space word representations. In Lucy Vanderwende, Hal Daumé III, and Katrin Kirchhoff, editors, Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 746–751, Atlanta, Georgia,...
2013
-
[22]
why should I trust you?
M. T. Ribeiro, S. Singh, and C. Guestrin. "why should I trust you?": Explaining the predictions of any classifier. InSIGKDD, pages 1135–1144, 2016
2016
-
[23]
Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra
Ramprasaath R. Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. Grad-CAM: Visual Explanations from Deep Networks via Gradient- based Localization.International Journal of Computer Vision, 128(2):336–359, February
-
[24]
arXiv:1610.02391 [cs]
-
[25]
A. Shih, A. Choi, and A. Darwiche. A symbolic approach to explaining bayesian network classifiers. InProc. of IJCAI’18, pages 5103–5111, 2018
2018
-
[26]
Learning important features through propagating activation differences
Avanti Shrikumar, Peyton Greenside, and Anshul Kundaje. Learning important features through propagating activation differences. InProceedings of the 34th International Confer- ence on Machine Learning - Volume 70, ICML’17, pages 3145–3153, Sydney, NSW, Australia, August 2017. JMLR.org
2017
-
[27]
Karen Simonyan, Andrea Vedaldi, and Andrew Zisserman. Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps, April 2014. arXiv:1312.6034 [cs]
Pith/arXiv arXiv 2014
-
[28]
Formal Abductive Latent Explanations for Prototype-Based Networks.Pro- ceedings of the AAAI Conference on Artificial Intelligence, 40(30):25590–25598, March 2026
Jules Soria, Zakaria Chihani, Julien Girard-Satabin, Alban Grastien, Romain Xu-Darme, and Daniela Cancila. Formal Abductive Latent Explanations for Prototype-Based Networks.Pro- ceedings of the AAAI Conference on Artificial Intelligence, 40(30):25590–25598, March 2026
2026
-
[29]
Axiomatic attribution for deep networks
Mukund Sundararajan, Ankur Taly, and Qiqi Yan. Axiomatic attribution for deep networks. InProceedings of the 34th International Conference on Machine Learning - Volume 70, ICML’17, pages 3319–3328, Sydney, NSW, Australia, August 2017. JMLR.org
2017
-
[30]
Zeiler and Rob Fergus
Matthew D. Zeiler and Rob Fergus. Visualizing and Understanding Convolutional Networks. In David Fleet, Tomas Pajdla, Bernt Schiele, and Tinne Tuytelaars, editors,Computer Vision – ECCV 2014, volume 8689, pages 818–833. Springer International Publishing, Cham, 2014. Series Title: Lecture Notes in Computer Science
2014
-
[31]
Luisa M. Zintgraf, Taco S. Cohen, Tameem Adel, and Max Welling. Visualizing Deep Neural Network Decisions: Prediction Difference Analysis, February 2017. arXiv:1702.04595 [cs]. 11 A Notations, Acronyms and Datasets Notations/Acronyms Description XInput spaceX ⊆R P PInput dimension YLabel space{1, . . . , K} (xn, yn)i.i.d. draw from the joint distributionP...
Pith/arXiv arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.