The Masked Advantage: Uncovering Local-Language Access to Cultural Knowledge in LLMs
Pith reviewed 2026-06-27 22:06 UTC · model grok-4.3
The pith
After correcting for English proficiency, local languages give LLMs better access to culture-specific knowledge in nearly all tested settings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
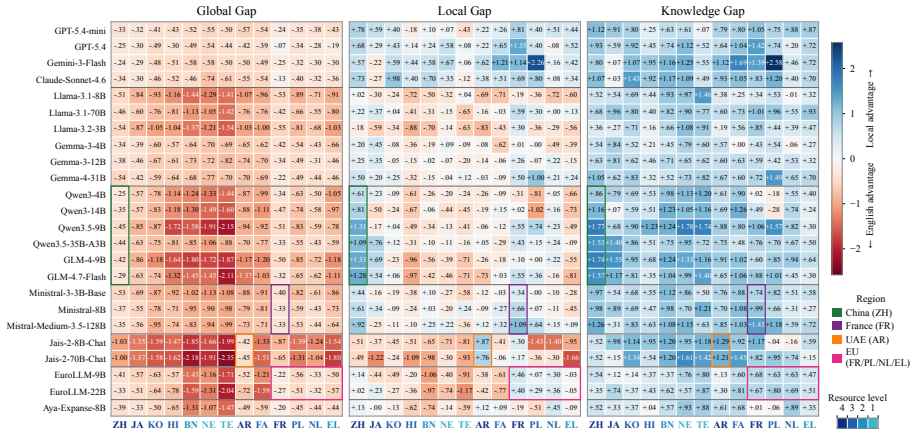
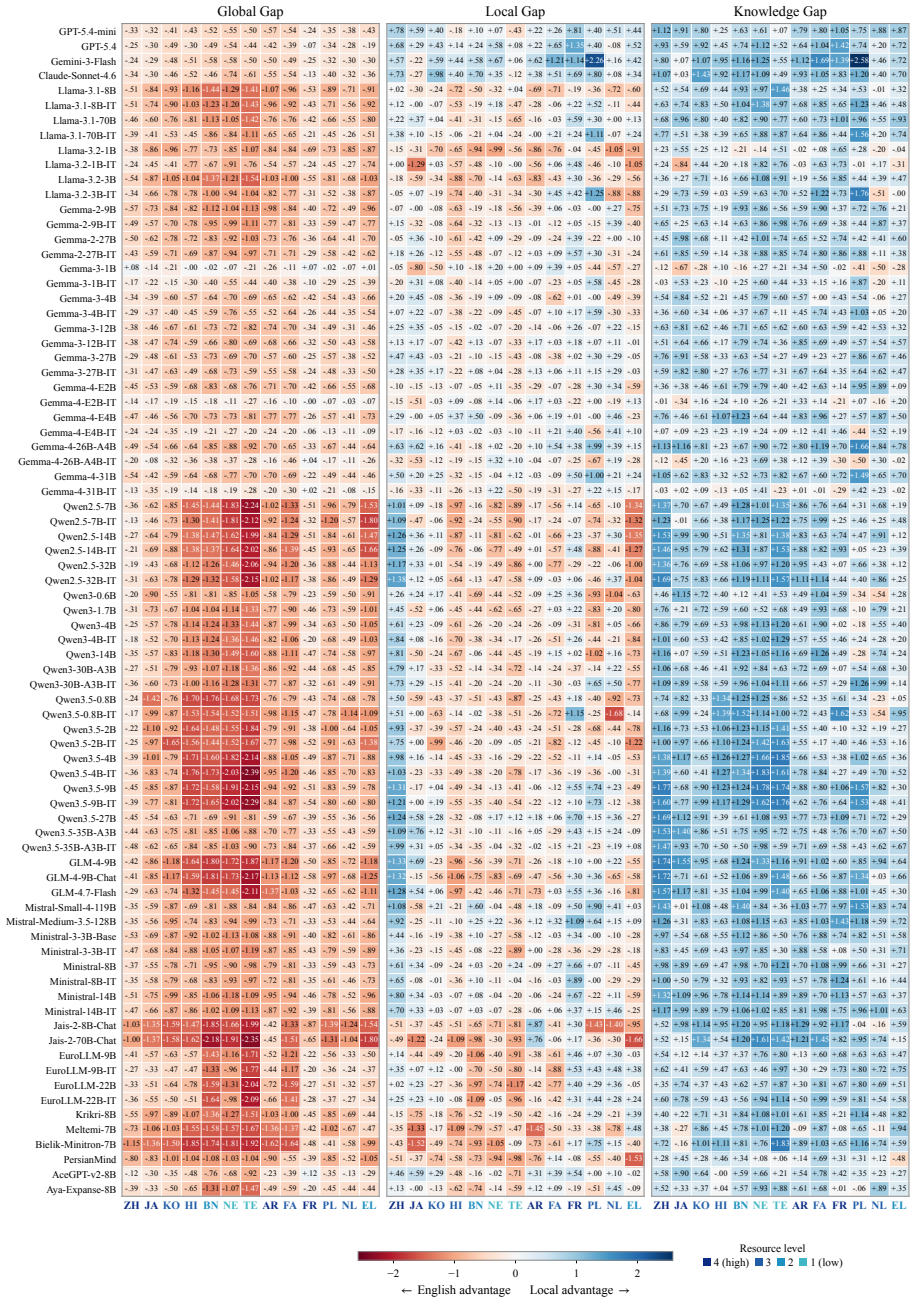
Crossing real-world cultural questions with English versus local-language prompts and fitting a shared 1PL item response theory model separates general proficiency from language-conditioned knowledge access. English holds a clear advantage on culture-agnostic items, yet local languages show a positive knowledge-access advantage on culture-specific items in nearly all of the 13 locales and roughly 80 models examined. The advantage is frequently masked in unadjusted accuracy and becomes more visible for frontier, regionally aligned, or language-adapted models.
What carries the argument
A shared 1PL item response theory model applied to crossed question types (culture-agnostic vs. culture-specific) and query languages (English vs. local) to isolate proficiency from localized knowledge access.
If this is right
- Raw accuracy on cultural questions underestimates the true accessibility of local cultural knowledge when local-language proficiency is lower.
- Frontier and language-adapted models display the local-language knowledge-access advantage more reliably than other models.
- Weaker observed performance in a local language on cultural tasks does not imply the absence of the relevant cultural knowledge inside the model.
- Evaluations that do not adjust for proficiency differences will systematically undervalue local-language routes to cultural information.
Where Pith is reading between the lines
- Evaluation benchmarks for cultural knowledge should routinely include both language versions of each item and an explicit proficiency adjustment step.
- Model developers could test whether additional local-language pretraining or alignment increases the measured knowledge-access advantage further.
- The pattern suggests that some cultural facts are stored in ways that are more readily retrieved when the prompt matches the language in which the fact was likely encountered during training.
Load-bearing premise
The 1PL item response theory model accurately separates general language proficiency from culture-specific knowledge access without residual confounding from question selection, model training data overlap, or response patterns.
What would settle it
Re-estimating the model with a different ability parameterization or with a new set of culture-specific questions that alters the estimated local-language advantage would falsify the central separation result.
Figures



read the original abstract
Large language models are increasingly used to answer culturally grounded questions across languages, yet it remains unclear whether local cultural knowledge is better accessed through English or the local language. Existing evaluations face two key limitations: many rely on parallel template-based questions that may not reflect how cultural knowledge naturally appears, and raw accuracy conflates general language proficiency with language-conditioned knowledge access. We address these issues with a controlled framework built on real-world cultural questions collected from regional benchmarks and local sources. By crossing question type (culture-agnostic vs. culture-specific) with query language (English vs. local language), and estimating ability with a shared 1PL item response theory model, we separate proficiency from localized knowledge access. Across 13 locales and roughly 80 models, we find a consistent English advantage on culture-agnostic questions, indicating stronger English proficiency. However, after accounting for this proficiency gap, local languages show a positive knowledge-access advantage in nearly all locale-model settings. This advantage is often masked in raw accuracy but becomes more visible for frontier, regionally aligned, or language-adapted models. Our results suggest that weaker local-language performance does not necessarily imply weaker cultural knowledge; rather, local cultural knowledge may be more accessible through the local language but hidden by limited language proficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a controlled evaluation framework for LLMs on cultural knowledge that collects real-world questions from regional benchmarks, crosses culture-agnostic vs. culture-specific items with English vs. local-language queries, and fits a single shared 1PL Rasch IRT model to separate general language proficiency from language-conditioned knowledge access. Across 13 locales and roughly 80 models the central result is an English advantage on culture-agnostic questions that, once proficiency is partialled out, reverses to a local-language advantage in knowledge access; this advantage is often masked in raw accuracy and is larger for frontier, regionally aligned, or language-adapted models.
Significance. If the IRT separation is shown to be valid, the result would be significant for multilingual evaluation: it would demonstrate that weaker local-language accuracy need not imply weaker cultural knowledge and would supply a concrete method for isolating language-specific knowledge access, with direct implications for benchmark design and model adaptation in non-English cultural settings.
major comments (3)
- [framework / IRT modeling] The description of the shared 1PL IRT model (framework section) reports no model-fit diagnostics, item-fit statistics, person reliability, or infit/outfit measures, leaving the claim that ability parameters cleanly capture general proficiency without visible empirical support.
- [framework / IRT modeling] No dimensionality checks (e.g., residual PCA or eigenvalue ratios) or differential item functioning (DIF) analysis are presented to verify the unidimensionality and cross-language invariance assumptions required for the language-by-item-type interaction to be interpreted as localized knowledge access rather than a modeling artifact.
- [results / discussion] The central claim that local languages exhibit a positive knowledge-access advantage after proficiency adjustment lacks any reported sensitivity analyses for question-selection bias, training-data overlap, or response-style confounds, which are load-bearing given that the advantage is defined as the residual after the IRT adjustment.
minor comments (2)
- [abstract] The abstract states 'roughly 80 models' and '13 locales' without listing selection criteria or exact counts, which would improve reproducibility.
- [framework] Explicit equations for the 1PL model (including how the language-by-item interaction is extracted from the ability estimates) would clarify the precise operationalization of 'knowledge-access advantage'.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help strengthen the methodological transparency and robustness of our IRT-based framework. We address each major comment below and will incorporate the suggested additions in the revised manuscript.
read point-by-point responses
-
Referee: The description of the shared 1PL IRT model (framework section) reports no model-fit diagnostics, item-fit statistics, person reliability, or infit/outfit measures, leaving the claim that ability parameters cleanly capture general proficiency without visible empirical support.
Authors: We agree that explicit model-fit diagnostics are needed to support the 1PL model. In the revision we will report infit/outfit statistics, item difficulty distributions, person reliability, and overall model fit indices for the shared model across locales to provide empirical grounding for the proficiency separation. revision: yes
-
Referee: No dimensionality checks (e.g., residual PCA or eigenvalue ratios) or differential item functioning (DIF) analysis are presented to verify the unidimensionality and cross-language invariance assumptions required for the language-by-item-type interaction to be interpreted as localized knowledge access rather than a modeling artifact.
Authors: We acknowledge the value of these checks for validating the modeling assumptions. The revised manuscript will include residual PCA, eigenvalue ratio analyses for unidimensionality, and DIF tests across English/local-language conditions to confirm that the language-by-item-type effects reflect knowledge access rather than violations of invariance. revision: yes
-
Referee: The central claim that local languages exhibit a positive knowledge-access advantage after proficiency adjustment lacks any reported sensitivity analyses for question-selection bias, training-data overlap, or response-style confounds, which are load-bearing given that the advantage is defined as the residual after the IRT adjustment.
Authors: We agree that sensitivity analyses are essential given the residual nature of the advantage. We will add analyses in the revision that test robustness to question-selection criteria, potential training-data overlap (via model provenance checks where available), and response-style differences, reporting how these affect the estimated local-language knowledge-access advantage. revision: yes
Circularity Check
No significant circularity; IRT separation is a data-driven modeling step, not a reduction by construction.
full rationale
The paper collects real-world cultural questions, crosses question type with language, fits a shared 1PL IRT model to the resulting responses, and computes the residual language-by-item-type interaction as the knowledge-access advantage. This computation is performed on new data and does not reduce to any self-cited prior result, fitted parameter renamed as prediction, or definitional equivalence. No self-citation chains, ansatzes smuggled via citation, or uniqueness theorems appear in the abstract or described framework. The derivation remains self-contained against the collected responses.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 1PL item response theory model can separate general language proficiency from localized cultural knowledge access
Reference graph
Works this paper leans on
-
[1]
KMMLU : Measuring Massive Multitask Language Understanding in K orean
Son, Guijin and Lee, Hanwool and Kim, Sungdong and Kim, Seungone and Muennighoff, Niklas and Choi, Taekyoon and Park, Cheonbok and Yoo, Kang Min and Biderman, Stella. KMMLU : Measuring Massive Multitask Language Understanding in K orean. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguist...
-
[2]
MILU : A Multi-task I ndic Language Understanding Benchmark
Verma, Sshubam and Khan, Mohammed Safi Ur Rahman and Kumar, Vishwajeet and Murthy, Rudra and Sen, Jaydeep. MILU : A Multi-task I ndic Language Understanding Benchmark. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2025. doi:10...
-
[3]
G eo MLAMA : Geo-Diverse Commonsense Probing on Multilingual Pre-Trained Language Models
Yin, Da and Bansal, Hritik and Monajatipoor, Masoud and Li, Liunian Harold and Chang, Kai-Wei. G eo MLAMA : Geo-Diverse Commonsense Probing on Multilingual Pre-Trained Language Models. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022. doi:10.18653/v1/2022.emnlp-main.132
-
[4]
Disentangling Language and Culture for Evaluating Multilingual Large Language Models
Ying, Jiahao and Tang, Wei and Zhao, Yiran and Cao, Yixin and Rong, Yu and Zhang, Wenxuan. Disentangling Language and Culture for Evaluating Multilingual Large Language Models. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.1082
-
[5]
CMMLU : Measuring massive multitask language understanding in C hinese
Li, Haonan and Zhang, Yixuan and Koto, Fajri and Yang, Yifei and Zhao, Hai and Gong, Yeyun and Duan, Nan and Baldwin, Timothy. CMMLU : Measuring massive multitask language understanding in C hinese. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.671
-
[6]
Is Translation All You Need? A Study on Solving Multilingual Tasks with Large Language Models
Liu, Chaoqun and Zhang, Wenxuan and Zhao, Yiran and Luu, Anh Tuan and Bing, Lidong. Is Translation All You Need? A Study on Solving Multilingual Tasks with Large Language Models. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2...
-
[7]
The State and Fate of Linguistic Diversity and Inclusion in the NLP World
Joshi, Pratik and Santy, Sebastin and Budhiraja, Amar and Bali, Kalika and Choudhury, Monojit. The State and Fate of Linguistic Diversity and Inclusion in the NLP World. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.560
-
[8]
A rabic MMLU : Assessing Massive Multitask Language Understanding in A rabic
Koto, Fajri and Li, Haonan and Shatnawi, Sara and Doughman, Jad and Sadallah, Abdelrahman and Alraeesi, Aisha and Almubarak, Khalid and Alyafeai, Zaid and Sengupta, Neha and Shehata, Shady and Habash, Nizar and Nakov, Preslav and Baldwin, Timothy. A rabic MMLU : Assessing Massive Multitask Language Understanding in A rabic. Findings of the Association for...
-
[9]
Lalor, John P. and Wu, Hao and Yu, Hong. Building an Evaluation Scale using Item Response Theory. Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. 2016. doi:10.18653/v1/D16-1062
-
[10]
and Jia, Robin and Boyd-Graber, Jordan
Rodriguez, Pedro and Barrow, Joe and Hoyle, Alexander and Lalor, John P. and Jia, Robin and Boyd-Graber, Jordan. Evaluation Examples are not Equally Informative: How should that change NLP Leaderboards?. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language P...
-
[11]
Global MMLU : Understanding and Addressing Cultural and Linguistic Biases in Multilingual Evaluation
Singh, Shivalika and Romanou, Angelika and Fourrier, Cl \'e mentine and Adelani, David Ifeoluwa and Ngui, Jian Gang and Vila-Suero, Daniel and Limkonchotiwat, Peerat and Marchisio, Kelly and Leong, Wei Qi and Susanto, Yosephine and Ng, Raymond and Longpre, Shayne and Ruder, Sebastian and Ko, Wei-Yin and Bosselut, Antoine and Oh, Alice and Martins, Andre a...
-
[12]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[13]
Publications Manual , year = "1983", publisher =
1983
-
[14]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[15]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[16]
Dan Gusfield , title =. 1997
1997
-
[17]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[18]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[19]
International Conference on Learning Representations , volume=
Include: Evaluating multilingual language understanding with regional knowledge , author=. International Conference on Learning Representations , volume=
-
[20]
arXiv preprint arXiv:2505.14990 , year=
Language Specific Knowledge: Do Models Know Better in X than in English? , author=. arXiv preprint arXiv:2505.14990 , year=
-
[21]
arXiv preprint arXiv:2601.15337 , year=
Language Models Entangle Language and Culture , author=. arXiv preprint arXiv:2601.15337 , year=
-
[22]
Advances in Neural Information Processing Systems , volume=
Blend: A benchmark for llms on everyday knowledge in diverse cultures and languages , author=. Advances in Neural Information Processing Systems , volume=
-
[23]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Polo, Felipe Maia and Weber, Lucas and Choshen, Leshem and Sun, Yuekai and Xu, Gongjun and Yurochkin, Mikhail , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[24]
metabench - A Sparse Benchmark of Reasoning and Knowledge in Large Language Models , url =
Kipnis, Alex and Voudouris, Konstantinos and Schulze Buschoff, Luca and Schulz, Eric , booktitle =. metabench - A Sparse Benchmark of Reasoning and Knowledge in Large Language Models , url =
-
[25]
Lost in Benchmarks? Rethinking Large Language Model Benchmarking with Item Response Theory , volume =
Zhou, Hongli and Huang, Hui and Zhao, Ziqing and Han, Lvyuan and Wang, Huicheng and Chen, Kehai and Yang, Muyun and Bao, Wei and Dong, Jian and Xu, Bing and Zhu, Conghui and Cao, Hailong and Zhao, Tiejun , year =. Lost in Benchmarks? Rethinking Large Language Model Benchmarking with Item Response Theory , volume =. Proceedings of the AAAI Conference on Ar...
-
[26]
Chen, Yu and Silva Filho, Telmo and Prudencio, Ricardo B and Diethe, Tom and Flach, Peter , booktitle=. \^. 2019 , organization=
2019
-
[27]
Efficiently measuring the cognitive ability of llms: An adaptive testing perspective , author=
-
[28]
arXiv preprint arXiv:2511.04689 , year=
Adaptive Testing for LLM Evaluation: A Psychometric Alternative to Static Benchmarks , author=. arXiv preprint arXiv:2511.04689 , year=
-
[29]
2017 , eprint=
Adam: A Method for Stochastic Optimization , author=. 2017 , eprint=
2017
-
[30]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Global mmlu: Understanding and addressing cultural and linguistic biases in multilingual evaluation , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[31]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
TurkishMMLU: Measuring massive multitask language understanding in Turkish , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
2024
-
[32]
arXiv preprint arXiv:2404.06644 , year=
Khayyam Challenge (PersianMMLU): Is your LLM truly wise to the Persian language? , author=. arXiv preprint arXiv:2404.06644 , year=
-
[33]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
CaLMQA: Exploring culturally specific long-form question answering across 23 languages , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[34]
Advances in Neural Information Processing Systems , volume=
Bertaqa: How much do language models know about local culture? , author=. Advances in Neural Information Processing Systems , volume=
-
[35]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
CulturalBench: A robust, diverse and challenging benchmark for measuring LMs’ cultural knowledge through human-AI red-teaming , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[36]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Lost in multilinguality: Dissecting cross-lingual factual inconsistency in transformer language models , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[37]
Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
Beneath the surface of consistency: Exploring cross-lingual knowledge representation sharing in llms , author=. Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
2025
-
[38]
arXiv preprint arXiv:2406.16135 , year=
Crosslingual capabilities and knowledge barriers in multilingual large language models , author=. arXiv preprint arXiv:2406.16135 , year=
-
[39]
1993 , publisher=
Minimum wages and employment: A case study of the fast food industry in New Jersey and Pennsylvania , author=. 1993 , publisher=
1993
-
[40]
Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing , pages=
Building an evaluation scale using item response theory , author=. Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing , pages=
2016
-
[41]
Evaluation examples are not equally informative: How should that change NLP leaderboards? , author=. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , pages=
-
[42]
Psychometrika , volume=
Homogeneous case of the continuous response model , author=. Psychometrika , volume=. 1973 , publisher=
1973
-
[43]
arXiv preprint arXiv:2602.05150 , year=
GreekMMLU: A Native-Sourced Multitask Benchmark for Evaluating Language Models in Greek , author=. arXiv preprint arXiv:2602.05150 , year=
-
[44]
arXiv preprint arXiv:2407.21783 , year=
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
-
[45]
arXiv preprint arXiv:2408.00118 , year=
Gemma 2: Improving open language models at a practical size , author=. arXiv preprint arXiv:2408.00118 , year=
-
[46]
2025 , eprint=
Gemma 3 Technical Report , author=. 2025 , eprint=
2025
-
[47]
2026 , month = apr, howpublished =
Gemma 4 Technical Overview and Model Card , author =. 2026 , month = apr, howpublished =
2026
-
[48]
OpenAI GPT-5 System Card , year =. 2601.03267 , archivePrefix=
-
[49]
2025 , month = dec, howpublished =
Gemini 3 Flash Model Card , author =. 2025 , month = dec, howpublished =
2025
-
[50]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[51]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[52]
2026 , eprint=
Qwen3.5-Omni Technical Report , author=. 2026 , eprint=
2026
-
[53]
arXiv preprint arXiv:2406.12793 , year=
Chatglm: A family of large language models from glm-130b to glm-4 all tools , author=. arXiv preprint arXiv:2406.12793 , year=
-
[54]
2025 , eprint=
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models , author=. 2025 , eprint=
2025
-
[55]
arXiv preprint arXiv:2601.08584 , year=
Ministral 3 , author=. arXiv preprint arXiv:2601.08584 , year=
-
[56]
arXiv preprint arXiv:2506.10910 , year=
Magistral , author=. arXiv preprint arXiv:2506.10910 , year=
-
[57]
arXiv preprint arXiv:2510.25771 , year=
Gaperon: A Peppered English-French Generative Language Model Suite , author=. arXiv preprint arXiv:2510.25771 , year=
-
[58]
arXiv preprint arXiv:2308.16149 , year=
Jais and jais-chat: Arabic-centric foundation and instruction-tuned open generative large language models , author=. arXiv preprint arXiv:2308.16149 , year=
-
[59]
arXiv preprint arXiv:2603.16397 , year=
Fanar 2.0: Arabic Generative AI Stack , author=. arXiv preprint arXiv:2603.16397 , year=
-
[60]
Advances in Neural Information Processing Systems , volume=
Alignment at pre-training! towards native alignment for Arabic LLMs , author=. Advances in Neural Information Processing Systems , volume=
-
[61]
arXiv preprint arXiv:2505.13772 , year=
Krikri: Advancing open large language models for greek , author=. arXiv preprint arXiv:2505.13772 , year=
-
[62]
arXiv preprint arXiv:2407.20743 , year=
Meltemi: The first open large language model for greek , author=. arXiv preprint arXiv:2407.20743 , year=
-
[63]
2024 , howpublished =
Llama-3-Open-Ko-8B , author =. 2024 , howpublished =
2024
-
[64]
arXiv preprint arXiv:2404.17790 , year=
Continual pre-training for cross-lingual llm adaptation: Enhancing japanese language capabilities , author=. arXiv preprint arXiv:2404.17790 , year=
-
[65]
arXiv preprint arXiv:2401.06466 , year=
Persianmind: A cross-lingual persian-english large language model , author=. arXiv preprint arXiv:2401.06466 , year=
-
[66]
1: A Polish Language Model--Development, Insights, and Evaluation , author=
Bielik 7B v0. 1: A Polish Language Model--Development, Insights, and Evaluation , author=. arXiv preprint arXiv:2410.18565 , year=
-
[67]
Sea-lion: Southeast asian languages in one network , author=. Proceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics , pages=
-
[68]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations) , pages=
SeaLLMs-large language models for Southeast Asia , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations) , pages=
-
[69]
2024 , eprint=
Aya Expanse: Combining Research Breakthroughs for a New Multilingual Frontier , author=. 2024 , eprint=
2024
-
[70]
2024 , eprint=
EuroLLM: Multilingual Language Models for Europe , author=. 2024 , eprint=
2024
-
[71]
2025 , eprint=
Teuken-7B-Base & Teuken-7B-Instruct: Towards European LLMs , author=. 2025 , eprint=
2025
-
[72]
Applying the Rasch Model: Fundamental Measurement in the Human Sciences , author =. 2015 , publisher =. doi:10.4324/9781315814698 , isbn =
-
[73]
Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
On the cross-lingual transferability of monolingual representations , author=. Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
-
[74]
arXiv preprint arXiv:2506.14012 , year=
Lost in the mix: Evaluating llm understanding of code-switched text , author=. arXiv preprint arXiv:2506.14012 , year=
-
[75]
Building an Evaluation Scale using Item Response Theory , volume =
Lalor, John and Wu, Hao and Yu, Hong , year =. Building an Evaluation Scale using Item Response Theory , volume =
-
[76]
Prudêncio and Adolfo Martínez-Usó and José Hernández-Orallo , keywords =
Fernando Martínez-Plumed and Ricardo B.C. Prudêncio and Adolfo Martínez-Usó and José Hernández-Orallo , keywords =. Item response theory in AI: Analysing machine learning classifiers at the instance level , journal =. 2019 , issn =. doi:https://doi.org/10.1016/j.artint.2018.09.004 , url =
-
[77]
Claude Sonnet 4.6 , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.