Rapid co-design of Buoyancy-assisted robots for Challenging Locomotion using Gaussian Evolutionary Specialists
Pith reviewed 2026-06-27 21:40 UTC · model grok-4.3
The pith
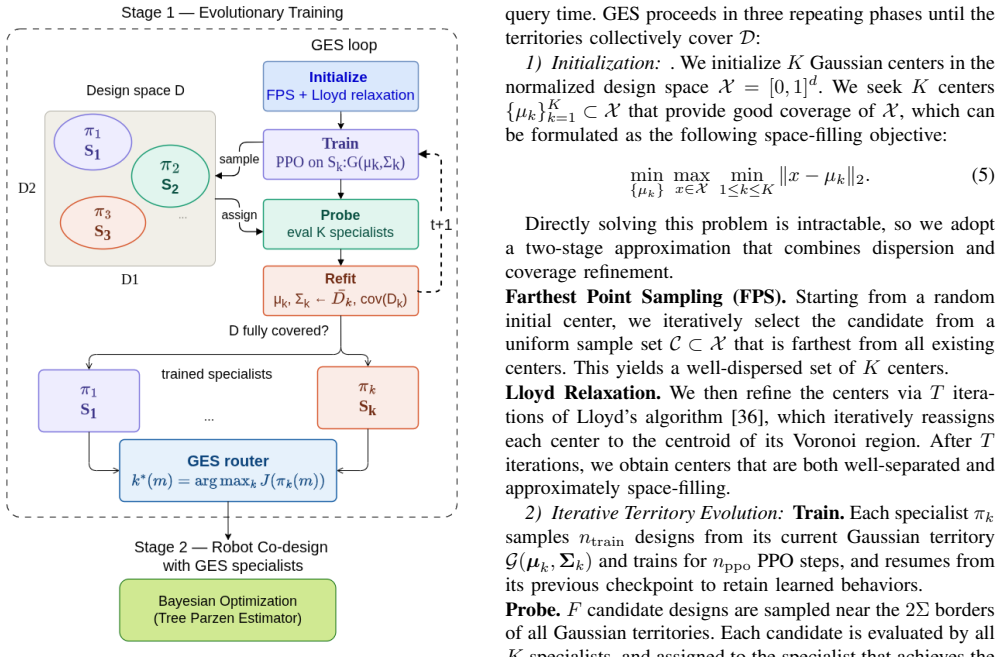
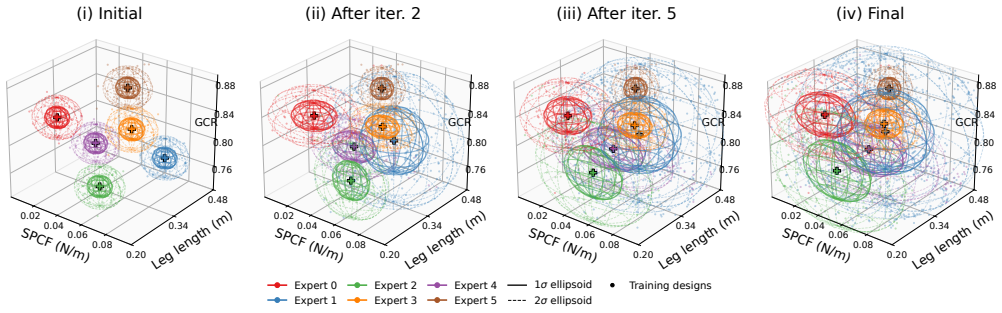
Gaussian Evolutionary Specialists partition design space into Gaussian regions and assign specialist policies to enable direct evaluation of new robot morphologies without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GES decouples design-space partitioning from policy learning by assigning specialist policies to evolving Gaussian regions and iteratively refines them via training, probing, and territory expansion; the resulting specialists are integrated into a design sampling loop that replaces costly re-training with direct evaluation.
What carries the argument
Gaussian Evolutionary Specialists (GES), a framework that partitions the design space into Gaussian regions and trains specialist policies on those regions to capture diverse behaviors for direct evaluation on new designs.
If this is right
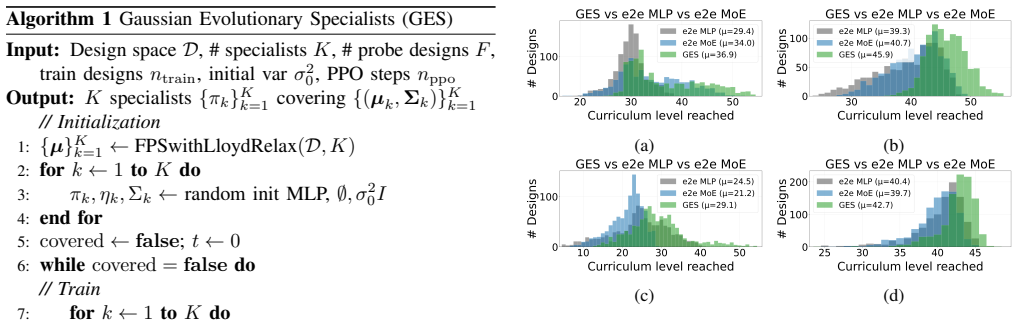
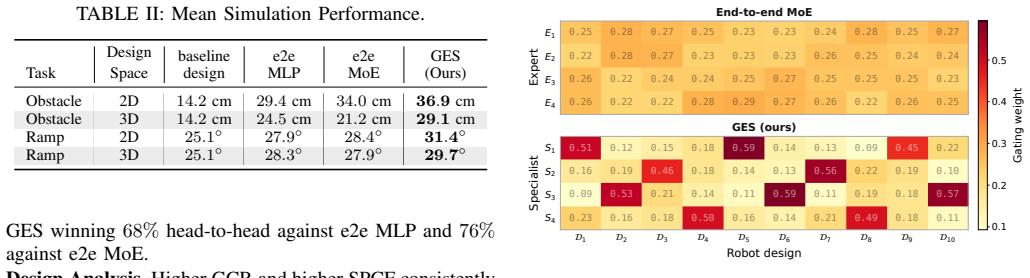
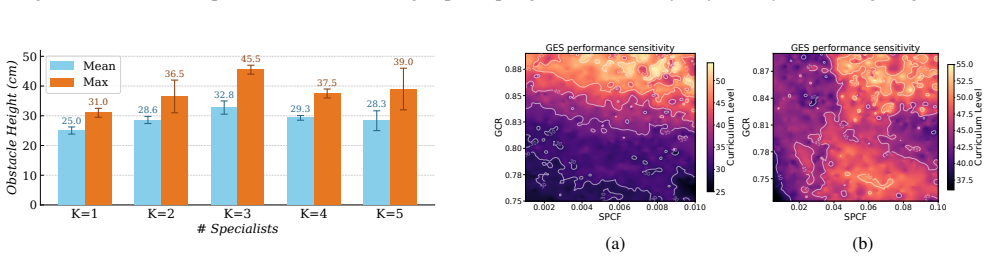
- Designs found by GES achieve 5-25 percent higher performance than designs found by naive universal policies.
- A GES-optimized design clears a 24 cm obstacle on hardware, three times the height cleared by the baseline BALLU design.
- Total design optimization time drops by 37 percent because repeated policy retraining is replaced by direct specialist evaluation.
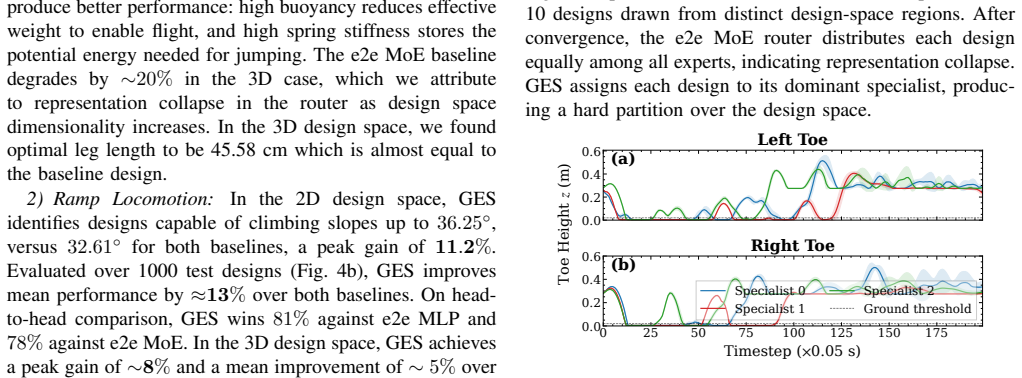
- Specialist policies remain usable across multiple designs inside their Gaussian region without behavioral collapse.
Where Pith is reading between the lines
- The Gaussian partitioning could be replaced by other adaptive region definitions if performance landscapes prove non-Gaussian.
- Direct evaluation might extend to sim-to-real transfer if the specialists are trained with domain randomization.
- The same decoupling could apply to co-design of non-legged systems where morphology changes alter dynamics strongly.
Load-bearing premise
Specialist policies trained on Gaussian regions can be directly evaluated on new designs without retraining and still accurately predict real performance.
What would settle it
Run a specialist policy directly on a held-out design and compare its measured performance against the performance of a policy retrained from scratch specifically for that same design; a large consistent gap would falsify the claim.
Figures



read the original abstract
Designing high-performance legged robots requires jointly optimizing morphology and control. Model-free Reinforcement Learning (RL) offers an alternative to model-predictive control for developing robust controllers without explicitly specifying robot dynamics. Thus, we have seen theuse of RL to train controllers and evaluate designs for robot morphology optimization. While RL has shown success inlocomotion, using it in the co-design inner loop is expensive due to repeated policy training. Universal policies conditioned on morphology offer a promising alternative, but suffer from behavioral diversity collapse, converging to a single strategy that performs sub-optimally across designs. On the other hand, end-to-end Mixture-of-Experts (MoE) architectures fail due to a collapse in its representation. We propose Gaussian Evolutionary Specialists (GES), a framework that decouples design-space partitioning from policy learning to capture diverse behaviors explicitly. GES assigns specialist policies to evolving Gaussian regions and iteratively refines them via training, probing, and territory expansion. The resulting specialists are integrated into a design sampling loop, replacing costly re-training with direct evaluation. When tested on the Buoyancy-Assisted Light Legged Unit (BALLU), GES discovers designs with 5 - 25% higher performance than naive universal policies. On hardware, a GES optimized design overcomes a 24 cm tall obstacle - 3x improvement over the baseline BALLU design. Moreover, GES curtails design optimization time by 37%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Gaussian Evolutionary Specialists (GES), a framework that decouples design-space partitioning into evolving Gaussian regions from policy learning to enable diverse specialist behaviors for robot co-design. It integrates these specialists into a design sampling loop that replaces repeated policy retraining with direct evaluation on new morphologies. Tested on the Buoyancy-Assisted Light Legged Unit (BALLU), GES is claimed to yield designs with 5-25% higher performance than naive universal policies, a hardware design that clears a 24 cm obstacle (3x the baseline), and a 37% reduction in design optimization time.
Significance. If the direct-evaluation assumption holds and the reported gains are reproducible, GES could meaningfully reduce the computational burden of morphology-control co-design loops that rely on model-free RL, offering a practical route to faster iteration on specialized legged robots for challenging environments. The explicit hardware result on BALLU supplies a concrete, falsifiable outcome that strengthens the practical relevance beyond simulation-only claims.
major comments (2)
- [Abstract] Abstract: The central efficiency claim (37% time reduction and 5-25% performance gains) rests on replacing retraining with direct evaluation of region-specialist policies, yet the manuscript provides no ablation, correlation coefficient, or transfer metric comparing direct evaluation scores to performance obtained after retraining a fresh policy on the same new design; without this, the reported improvements cannot be verified as load-bearing.
- [Abstract] Abstract: The hardware result (24 cm obstacle, 3x baseline) and simulation gains are stated without error bars, number of trials, statistical tests, or explicit definitions of the universal-policy and baseline BALLU designs, rendering the quantitative claims impossible to assess for robustness or reproducibility.
minor comments (1)
- [Abstract] The abstract contains a typographical error ('theuse' instead of 'the use').
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point-by-point below and will incorporate revisions to improve verifiability of the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central efficiency claim (37% time reduction and 5-25% performance gains) rests on replacing retraining with direct evaluation of region-specialist policies, yet the manuscript provides no ablation, correlation coefficient, or transfer metric comparing direct evaluation scores to performance obtained after retraining a fresh policy on the same new design; without this, the reported improvements cannot be verified as load-bearing.
Authors: We agree that an explicit validation of the direct-evaluation assumption is necessary to substantiate the efficiency claims. The current manuscript motivates the approach via the design-sampling loop but does not include a dedicated ablation with correlation or transfer metrics. In the revision we will add a new subsection reporting (i) Pearson correlation between direct-evaluation scores and post-retraining returns across sampled morphologies and (ii) the resulting wall-clock savings, thereby grounding the 37 % figure. revision: yes
-
Referee: [Abstract] Abstract: The hardware result (24 cm obstacle, 3x baseline) and simulation gains are stated without error bars, number of trials, statistical tests, or explicit definitions of the universal-policy and baseline BALLU designs, rendering the quantitative claims impossible to assess for robustness or reproducibility.
Authors: We acknowledge that the abstract’s quantitative statements lack the statistical detail required for reproducibility assessment. While the body of the manuscript defines the baselines and reports experimental protocols, the abstract itself does not. We will revise the abstract to state the number of independent trials, include standard-error bars or confidence intervals, report the appropriate statistical test, and explicitly name the universal-policy and baseline BALLU configurations. revision: yes
Circularity Check
No significant circularity; empirical results with no self-referential derivations
full rationale
The paper describes an algorithmic framework (GES) for co-design and reports performance metrics from simulation and hardware experiments on the BALLU robot. No equations, first-principles derivations, or predictions are presented that reduce by construction to fitted inputs or self-citations. The 5-25% improvement, 24 cm obstacle crossing, and 37% time reduction are framed as measured outcomes rather than quantities defined in terms of the same data or prior self-citations. The direct-evaluation assumption is an empirical claim subject to external validation, not a definitional loop.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Model-free RL can produce robust locomotion controllers without explicit robot dynamics
- ad hoc to paper Direct evaluation of specialist policies on new designs accurately reflects performance without retraining
invented entities (1)
-
Gaussian Evolutionary Specialists (GES)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Embodied intelli- gence via learning and evolution,
A. Gupta, S. Savarese, S. Ganguli, and L. Fei-Fei, “Embodied intelli- gence via learning and evolution,”Nature Communications, 2021
2021
-
[2]
Learning-based design and control for quadrupedal robots with parallel-elastic actuators,
F. Bjelonic, J. Lee, P. Arm, D. Sako, D. Tateo, S. Coros, and M. Hutter, “Learning-based design and control for quadrupedal robots with parallel-elastic actuators,”IEEE Robotics and Automation Letters, vol. 8, no. 3, 2023
2023
-
[3]
Ballu2: A safe and affordable buoyancy assisted biped,
H. Chae, M. S. Ahn, D. Noh, H. Nam, and D. Hong, “Ballu2: A safe and affordable buoyancy assisted biped,”Frontiers in Robotics and AI, 2021
2021
-
[4]
Buoyant choreographies: Harmonies of light, sound, and human connection,
D. Hong and Y . Tanaka, “Buoyant choreographies: Harmonies of light, sound, and human connection,” inIEEE International Conference on Robotics and Automation (ICRA) 25, Arts in robotics, 2025
2025
-
[5]
Computational Design of Robotic Devices From High-Level Motion Specifications,
S. Ha, S. Coros, A. Alspach, J. M. Bern, J. Kim, and K. Yamane, “Computational Design of Robotic Devices From High-Level Motion Specifications,”IEEE Transactions on Robotics, vol. 34, 2018
2018
-
[6]
An end-to-end differentiable framework for contact-aware robot design,
J. Xu, T. Chen, L. Zlokapa, M. Foshey, W. Matusik, S. Sueda, and P. Agrawal, “An end-to-end differentiable framework for contact-aware robot design,” inRobotics: Science and Systems, 2021
2021
-
[7]
Meta reinforcement learning for optimal design of legged robots,
´A. Belmonte-Baeza, J. Lee, G. Valsecchi, and M. Hutter, “Meta reinforcement learning for optimal design of legged robots,”IEEE Robotics and Automation Letters, vol. 7, no. 4, 2022
2022
-
[8]
Transform2act: Learning a transform-and-control policy for efficient agent design,
Y . Yuan, Y . Song, Z. Luo, W. Sun, and K. M. Kitani, “Transform2act: Learning a transform-and-control policy for efficient agent design,” ArXiv, vol. abs/2110.03659, 2021
arXiv 2021
-
[9]
Residual physics learning and system identification for sim-to-real transfer of policies on buoyancy assisted legged robots,
N. Sontakke, H. Chae, S. Lee, T. Huang, D. W. Hong, and S. Hal, “Residual physics learning and system identification for sim-to-real transfer of policies on buoyancy assisted legged robots,” in2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2023, pp. 392–399
2023
-
[10]
Robogrammar: Graph grammar for terrain- optimized robot design,
A. Zhao, J. Xu, M. Konakovi ´c-Lukovi´c, J. Hughes, A. Spielberg, D. Rus, and W. Matusik, “Robogrammar: Graph grammar for terrain- optimized robot design,” inACM Transactions on Graphics (TOG), vol. 39, no. 6, 2020
2020
-
[11]
Glso: Grammar-guided latent space optimization for sample-efficient robot design automation,
J. Hu, J. Xu, A. Spielberg, S. Shekhar, A. B. Farimani, D. Rus, and W. Matusik, “Glso: Grammar-guided latent space optimization for sample-efficient robot design automation,” inConference on Robot Learning (CoRL), 2022
2022
-
[12]
Genloco: Generalized locomotion controllers for quadrupedal robots,
G. Feng,et al., “Genloco: Generalized locomotion controllers for quadrupedal robots,” inConference on Robot Learning (CoRL), 2023
2023
-
[13]
On Designing a Learning Robot: Improving Morphol- ogy for Enhanced Task Performance and Learning,
M. Sorokin, C. Fu, J. Tan, C. Liu, Y . Bai, W. Lu, S. Ha, and M. Khansari, “On Designing a Learning Robot: Improving Morphol- ogy for Enhanced Task Performance and Learning,” inIEEE/RJS International Conference on Intelligent Robots and Systems, 2023
2023
-
[14]
Gra- dient surgery for multi-task learning,
T. Yu, S. Kumar, A. Gupta, S. Levine, K. Hausman, and C. Finn, “Gra- dient surgery for multi-task learning,”Advances in neural information processing systems, vol. 33, pp. 5824–5836, 2020
2020
-
[15]
Conflict-averse gradient descent for multi-task learning,
B. Liu, X. Liu, X. Jin, P. Stone, and Q. Liu, “Conflict-averse gradient descent for multi-task learning,”Advances in neural information processing systems, vol. 34, pp. 18 878–18 890, 2021
2021
-
[16]
Adaptive Mixtures of Local Experts,
R. Jacobs, M. I. Jordan, S. Nowlan, and G. E. Hinton, “Adaptive Mixtures of Local Experts,”Neural Computation, vol. 3, 1991
1991
-
[17]
On the representation collapse of sparse mixture of experts,
Z. Chiet al., “On the representation collapse of sparse mixture of experts,”Advances in Neural Information Processing Systems, vol. 35, pp. 34 600–34 613, 2022
2022
-
[18]
Computational design of mechanical characters,
S. Coros, B. Thomaszewski, G. Noris, S. Sueda, M. Forberg, R. Sum- ner, W. Matusik, and B. Bickel, “Computational design of mechanical characters,”ACM Transactions on Graphics (TOG), vol. 32, 2013
2013
-
[19]
Computational design of linkage-based characters,
B. Thomaszewski, S. Coros, D. Gauge, V . Megaro, E. Grinspun, and M. Gross, “Computational design of linkage-based characters,”ACM Transactions on Graphics (TOG), vol. 33, 2014
2014
-
[20]
Computational design of walking automata,
G. Bharaj, S. Coros, B. Thomaszewski, J. Tompkin, B. Bickel, and H. Pfister, “Computational design of walking automata,”the 14th ACM SIGGRAPH / Eurographics Symposium on Computer Animation, 2015
2015
-
[21]
Joint Opti- mization of Robot Design and Motion Parameters using the Implicit Function Theorem,
S. Ha, S. Coros, A. Alspach, J. Kim, and K. Yamane, “Joint Opti- mization of Robot Design and Motion Parameters using the Implicit Function Theorem,”Robotics: Science and Systems XIII, 2017
2017
-
[22]
Computational co-optimization of design parameters and mo- tion trajectories for robotic systems,
——, “Computational co-optimization of design parameters and mo- tion trajectories for robotic systems,”The International Journal of Robotics Research, vol. 37, 2018
2018
-
[23]
Multi- objective graph heuristic search for terrestrial robot design,
J. Xu, A. Spielberg, A. Zhao, D. Rus, and W. Matusik, “Multi- objective graph heuristic search for terrestrial robot design,” inIEEE International Conference on Robotics and Automation (ICRA), 2021
2021
-
[24]
Structural optimization of lightweight bipedal robot via serl,
Y . Cheng, C. Han, Y . Min, L. Ye, H. Liu, and H. Liu, “Structural optimization of lightweight bipedal robot via serl,” inIEEE/RSJ International Conference on Intelligent Robots and Systems, 2024
2024
-
[25]
DiffuseBot: Breeding Soft Robots With Physics-Augmented Generative Diffusion Models,
T.-H. Wang, J. Zheng, P. Ma, Y . Du, B. Kim, A. Spielberg, J. Tenen- baum, C. Gan, and D. Rus, “DiffuseBot: Breeding Soft Robots With Physics-Augmented Generative Diffusion Models,”Advances in Neural Information Processing Systems, 2023
2023
-
[26]
Accelerated co-design of robots through morphological pretraining,
L. Strgar and S. Kriegman, “Accelerated co-design of robots through morphological pretraining,” inInternational Conference on Learning Representations (ICLR), 2026
2026
-
[27]
One policy to control them all: Shared modular policies for agent-agnostic control,
W. Huang, I. Mordatch, and D. Pathak, “One policy to control them all: Shared modular policies for agent-agnostic control,” inInternational Conference on Machine Learning (ICML). PMLR, 2020
2020
-
[28]
Metamorph: Learning universal controllers with transformers,
A. Gupta, L. Hu, S. Savarese, J. Malik, and L. Fei-Fei, “Metamorph: Learning universal controllers with transformers,” inInternational Conference on Learning Representations (ICLR), 2022
2022
-
[29]
Preparing for the Unknown: Learning a Universal Policy with Online System Identification,
W. Yu, C. Liu, and G. Turk, “Preparing for the Unknown: Learning a Universal Policy with Online System Identification,”ArXiv, vol. abs/1702.02453, 2017
Pith/arXiv arXiv 2017
-
[30]
Learning Fast Adaptation With Meta Strategy Optimization,
W. Yu, J. Tan, Y . Bai, E. Coumans, and S. Ha, “Learning Fast Adaptation With Meta Strategy Optimization,”IEEE Robotics and Automation Letters, vol. 5, 2019
2019
-
[31]
One policy to run them all: an end-to-end learning approach to multi- embodiment locomotion,
N. Bohlinger, T. Flayols, F. Bordes, I. Laptev, C. Schmid, and J. Sivic, “One policy to run them all: an end-to-end learning approach to multi- embodiment locomotion,” inConference on Robot Learning, 2024
2024
-
[32]
S. Yang, Z. Fu, Z. Cao, G. Junde, P. Wensing, W. Zhang, and H. Chen, “Multi-loco: Unifying multi-embodiment legged locomo- tion via reinforcement learning augmented diffusion,”arXiv preprint arXiv:2506.11470, 2025
arXiv 2025
-
[33]
Giacometti arm with balloon body,
M. Takeichi, K. Suzumori, G. Endo, and H. Nabae, “Giacometti arm with balloon body,”IEEE Robotics and Automation Letters, 2017
2017
-
[34]
Control of a pneu- matically actuated, fully inflatable, fabric-based, humanoid robot,
C. M. Best, J. P. Wilson, and M. D. Killpack, “Control of a pneu- matically actuated, fully inflatable, fabric-based, humanoid robot,” in IEEE-RAS 15th International Conference on Humanoid Robots, 2015
2015
-
[35]
Recon: Reducing conflicting gradients from the root for multi-task learning,
G. Shi, Q. Li, W. Zhang, J. Chen, and X.-M. Wu, “Recon: Reducing conflicting gradients from the root for multi-task learning,”arXiv preprint arXiv:2302.11289, 2023
arXiv 2023
-
[36]
Least squares quantization in PCM,
S. Lloyd, “Least squares quantization in PCM,”IEEE Trans. Inf. Theory, vol. 28, 1982
1982
-
[37]
Isaac lab: A gpu-accelerated simulation framework for multi-modal robot learning,
M. Mittal,et al., “Isaac lab: A gpu-accelerated simulation framework for multi-modal robot learning,”arXiv, arXiv:2511.04831, 2025
Pith/arXiv arXiv 2025
-
[38]
Algorithms for hyper-parameter optimization,
J. Bergstra, R. Bardenet, Y . Bengio, and B. K ´egl, “Algorithms for hyper-parameter optimization,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 24, 2011
2011
-
[39]
Proximal policy optimization algorithms,
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,”arXiv:1707.06347, 2017
Pith/arXiv arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.