PaperFlow: Profiling, Recommending, and Adapting Across Daily Paper Streams
Pith reviewed 2026-06-27 20:26 UTC · model grok-4.3
The pith
PaperFlow organizes daily scientific paper recommendation into profiling, recommending, and adapting stages that handle interest shifts over time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
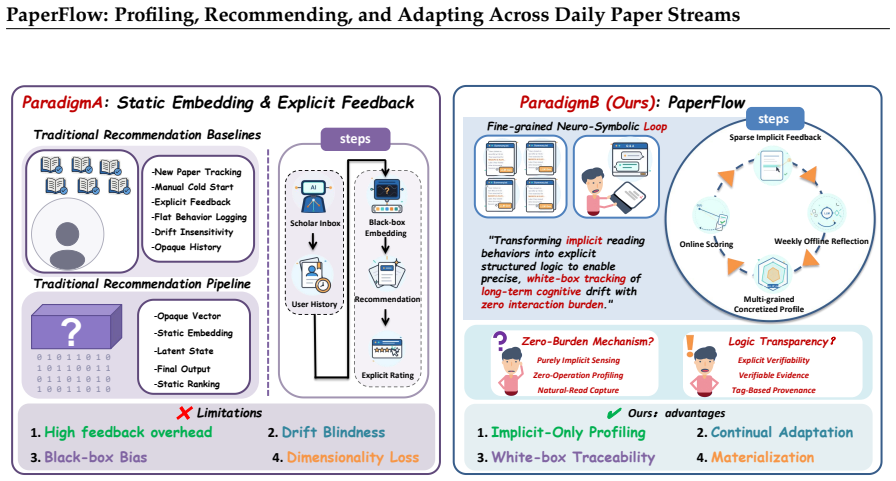
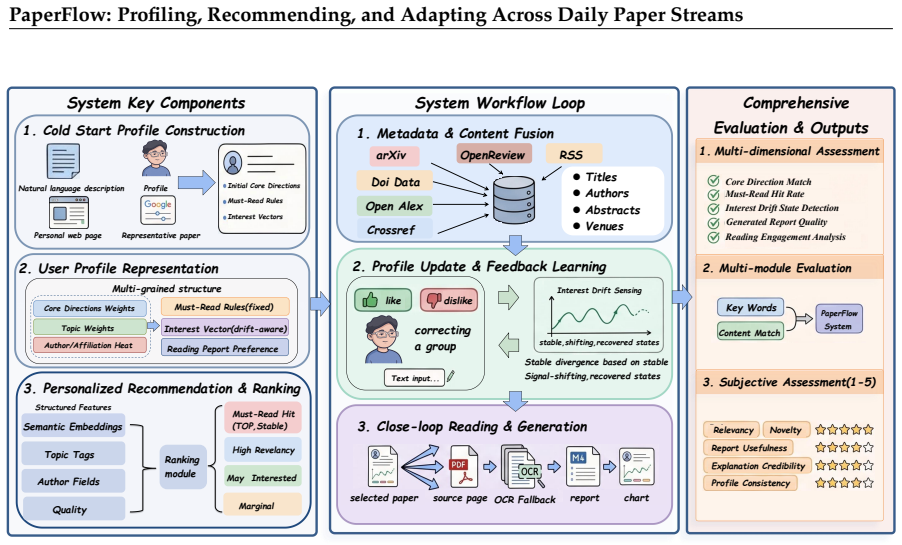
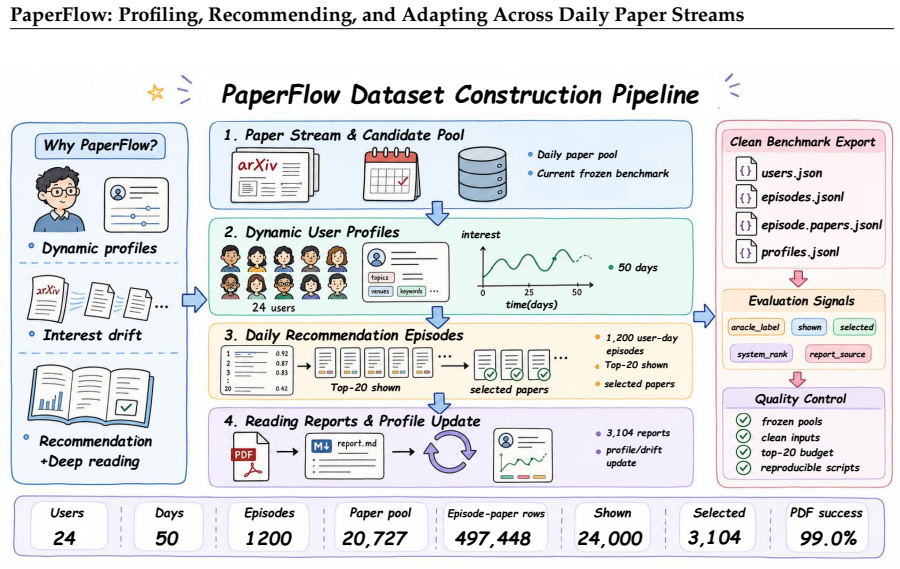
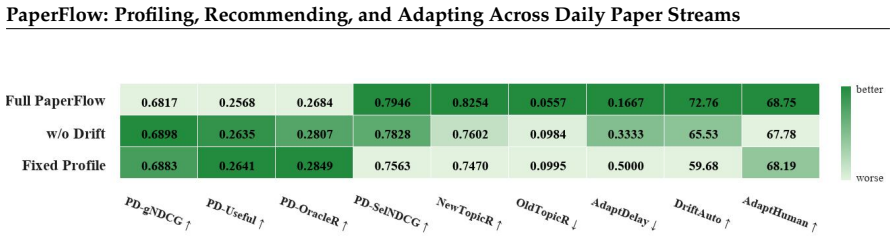
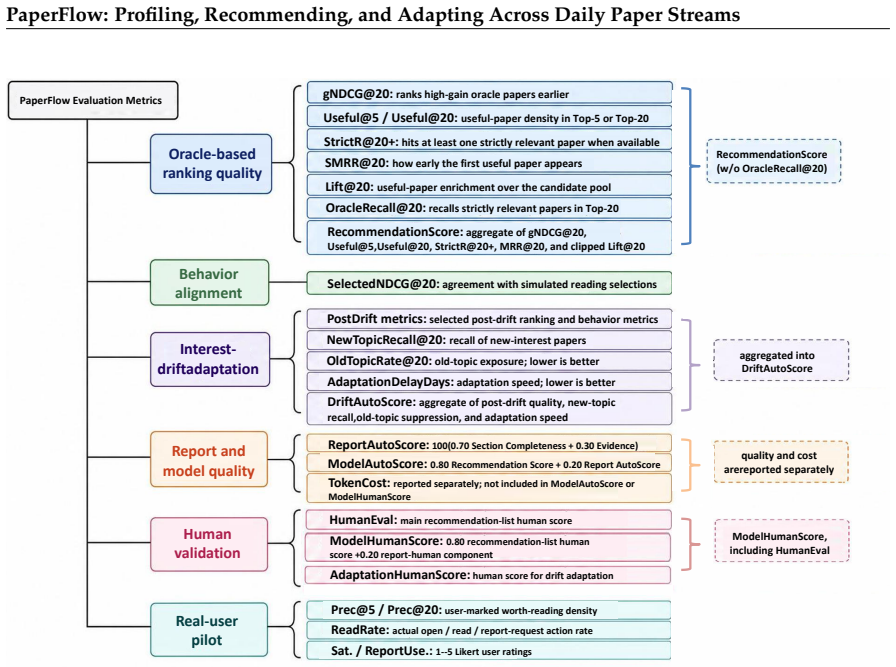
PaperFlow structures scientific paper recommendation as three coupled stages—Profiling from heterogeneous cold-start evidence into a structured scholarly profile, Recommending via multi-signal aggregation on date-specific streams under a fixed budget, and Adapting from semantically distinct feedback while modeling interest drift—and demonstrates stronger oracle-based ranking, behavioral alignment with simulated reading, and blind human-evaluation scores than five baselines on a fixed longitudinal user-day benchmark containing 1,200 episodes and 20,727 papers.
What carries the argument
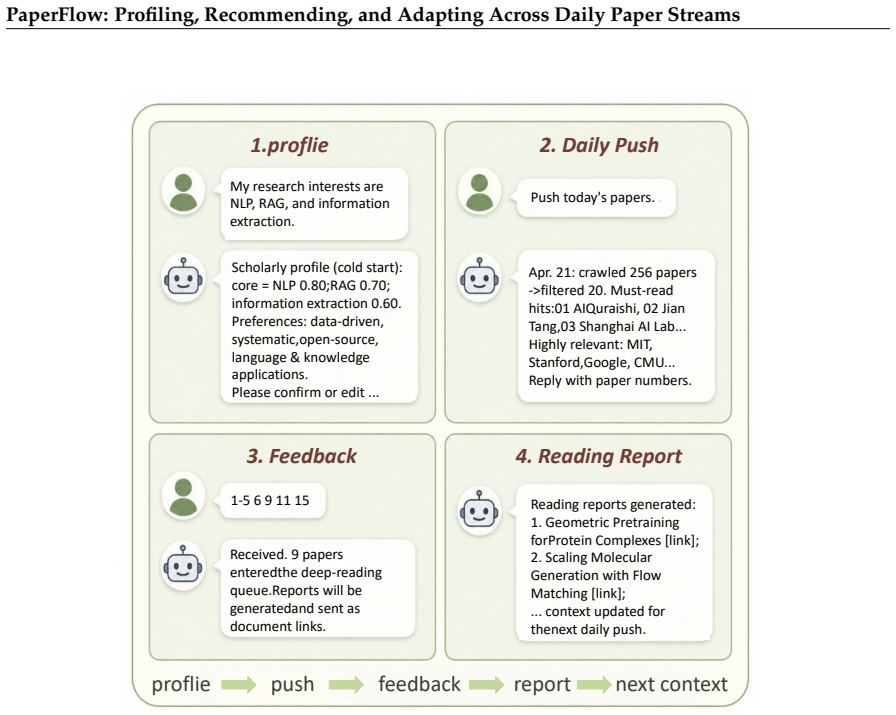
The PaperFlow framework's three coupled stages (Profiling, Recommending, Adapting) linked through a longitudinal user-day benchmark that fixes users, dates, candidate pools, visible inputs, and hidden relevance labels under a shared temporal boundary.
If this is right
- Daily paper streams can be ranked more effectively when user profiles are maintained and updated across days rather than recomputed from scratch.
- Interest drift becomes modellable when feedback is treated as semantically distinct signals instead of uniform relevance labels.
- Evaluation of recommendation systems gains consistency when benchmarks fix the temporal information boundary and separate visible inputs from hidden labels.
- Automatic metrics gain credibility when aligned with blind human expert judgments on the same episodes.
- Cold-start scenarios in scientific reading become addressable through structured, inspectable profiles built from heterogeneous evidence.
Where Pith is reading between the lines
- The same staged structure could apply to other evolving recommendation settings such as daily news or research tool suggestions where user state changes over short time scales.
- The fixed-benchmark design could serve as a template for testing adaptive systems in domains outside papers, provided the simulated users are replaced by real traces.
- If the simulated drift patterns diverge from actual researcher behavior, the adaptation stage would need recalibration using real longitudinal logs.
- Integration with live arXiv or PubMed feeds would allow direct measurement of whether the multi-signal ranking reduces information overload on working days.
Load-bearing premise
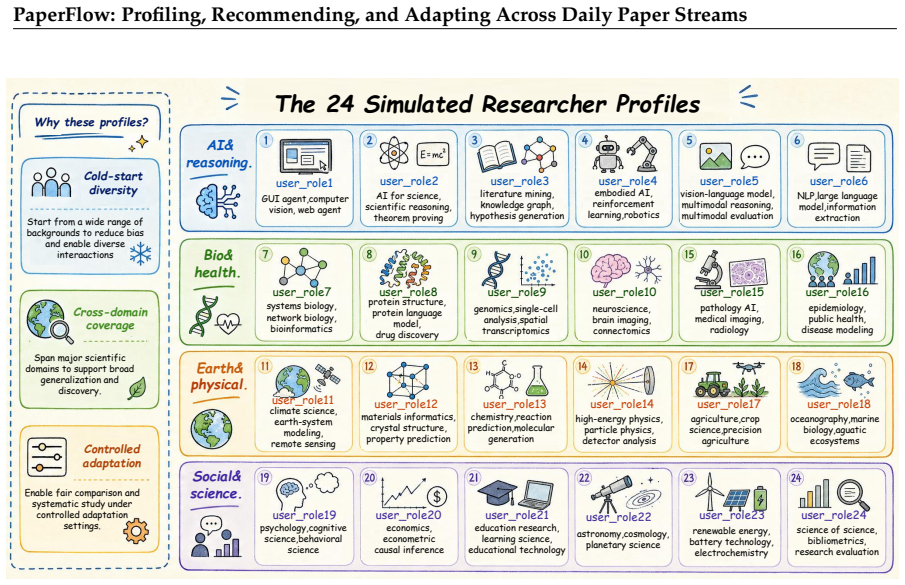
The 24 simulated research users, their feedback signals, and the hidden simulated relevance labels accurately reflect real scientific reading behavior, interest drift, and relevance judgments.
What would settle it
Deploy PaperFlow to real researchers for multiple consecutive days, record their actual reading selections and explicit feedback, then compare the system's rankings and adaptations against those observed choices and reported satisfaction.
Figures



read the original abstract
Scientific paper recommendation is typically evaluated as static ranking over a fixed candidate set, yet real scientific reading unfolds as a daily, longitudinal process in which interests shift and feedback accumulates. We introduce PaperFlow, a framework that organizes it into three coupled stages: Profiling, which constructs and maintains a structured, inspectable scholarly profile from heterogeneous cold-start evidence; Recommending, which ranks each date-specific paper stream through multi-signal aggregation under a fixed display budget; and Adapting, which updates user state from semantically distinct feedback signals and models interest drift across days. We further define a longitudinal user-day benchmark that fixes users, dates, candidate pools, visible inputs, and hidden simulated relevance labels under a shared temporal information boundary. The benchmark contains 24 simulated research users, 50 daily paper streams, 1,200 user-day episodes, 20,727 unique papers, and 497,448 episode-paper records. We additionally specify a blind human-evaluation protocol to validate alignment between automatic metrics and expert judgments. Experiments against five scientific recommendation baselines show that PaperFlow achieves the strongest oracle-based ranking, the highest behavioral alignment with simulated reading selections, and the best blind human-evaluation score.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents PaperFlow, a framework for recommending scientific papers in a daily longitudinal setting. It consists of three stages: Profiling to build inspectable scholarly profiles from cold-start evidence, Recommending to rank date-specific paper streams under a display budget using multi-signal aggregation, and Adapting to update user state from feedback and model interest drift. The authors introduce a longitudinal user-day benchmark with 24 simulated users, 50 daily streams, 1,200 episodes, and 497,448 records, and report that PaperFlow outperforms five baselines in oracle ranking, behavioral alignment, and blind human evaluation.
Significance. This work has potential significance in moving paper recommendation evaluation from static to dynamic, longitudinal settings that better reflect real scientific reading. The provision of a fixed, reproducible benchmark with explicit temporal boundaries and the use of blind human evaluation are positive aspects that could facilitate future comparisons. Credit is due for the detailed specification of the benchmark parameters (24 users, 50 streams, shared information boundary) and the multi-stage framework. However, the significance is tempered by the exclusive reliance on simulated data for all quantitative claims.
major comments (1)
- [Longitudinal user-day benchmark definition and evaluation] The performance claims (strongest oracle-based ranking, highest behavioral alignment with simulated reading selections, best blind human-evaluation score) are obtained exclusively on the longitudinal user-day benchmark constructed from 24 simulated research users, hidden simulated relevance labels, and an interest-drift model (as described in the benchmark definition and evaluation sections). No validation of the simulation procedure against real scholarly reading patterns, interest drift, or external relevance judgments is provided, which is load-bearing for the central empirical contribution and the reported superiority over the five baselines.
minor comments (1)
- [Abstract] The abstract could more explicitly state the limitations of the simulated benchmark to set appropriate expectations.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for acknowledging the reproducibility of the benchmark and the value of longitudinal evaluation. We address the single major comment below.
read point-by-point responses
-
Referee: [Longitudinal user-day benchmark definition and evaluation] The performance claims (strongest oracle-based ranking, highest behavioral alignment with simulated reading selections, best blind human-evaluation score) are obtained exclusively on the longitudinal user-day benchmark constructed from 24 simulated research users, hidden simulated relevance labels, and an interest-drift model (as described in the benchmark definition and evaluation sections). No validation of the simulation procedure against real scholarly reading patterns, interest drift, or external relevance judgments is provided, which is load-bearing for the central empirical contribution and the reported superiority over the five baselines.
Authors: We agree the simulation is central to the quantitative results. The benchmark was deliberately constructed as a fully specified, reproducible simulation to enable controlled longitudinal experiments (interest drift, accumulating feedback, date-specific streams) that cannot be ethically or practically obtained at this scale with real users. All five baselines are evaluated under identical conditions, so relative improvements remain valid within the benchmark. The blind human evaluation supplies an external, non-simulated check: domain experts preferred PaperFlow outputs without knowledge of the underlying labels or drift model. We will add a dedicated Limitations subsection that explicitly discusses the simulation assumptions, their potential divergence from real reading patterns, and the absence of direct validation against external user logs. No new experiments are required for this clarification. revision: partial
Circularity Check
No circularity; empirical claims rest on external baseline comparisons within a self-defined but non-reductive benchmark
full rationale
The paper introduces PaperFlow as a three-stage framework and defines its own longitudinal user-day benchmark with 24 simulated users and hidden relevance labels. It then reports performance against five independent baselines plus a blind human-evaluation protocol. No derivation, equation, or result reduces to its own inputs by construction; the benchmark is an evaluation substrate rather than a self-referential loop, and no self-citations or fitted parameters are invoked as load-bearing premises. This is the standard case of a proposal evaluated on a custom testbed.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Akari Asai, Jacqueline He, Rulin Shao, Weijia Shi, Amanpreet Singh, Joseph Chee Chang, Kyle Lo, Luca Soldaini, Sergey Feldman, Mike D’Arcy, David Wadden, Matt Latzke, Jenna Sparks, Jena D. Hwang, Varsha Kishore, Minyang Tian, Pan Ji, Shengyan Liu, Hao Tong, Bohao Wu, Yanyu Xiong, Luke Zettlemoyer, Graham Neubig, Daniel S. Weld, Doug Downey, Wen-Tau Yih, P...
-
[2]
Agentic Feedback Loop Modeling Improves Recommendation and User Simulation
Shihao Cai, Jizhi Zhang, Keqin Bao, Chongming Gao, Qifan Wang, Fuli Feng, and Xiangnan He. Agentic Feedback Loop Modeling Improves Recommendation and User Simulation. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 2235–2244,
-
[3]
URLhttps://doi.org/10.1145/3726302.3729893
doi: 10.1145/3726302.3729893. URLhttps://doi.org/10.1145/3726302.3729893
-
[4]
A Multi-Agent Conversational Recommender System.arXiv preprint arXiv:2402.01135, 2024
Jiabao Fang, Shen Gao, Pengjie Ren, Xiuying Chen, Suzan Verberne, and Zhaochun Ren. A Multi-Agent Conversational Recommender System.arXiv preprint arXiv:2402.01135, 2024. URL https://arxiv.org/abs/ 2402.01135
arXiv 2024
-
[5]
Scholar Inbox: Personalized Paper Recommendations for Scientists
Markus Flicke, Glenn Angrabeit, Madhav Iyengar, Vitalii Protsenko, Illia Shakun, Jovan Cicvaric, Bora Kargi, 11 PaperFlow: Profiling, Recommending, and Adapting Across Daily Paper Streams Haoyu He, Lukas Schuler, Lewin Scholz, Kavyanjali Agnihotri, Yong Cao, and Andreas Geiger. Scholar Inbox: Personalized Paper Recommendations for Scientists. InACL 2025 S...
2025
-
[6]
Raymond Fok, Hita Kambhamettu, Luca Soldaini, Jonathan Bragg, Kyle Lo, Andrew Head, Marti A. Hearst, and Daniel S. Weld. Scim: Intelligent Skimming Support for Scientific Papers. InIUI 2023, 2023. doi: 10.1145/3581641.3584034. URLhttps://doi.org/10.1145/3581641.3584034
-
[7]
Yunfan Gao, Tao Sheng, Youlin Xiang, Yun Xiong, Haofen Wang, and Jiawei Zhang. Chat-REC: Towards Interactive and Explainable LLMs-Augmented Recommender System.arXiv preprint arXiv:2303.14524, 2023. URLhttps://arxiv.org/abs/2303.14524
arXiv 2023
-
[8]
PaSa: An LLM Agent for Comprehensive Academic Paper Search
Yichen He, Guanhua Huang, Peiyuan Feng, Yuan Lin, Yuchen Zhang, Hang Li, and Weinan E. PaSa: An LLM Agent for Comprehensive Academic Paper Search. InACL 2025 Long Papers, 2025. URL https: //aclanthology.org/2025.acl-long.572/
2025
-
[9]
Jiani Huang, Shijie Wang, Liang bo Ning, Wenqi Fan, Shuaiqiang Wang, Dawei Yin, and Qing Li. Towards Next-Generation Recommender Systems: A Benchmark for Personalized Recommendation Assistant with LLMs (RecBench+). InWSDM 2026, 2026. doi: 10.1145/3773966.3777954. URL https://doi.org/10.1145/ 3773966.3777954
-
[10]
Xu Huang, Jianxun Lian, Yuxuan Lei, Jing Yao, Defu Lian, and Xing Xie. Recommender AI Agent: Integrating Large Language Models for Interactive Recommendations.ACM Transactions on Recommender Systems, 2025. doi: 10.1145/3731446. URLhttps://doi.org/10.1145/3731446
-
[11]
Kang, Sherry Tongshuang Wu, Joseph Chee Chang, and Aniket Kittur
Hyeonsu B. Kang, Sherry Tongshuang Wu, Joseph Chee Chang, and Aniket Kittur. Synergi: A Mixed- Initiative System for Scholarly Synthesis and Sensemaking. InUIST 2023, 2023. doi: 10.1145/3586183.3606759. URLhttps://doi.org/10.1145/3586183.3606759
-
[12]
Kang, Matt Latzke, Juho Kim, Jonathan Bragg, Joseph Chee Chang, and Pao Siangliulue
Yoonjoo Lee, Hyeonsu B. Kang, Matt Latzke, Juho Kim, Jonathan Bragg, Joseph Chee Chang, and Pao Siangliulue. PaperWeaver: Enriching Topical Paper Alerts by Contextualizing Recommended Papers with User-collected Papers. InCHI 2024, 2024. doi: 10.1145/3613904.3642196. URL https://doi.org/10.1145/ 3613904.3642196
-
[13]
Incorporating External Knowledge and Goal Guidance for LLM-based Conversational Recommender Systems
Chuang Li, Yang Deng, Hengchang Hu, Min-Yen Kan, and Haizhou Li. Incorporating External Knowledge and Goal Guidance for LLM-based Conversational Recommender Systems. InFindings of NAACL 2025, 2025. URLhttps://aclanthology.org/2025.findings-naacl.17/
2025
-
[14]
Towards Personalized Deep Research: Benchmarks and Evaluations (PDR-Bench)
Yuan Liang, Jiaxian Li, Yuqing Wang, Piaohong Wang, Motong Tian, Pai Liu, Shuofei Qiao, Runnan Fang, He Zhu, Ge Zhang, Minghao Liu, Yuchen Eleanor Jiang, Ningyu Zhang, and Wangchunshu Zhou. Towards Personalized Deep Research: Benchmarks and Evaluations (PDR-Bench). InICLR 2026 Poster, 2026. URL https://openreview.net/forum?id=51LIRzF53v
2026
-
[15]
Guanyu Lin, Tao Feng, Pengrui Han, Ge Liu, and Jiaxuan You. Arxiv Copilot: A Self-Evolving and Efficient LLM System for Personalized Academic Assistance. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 122–130, 2024. doi: 10.18653/v1/2024. emnlp-demo.13. URLhttps://aclanthology.org/202...
-
[16]
Towards Interest Drift-driven User Representation Learning in Sequential Recommendation (IDURL)
Xiaolin Lin, Weike Pan, and Zhong Ming. Towards Interest Drift-driven User Representation Learning in Sequential Recommendation (IDURL). InSIGIR 2025, 2025. doi: 10.1145/3726302.3730099. URL https: //doi.org/10.1145/3726302.3730099
-
[17]
Guangyi Liu, Quanming Yao, Yongqi Zhang, and Lei Chen. Knowledge-Enhanced Recommendation with User-Centric Subgraph Network.arXiv preprint arXiv:2403.14377, 2024. URLhttps://arxiv.org/abs/2403. 14377
arXiv 2024
-
[19]
URLhttps://arxiv.org/abs/2503.01189
-
[20]
Kyle Lo, Joseph Chee Chang, Andrew Head, Jonathan Bragg, Amy X. Zhang, Cassidy Trier, Chloe Anastasi- ades, Tal August, Russell Authur, Danielle Bragg, Erin Bransom, Isabel Cachola, Stefan Candra, Yoganand Chandrasekhar, Yen-Sung Chen, Evie Yu-Yen Cheng, Yvonne Chou, Doug Downey, Rob Evans, Raymond 12 PaperFlow: Profiling, Recommending, and Adapting Acros...
-
[21]
Programming with data: Test-driven data engineering for self-improving llms from raw corpora
Chenkai Pan, Xinglong Xu, Yuhang Xu, Yujun Wu, Siyuan Li, Jintao Chen, Conghui He, Jingxuan Wei, and Cheng Tan. Programming with data: Test-driven data engineering for self-improving llms from raw corpora. arXiv preprint arXiv:2604.24819, 2026
Pith/arXiv arXiv 2026
-
[22]
Napol Rachatasumrit, Jonathan Bragg, Amy X. Zhang, and Daniel S Weld. CiteRead: Integrating Localized Citation Contexts into Scientific Paper Reading. InIUI 2022, 2022. doi: 10.1145/3490099.3511162. URL https://doi.org/10.1145/3490099.3511162
-
[23]
Rahmani, Xi Wang, Xiao Fu, and Aldo Lipani
Jerome Ramos, Hossen A. Rahmani, Xi Wang, Xiao Fu, and Aldo Lipani. Transparent and Scrutable Recommendations Using Natural Language User Profiles. InACL 2024 Long Papers, 2024. URL https: //aclanthology.org/2024.acl-long.753/
2024
-
[24]
AgentRecBench: Benchmarking LLM Agent-based Personalized Recommender Systems
Yu Shang, Peijie Liu, Yuwei Yan, Zijing Wu, Leheng Sheng, Yuanqing Yu, Chumeng Jiang, An Zhang, Fengli Xu, Yu Wang, Min Zhang, and Yong Li. AgentRecBench: Benchmarking LLM Agent-based Personalized Recommender Systems. InNeurIPS 2025 Datasets and Benchmarks Track Spotlight, 2025. URL https:// openreview.net/forum?id=fm77rDf9JS
2025
-
[25]
Large Language Models are Learnable Planners for Long-Term Recommendation
Wentao Shi, Xiangnan He, Yang Zhang, Chongming Gao, Xinyue Li, Jizhi Zhang, Qifan Wang, and Fuli Feng. Large Language Models are Learnable Planners for Long-Term Recommendation. InSIGIR 2024, 2024. doi: 10.1145/3626772.3657683. URLhttps://doi.org/10.1145/3626772.3657683
-
[26]
Yubo Shu, Haonan Zhang, Hansu Gu, Peng Zhang, Tun Lu, Dongsheng Li, and Ning Gu. RAH! RecSys– Assistant–Human: A Human-Centered Recommendation Framework With LLM Agents.IEEE Transactions on Computational Social Systems, 11(5):6759–6770, 2024. doi: 10.1109/TCSS.2024.3404039. URL https://doi. org/10.1109/TCSS.2024.3404039
-
[27]
Michael D. Skarlinski, Sam Cox, Jon M. Laurent, James D. Braza, Michaela Hinks, Michael J. Hammerling, Manvitha Ponnapati, Samuel G. Rodriques, and Andrew D. White. Language agents achieve superhuman synthesis of scientific knowledge.arXiv preprint arXiv:2409.13740, 2024. URL https://arxiv.org/abs/2409. 13740
arXiv 2024
-
[28]
Ruotong Wang, Xinyi Zhou, Lin Qiu, Joseph Chee Chang, Jonathan Bragg, and Amy X. Zhang. PaperPing: A Socially-aware AI Agent that Recommends Academic Papers to Research Group Chats with Contextualized Explanations. InCSCW Companion 2025, 2025. doi: 10.1145/3715070.3757230. URL https://doi.org/10. 1145/3715070.3757230
-
[29]
Ruotong Wang, Xinyi Zhou, Lin Qiu, Joseph Chee Chang, Jonathan Bragg, and Amy X. Zhang. Social- RAG: Retrieving from Group Interactions to Socially Ground AI Generation. InCHI 2025, 2025. doi: 10.1145/3706598.3713749. URLhttps://doi.org/10.1145/3706598.3713749
-
[30]
Shenghua Wang and Zhen Yin. Discourse-Aware Scientific Paper Recommendation via QA-Style Sum- marization and Multi-Level Contrastive Learning.arXiv preprint arXiv:2511.03330, 2025. URL https: //arxiv.org/abs/2511.03330
arXiv 2025
-
[31]
Xintao Wang, Jiangjie Chen, Nianqi Li, Lida Chen, Xinfeng Yuan, Wei Shi, Xuyang Ge, Rui Xu, and Yanghua Xiao. SurveyAgent: A Conversational System for Personalized and Efficient Research Survey.arXiv preprint arXiv:2404.06364, 2024. URLhttps://arxiv.org/abs/2404.06364
arXiv 2024
-
[32]
RecMind: Large Language Model Powered Agent For Recommendation
Yancheng Wang, Ziyan Jiang, Zheng Chen, Fan Yang, Yingxue Zhou, Eunah Cho, Xing Fan, Xiaojiang Huang, Yanbin Lu, and Yingzhen Yang. RecMind: Large Language Model Powered Agent For Recommendation. In Findings of NAACL 2024, 2024. URLhttps://aclanthology.org/2024.findings-naacl.271/. 13 PaperFlow: Profiling, Recommending, and Adapting Across Daily Paper Streams
2024
-
[33]
Jingxuan Wei, Xi Bai, Shan Liu, Caijun Jia, Zheng Sun, Xinglong Xu, Siyuan Li, Linzhuang Sun, Bihui Yu, Conghui He, et al. Pager: Bridging the semantic-execution gap in point-precise geometric gui control.arXiv preprint arXiv:2605.15963, 2026
Pith/arXiv arXiv 2026
-
[34]
Jingxuan Wei, Siyuan Li, Yuhang Xu, Zheng Sun, Junjie Jiang, Hexuan Jin, Caijun Jia, Honghao He, Xinglong Xu, Chang Yu, et al. The trinity of consistency as a defining principle for general world models.arXiv preprint arXiv:2602.23152, 2026
arXiv 2026
-
[35]
Research Paper Recommender System by Considering Users’ Information Seeking Behaviors
Zhelin Xu, Shuhei Yamamoto, and Hideo Joho. Research Paper Recommender System by Considering Users’ Information Seeking Behaviors. InJSAI 2025, 2025. URL https://www.jstage.jst.go.jp/article/pjsai/ JSAI2025/0/JSAI2025_1D4OS24b02/_article/-char/en
2025
-
[36]
Embracing Plasticity: Balancing Stability and Plasticity in Continual Recommender Systems
Hyunsik Yoo, SeongKu Kang, Ruizhong Qiu, Charlie Xu, Fei Wang, and Hanghang Tong. Embracing Plasticity: Balancing Stability and Plasticity in Continual Recommender Systems. InSIGIR 2025, 2025. doi: 10.1145/3726302.3729964. URLhttps://doi.org/10.1145/3726302.3729964
-
[37]
Bihui Yu, Xinglong Xu, Junjie Jiang, Jiabei Cheng, Caijun Jia, Siyuan Li, Conghui He, Jingxuan Wei, and Cheng Tan. Paperfit: Vision-in-the-loop typesetting optimization for scientific documents.arXiv preprint arXiv:2605.10341, 2026
Pith/arXiv arXiv 2026
-
[38]
AgentCF: Collaborative Learning with Autonomous Language Agents for Recommender Systems
Junjie Zhang, Yupeng Hou, Ruobing Xie, Wenqi Sun, Julian McAuley, Wayne Xin Zhao, Leyu Lin, and Ji-Rong Wen. AgentCF: Collaborative Learning with Autonomous Language Agents for Recommender Systems. InThe Web Conference 2024 / WWW 2024, 2024. doi: 10.1145/3589334.3645537. URL https: //doi.org/10.1145/3589334.3645537
-
[39]
Let Me Do It For You: Towards LLM Empowered Recommendation via Tool Learning
Yuyue Zhao, Jiancan Wu, Xiang Wang, Wei Tang, Dingxian Wang, and Maarten de Rijke. Let Me Do It For You: Towards LLM Empowered Recommendation via Tool Learning. InSIGIR 2024, 2024. doi: 10.1145/3626772.3657828. URLhttps://doi.org/10.1145/3626772.3657828. 14 PaperFlow: Profiling, Recommending, and Adapting Across Daily Paper Streams Appendix Appendix Table...
-
[40]
Retrieve the candidate papers for the corresponding date from the fixed paper pool
-
[41]
Compute the base relevance score from the user profile and paper content
-
[42]
Check must-read author, institution, and keyword matches
-
[43]
Apply interest-drift weighting to new interest topics and downweight suppressed old topics
-
[44]
Apply recent reading-signal weights to short-term topics that repeatedly appear and are selected by the user
-
[45]
Generate the Top-20 recommendation list
-
[46]
Simulate user selections based on oracle labels, system rank, system label, and drift-topic matches
-
[47]
always show papers by this author,
Generate reading reports for selected papers and record token usage, episode metadata, and the drift timeline. This pipeline connects recommendation, selection, profile update, and reading assistance into a closed loop. The recommendation stage determines what the user sees. The selection stage simulates what the user actually clicks or reads. The profile...
-
[48]
Do not invent methods, experiments, or conclusions that do not appear in the paper information
-
[49]
Do not exaggerate it as directly solving the user's problem
If the paper is only topically related, explicitly say it is topically related. Do not exaggerate it as directly solving the user's problem
-
[50]
If a must-read author, institution, or keyword is matched, state the reason
-
[51]
If the paper is related to an interest-drift direction, state the corresponding new interest topic
-
[52]
user_profile
Output only one or two sentences. User: { "user_profile": { "core_directions": {...}, "must_read": {...}, "drift_state": "...", "reading_signal_topics": [...] }, "paper": { "title": "...", "abstract": "...", "authors": [...], "institutions": [...], "keywords": [...] }, "signals": { "system_label": "...", "score": 0.0, "matched_topics": [...], "matched_mus...
-
[53]
ProfileMatch: whether the list matches the user's profile and current research interests
-
[54]
RankingQuality: whether stronger or more useful papers appear earlier in the Top-20 list
-
[55]
DecisionUsefulness: whether the list helps the user decide what to read, skim, or skip
-
[56]
DiversityFocusBalance: whether the list balances focused relevance with useful breadth. Return JSON: { "ProfileMatch": 1, "RankingQuality": 1, "DecisionUsefulness": 1, "DiversityFocusBalance": 1, "comments": "brief rationale" } Model-comparison report prompt. Model-Comparison Report Prompt You will see a researcher profile, a recommended paper, the paper ...
Pith/arXiv arXiv 2026
-
[57]
The candidate paper pool remains fixed
-
[58]
User profiles remain fixed
-
[59]
The Top-20 display budget remains fixed
-
[60]
The embedding model remains fixed
-
[61]
Evaluation metrics remain fixed
-
[62]
42 PaperFlow: Profiling, Recommending, and Adapting Across Daily Paper Streams
Each model writes to a separate output directory. 42 PaperFlow: Profiling, Recommending, and Adapting Across Daily Paper Streams
-
[63]
8.TokenCost is reported only as an efficiency metric and is not included in ModelAutoScore or ModelHumanScore
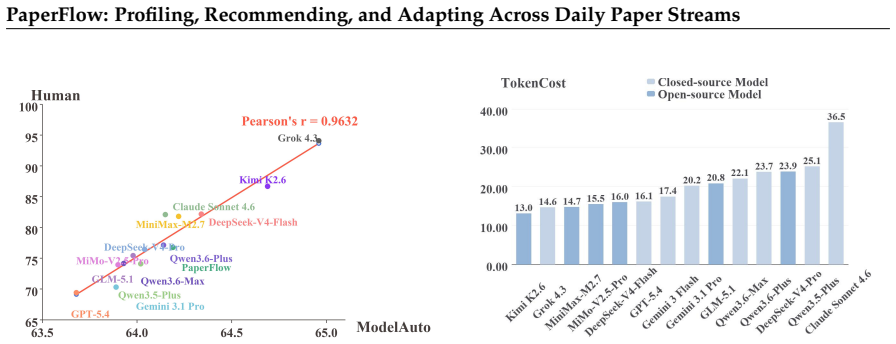
Token usage is recorded by date. 8.TokenCost is reported only as an efficiency metric and is not included in ModelAutoScore or ModelHumanScore. If a model encounters JSON parsing errors, API connection errors, or token-usage accounting anoma- lies, these should be recorded separately and should not be directly compared with models that completed full runs...
-
[64]
Several Top-5 papers are both must_read and relevant
-
[65]
The user selects five papers from the list
-
[66]
The ranking remains strong beyond static oracle labels. Top-20 Overview: Density of Relevant/Must-read Papers Rank Relevant/Must_read Rank Relevant/Must_read relevant/must_read relevant(not must_read) not relevant User Long-term Interests Mechanism: The success comes from aligned signals. The user's long-termdirections are NLP, LLMs, and information extra...
-
[67]
The user initially concentrates on GUI agents and web automation
-
[68]
The observing state accumulates repeated new-topic hits
-
[69]
The signal eventually crosses the drift threshold. New-Topic Hits over Time New-topic hits (per observation) Drift threshold threshold(30) Time (observations) Update Mechanism: After the threshold is crossed, the system locks multimodal reasoning as the anchor topic. It then increases the ranking weight of papers related to multimodal interaction and reas...
-
[70]
Some papers may be only weak_relevant under the oracle
-
[71]
The user may still click or read them because similar topicswere selected recently
-
[72]
Interpretation: The case illustrates that behavioral consistency is not identical to static relevance
If the system ranks these papers early, SelectedNDCG@20 increases. Interpretation: The case illustrates that behavioral consistency is not identical to static relevance. Selected papers are not always those with the highest oracle gain, but they may better match the user's recent reading trajectory. Longitudinal scientific recommendation should therefore ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.