PathoSage: Towards Multi-Source Evidence Adjudication in Pathology via Experience-Aware Agentic Workflow
Pith reviewed 2026-06-30 18:37 UTC · model grok-4.3
The pith
PathoSage separates evidence retrieval, collection, and adjudication into distinct stages to reduce hallucinations and conflicts in pathology multimodal reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
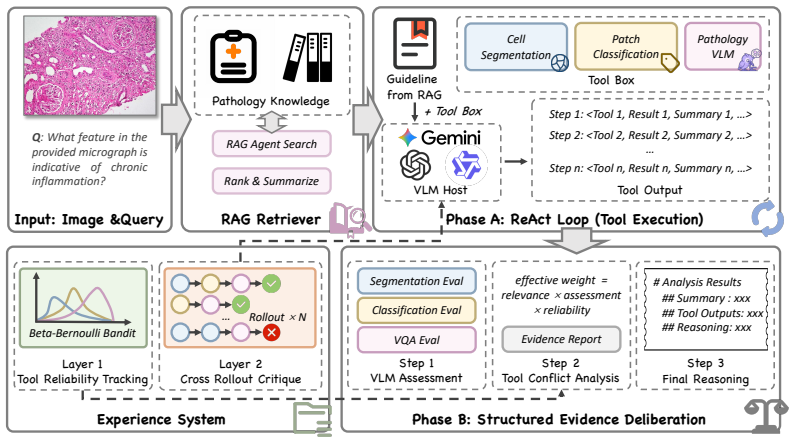
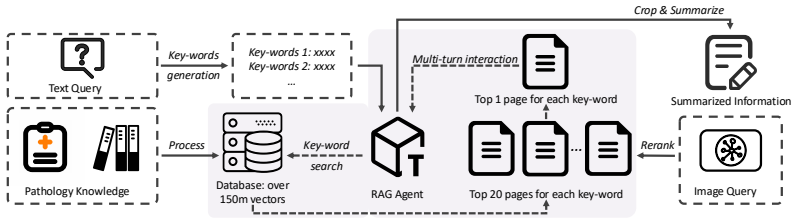
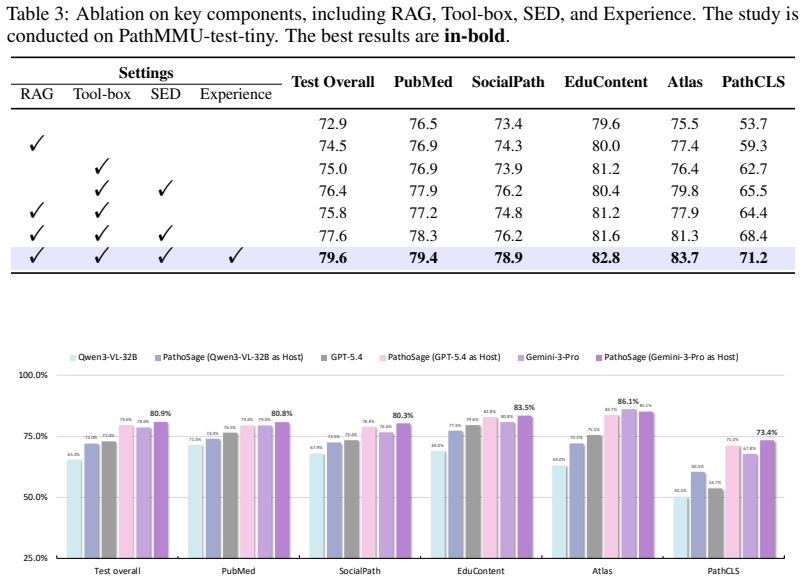
PathoSage is a three-stage framework that explicitly separates knowledge retrieval, evidence collection, and evidence adjudication for patch-level pathology multimodal reasoning. Its core component, Structured Evidence Deliberation, independently evaluates heterogeneous evidence from tools, performs conflict analysis, and generates the final judgment in a fresh context to reduce anchoring bias. The system adds a training-free Beta-Bernoulli experience model with continuous credit assignment that estimates long-term tool reliability and supplies similarity-weighted priors for future tool selection. Experiments demonstrate that this structure mitigates VQA hallucinations and classifier disagre
What carries the argument
Structured Evidence Deliberation, which evaluates tool outputs independently, analyzes conflicts, and issues the judgment in a fresh context, together with the Beta-Bernoulli experience system that models tool reliability via continuous credit assignment.
If this is right
- Explicit conflict analysis between heterogeneous tool outputs reduces disagreement among classifiers.
- Judgment in a fresh context limits propagation of early misleading evidence into the final answer.
- The Beta-Bernoulli model supplies reliability-weighted priors that improve tool selection on later cases without retraining.
- The overall workflow outperforms both end-to-end pathology MLLMs and merged-context agent baselines on patch-level VQA tasks.
Where Pith is reading between the lines
- The separation of adjudication from collection could be tested on other multimodal domains that face conflicting tool outputs, such as radiology report generation.
- Continuous credit assignment might allow the agent to adapt tool preferences across an entire hospital dataset without additional labeled validation sets.
- If the experience system generalizes, similar reliability tracking could be added to non-pathology agent workflows that already use multiple vision-language tools.
Load-bearing premise
That performing conflict analysis and final judgment in a fresh context sufficiently reduces anchoring bias and that the Beta-Bernoulli experience system supplies accurate long-term tool reliability estimates without task-specific tuning or validation data.
What would settle it
A controlled experiment in which the same tool outputs are fed once to a shared-context agent and once to PathoSage's fresh-context adjudication, with no difference in hallucination rate or final accuracy, would falsify the claimed benefit of the separated adjudication stage.
Figures

read the original abstract
Recent advances in Multimodal Large Language Models (MLLMs) and agent workflows have shown strong promise for computational pathology, yet reliable patch-level reasoning remains challenging. End-to-end pathology MLLMs often hallucinate morphological features, while recent agentic systems usually merge tool outputs and retrieved knowledge into a shared context, making decisions vulnerable to conflicting evidence and context contamination. We propose PathoSage, a three-stage framework that explicitly separates knowledge retrieval, evidence collection, and evidence adjudication for patch-level pathology multimodal reasoning. Its core component, Structured Evidence Deliberation, independently evaluates heterogeneous evidence from tools, performs conflict analysis, and generates the final judgment in a fresh context to reduce anchoring bias. We further introduce a training-free Beta-Bernoulli experience system with continuous credit assignment to model long-term tool reliability and construct similarity-weighted priors for future tool use. Experiments show that PathoSage effectively mitigates VQA hallucinations and classifier disagreement, outperforming strong pathology MLLM and agentic baselines. Our results highlight explicit evidence adjudication and reliability-aware tool modeling as key ingredients for robust pathology agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PathoSage, a three-stage agentic framework for patch-level pathology multimodal reasoning that separates knowledge retrieval, evidence collection, and Structured Evidence Deliberation (which performs independent evidence evaluation, conflict analysis, and final judgment in a fresh context). It adds a training-free Beta-Bernoulli experience system with continuous credit assignment to model long-term tool reliability and build similarity-weighted priors. The central claim is that this mitigates VQA hallucinations and classifier disagreement, outperforming pathology MLLMs and agentic baselines.
Significance. If the empirical claims hold after proper validation, the explicit adjudication stage and the experience system could offer a practical, training-free route to more robust multimodal agents in domains with conflicting evidence sources, such as computational pathology.
major comments (3)
- Abstract: the assertion that PathoSage 'effectively mitigates VQA hallucinations and classifier disagreement, outperforming strong pathology MLLM and agentic baselines' supplies no metrics, baselines, datasets, statistical tests, or controls, so the central empirical claim cannot be evaluated from the manuscript.
- Abstract (Structured Evidence Deliberation description): the premise that moving conflict analysis and final judgment to a fresh context 'reduce[s] anchoring bias' is stated without any quantitative measure, ablation, or bias metric, leaving the load-bearing mechanism for bias reduction unsupported.
- Abstract (Beta-Bernoulli experience system): the claim that the training-free Beta-Bernoulli model with continuous credit assignment yields accurate long-term tool reliability estimates is presented without validation against ground-truth tool accuracy, held-out data, or analysis of how success/failure signals are obtained, raising a direct threat to the reliability-aware component credited for outperformance.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the need for the abstract to better reflect the empirical grounding in the full manuscript. We address each point below and indicate where revisions will be made.
read point-by-point responses
-
Referee: Abstract: the assertion that PathoSage 'effectively mitigates VQA hallucinations and classifier disagreement, outperforming strong pathology MLLM and agentic baselines' supplies no metrics, baselines, datasets, statistical tests, or controls, so the central empirical claim cannot be evaluated from the manuscript.
Authors: The abstract provides a high-level summary of the results. The full manuscript details the evaluation in the Experiments section, including specific datasets (e.g., patch-level VQA benchmarks), baselines (pathology MLLMs and agentic systems), metrics (accuracy, hallucination rates), and statistical comparisons. We will revise the abstract to incorporate a concise reference to the key evaluation setup and main quantitative gains. revision: yes
-
Referee: Abstract (Structured Evidence Deliberation description): the premise that moving conflict analysis and final judgment to a fresh context 'reduce[s] anchoring bias' is stated without any quantitative measure, ablation, or bias metric, leaving the load-bearing mechanism for bias reduction unsupported.
Authors: The fresh-context design is motivated by reducing context contamination and anchoring; the manuscript supports this via ablations isolating the Structured Evidence Deliberation stage and showing performance differences. While no dedicated bias metric is introduced, the empirical gains from the stage are quantified. We will revise the abstract to frame the bias reduction as a design rationale validated by the ablations reported in the main text. revision: partial
-
Referee: Abstract (Beta-Bernoulli experience system): the claim that the training-free Beta-Bernoulli model with continuous credit assignment yields accurate long-term tool reliability estimates is presented without validation against ground-truth tool accuracy, held-out data, or analysis of how success/failure signals are obtained, raising a direct threat to the reliability-aware component credited for outperformance.
Authors: The experience system is assessed in the manuscript by tracking estimated reliabilities against observed tool success rates across queries, with success/failure derived from downstream task outcomes. Longitudinal analysis and comparisons appear in the Experiments and supplementary sections. We will revise the abstract to note that the reliability estimates are validated through these performance-tracking experiments. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The provided manuscript text contains no equations, derivations, or mathematical steps that reduce a claimed result to its inputs by construction. The framework is described at a high level with a training-free Beta-Bernoulli component, but no self-definitional mappings, fitted parameters renamed as predictions, or load-bearing self-citations are exhibited. Claims rest on experimental outperformance rather than any internal reduction that would trigger the enumerated circularity patterns. This is the expected outcome for a system-description paper without visible formal derivations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Quilt-llava: Visual instruction tuning by extracting localized narratives from open- source histopathology videos
Mehmet Saygin Seyfioglu, Wisdom O Ikezogwo, Fatemeh Ghezloo, Ranjay Krishna, and Linda Shapiro. Quilt-llava: Visual instruction tuning by extracting localized narratives from open- source histopathology videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13183–13192, 2024
2024
-
[2]
A multimodal generative ai copilot for human pathology.Nature, 634(8033):466–473, 2024
Ming Y Lu, Bowen Chen, Drew FK Williamson, Richard J Chen, Melissa Zhao, Aaron K Chow, Kenji Ikemura, Ahrong Kim, Dimitra Pouli, Ankush Patel, et al. A multimodal generative ai copilot for human pathology.Nature, 634(8033):466–473, 2024
2024
-
[3]
Pa-llava: A large language-vision assistant for human pathology image understanding
Dawei Dai, Yuanhui Zhang, Long Xu, Qianlan Yang, Xiaojing Shen, Shuyin Xia, and Guoyin Wang. Pa-llava: A large language-vision assistant for human pathology image understanding. InProceedings of the International Conference on Bioinformatics and Biomedicine, pages 3138–3143, 2024
2024
-
[4]
Pathgen-1.6m: 1.6 million pathol- ogy image-text pairs generation through multi-agent collaboration
Yuxuan Sun, Yunlong Zhang, Yixuan Si, Chenglu Zhu, Kai Zhang, Zhongyi Shui, Jingxiong Li, Xuan Gong, XINHENG LYU, Tao Lin, and Lin Yang. Pathgen-1.6m: 1.6 million pathol- ogy image-text pairs generation through multi-agent collaboration. InProceedings of the International Conference on Learning Representations, 2025
2025
-
[5]
Patho-r1: A multimodal reinforcement learning-based pathol- ogy expert reasoner
Wenchuan Zhang, Penghao Zhang, Jingru Guo, Tao Cheng, Jie Chen, Shuwan Zhang, Zhang Zhang, Yuhao Yi, and Hong Bu. Patho-r1: A multimodal reinforcement learning-based pathol- ogy expert reasoner. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 28418–28426, 2026
2026
-
[6]
Zhe Xu, Ziyi Liu, Junlin Hou, Jiabo Ma, Cheng Jin, Yihui Wang, Zhixuan Chen, Zhengyu Zhang, Fuxiang Huang, Zhengrui Guo, et al. A versatile pathology co-pilot via reasoning enhanced multimodal large language model.arXiv preprint arXiv:2507.17303, 2025
-
[7]
TeamPath: Building MultiModal Pathology Experts with Reasoning AI Copilots
Tianyu Liu, Weihao Xuan, Hao Wu, Peter Humphrey, Marcello DiStasio, Heli Qi, Rui Yang, Simeng Han, Tinglin Huang, Fang Wu, et al. Teampath: Building multimodal pathology experts with reasoning ai copilots.arXiv preprint arXiv:2511.17652, 2025. 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Wsicaption: Multiple instance generation of pathology reports for gigapixel whole-slide images
Pingyi Chen, Honglin Li, Chenglu Zhu, Sunyi Zheng, Zhongyi Shui, and Lin Yang. Wsicaption: Multiple instance generation of pathology reports for gigapixel whole-slide images. InPro- ceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, pages 546–556. Springer, 2024
2024
-
[9]
Wsi-vqa: Interpreting whole slide images by generative visual question answering
Pingyi Chen, Chenglu Zhu, Sunyi Zheng, Honglin Li, and Lin Yang. Wsi-vqa: Interpreting whole slide images by generative visual question answering. InProceedings of the European Conference on Computer Vision, pages 401–417. Springer, 2024
2024
-
[10]
Histgen: Histopathology report generation via local-global feature encoding and cross-modal context interaction
Zhengrui Guo, Jiabo Ma, Yingxue Xu, Yihui Wang, Liansheng Wang, and Hao Chen. Histgen: Histopathology report generation via local-global feature encoding and cross-modal context interaction. InProceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, pages 189–199. Springer, 2024
2024
-
[11]
Slidechat: A large vision-language assistant for whole-slide pathology image understanding
Ying Chen, Guoan Wang, Yuanfeng Ji, Yanjun Li, Jin Ye, Tianbin Li, Ming Hu, Rongshan Yu, Yu Qiao, and Junjun He. Slidechat: A large vision-language assistant for whole-slide pathology image understanding. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5134–5143, 2025
2025
-
[12]
Wsi-llava: A multimodal large language model for whole slide image
Yuci Liang, Xinheng Lyu, Wenting Chen, Meidan Ding, Jipeng Zhang, Xiangjian He, Song Wu, Xiaohan Xing, Sen Yang, Xiyue Wang, et al. Wsi-llava: A multimodal large language model for whole slide image. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 22718–22727, 2025
2025
-
[13]
Faruk Ahmed, Andrew Sellergren, Lin Yang, Shawn Xu, Boris Babenko, Abbi Ward, Niels Olson, Arash Mohtashamian, Yossi Matias, Greg S Corrado, et al. Pathalign: A vision-language model for whole slide images in histopathology.arXiv preprint arXiv:2406.19578, 2024
-
[14]
Alpaca: Adapting llama for pathology context analysis to enable slide-level question answering.medRxiv, pages 2025–04, 2025
Zeyu Gao, Kai He, Weiheng Su, Ines P Machado, William McGough, Mercedes Jimenez-Linan, Brian Rous, Chunbao Wang, Chengzu Li, Xiaobo Pang, et al. Alpaca: Adapting llama for pathology context analysis to enable slide-level question answering.medRxiv, pages 2025–04, 2025
2025
-
[15]
A multimodal whole-slide foundation model for pathology.Nature Medicine, pages 1–13, 2025
Tong Ding, Sophia J Wagner, Andrew H Song, Richard J Chen, Ming Y Lu, Andrew Zhang, Anurag J Vaidya, Guillaume Jaume, Muhammad Shaban, Ahrong Kim, et al. A multimodal whole-slide foundation model for pathology.Nature Medicine, pages 1–13, 2025
2025
-
[16]
Songhan Jiang, Fengchun Liu, Ziyue Wang, Linghan Cai, and Yongbing Zhang. Pathreasoner-r1: Instilling structured reasoning into pathology vision-language model via knowledge-guided policy optimization.arXiv preprint arXiv:2601.21617, 2026
-
[17]
Cpath-omni: A unified multimodal foundation model for patch and whole slide image analysis in computational pathology
Yuxuan Sun, Yixuan Si, Chenglu Zhu, Xuan Gong, Kai Zhang, Pingyi Chen, Ye Zhang, Zhongyi Shui, Tao Lin, and Lin Yang. Cpath-omni: A unified multimodal foundation model for patch and whole slide image analysis in computational pathology. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10360–10371, 2025
2025
-
[18]
Polypath: Adapting a large multimodal model for multi-slide pathology report generation.Modern Pathology, page 100886, 2025
Faruk Ahmed, Lin Yang, Tiam Jaroensri, Andrew Sellergren, Yossi Matias, Avinatan Hassidim, Greg S Corrado, Dale R Webster, Shravya Shetty, Shruthi Prabhakara, et al. Polypath: Adapting a large multimodal model for multi-slide pathology report generation.Modern Pathology, page 100886, 2025
2025
-
[19]
Generating dermatopathology reports from gigapixel whole slide images with histogpt.Nature Communications, 16(1):4886, 2025
Manuel Tran, Paul Schmidle, Ruifeng Ray Guo, Sophia J Wagner, Valentin Koch, Valerio Lupperger, Brenna Novotny, Dennis H Murphree, Heather D Hardway, Marina D’Amato, et al. Generating dermatopathology reports from gigapixel whole slide images with histogpt.Nature Communications, 16(1):4886, 2025
2025
-
[20]
Eugene V orontsov, George Shaikovski, Adam Casson, Julian Viret, Eric Zimmermann, Neil Tenenholtz, Yi Kan Wang, Jan H Bernhard, Ran A Godrich, Juan A Retamero, et al. Prism2: Unlocking multi-modal general pathology ai with clinical dialogue.arXiv preprint arXiv:2506.13063, 2025
-
[21]
Shengyi Hua, Jianfeng Wu, Tianle Shen, Kangzhe Hu, Zhongzhen Huang, Shujuan Ni, Zhihong Zhang, Yuan Li, Zhe Wang, and Xiaofan Zhang. Pathfound: An agentic multimodal model activating evidence-seeking pathological diagnosis.arXiv preprint arXiv:2512.23545, 2025. 11
-
[22]
Yuxuan Yang, Zhonghao Yan, Yi Zhang, Bo Yun, Muxi Diao, Guowei Zhao, Kongming Liang, Wenbin Li, and Zhanyu Ma. Hepato-llava: An expert mllm with sparse topo-pack attention for hepatocellular pathology analysis on whole slide images.arXiv preprint arXiv:2602.19424, 2026
-
[23]
Pathasst: A generative foundation ai assistant towards artificial gen- eral intelligence of pathology
Yuxuan Sun, Chenglu Zhu, Sunyi Zheng, Kai Zhang, Lin Sun, Zhongyi Shui, Yunlong Zhang, Honglin Li, and Lin Yang. Pathasst: A generative foundation ai assistant towards artificial gen- eral intelligence of pathology. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 5034–5042, 2024
2024
-
[24]
Patho-agenticrag: towards multimodal agentic retrieval- augmented generation for pathology vlms via reinforcement learning
Wenchuan Zhang, Jingru Guo, Hengzhe Zhang, Penghao Zhang, Jie Chen, Shuwan Zhang, Zhang Zhang, Yuhao Yi, and Hong Bu. Patho-agenticrag: towards multimodal agentic retrieval- augmented generation for pathology vlms via reinforcement learning. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 29921–29929, 2026
2026
-
[25]
Chengkuan Chen, Luca L Weishaupt, Drew FK Williamson, Richard J Chen, Tong Ding, Bowen Chen, Anurag Vaidya, Long Phi Le, Guillaume Jaume, Ming Y Lu, et al. Evidence- based diagnostic reasoning with multi-agent copilot for human pathology.arXiv preprint arXiv:2506.20964, 2025
-
[26]
Sheng Wang, Ruiming Wu, Charles Herndon, Yihang Liu, Shunsuke Koga, Jeanne Shen, and Zhi Huang. Pathology-cot: Learning visual chain-of-thought agent from expert whole slide image diagnosis behavior.arXiv preprint arXiv:2510.04587, 2025
-
[27]
Pathfinder: A multi-modal multi-agent system for medical diagnostic decision-making applied to histopathol- ogy
Fatemeh Ghezloo, Mehmet Saygin Seyfioglu, Rustin Soraki, Wisdom O Ikezogwo, Beibin Li, Tejoram Vivekanandan, Joann G Elmore, Ranjay Krishna, and Linda Shapiro. Pathfinder: A multi-modal multi-agent system for medical diagnostic decision-making applied to histopathol- ogy. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 234...
2025
-
[28]
Jingyun Chen, Linghan Cai, Zhikang Wang, Yi Huang, Songhan Jiang, Shenjin Huang, Hongpeng Wang, and Yongbing Zhang. Pathagent: Toward interpretable analysis of whole- slide pathology images via large language model-based agentic reasoning.arXiv preprint arXiv:2511.17052, 2025
- [29]
-
[30]
Guolin Huang, Wenting Chen, Jiaqi Yang, Xinheng Lyu, Xiaoling Luo, Sen Yang, Xiaohan Xing, and Linlin Shen. Survagent: Hierarchical cot-enhanced case banking and dichotomy-based multi-agent system for multimodal survival prediction.arXiv preprint arXiv:2511.16635, 2025
-
[31]
Xinheng Lyu, Yuci Liang, Wenting Chen, Meidan Ding, Jiaqi Yang, Guolin Huang, Daokun Zhang, Xiangjian He, and Linlin Shen. Wsi-agents: A collaborative multi-agent system for multi-modal whole slide image analysis.arXiv preprint arXiv:2507.14680, 2025
-
[32]
A co-evolving agentic ai system for medical imaging analysis.arXiv preprint arXiv:2509.20279, 2025
Songhao Li, Jonathan Xu, Tiancheng Bao, Yuxuan Liu, Yuchen Liu, Yihang Liu, Lilin Wang, Wenhui Lei, Sheng Wang, Yinuo Xu, et al. A co-evolving agentic ai system for medical imaging analysis.arXiv preprint arXiv:2509.20279, 2025
-
[33]
Zhengyang Xu, Han Li, Jingsong Liu, Linrui Xie, Xun Ma, Xin You, Shihui Zu, Ayako Ito, Xinyu Hao, Hongming Xu, et al. Mmnavagent: Multi-magnification wsi navigation agent for clinically consistent whole-slide analysis.arXiv preprint arXiv:2603.02079, 2026
-
[34]
Development and validation of an autonomous artificial intelligence agent for clinical decision-making in oncology.Nature Cancer, 6(8):1337–1349, 2025
Dyke Ferber, Omar SM El Nahhas, Georg Wölflein, Isabella C Wiest, Jan Clusmann, Marie- Elisabeth Leßmann, Sebastian Foersch, Jacqueline Lammert, Maximilian Tschochohei, Dirk Jäger, et al. Development and validation of an autonomous artificial intelligence agent for clinical decision-making in oncology.Nature Cancer, 6(8):1337–1349, 2025. 12
2025
-
[35]
Sahar Almahfouz Nasser, Juan Francisco Pesantez Borja, Jincheng Liu, Tanvir Hasan, Zenghan Wang, Suman Ghosh, Sandeep Manandhar, Shikhar Shiromani, Twisha Shah, Naoto Tokuyama, et al. Sage: Agentic framework for interpretable and clinically translatable computational pathology biomarker discovery.arXiv preprint arXiv:2602.00953, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[36]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InProceedings of the International Conference on Learning Representations, 2022
2022
-
[37]
Andrew Zhang, Tong Ding, Sophia J Wagner, Caiwei Tian, Ming Y Lu, Rowland Pettit, Joshua E Lewis, Alexandre Misrahi, Dandan Mo, Long Phi Le, et al. A multimodal and temporal foundation model for virtual patient representations at healthcare system scale.arXiv preprint arXiv:2604.18570, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[38]
Toolformer: Language models can teach themselves to use tools.Advances in Neural Information Processing Systems, 36:68539– 68551, 2023
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools.Advances in Neural Information Processing Systems, 36:68539– 68551, 2023
2023
-
[39]
Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in Neural Information Processing Systems, 33:9459–9474, 2020
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in Neural Information Processing Systems, 33:9459–9474, 2020
2020
-
[40]
Toolmem: Enhancing multimodal agents with learnable tool capability memory,
Yunzhong Xiao, Yangmin Li, Hewei Wang, Yunlong Tang, and Zora Zhiruo Wang. Toolmem: Enhancing multimodal agents with learnable tool capability memory.arXiv preprint arXiv:2510.06664, 2025
-
[41]
XSkill: Continual Learning from Experience and Skills in Multimodal Agents
Guanyu Jiang, Zhaochen Su, Xiaoye Qu, et al. Xskill: Continual learning from experience and skills in multimodal agents.arXiv preprint arXiv:2603.12056, 2026
work page internal anchor Pith review arXiv 2026
-
[42]
MemOS: A Memory OS for AI System
Zhiyu Li, Chenyang Xi, Chunyu Li, Ding Chen, Boyu Chen, Shichao Song, Simin Niu, Hanyu Wang, Jiawei Yang, Chen Tang, et al. Memos: A memory os for ai system.arXiv preprint arXiv:2507.03724, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
MemVerse: Multimodal Memory for Lifelong Learning Agents
Junming Liu, Yifei Sun, Weihua Cheng, Haodong Lei, Yirong Chen, Licheng Wen, Xuemeng Yang, Daocheng Fu, Pinlong Cai, Nianchen Deng, et al. Memverse: Multimodal memory for lifelong learning agents.arXiv preprint arXiv:2512.03627, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Reflexion: Language agents with verbal reinforcement learning.Advances in Neural Information Processing Systems, 36:8634–8652, 2023
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning.Advances in Neural Information Processing Systems, 36:8634–8652, 2023
2023
-
[45]
Colpali: Efficient document retrieval with vision language models
Manuel Faysse, Hugues Sibille, Tony Wu, Bilel Omrani, Gautier Viaud, CELINE HUDELOT, and Pierre Colombo. Colpali: Efficient document retrieval with vision language models. In Proceedings of the International Conference on Learning Representations, 2025
2025
-
[46]
Milvus: A purpose-built vector data management system
Jianguo Wang, Xiaomeng Yi, Rentong Guo, Hai Jin, Peng Xu, Shengjun Li, Xiangyu Wang, Xiangzhou Guo, Chengming Li, Xiaohai Xu, et al. Milvus: A purpose-built vector data management system. InProceedings of the International Conference on Management of Data, pages 2614–2627, 2021
2021
-
[47]
Yu A Malkov and Dmitry A Yashunin. Efficient and robust approximate nearest neighbor search using hierarchical navigable small world graphs.IEEE Transactions on Pattern Analysis and Machine Intelligence, 42(4):824–836, 2018
2018
-
[48]
Cognitive bias in decision-making with llms
Jessica Maria Echterhoff, Yao Liu, Abeer Alessa, Julian McAuley, and Zexue He. Cognitive bias in decision-making with llms. InFindings of the Association for Computational Linguistics, pages 12640–12653, 2024
2024
-
[49]
Application of artificial intelligence and digital tools in cancer pathology.The Lancet Digital Health, 7(10), 2025
Lawrence A Shaktah, Zunamys I Carrero, Katherine Jane Hewitt, Marco Gustav, Matthew Cecchini, Sebastian Foersch, Sabina Berezowska, and Jakob Nikolas Kather. Application of artificial intelligence and digital tools in cancer pathology.The Lancet Digital Health, 7(10), 2025. 13
2025
-
[50]
Can llms express their uncertainty? an empirical evaluation of confidence elicitation in llms
Miao Xiong, Zhiyuan Hu, Xinyang Lu, YIFEI LI, Jie Fu, Junxian He, and Bryan Hooi. Can llms express their uncertainty? an empirical evaluation of confidence elicitation in llms. In Proceedings of the International Conference on Learning Representations, 2024
2024
-
[51]
A visual-language foundation model for computational pathology.Nature Medicine, 30(3):863–874, 2024
Ming Y Lu, Bowen Chen, Drew FK Williamson, Richard J Chen, Ivy Liang, Tong Ding, Guil- laume Jaume, Igor Odintsov, Long Phi Le, Georg Gerber, et al. A visual-language foundation model for computational pathology.Nature Medicine, 30(3):863–874, 2024
2024
-
[52]
A visual–language foundation model for pathology image analysis using medical twitter.Nature Medicine, 29(9):2307–2316, 2023
Zhi Huang, Federico Bianchi, Mert Yuksekgonul, Thomas J Montine, and James Zou. A visual–language foundation model for pathology image analysis using medical twitter.Nature Medicine, 29(9):2307–2316, 2023
2023
-
[53]
Quilt-1m: One million image-text pairs for histopathology.Advances in Neural Information Processing Systems, 36:37995–38017, 2023
Wisdom Ikezogwo, Saygin Seyfioglu, Fatemeh Ghezloo, Dylan Geva, Fatwir Sheikh Mo- hammed, Pavan Kumar Anand, Ranjay Krishna, and Linda Shapiro. Quilt-1m: One million image-text pairs for histopathology.Advances in Neural Information Processing Systems, 36:37995–38017, 2023
2023
-
[54]
A vision–language foundation model for precision oncology.Nature, 638(8051):769–778, 2025
Jinxi Xiang, Xiyue Wang, Xiaoming Zhang, Yinghua Xi, Feyisope Eweje, Yijiang Chen, Yuchen Li, Colin Bergstrom, Matthew Gopaulchan, Ted Kim, et al. A vision–language foundation model for precision oncology.Nature, 638(8051):769–778, 2025
2025
-
[55]
Interpretable vision-language sur- vival analysis with ordinal inductive bias for computational pathology
Pei Liu, Luping Ji, Jiaxiang Gou, Bo Fu, and Mao Ye. Interpretable vision-language sur- vival analysis with ordinal inductive bias for computational pathology. InProceedings of the International Conference on Learning Representations, 2025
2025
-
[56]
Praveenbalaji Rajendran, Mojtaba Safari, Wenfeng He, Mingzhe Hu, Shansong Wang, Jun Zhou, and Xiaofeng Yang. Foundation models in medical image analysis: A systematic review and meta-analysis.ArXiv, abs/2510.16973, 2025
-
[57]
Aligning clinical needs and ai capabilities: a survey on llms for medical reasoning.Authorea Preprints, 2025
Qi Peng, Jiatong Li, Sirui Huang, Yiyang Jiang, Kaisong Gong, Ronger Ding, Shijie Ye, Changmeng Zheng, Xiao-Yong Wei, and Qing Li. Aligning clinical needs and ai capabilities: a survey on llms for medical reasoning.Authorea Preprints, 2025
2025
-
[58]
A pathology foundation model for cancer diagnosis and prognosis prediction.Nature, 634(8035):970–978, 2024
Xiyue Wang, Junhan Zhao, Eliana Marostica, Wei Yuan, Jietian Jin, Jiayu Zhang, Ruijiang Li, Hongping Tang, Kanran Wang, Yu Li, et al. A pathology foundation model for cancer diagnosis and prognosis prediction.Nature, 634(8035):970–978, 2024
2024
-
[59]
Qifeng Zhou, Wenliang Zhong, Thao M Dang, Hehuan Ma, Saiyang Na, Yuzhi Guo, and Junzhou Huang. Homie: Histopathology omni-modal embedding for pathology composed retrieval.arXiv preprint arXiv:2502.07221, 2025
work page internal anchor Pith review arXiv 2025
-
[60]
The landscape of computational pathology agents from static analysis to autonomous diagnostic workflows.Authorea Preprints, 2026
Jingyun Chen, Fengchun Liu, Songhan Jiang, and Linghan Cai. The landscape of computational pathology agents from static analysis to autonomous diagnostic workflows.Authorea Preprints, 2026
2026
-
[61]
arXiv preprint arXiv:2511.23269 (2025)
Timothy Ossowski, Sheng Zhang, Qianchu Liu, Guanghui Qin, Reuben Tan, Tristan Naumann, Junjie Hu, and Hoifung Poon. Octomed: Data recipes for state-of-the-art multimodal medical reasoning.arXiv preprint arXiv:2511.23269, 2025
-
[62]
Jiao Xu, Junwei Liu, Jiangwei Lao, Qi Zhu, Yunpeng Zhao, Congyun Jin, Shinan Liu, Zhihong Lu, Lihe Zhang, Xin Chen, et al. Pulsemind: A multi-modal medical model for real-world clinical diagnosis.arXiv preprint arXiv:2601.07344, 2026
-
[63]
Cx-mind: a pioneering multimodal large language model for interleaved reasoning in chest x-ray via curriculum-guided reinforcement learning.Information Fusion, page 104027, 2025
Wenjie Li, Yujie Zhang, Haoran Sun, Yueqi Li, Fanrui Zhang, Mengzhe Xu, Victoria Borja Clau- sich, Sade Mellin, Renhao Yang, Chenrun Wang, et al. Cx-mind: a pioneering multimodal large language model for interleaved reasoning in chest x-ray via curriculum-guided reinforcement learning.Information Fusion, page 104027, 2025
2025
-
[64]
Ruiqi Wu, Yuang Yao, Tengfei Ma, Chenran Zhang, Na Su, Tao Zhou, Geng Chen, Wen Fan, and Yi Zhou. Bridging the gap in ophthalmic ai: Mm-retinal-reason dataset and ophthareason model toward dynamic multimodal reasoning.arXiv preprint arXiv:2508.16129, 2025. 14
-
[65]
Wenchuan Zhang, Shuwan Zhang, Jiadi You, Fengling Li, Xiaoyan Wu, Xunxi Lu, Qingjie Lv, Juan Huang, Yuhao Yi, and Hong Bu. Attention-based multimodal fusion transformer for predicting the efficacy of neoadjuvant therapy in breast cancer: a cross-institutional retrospective study.Breast Cancer Research, 2025
2025
-
[66]
Analysis of thompson sampling for the multi-armed bandit problem
Shipra Agrawal and Navin Goyal. Analysis of thompson sampling for the multi-armed bandit problem. InProceedings of the Conference on Learning Theory, pages 39–1. JMLR Workshop and Conference Proceedings, 2012
2012
-
[67]
Ahmadreza Jeddi, Kimia Shaban, Negin Baghbanzadeh, Natasha Sharan, Abhishek Moturu, Elham Dolatabadi, and Babak Taati. When does rl help medical vlms? disentangling vision, sft, and rl gains.arXiv preprint arXiv:2603.01301, 2026
-
[68]
Nunext: Reframing nucleus detection as next-point detection.arXiv preprint arXiv:2603.07098, 2026
Zhongyi Shui, Honglin Li, Xiaozhong Ji, Ye Zhang, Zijiang Yang, Chenglu Zhu, Yuxuan Sun, Kai Yao, Conghui He, and Cheng Tan. Nunext: Reframing nucleus detection as next-point detection.arXiv preprint arXiv:2603.07098, 2026
-
[69]
Ziyang Song, Zelin Zang, Zuyao Chen, Xusheng Liang, Dong Yi, Jinlin Wu, Hongbin Liu, Jiebo Luo, and Zhen Lei. Anatomy-r1: Enhancing anatomy reasoning in multimodal large language models via anatomical similarity curriculum and group diversity augmentation.arXiv preprint arXiv:2512.19512, 2025
-
[70]
PathVQA: 30000+ Questions for Medical Visual Question Answering
Xuehai He, Yichen Zhang, Luntian Mou, Eric Xing, and Pengtao Xie. Pathvqa: 30000+ questions for medical visual question answering.arXiv preprint arXiv:2003.10286, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2003
-
[71]
MedXpertQA: Benchmarking Expert-Level Medical Reasoning and Understanding
Yuxin Zuo, Shang Qu, Yifei Li, Zhangren Chen, Xuekai Zhu, Ermo Hua, Kaiyan Zhang, Ning Ding, and Bowen Zhou. Medxpertqa: Benchmarking expert-level medical reasoning and understanding.arXiv preprint arXiv:2501.18362, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[72]
Omnimed- vqa: A new large-scale comprehensive evaluation benchmark for medical lvlm
Yutao Hu, Tianbin Li, Quanfeng Lu, Wenqi Shao, Junjun He, Yu Qiao, and Ping Luo. Omnimed- vqa: A new large-scale comprehensive evaluation benchmark for medical lvlm. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22170–22183, 2024
2024
-
[73]
Pathmmu: A massive multimodal expert-level benchmark for understanding and reasoning in pathology
Yuxuan Sun, Hao Wu, Chenglu Zhu, Sunyi Zheng, Qizi Chen, Kai Zhang, Yunlong Zhang, Dan Wan, Xiaoxiao Lan, Mengyue Zheng, et al. Pathmmu: A massive multimodal expert-level benchmark for understanding and reasoning in pathology. InProceedings of the European Conference on Computer Vision, pages 56–73. Springer, 2024
2024
-
[74]
Introducing-gpt-5-4
OpenAI. Introducing-gpt-5-4. 2026
2026
-
[75]
Gemini 3 pro - model card
Google. Gemini 3 pro - model card. 2025
2025
-
[76]
Hover-net: Simultaneous segmentation and classification of nuclei in multi-tissue histology images.Medical Image Analysis, 58:101563, 2019
Simon Graham, Quoc Dang Vu, Shan E Ahmed Raza, Ayesha Azam, Yee Wah Tsang, Jin Tae Kwak, and Nasir Rajpoot. Hover-net: Simultaneous segmentation and classification of nuclei in multi-tissue histology images.Medical Image Analysis, 58:101563, 2019
2019
-
[77]
critical
Fabian Hörst, Moritz Rempe, Helmut Becker, Lukas Heine, Julius Keyl, and Jens Kleesiek. Cellvit++: Energy-efficient and adaptive cell segmentation and classification using foundation models.Computer Methods and Programs in Biomedicine, page 109206, 2026. 15 A Additional Experiments and Discussion A.1 Experience Accumulation on PathMMU-val Table A.1: Quant...
2026
-
[78]
[Tool Selection Guide]
and Quilt-VQA [53]. These tasks require precise identification of specific pathological features (e.g., the presence of necrosis, specific cellular arrangements, or staining characteristics). We collect closed-ended questions from their respective test splits, resulting in 3,362 questions for Path-VQA and 343 questions for Quilt-VQA. B.2 Implementation De...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.